
Aly and Sue's talk outside parliament with screenshots of the evidence edited into this video. We are now taking this to the Ombudsman and probably further than that. @ChildrensHD @RCR_NZ @theplatform_nz @SeanPlunket @centrist_nz @DailyTelegraph5 @dchengnz @RiverFreedom22 @nzdsos @HopeRising19 @P_McCulloughMD @aniobrien #myocarditis #pericarditis #royalcommission #hidingofdata #alteredgovernmentdocs #covidvaccine #children #safetydata #NZPOL #nzpolitics #nzbrockoviches #nzbrockobitches :)
8
20
56
1,437

Feb 23
Usual Dose is 50mg/kg/d in 2 doses, for adults 2x1g. Safetydata exists for up to 4g/d, so more frequent dosing in certain infections is no problem. Still have the nice bioavailability and the narrow spectrum and few side effects, its my go-to for oral s.aureus treatment.
2
35

Jan 8
Good security decisions depend on timely, local information, not rumors.
What kind of alert would you find most useful?
Explore more on the Gatehouse website: gate-house.com
#SecurityAlerts
#SafetyData
#Gatehouse
1
2
21

7 Dec 2025
My brief summary of the discussion I linked: We know there's no safetydata available, but let's recommend the vaccine in pregnancy and to our patients ongoing IVF treatments anyway. Disinformation, vaccine hesitancy, the virus itself or not having a consensus are far more concerning than the extremely small theoretical risks of the vaccine.
(February 2021)👇
youtu.be/sxR2g1b4ge4?si=08xn…

1
6
375

20 Nov 2025
🚨 MAJOR NEWS: We have officially submitted our preclinical study protocol for the peptide BPC-157 to the lab.
This 2-month mouse study is specifically designed to generate formal high-dose chronic safety (200 ug/kg) and functional performance data (Grip Strength, Cytokines).
🔑 Why this matters: This dataset addresses the critical non-toxicity requirements from regulatory agencies (e.g., AIFA/EMA) needed to proceed to human Phase I trials. We are actively building the bridge toward official approval!
@BioProtocol @Molecule_sci @pumpdotscience
#BPC157 #PreclinicalData #ClinicalTrials #AIFA #RegenerativeMedicine #Peptides #PreclinicalStudy #Pharmacology #SafetyData #Pharmacology #Fitness #Innovation


7
5
17
2,287

18 Nov 2025
That’s a crucial baseline
FSD matching human safety is a major milestone. But what stands out is FSD’s potential to improve with more data, unlike humans. Are we tracking near-term safety gains or just relying on cumulative miles? #AutonomousDriving #FSDTesla’s 6.4B miles with FSD sets a huge benchmark, but the real test is comparing its fatality rate to the national average of 1 per 79M miles. Does Tesla’s data show fewer actual fatalities? That’s the critical insight for widespread adoption trust. #FSD #SafetyData
1
2
89

15 Nov 2025
🚗🔢 Tesla just launched a live FSD safety tracker!
FSD (Supervised) now logs real-time miles and shows 7x fewer major and minor crashes than the US average.
Safer rides, updated stats, more transparency. 🚘🛡️
#Tesla #FSD #SafetyData

1
2
89

7 Nov 2025
Cam Kutu Devrimi: TanAI Prompt Füzyon (L1) ile Açıklanabilir Kendini Geliştiren Yapay Zekâ
Kara kutuların çağı kapanıyor. Artık yapay zekâlar hem nasıl düşündüğünü açıklayacak, hem de kendilerini eğitecek. TanAI L1, bu devrimin ilk katmanı.
Sorun: Kara Kutu Modeller
Günümüzün en güçlü yapay zekâları bile hâlâ bir kara kutu. Siz bir komut verirsiniz, o bir sonuç üretir. Ancak aradaki süreç hangi adımları takip etti, hangi verileri kıyasladı, hangi çıkarımları yaptı neredeyse tamamen görünmezdir. Bu da üç temel sorun doğurur:
* Açıklanamayan kararlar
* Hatalardan öğrenememe
* Kurumsal veriyle bağ kuramama
Özellikle B2B dünyasında bu üç sorun kabul edilemez. Şirket içi hassas verilerle çalışacak bir yapay zekânın hem şeffaf, hem güvenilir, hem de uyarlanabilir olması gerekir.
Fırsat ve çözüm: TanAI Prompt Füzyon (L1 Katmanı)
TanAI’nin Prompt Füzyon (L1) modülü, bu sorunlara devrimsel bir yaklaşımla çözüm getiriyor.
Mimari: Dual Reasoning Feedback Loop ARD
TanAI L1, klasik tek adımlı “prompt → yanıt” mimarisi yerine çok modüllü bir düşünce zinciri sunar.
Dual Reasoning Architecture:
* Sol Dal (Analitik): Anlam çözümleme, bağlamsal çoğaltma, bilgi çıkarımı.
* Sağ Dal (Duygusal Kişisel Bağlam): Tonlama, etki, bellek, kişiselleştirme.
Bu iki rota birlikte çalışarak hem bilgi doğruluğu hem de duygusal rezonans sağlar.
ReasonAug: Kendini Eğiten Yapay Zekâ
ReasonAug sistemi, her prompt sonrası yapılan işlem adımlarını bir telemetry sistemine kaydeder. Bu kayıtlar, daha sonra sistemin kendini eğitmesi için kullanılır. Bu eğitim LLM’lerde ki SFT / Lora / FFt gibi yüksek işlem gücü gerektiren bir eğitim prosedürü değil, tersine CPU ile işlenebilen karmaşık matematiksel hesapların eğitim setini ağırlıklandırmasıdır. Her adımda şu bilgiler toplanır:
* Hangi veriler seçildi?
* Hangi mantık zinciri izlendi?
* Hangi modül hangi süreyi aldı?
* Hangi kararlar discard edildi?
Artık LLM’ler sadece cevap üretmiyor, aynı zamanda kendi süreçlerinden öğreniyor.
ARD: Adaptive Reasoning Diffusion ile Sebep-Zinciri Evrimi
L1 katmanının düşünce işleme kabiliyetinin kalbinde, ARD (Adaptive Reasoning Diffusion) mimarisi yer alır. ARD, L1’in sadece belirli kurallarla işlem yapan bir sistem değil; bağlama, çıktıya ve içsel belleklere göre evrilen bir akıl zinciri geliştirmesini sağlar.
Peki ARD nedir?
ARD, klasik “input → process → output” şemasının ötesine geçerek, sistemin her bir düşünce zinciri adımını dinamik olarak adapte etmesine olanak tanır. Bu sistemde düşünceler sabit bir mantık sırasına göre değil; aşağıdaki faktörlere göre değişkenlik gösteren bir yayılım (diffusion) modeliyle şekillenir:
* Girdi bağlamının karmaşıklığı
* Kullanıcının duygusal ve bilişsel geçmişi
* Önceki snippet’lerin başarımı
* ReasonAug log’larından öğrenilen sezgisel motifler
ARD Nasıl Çalışır?
1. Bağlam Analizi
Her bir prompt, semantik olarak parçalanır. Bu parçalar snippet’lere ayrılırken, snippet’lerin anlam yoğunluğu ve önem derecesi hesaplanır.
2. Rota Önerisi & Yayılım
Prompt Evaluation Engine (PEE) modülü, veriyi Sol (analitik) veya Sağ (duygusal) dala yönlendirirken; ARD bu seçimin parametrelerini (örneğin tonalite, etki gücü, geçmiş tutarlılığı) günceller. Böylece sadece sabit bir mantıkla değil, adaptif bir mantıkla yönlendirme yapılır.
3. Diffusion Dinamiği
Her bir snippet, diğer modüllere iletilmeden önce ARD tarafından bir “yayılım kararlılığı” skoruna göre filtrelenir. Eğer bilgi, L1’in hafıza yapılarıyla (Emotional Conditioning Vector[ECV], Affective Memory Retriever [AMR]) çelişiyorsa zayıflatılır; destekliyorsa kuvvetlendirilir.
4. Geri Yansıma (Back Reflection)
ReasonAug sistemi, daha sonra bu kararları izleyerek hangi ARD konfigürasyonlarının başarı getirdiğini ölçer. Bu sayede ARD’nin içsel parametreleri zamanla optimize edilir, tıpkı bir organizmanın evrim geçirmesi gibi.
Neden Fark Yaratır?
ARD sayesinde TanAI L1, tüm geleneksel LLM’lerden ayrılır. Çünkü:
* Aynı prompt, farklı bağlamlarda farklı çıkarımlarla işlenebilir.
* Kullanıcı bazlı düşünce tarzı oluşturulabilir.
* Modül içi geçişler “sabitten dinamiğe” dönüşür.
* Kendi kendini optimize eden düşünce zincirleri oluşur.
Bu özellikler TanAI ’i statik değil, dinamik düşünen bir yapay zekâ sistemine dönüştürür.
Örnek: L1 Süreç Aşamaları (bir B2B senaryosu)
Prompt: “Yarınki müşteri lansmanı öncesi teknik ekiplerin hazırlık durumunu bana özetle.”
1. Pre-clean & Safety Filters (B1 & B2)
Prompt, dilsel ve içeriksel olarak sadeleştirilir, küfür, hassas veri ve yüksek riskli istekler tespit edilip temizlenir.
* B2B için özel filtreler uygulanır: şirket içi jargonlar, hassas müşteri adı, ürün kodları vs.
2. PEE: Prompt Evaluation Engine (C)
Bu aşamada prompt, L1’in analiz motoru olan PEE tarafından değerlendirilir:
* Anlam yoğunluğu
* Zaman referansları (yarın)
* Görev türü (özetleme)
* Kritiklik derecesi (müşteri lansmanı)
Bu bağlamda prompt, “yüksek bağlamlı görev yönelimli komut” olarak sınıflanır.
Ardından Dual Route Seçimi (Sol — Sağ) yapılır:
* Sol Dal (Low Context): teknik özet, veri raporları, organizasyonel planlama
* Sağ Dal (Sufficient Context): ekiplerin duygusal-davranışsal eğilimi, geçmiş etkileşimlerin tonu Bu örnekte her iki rota da aktifleşir çünkü hem görev odaklı hem de insan faktörü içeren bir komuttur.
3. ARD: Adaptive Reasoning Diffusion Aktifleşir
ARD, route seçiminde bağlamsal yayılım sağlar:
* Sol Dal’a teknik geçmiş ve prosedürel bilgi ağırlıklı yayılım yapılır.
* Sağ Dal’a geçmiş konuşmalardan duygusal tonu taşıyan snippet’ler filtrelenir.
Her snippet, ARD tarafından güven ve bağlamsal tutarlılık skoru ile değerlendirilerek süreç içinde yer bulur.
4. ReasonAug: Zihinsel Gerekçelendirme Katmanı
Prompt, sadece kelime düzeyinde değil, niyet düzeyinde analiz edilir.
ReasonAug devreye girer:
* “Bu kişi sadece durum özeti istemiyor, riskli alanları görmek istiyor.”
* “Müşteri lansmanı demek, yüksek beklenti ve stresli ekip olabilir.”
Bu sezgisel gerekçeler, daha sonra tüm süreç boyunca kullanılır (ve telemetry’ye kaydedilir).
5. Semantic Enrichment & Anchor Retrieval (D1.x, D3.x)
* Prompt semantik olarak genişletilir.
* Gerekli bilgi parçacıkları (anchored micro snippets) ve embedding tabanlı benzer kayıtlar veritabanından getirilir.
Örnek: Son 3 lansman öncesi konuşmalar, teknik ekibin proje güncellemeleri, lead kişilerin stres yanıtları.
6. Snippet Filtreleme & Hafıza Modülasyonu (E1-E6)
E1: Doğru snippet’ler seçilir.
E2: Geniş tarama yapılır (wide retrieval).
E3: Token bütçesi belirlenir.
E4: Zaman duyarlılığına göre sıralanır (temporal relevance).
E5: AffMem modülü duygusal bağlamı ayıklar: “ekip yorgun ama özverili.”
E6: ECV ile durumsal hafıza vektörü çıkarılır.
7. Fusion (F)
Sol ve Sağ dalın tüm bilgi ve sezgileri birleştirilir.
* Teknik detay insan davranışı → “tekil bilgi portresi” olarak biçimlenir.
* SafetyData, ECV, SemanticCtx ve ReasonAug birlikte işlenir.
8. Handoff (G)
L2’ye, yapılandırılmış bir “bilgi paketi” aktarılır.
Bu paket şunları içerir:
* Özet metin
* Referans snippet listesi
* Hafıza vektörü
* ReasonAug log’ları
* Anchor ID’leri ve bağlamsal skorlar
*ARD seçim parametreleri
Bu akış sayesinde L1, bir B2B yöneticisinin sorusuna sadece yüzeysel bir yanıt vermez; şirket belleği, insan faktörü, zaman hassasiyeti ve bağlamın tamamını işleyerek özelleştirilmiş ve güçlü bir yanıt oluşturur. Tüm bu süreç boyunca yüzlerce küçük telemetry kaydı oluşur ve bunlar sistemin kendi eğitimi için kullanılır.
Teknolojik Temeller
* Telemetry & LogStack: Tüm işlem zinciri kaydedilir ve zamanlayıcılarla ölçülür.
* ECV (Emotional Conditioning Vector): Kişiye özel duygusal eğilimlerin öğrenilmesi.
* ReasonAugStats: L1’in düşündüğü her adımın açıklanabilirliği.
* Session State Contracting: Tüm modüller arasında veri akışı garanti edilir.
* Vector DB & SQL Harmonisi: Anlam çıkarımı veri tutarlılığı bir arada.
Neden B2B On-Premise?
TanAI, B2C yerine doğrudan kurumsal yapılarla çalışan bir yapay zekâ sistemidir. Bu yüzden:
* Veriler dışarı çıkmaz.
* Sistemler içten öğrenilir.
* Latency kontrol altındadır.
* Her adım izlenebilir ve doğrulanabilir.
* Firmalar için geliştirilebilir ve uyarlanabilir zeka.
Örneğin; şirket içi CRM sistemi, takvimler, slack konuşmaları gibi yapılar L1 tarafından içsel olarak öğrenilir. Böylece “kullanıcı neleri öncelikli buluyor”, “hangi veriler önemli” gibi çıkarımlar otomatik hale gelir.
Neden Bu Bir Devrimdir?
TanAI L1 sadece bir “prompt fusion engine” değil. Kendi düşünce zincirini yorumlayabilen, davranışsal ve yapısal olarak kendini eğitebilen ilk mimaridir. Şunları mümkün kılar:
* Neden bu cevabı verdiğini gösterir.
* Yanlış cevaptan ders çıkarır.
* Kullanıcıyla zaman içinde ortak bir bilinç geliştirir.
Yani bu sadece cam bir kutu değil; aynı zamanda kendine ayna tutabilen bir sistemdir.
Gelecek: L1 ve Ötesi
L1 mimarisi L2’ye (Autoregressive Core) entegre olduğunda artık sistem:
* Kendini denetler,
* Yeni bilgi çıkarımları yapar,
* Karakter ve kullanıcı tabanlı kararlar üretir.
Tüm bunlar TanAI’nin “Organik Zekâ” vizyonunun ilk adımlarıdır. Tüm katmanlar tamamladığında bu Hybrid ve Modüler yapı LLM ekosistemine büyük yenilikler getirmiş olacak…
Prompt Füzyon sonrasında modüler olarak çalışacak TanAI katmanlarımız;
1. Prompt Füzyon — (L1)
2. Autoregressive Core — (L2)
3. Encoder Bridge — (L3)
4. dLLM Core — (L4)
5. Fusion Core — (L5)
6. Emotional Memory — (L6)
7. Output Synth Final Decoder — (L7)
8. Self Adaptive Tuning — (L8)
9. Agentic Planner — (L9)
Son Söz
Yapay zekâda yeni bir çağ başlıyor. TanAI ile birlikte artık modeller açıklanabilir, kişiselleştirilebilir ve kendi süreçlerinden öğrenebilir hale geliyor. GPT devri değil; Akıl arttırabilen, kendi öğrenebilen, en az düzeyde halüsinasyon görebilen ve bağlam kopmasını aşabilen modellerin çağı geliyor…
Kara kutular kapanıyor. Cam kutular düşünmeye başlıyor.
Promptun, Füzyon edilmiş halini JSON formatında görmek için : tanai.xyz/l1/tanai-l1-respon…
Ek: L1, klasik prompt işleme mimarilerini kökten değiştirerek şu yenilikleri sunar:

4
3
32
16,506

22 Oct 2025
Strive for #PVExcellence! Our comprehensive white paper guides you through best practices for #SafetyData management, from receipt to reporting, adapting to the evolving data landscape: hubs.li/Q03Hzb_60
#PatientsFirst #UBC

2
101

13 Apr 2025
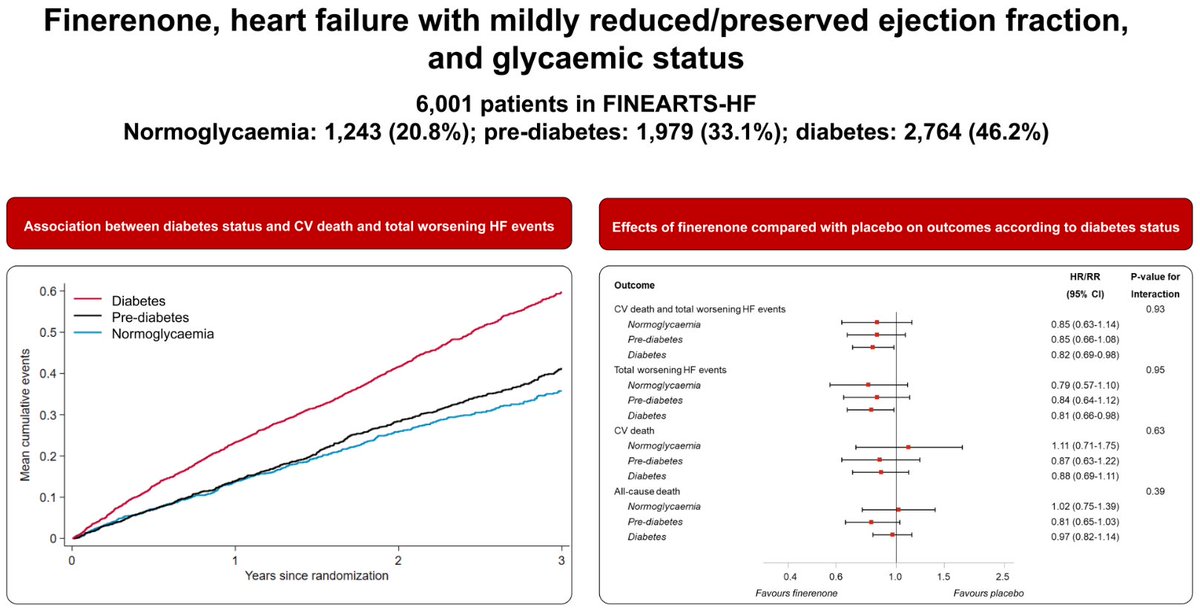
📢🧵Thread: Finerenone in HFpEF & Glycaemic Status
💡 New insights from the FINEARTS-HF trial — published in @EJHeartFailure
#CardioTwitter #HeartFailure #Finerenone #HFpEF #Diabetes #MedTwitter
1/🔬 Study: Prespecified analysis of the FINEARTS-HF trial
🧍♂️Population: 6001 patients with HFpEF/HFmrEF
🔎 Stratified by glycaemic status:
Normoglycemia (21%)
Pre-diabetes (33%)
Diabetes (46%)#Cardiology
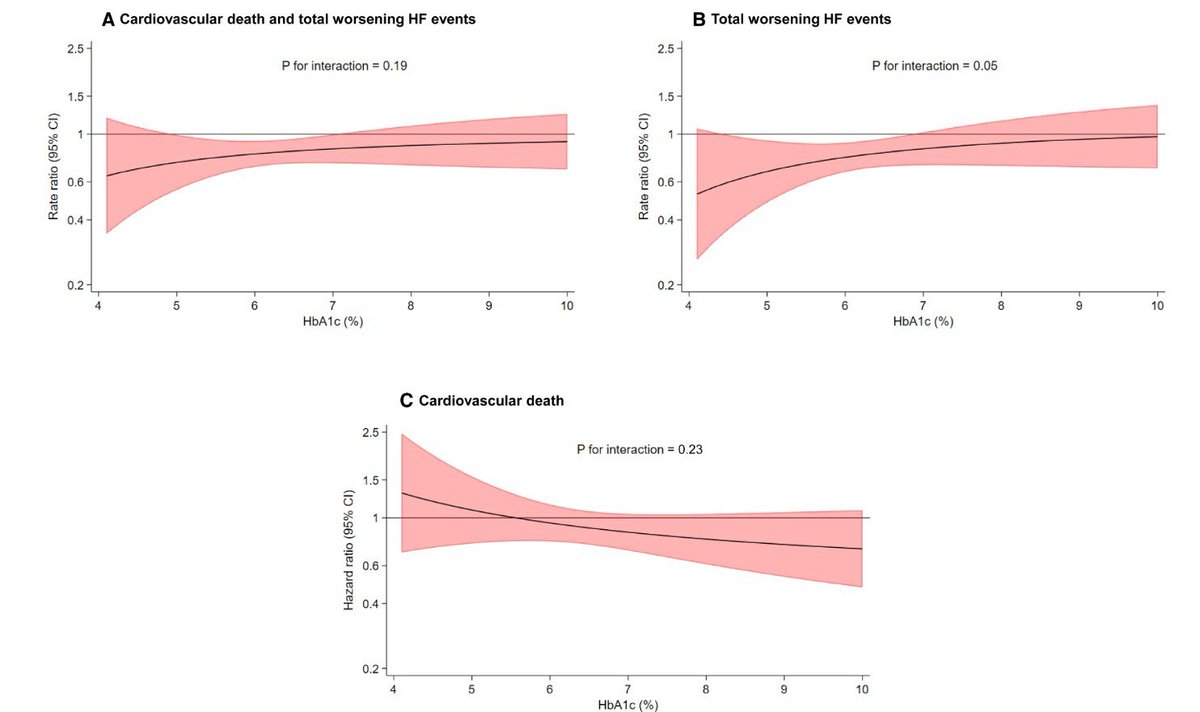
2/🫀 Primary outcome: CV death total worsening HF events
Finerenone significantly reduced risk vs placebo:
➡️ RR 0.84 (95% CI 0.74–0.95; p=0.007)
Consistent benefit across glycaemic categories
📉 No interaction by diabetes status (p=0.93)
#HF #RCT
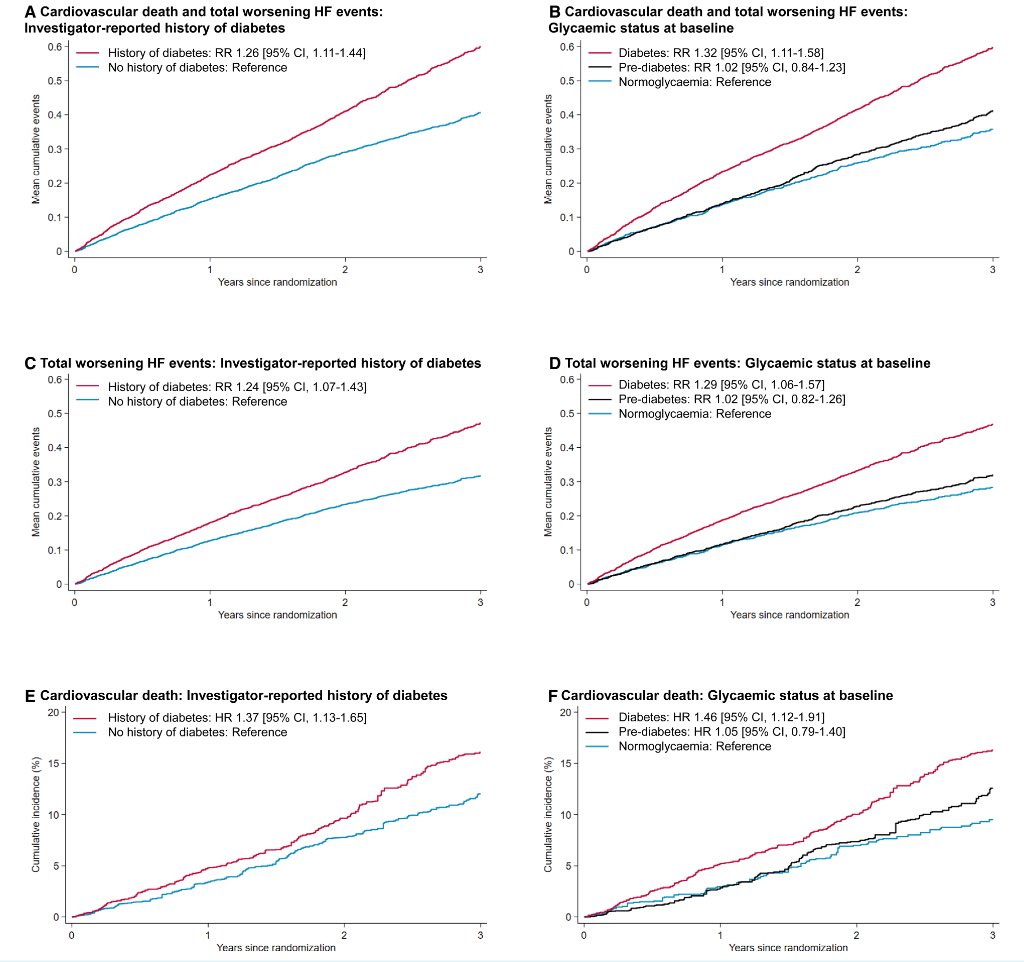
3/🧪 Risk profile by glycaemic status:
Compared to normoglycemia:
Pre-diabetes: No ↑ in risk (RR 1.02 [0.84–1.23])
Diabetes: ↑ risk for all outcomes (RR 1.32 [1.11–1.58])🔁 Trend holds after multivariable adjustment#Diabetes
4/📉 Finerenone benefit per subgroup:
✔️ Normoglycemia: RR 0.85
✔️ Pre-diabetes: RR 0.85
✔️ Diabetes: RR 0.82
🎯 Consistent across CV, renal, and symptom-based outcomes (KCCQ, NYHA)
5/⚠️ Adverse events
↑ Hyperkalaemia and ↓ BP with finerenone
No increase in hypoglycaemia🧑⚕️ Effects consistent regardless of diabetes history#SafetyData
6/📌 Clinical implication:
Finerenone reduces HF events in HFpEF/HFmrEF patients — with or without diabetes.
First trial to show this across the glycaemic spectrum.
✅ Expand MRA use beyond diabetic populations
7/📚 Full article:
Butt et al. Eur J Heart Fail. 2025.
doi: 10.1002/ejhf.3649
#EBM #Cardiology
1
25
54
4,499

11 Nov 2024
Vier jaar nadat de klinische testfases succesvol waren afgerond, met 4 jaar aan safetydata uit de hele wereld, zijn er nog steeds mensen die menen dat er geen bewijs is dat covidvaccins veilig zijn.
En die blijven de vaccins, zonder schaamte, nog steeds "gentherapie" noemen...
4
29

26 Sep 2024
Sun Pharma Presents New Clinical Efficacy and Safety Data in Severe Dermatological Conditions at the 2024 EADV Congress
@SunPharma_Live #SunPharma #ClinicalEfficacy #SafetyData #2024EADVCongress
equitybulls.com/category.php…
2
538
29 Feb 2024
Waarom komt er nou nooit eens iemand met controleerbaar bewijs dat er iets mis is met de covidvaccins?
Waarom kan niet met harde feiten aantonen dat alle safetydata onjuist is?
1
42

29 Feb 2024
From IFU (Instruction for Use) platform on stago.com customers worldwide could visit and download #reagent instructions, #analyser reference manuals and #safetydata sheets.
👉 stago.com/products-services/…
#IFUplatform #InstructionForUse

2
52
28 Feb 2024
The injections with no safetydata were pushed for fertile aged people and in pregnancy. We were silent. The authorities said there's constant safety monitoring. Not true. We were silent. The "official truth" (lies, propaganda) contradicts the reality that I knew as a professional
3
9
44
2,223
15 Jan 2024
I've left my job so I don't have access to the data I trust. The official data may not be reliable. The birthrate has dropped in Finland as well.
It's unethical to promote injections with no safetydata to fertile aged people, children and in pregnancy. And no safety monitoring.
3
15
117
5,717
15 Jan 2024
It's not about IVF, it's about the 💉without safetydata injected to children, fertile aged people, in pregnancy. I'm appealing to the IVF staff because we were supposed to be the fertility experts, but many recommended the unsafe💉, blindly complied, "forgot" ethics, kept silent
2
2
18
1,026

20 Nov 2023
Dr. #PeterMcCullough #summarizing the #latest #safetydata on the #COVID19vaccines rumble.com/v3wngz7-dr.-peter…
62

20 Nov 2023
Dr. #PeterMcCullough #summarizing the #latest #safetydata on the #COVID19vaccines rumble.com/v3wngz7-dr.-peter…
68
9 Nov 2023
From IFU (Instruction for Use) platform on stago.com customers worldwide could visit and download #reagent instructions, #analyser reference manuals and #safetydata sheets.
👉 stago.com/products-services/…
#IFUplatform #InstructionForUse

2
48