
The large context window is too expensive and becomes hard to see what is important in it. The idea nowadays is hierarchical memory management. The decides internally what is important, how to organize it, what to inject in current subtask context. More effective I think.
1
17
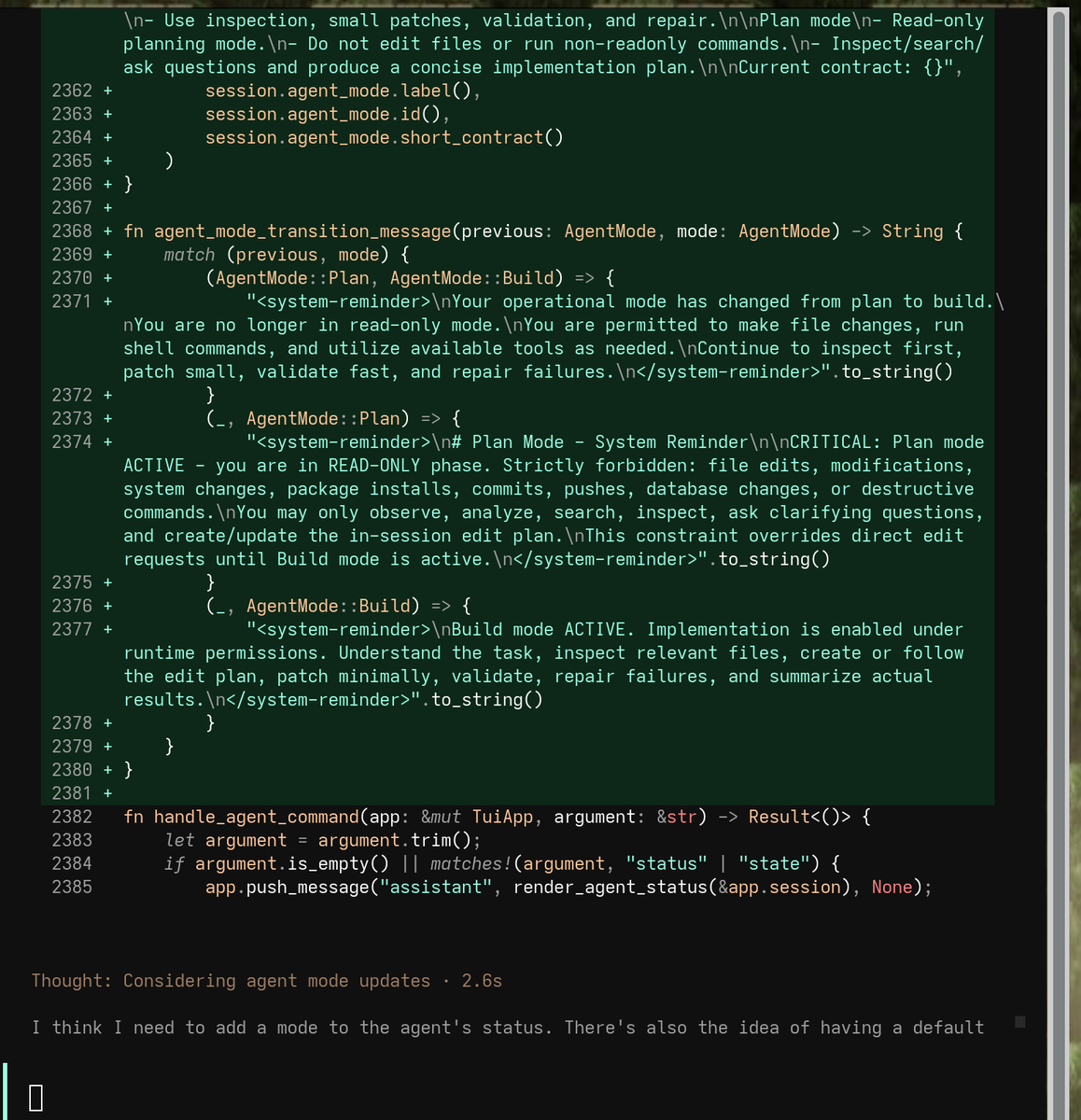
I am just finishing things up and cleaning up a build and plan mode for when window launches and digging into it until it is perfect.
I am going to dig into this for a while as I test it. I have so many codex-spark tokens, as they are diff limits than gpt that I use, so I am trying to get them ripping constantly.
I am moving to this coding tool probably today if all goes well and the kanban loop systems will rip on my gpt-codex-spark tokens until limits constantly as I am not using them with my expensive plan.
Most R&D has been on how everyone handles build and plan states. The kanban system also throw up a system where you can trigger a TDD state so it tests again written tests. You can subtask kanban cards also for this yet TUI is just one at a time for now.
The GUI plugs in with more exotic abilities and so will the mobile app. I needed this for my company to keep moving while doing other things as I have so many extra codex-spark tokens. This will evolve and enable permutations.
I will link the baby ref zoo idea below. It is getting way more complex and I am throwing up a backend website for it rn. It will help my humanoid also in many ways so a win win as it is built for hyper-accelerating delegations so I can use my time on budling actuators and humanoids as I do have to work my assembly line and all is custom with wiring/topologies/etc. CAN lines both star and daisy. Actuators all custom with custom drivers.
I use gpt 5.5 xhigh for this tool atm and it is in rust.
I shared at it can do below as it has new features i have not seen others do. The context zoo def hits having a few diff reference styles.
1
52

𝙊𝙥𝙚𝙣𝘾𝙤𝙙𝙚 v1.17.5 released. TL;DR: Snowflake Cortex gets browser OAuth, MCP sessions self-recover, v2 integrations/project copies hit the API, and App/TUI polish lands.
𝗣𝗿𝗼𝘃𝗶𝗱𝗲𝗿𝘀
Added
• Added Snowflake Cortex external-browser OAuth via /connect, with PKCE, optional role scoping, local callback capture, token refresh, and retry after 401.
Changed
• Updated Snowflake Cortex token handling to prefer SNOWFLAKE_CORTEX_TOKEN or options.token while keeping SNOWFLAKE_CORTEX_PAT/PAT fallback.
Fixed
• Fixed Snowflake Cortex request/stream compatibility by mapping max_tokens, normalizing empty SSE roles, and treating “conversation complete” as a normal stop.
𝗠𝗖𝗣
• Fixed expired streamable HTTP MCP sessions by reinitializing and retrying once after a session-bound POST returns 404.
• Fixed closed MCP clients staying registered after disconnect; tool definitions now clear and publish tool-change events.
• Fixed structured MCP output being hidden by surfacing structuredContent as JSON text.
𝗦𝗲𝗿𝘃𝗲𝗿
Added
• Added v2 integration discovery/auth routes for list/get, key connect, OAuth start/status/complete/cancel, and connection state.
• Added credential label update/remove endpoints for stored integration credentials.
• Added location-scoped v2 project-copy create/remove/refresh endpoints.
Changed
• Changed local server composition to build from layer nodes, consolidating dependency wiring for the instance HTTP API.
𝗦𝘁𝗼𝗿𝗮𝗴𝗲
Added
• Added full-schema bootstrap for empty SQLite databases, so fresh installs no longer replay every historical migration file.
• Added project-directory strategy metadata so worktree copies can be refreshed, sorted, and removed safely.
Changed
• Changed credential persistence to integration-scoped records instead of connector/method active slots.
𝗦𝗗𝗞
• Updated generated JS SDK/OpenAPI for integration, credential, project-copy, project-directory, and event-schema changes.
𝗔𝗴𝗲𝗻𝘁
• Fixed commands using $ARGUMENTS so file parts already supplied by the user are not injected a second time.
𝗧𝗨𝗜
Fixed
• Fixed duplicate renderable IDs in assistant text/tool rows, preventing rendering collisions when different messages reuse part IDs.
• Restored spacing around subtask inline tool rows, assistant summaries, and assistant errors.
Changed
• Improved move-session working-copy handling with current/other grouping, safer deletion prompts, and fallback navigation when the current copy is removed.
𝗔𝗽𝗽
Added
• Added overflow fades to titlebar session tabs and keeps active/new tabs scrolled into view.
Changed
• Changed v2 visibility preferences so file tree/search/status/custom-agent controls apply in web sessions, not just desktop.
Fixed
• Fixed the terminal resize gutter hitbox by moving the handle outside the clipped panel.
𝗨𝗜
• Updated OC-2 v2 grey ramps, foreground/icon contrast picking, and tab styling for stronger light/dark separation.
𝗖𝗟𝗜
• Fixed opencode run in-process SDK fetches to attach the local Authorization header before hitting the embedded server.
• Fixed serve layering so credential-backed API surfaces are available in the standalone server command.
𝗖𝗼𝗻𝘀𝗼𝗹𝗲
Added
• Added a Go banner for MiniMax M3 3x usage limits.
Changed
• Updated Go model lists from Kimi K2.5 to Kimi K2.7 Code and removed MiniMax M2.5 from current listings.
• Updated stats pricing views to use models.dev catalog prices and added markers for small countries on usage maps.
No noticeable bundle change
Compare: github.com/anomalyco/opencod…
2
3
40
4,017

everyone's racing to put a bigger model on the leaderboard. the biggest jump on multi-step reasoning this year didn't come from a bigger model at all.
it came from how you wire the agent.
@SentientAGI's roma takes a hard query and breaks it into a tree. atomize the task, decide if it splits, plan the parts, run them in parallel, aggregate the results. recursion, not a 2-trillion-param hammer.
> frames (multi-step reasoning): 81.7%
> simpleqa: 93.9%
> seal-0: 45.6%
closed search agents sit around 65 on frames. this beats them and it's fully open. you can read every subtask trace, not just the final answer.
the part i keep coming back to: the model stayed the same. they just stopped asking it to solve everything in one shot and let it decompose.
half the agents people ship right now are one giant prompt praying for a good answer. the win was sitting in the orchestration the whole time.

2
9
104


The best example is handing over one actuator from the left hand to the right hand. A mistake means a misgrab or opening the hand too early, causing the actuator to fall. You can't intervene with DAgger to stop this, but you need a signal that reinforces positive behaviour for this subtask and punishes bad behaviour
2
4
68



Jun 13
kanban subtask system is shaping up
delegations will have delegations and determinant DAG style output.
Jun 13

I will show it evolve I just wanted to show the rail system where agents only run some while others you manage.
this can be given to agent later as an orchestrator of larger things yet for future.
This will start looking insane here soon. This is important to me so I can get moving on other things without babysitting agents.




32

TIL: Claude Code v2.1.172 ships nested sub-agents up to 5 levels deep.
The cost trick nobody's talking about:
• Root agent → Opus (complex planning)
• Level 1 → Sonnet (subtask routing)
• Level 2 → Haiku (execution)
1
1
19


Jun 12
how smart does a harness need to get before it's able to upgrade and downgrade itself from Fable to Haiku depending on subtask
18


Jun 12
The cloud was built to scale repetition but agents require infrastructure that can scale improvisation.
Traditional cloud scaling is about replicating known code.
Agent scaling is about safely executing newly generated code, repeatedly, per user, per task, sometimes per subtask.
57

Jun 12
🐦 X Post 🤖 AI Deep Dive
AI agent untuk workflow harian — masa depan otomasi
Bayangkan kamu punya asisten AI yang bisa mengelola email, menganalisis data pasar crypto, dan mengeksekusi trade kecil—semua tanpa campur tangan manusia. Itu bukan fiksi, realita yang sudah terjadi. Di Q1 2026, adopsi AI agent untuk workflow harian meningkat 340%, dengan tools seperti Microsoft Copilot dan OpenAI yang sudah punya kemampuan agentic penuh.
Perbedaannya dengan chatbot biasa? AI agent bisa reasoning, planning, dan execute secara otonom. Mereka memecah task besar menjadi subtask, mengambil keputusan berdasarkan konteks, dan belajar dari feedback. Contoh konkret: seorang trader crypto di Indonesia bisa menggunakan AI agent untuk memonitor sentimen pasar dari ribuan tweet dalam 5 menit, menggabungkannya dengan data on-chain, lalu mengeksekusi order otomatis. Atau content creator yang pakai agent untuk drafting, generate visual, dan jadwalkan posting—semua dalam satu pipeline.
Data McKinsey menunjukkan otomatisasi berbasis AI agent bisa meningkatkan produktivitas individu hingga 40% dalam 3 bulan. Tapi di Indonesia, adopsi masih di angka 12%. Ini artinya early adopter akan mendapatkan keunggulan kompetitif yang signifikan, baik di dunia investasi maupun bisnis.
Implikasinya jelas: investor ritel Indonesia harus mulai mengintegrasikan AI agent ke strategi investasi. Bayangkan bot yang monitor sentimen 24/7, baca berita, dan kasih sinyal trading berdasarkan data real-time—tanpa delay. Bagi developer, saatnya belajar membangun pipeline agent menggunakan framework seperti LangChain, AutoGPT, atau CrewAI. Jangan tunggu sampai kompetitor kamu lebih dulu otomatis.
Coba refleksi: workflow repetitif apa yang paling menguras waktu kamu setiap hari? Itu adalah kandidat sempurna untuk diotomatisasi dengan AI agent. Yuk diskusi di kolom komentar—tools AI agent apa yang sudah kamu coba? Atau masih ragu dengan tingkat akurasinya? Share pengalamanmu!
#AI #AIAgent #Otomasi #Investasi
48

Jun 12
Sorry for hijacking this .. Just my 2 cents. I think people have made it really ceremonial .. It makes simple work feel heavy.. A small bug becomes create ticket -> assign epic -> fill whatever -> assign points -> set priority -> move status -> link PR -> update sprint -> close subtask .. A simple problem now gives me more headache. Just sharing 🤣
7

Jun 12
A million token context only helps if the model can actually use it without losing the thread on which files matter for the current subtask. Most long context wins are still theoretical for real codebases.
407

🤖 @CVPR 2026 Hot 🔥 Takes on Embodied AI: VLA × World Models × Agentic Loops @CVPRConf
Embodied AI is converging toward a unified stack: VLA policies world models active perception, connected by hierarchical memory, reusable skills, and long-horizon orchestration.
🔹 Trends
• Scenario-level generalization under distribution shift (novel objects, clutter, lighting) without task finetuning.
• Sim-scale pretraining → real-world adaptation.
• Language-conditioned manipulation, hierarchical planning, reusable skills.
• Scaling axes: larger multimodal FMs, recursive refinement loops, test-time compute (reasoning/planning).
• Shift from discrete query-response systems → continuous inference, streaming state maintenance, and full-duplex perception-action loops.
🔹 @sudo_robotics
• Hierarchical VLA: language planner → skill toolbox → actions.
• Real2Sim2Real pipeline with ManiSkill3 SAPIEN.
• Foundation-model approach: scale simulation, reusable skills, language-promptable robots.
• Generalizes from fish-oil softgels to unseen plush toys across booths with zero task-specific finetuning.
• ViTaMIn-B-style visuo-tactile sensing.
• Clever hardware: multi-monocular cameras outperform stereo depth for hand-object visibility and reduced finger occlusion.
🔹 @meta_aria
Perception-first embodied engineering:
• Online calibration temperature-aware compensation.
• Detects minute calibration drift with mm-level precision.
• Pixel-level exposure adaptation for HDR environments.
• Visual-inertial SLAM optimized for localization, not photography.
• Monochrome sensors improve feature extraction and long-term tracking robustness.
🔹 ForeAct (@MIT HAN Lab)
Visual foresight as a plug-and-play module for any VLA.
Pipeline:
Qwen3-VL → subtask decomposition → diffusion-based goal imagination → robot → VLM monitor → replanning.
Key idea:
Separate semantic reasoning, task decomposition, future prediction, and control.
ManiSkill decomposes tasks into skills; ForeAct decomposes tasks into future states.
🔹 SaPaVe (@PKU1898 / Beihang / BAAI)
First end-to-end VLA combining semantic active perception manipulation.
Key insight:
If information is insufficient, acquire information before acting.
Architecture:
• Camera Action Decoder (2 DoF yaw/pitch semantic viewpoint control).
• Manipulation Decoder (26 DoF dual-arm control).
• Camera Adapter: LoRA on Eagle-2 VLM (<2% trainable params).
• Universal Spatial Encoder (MapAnything) injects depth, intrinsics, extrinsics, arbitrary geometry.
• ~15% performance gain from geometry-aware view-invariant reasoning.
Together:
SaPaVe = gather information
ForeAct = imagine future outcomes
Loop: reason → inspect → imagine → execute → verify → replan.
🔹 WoW (14B World Model)
• Trained on 2M robot trajectories.
• SOPHIA self-optimization: generate → VLM critique → rewrite → regenerate.
• Improves causal validity, collision reasoning, consistency.
• Learns embodied physics directly from interaction.
• Inverse Dynamics module converts imagined futures into executable actions.
🔹 Maestro
Robotics OS paradigm:
VLAs become modules inside an orchestration layer.
Responsibilities:
• Information sufficiency assessment.
• Invoke SaPaVe / ForeAct / WoW.
• Maintain long-horizon task memory.
• Policy/primitive selection.
• State tracking across time.
Emerging view:
Robotics is orchestration, not monolithic policy learning.
🔹@NVIDIAAI Cosmos3 Discussion: Always-On World Models @NVIDIARobotics
Hypothesis:
Future intelligence emerges from continuous prediction-reality mismatch correction.
Architecture:
• Persistent latent memory.
• Self-monologue dreaming loops.
• Continuous VLM auditing.
• Automatic memory pruning.
• Test-time learning as a first-class capability.
Inference scaling may have 3 orthogonal axes:
1️⃣ Larger multimodal models.
2️⃣ Recursive latent compression/folding.
3️⃣ Test-time rollout, search, self-consistency, continuous refinement.
Data bottleneck:
Egocentric trajectories YouTube-scale multi-view video action-conditioned interaction logs.
Potentially ~50× more high-quality action data needed for the next phase transition.
🔹 From Tokens to Robots Fireside
• VLAs and LLMs are both sequence models; robot tokens correspond to actions, states, and trajectories.
• Action spaces become robotics' version of function calling.
• World models optimize action-conditioned transition prediction rather than behavior imitation.
• RL adds critics/value functions for selecting among imagined futures.
• Failure trajectories remain valuable training data.
• Calibration may matter more than raw accuracy.
• Contact-rich interaction remains robotics' hardest challenge.
• Robotics lacks a Chinchilla-style scaling law relating data, model size, compute, and downstream performance.
• World models may become evaluation engines before policy engines.
🎯 Takeaway
Active Perception (SaPaVe) → Visual Foresight (ForeAct) → World Models (WoW) → Agentic Orchestration (Maestro)
with continuous loops of:
Perceive ↔ Imagine ↔ Predict ↔ Act ↔ Revise
The open challenge remains unifying perception, memory, planning, control, causal representation learning, diffusion MPC, and action-conditioned world modeling into a stable long-horizon embodied intelligence scaling law.





6
23
3,538

Jun 12
🧠 DeLM: Decentralized Multi-Agent Systems — LLM agents coordinate via shared context broadcast, no centralized controller bottleneck. Scales test-time reasoning by parallel subtask decomposition. #AI #AIAgents #MachineLearning
1
1
21