
May 30
On the Interplay Between Prior Weight and Variance of the Robustification Component in Robust Mixture Prior Bayesian Dynamic Borrowing Approach - Ratta - 2026 - Statistics in Medicine - Wiley Online Library onlinelibrary.wiley.com/doi/…
4
305


'skwdro: a library for Wasserstein distributionally robust machine learning', by Vincent Florian, Waïss Azizian, Franck Iutzeler, Jérôme Malick.
jmlr.org/papers/v27/24-1840.…
#robustification #robust #models
3
11
804

Jan 26
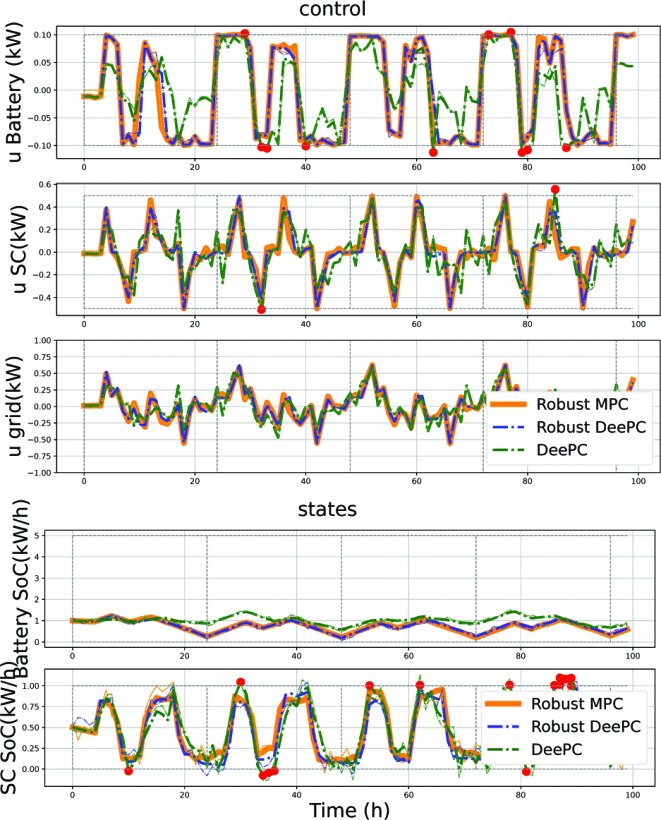
Tube-based Robustification of Data Enabled Predictive Control with Guarantees.
doi.org/10.1109/CDC57313.202…
3
34

Jan 12
Exemples recents inclouen propostes de “simple robustification” de proteccions existents i esquemes com DCT-Shield (freqüència) o variants optimitzades que continuen fent inútil l’edició fins i tot després de compressió i filtres típics.
openaccess.thecvf.com/conten…
1
4
157

Jan 9
Bonne année 2026 🎯
2025 = 1ère vraie année de trading systématique.
Même algorithme ATS (CFD DAX – FXCM), deux réalités :
En Démo :
85 % ( 42K€ sur un capital de 50K€ réinitialisé tous les mois, 2% risqué par trade) pour un DD de ~20%
En Live (argent réel, semi-auto) :
23 % depuis Juin pour un DD de 15%
2026 : Apprentissage continu, mise en place et robustification d'un portefeuille d'algos si le temps (et ma patience) me le permet.
Merci à mes mentors ATS: @Donovan_Ray_1 et @ATS_Eric 🙏
Et merci aussi les gars à @265Souls , @DavidG18278195 et @NotionRaphaxelo pour votre support et votre enthousiasme motivant!
2
9
978
Bien sûr après nous avoir supprimé 2 lianes
@PoirierPierrick c’est normal c’est juste la Robustification hein n’est-ce pas ?
1
1
57

4 Dec 2025
📢 Happening soon!
Uri & Yonatan are going to present the awesome work they did analyzing the robustification effect of state entropy regularization
Looking forward to see you all and to discuss at the poster later (11am, n.512)
#NeurIPS2025

1
16
509

14 Nov 2025
Introduce SPIDER - a unified scalable dynamics-level retargeting method for both dex hand and humanoid!
What does "dynamics-level retargeting" mean? Human motions in, physically feasible high-quality robot motions out (BOTH state and action).
These robot motions are so good that you can directly open-loop execute the action sequence in the real world! Also, dynamics-level retargeting makes the downstream RL policy learning super easy since it only needs to figure out a "small residual" on top of the already physically feasible refs.
Even better, we can easily do physics-level data augmentation & robustification, such as adding external forces and changing frictions. SPIDER can be used as a data engine for real2sim2real and learning from human data.
How it works? It is based on the diffusion-inspired sampling-based optimal control framework we developed in the past (MBD, DIAL-MPC) and virtual contact guidance.
Led by @ChaoyiPan and collaboration with @Meta FAIR.
14 Nov 2025

🕸️ Introducing SPIDER — Scalable Physics-Informed Dexterous Retargeting!
A dynamically feasible, cross-embodiment retargeting framework for BOTH humanoids 🤖 and dexterous hands ✋.
From human motion → sim → real robots, at scale.
🔗 Website: jc-bao.github.io/spider-proj…
🧵 1/n
1
9
69
8,183

5 Nov 2025
Constant growth hasn't always been the norm, and a bit of scepticism used to be healthy.
Somewhere along the way, scepticism became a bad word, as if its mere existence brings about bad news.
I guess that's because we unconsciously accepted that our bright thoughts are the cause of our bright future, when in truth it's mostly the other way around.
It helps, at the very least, to separate scepticism from pessimism. Roughly speaking:
Optimism = optimization
Scepticism = robustification
Pessimism = inaction
1
13
469

Maybe I had too high hopes of finding novel ideas that powered GDM’s IMO gold and would change my perspective, but that isn’t the case and my earlier views largely stand. The biggest takeaway is that their ProofAutoGrader shows strong correlation with expert graders. Skimming the datasets they look usable, though to my taste there’s a bit too much algebraic inequalities and computational geometry. Thanks to their “robustification,” they’re a decent starting point for evals. I’m actually surprised they made these datasets public and they even note long-term data contamination as a limitation, so the benchmark’s longevity may be limited. Also their “hard” problems are hard in the time-limited IMO sense, but don’t really resemble real-world hard problems.
4 Nov 2025

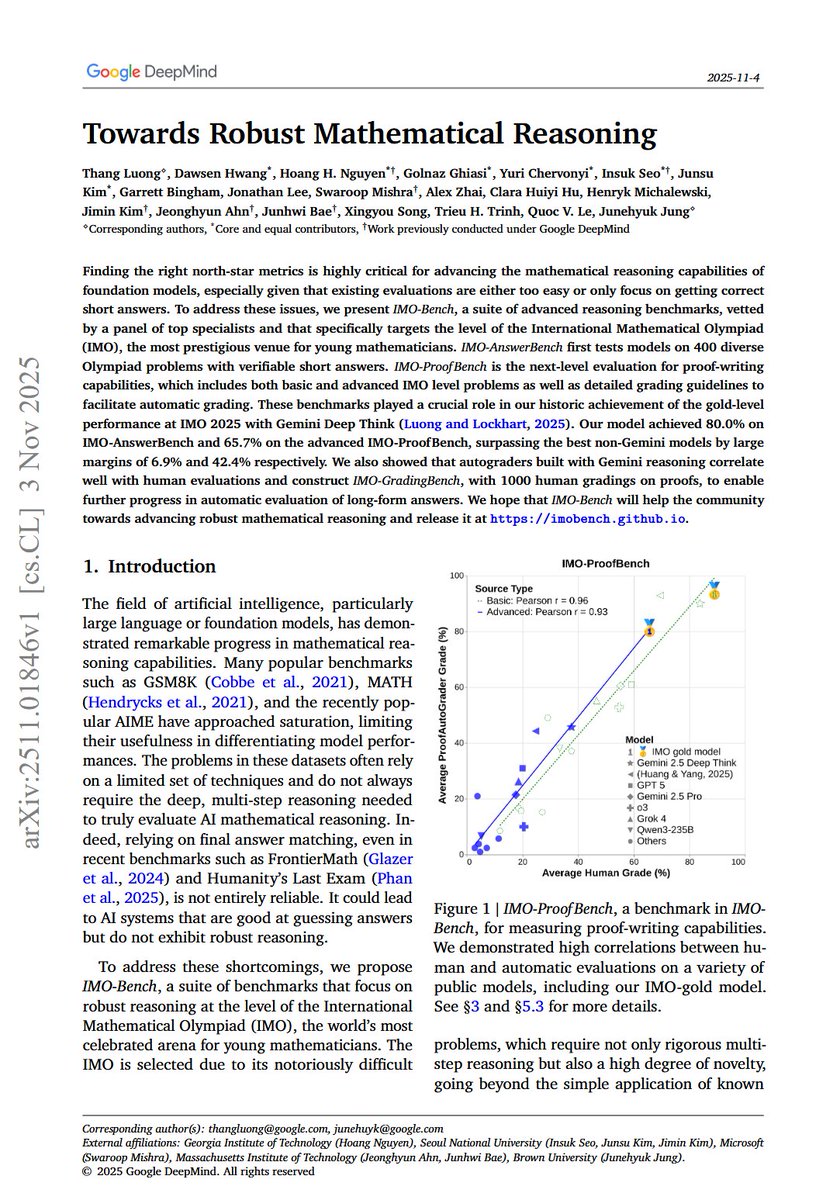
Google DeepMind release:
Towards Robust Mathematical Reasoning
Introduces IMO-Bench, a suite of advanced reasoning benchmarks that played a crucial role in GDM's IMO-gold journey. Vetted by a panel of IMO medalists and mathematicians.
IMO-AnswerBench - a large-scale test on getting the right answer
IMO-ProofBench - a next-level evaluation for proof writing
IMO-GradingBench to enable further progress in automatic evaluation of long-form answers.
7
1,342

1 Oct 2025
Alain Quevrin, CEO de Thalès au #ColloqueCJG sur l’industrie :
🛡️ Les enjeux de défense et d’autonomie industrielle en Europe sont de plus en plus complexes. Après les chocs du Covid, de la guerre en Ukraine et face aux tensions géopolitiques, il devient crucial de renforcer notre souveraineté et de ne pas dépendre excessivement de la Chine ou des États-Unis.
🔗 La fragilité des chaînes d’approvisionnement reste préoccupante : pour certains secteurs stratégiques comme les radars (jusqu’à 30.000 pièces par système), 50 % des composants viennent de l’extérieur de l’Europe. La capacité européenne dans les semi-conducteurs n’atteint que 10 % des besoins, et 80 % des outils de cybersécurité utilisés ici sont importés.
🔄 3 grands axes émergent aujourd’hui :
- Robustification des chaînes industrielles et diversification des sous-traitants, dictées désormais par des considérations géopolitiques, pas seulement économiques.
- Compétitivité’non seulement vis-à-vis de la Chine mais aussi des États-Unis, en restant très attentifs à ce point clé.
- Innovation qui risque d’être sacrifiée à la facilité d’acheter ce qui existe déjà sur le marché. Ne pas investir dans l’innovation serait une erreur majeure pour l’autonomie européenne à long terme.
#ColloqueCJG #Industrie #Entreprise #Emploi #Energie #Autonomie #Competitivité #Innovation #CJG

3
171

26 Jul 2025
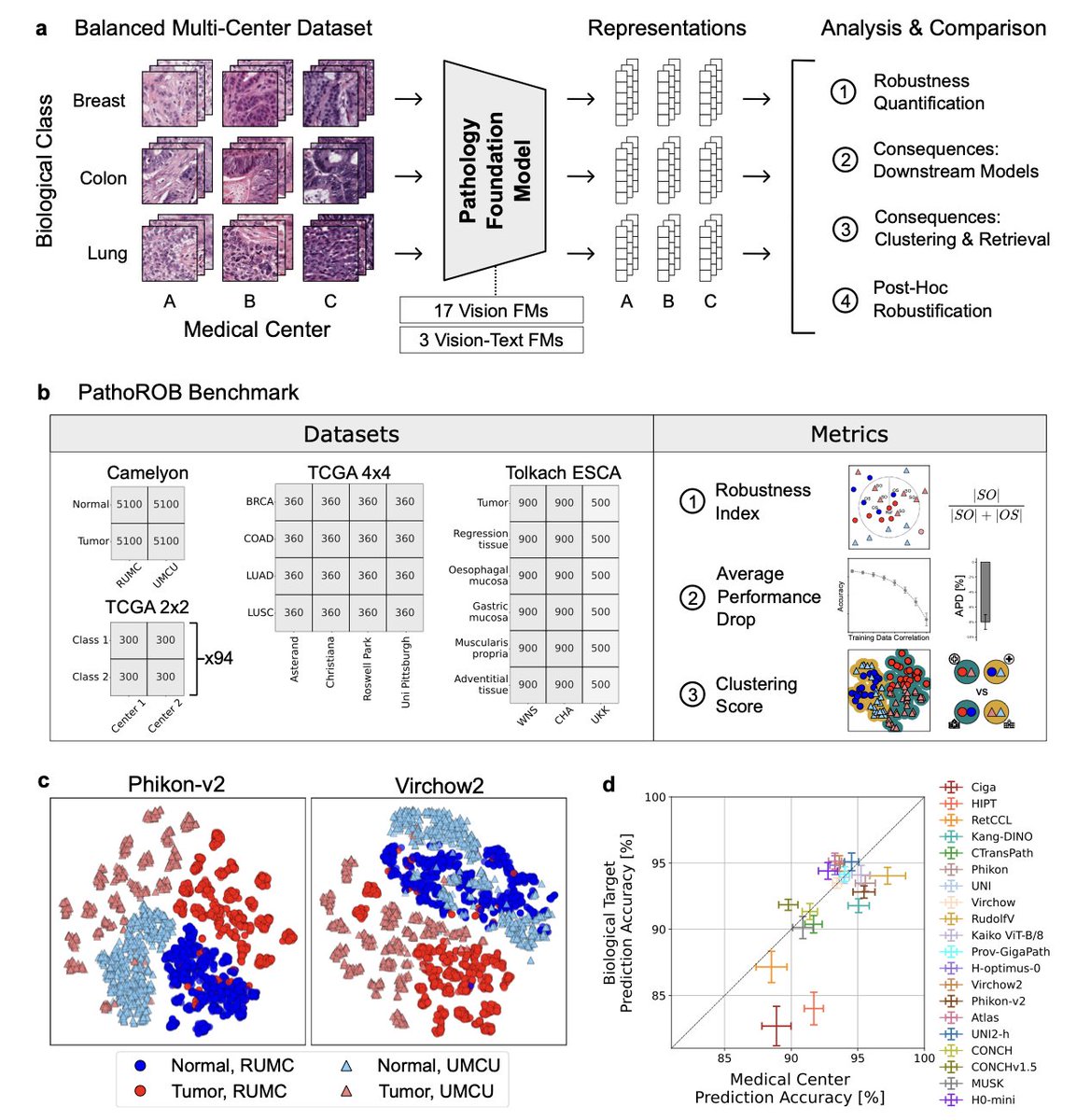
Towards Robust Foundation Models for Digital Pathology
1. This study investigates the robustness of biomedical foundation models (FMs) in digital pathology, revealing that current models are highly susceptible to non-biological technical variations such as staining differences and scanner artifacts, which can lead to significant errors in clinical applications.
2. The authors introduce PathoROB, a novel benchmark with three innovative metrics — the robustness index, performance drop in downstream tasks, and clustering score — to systematically measure and quantify the robustness of pathology FMs against non-biological variability across medical centers.
3. The study evaluates 20 state-of-the-art pathology FMs using the PathoROB benchmark and finds that all models exhibit substantial robustness deficits, with non-robust models causing major diagnostic errors and clinical blunders that could prevent safe clinical adoption.
4. The research proposes a framework for post-hoc robustification techniques, such as image-space stain normalization and representation-space batch correction, which significantly improve the robustness of FMs without requiring retraining, reducing the risk of downstream errors but not eliminating them entirely.
5. The findings emphasize that robustness evaluation is essential for validating pathology FMs before clinical use and highlight the need for future FM development to integrate robustness as a core design principle to ensure reliable and safe clinical deployment.
📜Paper: arxiv.org/abs/2507.17845
#DigitalPathology #FoundationModels #Robustness #AIinMedicine
2
9
796
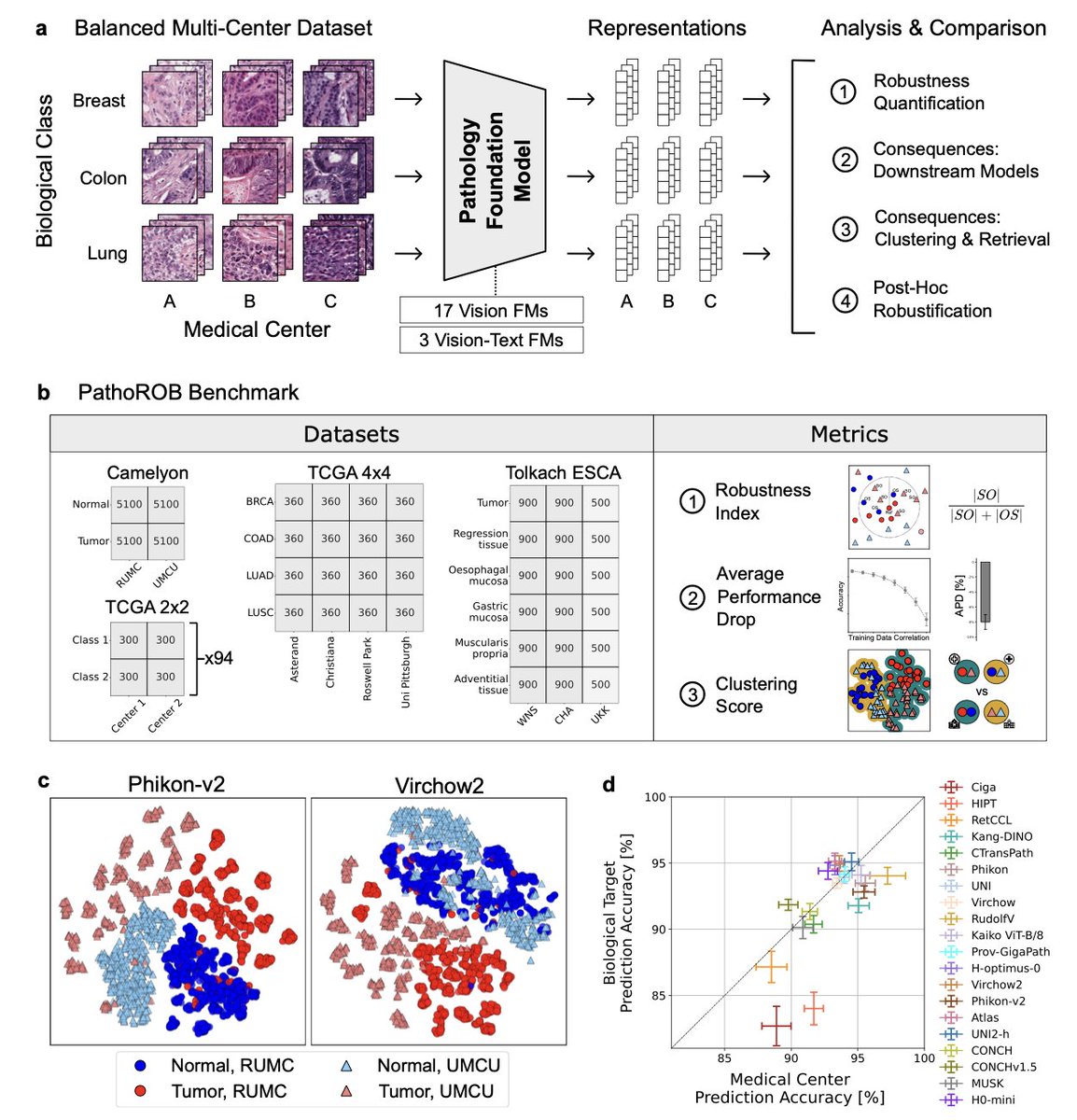
26 Jul 2025
Towards Robust Foundation Models for Digital Pathology
1. This study investigates the robustness of biomedical foundation models (FMs) in digital pathology, revealing that current models are highly susceptible to non-biological technical variations such as staining differences and scanner artifacts, which can lead to significant errors in clinical applications.
2. The authors introduce PathoROB, a novel benchmark with three innovative metrics — the robustness index, performance drop in downstream tasks, and clustering score — to systematically measure and quantify the robustness of pathology FMs against non-biological variability across medical centers.
3. The study evaluates 20 state-of-the-art pathology FMs using the PathoROB benchmark and finds that all models exhibit substantial robustness deficits, with non-robust models causing major diagnostic errors and clinical blunders that could prevent safe clinical adoption.
4. The research proposes a framework for post-hoc robustification techniques, such as image-space stain normalization and representation-space batch correction, which significantly improve the robustness of FMs without requiring retraining, reducing the risk of downstream errors but not eliminating them entirely.
5. The findings emphasize that robustness evaluation is essential for validating pathology FMs before clinical use and highlight the need for future FM development to integrate robustness as a core design principle to ensure reliable and safe clinical deployment.
📜Paper: arxiv.org/abs/2507.17845
#DigitalPathology #FoundationModels #Robustness #AIinMedicine
5
17
1,536

19 Jun 2025
latent rl reasoning, Chinese energy sputnik, actual robots, anti-ai sentiment, continual gen video ai gaming, light gpu datacenters, corporate vertical integration of chipmaking, hopefully food supply robustification.
1
6
972

19 Jun 2025
Terminus partiels, extensions inconsidérées du tram, même la ligne de bus express G qui a à peine un an est déjà à bout de souffle ! Les lignes E et F du tram vont venir fragiliser encore plus son exploitation dans le cadre d’une tentative désespérée de robustification qui ressemble davantage à du rafistolage.
À force de bricoler dans l'urgence du mandat, les politiques successives ont perdu de vue les enjeux de long terme.
Alain Anziani parlait d'échec collectif mais beaucoup restent pourtant encore dans le déni, prêts à renouveler les erreurs du passé dans une sorte de mépris des usagers d'aujourd'hui et de demain.
La politique des mobilités que nous proposons, structurée autour du métro est la promesse de transmettre une ville fluide et apaisée.
Métro, marche, vélo, train...
👉 Voir nos propositions sur la mobilité
bordeauxnouvellevoie.fr/nos-…

3
6
511

13 Jun 2025
Time-series regression primitives done✨. OLS and a couple recency weighted variants, optional ridge of course, optional robustification via several methods. Separate Theil-Sen. Handles all my signal needs. No multi-regression -- too heavy.
1
2
338
12 Jun 2025
Was literally in the wilderness the last 4 days. Now in process of prod impl of regression primitives. Taking a bit of time to select a few variants w/ tangible benefits and some robustification options. Beyond basic OLS, but nothing too aggressive.
1
2
246

5 Apr 2025
Your friend Howard Lutnick made it clear that robustification will be used to produce goods, not sure where your children fit in.
2
123

1 Apr 2025
🚀 AI is moving fast, but how do we know it’s safe?
As machine learning models grow in complexity, their behavior becomes harder to predict. Traditional testing just isn’t enough, especially in high-stakes environments like finance, aviation, and healthcare.
At @safe_intel_ai , we’re tackling this head-on with formal verification, a deep validation approach that lets us mathematically prove model behavior under a wide range of real-world conditions.
✅ Go beyond pass/fail test cases
✅ Uncover hidden fragilities
✅ Make models robust by design, not by luck
Our mission is to help companies move from guesswork to guarantees so they can deploy AI with confidence.
💡 Backed by cutting-edge research from @imperialcollege
💸 Backed by @AmadeusCapital, Vsquared Ventures & OTB Ventures
🔗 Connect with us and check out our ML validation platform (early access is now open): lnkd.in/eS2-rxDW
#AI #MachineLearning #FormalVerification #AIsafety #DeepTech #Startup #RobustAI #Validation #SafeIntelligence #Robustification


1
5
244