
Computer Vision and Pattern Recognition News
Joined September 2018
- Tweets 2,146
- Following 732
- Followers 14,968
- Likes 5,055
25 Photos and videos








CVPR News retweeted

CVPR 2026 Embodied AI Highlight Papers
Active Perception · Visual Foresight · Embodied Cognitive Loops
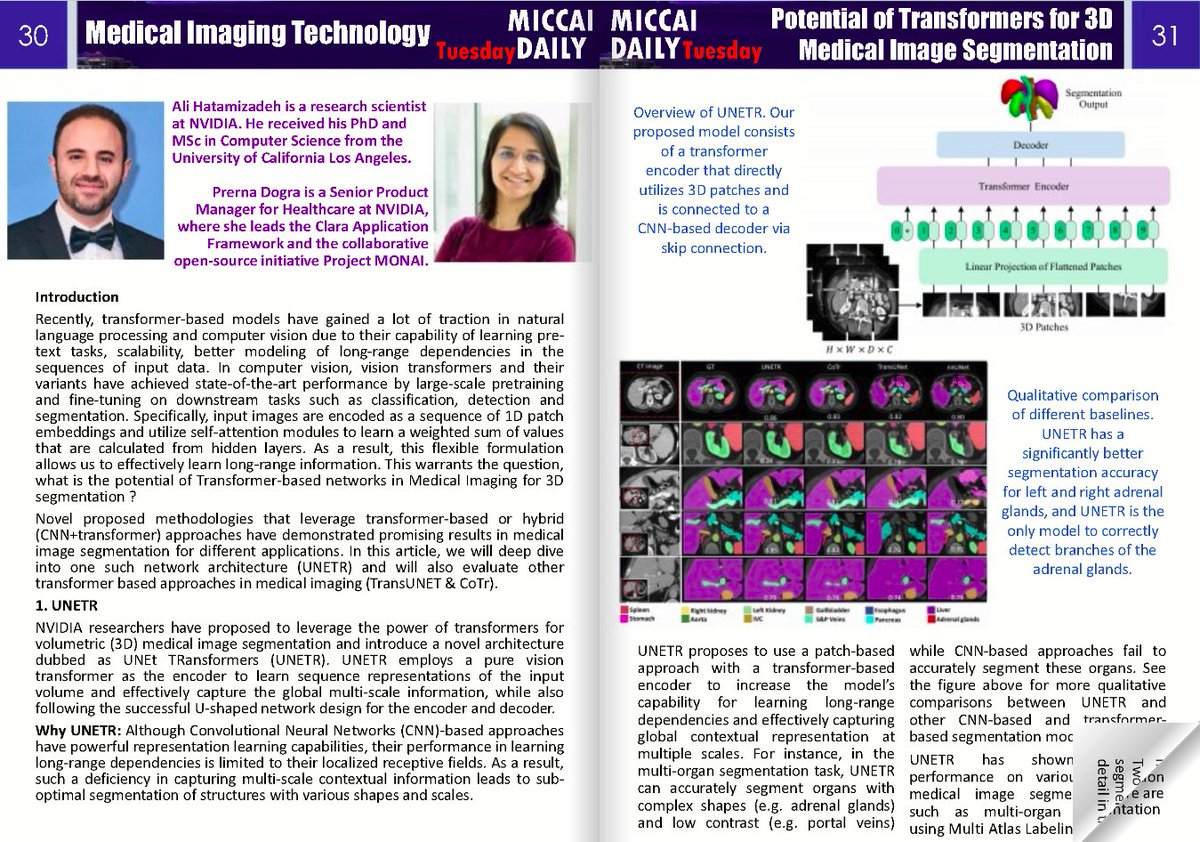
1. ForeAct (MIT HAN Lab, Zhuoyang Zhang, Shang Yang et al., arXiv:2602.12322, github.com/mit-han-lab/forea…)
ForeAct delivers efficient visual foresight that steers any VLA via atomic visual goal imagination.
It addresses the failure mode where sufficient information already exists, but explicit future grounding is missing.
If SaPaVe answers: Do I know enough to act?
ForeAct answers: Now that I know enough, what exactly should success look like?
The core argument: existing VLAs are overloaded. They simultaneously perform: semantic reasoning, task decomposition, future prediction, visuo-motor control.
ForeAct explicitly separates these responsibilities.
This resembles skill-library systems such as ManiSkill in spirit, but with a different abstraction:
ManiSkill decomposes tasks into reusable skills;
ForeAct decomposes tasks into reusable future states.
Unlike Sudo-style systems that reduce VLAs into lightweight coordinators over primitives, ForeAct keeps the VLA intact and steers it via visual foresight.
Closed loop pipeline:
Qwen3-VL → subtask → ImGen → robot (multi-cam) → VLM monitor / re-plan
(finer granularity than ManiSkill skills; no VLA replacement, unlike Sudo-style coordination layers)
2. SaPaVe (Mengzhen Liu, Enshen Zhou et al., PKU / Beihang / BAAI, arXiv:2603.12193)
SaPaVe delivers the first end-to-end VLA unifying semantic active perception and manipulation via explicit decoupling.
It addresses insufficient information before action.
I was surprised that the human-like paradigm:
“Look again, look closer, look left and right”
(combining perception action)
was not already well-established in VLAs—it is extremely natural for embodied intelligence.
Core insight
SaPaVe solves the regime where robots lack: occlusion understanding, grasp affordances, articulation state,
action success certainty.
Existing VLAs operate under passive perception: fixed camera viewpoints, direct manipulation prediction from static observations.
However, active perception introduces a key coupling problem: moving the camera changes observations, manipulating objects changes observations, reorienting objects changes observations.
Traditional unified action spaces entangle: camera motion objectives, manipulation objectives.
SaPaVe resolves this via explicit decoupling.
Decoupled design
Embodied intelligence becomes a two-branch decision process:
- test information sufficiency
- if sufficient → act; if insufficient → active information acquisition.
SaPaVe ForeAct together instantiate this loop:
reason → gather info → imagine futures → execute → verify → re-plan
(vs traditional perceive → act)
SaPaVe architecture
Camera Action Decoder: 2 DoF (pitch yaw), embodiment-agnostic semantic viewpoint control, supports: “look left / zoom / inspect behind”
Manipulation Action Decoder: 26 DoF joint positions, dual-arm dexterity
Decoupled heads outperform unified decoder (71.25% vs lower baseline)
Camera / perception modules
Camera Adapter: LoRA on Eagle-2 VLM, <2% trainable parameters, learns semantic active perception priors, preserves base manipulation knowledge
Universal Spatial Encoder (MapAnything): injects depth intrinsics extrinsics arbitrary geometry, element-wise fused into VLM tokens & action head during denoising, enforces view-invariant 3D consistency, improves performance by ~15% even on simple tasks.
3. Long-horizon cognition: WoW (arXiv:2509.22642)
WoW is a 14B embodied world model trained on 2M robot trajectories (not passive video).
Key mechanism: SOPHIA self-optimizing loop: generate,
VLM critique (physical causal validity), rewrite, regenerate.
This improves: consistency, collision reasoning, causal validity.
Unlike video-only world models, WoW learns physical dynamics directly from embodied interaction.
It also introduces Inverse Dynamics → executable actions, achieving SOTA on manipulation simulation and real Franka setups.
Overall implication: embodied pretraining may function as meta-learning for intuitive physics.
4. Agent OS / Robotics orchestration: Maestro (maestro-robot.github.io)
Maestro reframes VLAs as modules inside a robot operating system layer.
This OS layer is responsible for: deciding information sufficiency, invoking SaPaVe / ForeAct / WoW, tracking long-horizon state, selecting primitives / policies, maintaining task memory across time
Pure VLAs remain weak at long-horizon reasoning.
Missing system components (explicit gaps): causal latent learning (MPI-style), Diffusion MPC, tighter integration between generative world models and real-time control.
Related systems (e.g., Dexmate) similarly argue for: representation layers, world models, agentic harnesses, modular execution systems.
The emerging paradigm: robotics as orchestration, not monolithic policy learning
Conclusion
SaPaVe (information acquisition layer): semantic active perception, embodiment-agnostic camera control, decoupled action modeling, geometry-aware viewpoint reasoning.
ForeAct (future grounding layer): atomic subtask decomposition, visual goal imagination, efficient diffusion-based foresight, plug-and-play steering of existing VLAs.
System stack: Above both layers sit: embodied world models (WoW), agentic orchestration frameworks (Maestro), representation-centric architectures (Dexmate)
Likely missing ingredients to close the loop: causal latent representation learning, diffusion-based model predictive control, MPI-style causal world modeling frameworks.
@CVPR @CVPRConf @saturdayrobotic #CVPR2026




CVPR 2026 — Embodied AI Takeaways @CVPRConf @CVPR
Embodied AI converges along three coupled axes: VLA policies, world models, agentic perception-action loops, linked via hierarchical memory skill composition.
🤖 Robotics shows scenario-level generalization under distribution shift (novel objects, clutter, lighting variation), incl. unseen household items long-tail tabletop objects, often without task finetuning.
Common pattern:
sim-scale pretraining real adaptation
language-conditioned manipulation policies
hierarchical planning reusable skills
ManiSkill-style benchmark ecosystems
Trend: compositional policies simulation-scaled pipelines; cross-embodiment transfer remains open.
👓 Meta Aria = perception-first SLAM engineering
SLAM-first embodied sensing design co-optimizes hardware algorithms for stability over imaging.
Key priorities:
online calibration drift correction
illumination robustness
visual-inertial SLAM primary objective
per-sensor consistency for long-term tracking
Optimized for continuous egocentric state estimation, not photography.
🌍 World models & agentic systems converge conceptually
Shared abstraction: prediction–observation mismatch correction in continuous loops.
Design directions:
streaming latent state updates
persistent memory / belief revision
anomaly-driven representation correction
tight perception–imagination–action coupling
Shift: discrete I/O → continuous inference continuous state maintenance.
📈 Scaling axes:
larger multimodal foundation models
recursive / iterative refinement loops
test-time computation scaling (reasoning planning)
Shift: model size scaling forward dynamics quality inference-time adaptation.
🎙 Continuous interaction models
Move beyond turn-taking:
low-latency streaming speech (Moshi-style)
overlap-tolerant dialogue
continuous embodied perception-action loops
Toward full-duplex systems with persistent internal state vs query-response cycles.
🦾 Robot “OS” = hierarchical orchestration
Long-horizon manipulation remains hard under flat policies.
Stack:
high-level planners (language/symbolic/latent)
mid-level skill libraries (reusable primitives)
low-level reactive control
Active perception:
query environment under uncertainty
manipulate to reduce ambiguity
update belief before action
🧭 Synthesis:
reactive policies → agentic systems with persistent world models
Integration:
world models VLA
active perception uncertainty-aware control
simulation scaling real adaptation
continuous interaction streaming inference
🧩Summary:
Embodied AI is moving toward systems that continuously perceive, maintain internal state, and iteratively refine predictions via environment interaction.
Open problem: unifying perception, memory, planning, control into stable long-horizon agent loops.
#CVPR2026 #EmbodiedAI #WorldModels #Robotics #VLA #AgenticAI




6
44
5,016
CVPR News retweeted
🌌 @saturdayrobotic @CVPR 2026 Robotics Research Night Recap: World Models, Physical AI & Embodied Intelligence @CVPRConf
👉🏻YouTube: youtube.com/live/P_3gSC-5cYM…
👉🏻Luma: luma.com/zamm9g2g
6 Lightning talks:
🤖 @neuralmotion — NM-GenET
@aurorafeng_01 introduced NM-GenET, a generative video-action model for universal embodiment transfer and cross-domain policy learning. The goal is to enable policies learned on one robot, morphology, or environment to generalize across embodiments and domains through video-action generation.
🌍 @NVIDIAAI Cosmos 3
@mli0603 Zhaoshuo Li unveiled Cosmos 3, NVIDIA's next-generation omnimodal world model.
Built on a Mixture-of-Transformers architecture with parallel autoregressive and diffusion pathways, Cosmos 3 jointly processes and generates language, image, video, audio, and action sequences within a single model.
The same backbone supports:
• Vision reasoning
• Image/video/audio generation
• Forward dynamics prediction
• Inverse dynamics inference
• Robot policy control
A particularly impressive capability is explicit spatial grounding combined with structured action generation, allowing the model to identify task-relevant objects, reason about spatial relationships, and generate executable robot trajectories in cluttered scenes.
Cosmos 3 positions omnimodal world models as a foundation model for Physical AI, unifying understanding, generation, simulation, reasoning, and control.
🧠 WALL-WM (@XSquareRobot)
Xiaofan Li presented WALL-WM, a World Action Model built around event-level Vision-Language-Action pretraining.
Instead of predicting fixed-length action chunks, WALL-WM treats semantic events as the atomic unit of world modeling.
Core transition:
Next Chunk Prediction → Next Event Prediction
By aligning language, perception, and action around event representations, WALL-WM aims to better capture real-world temporal structure while preserving pretrained multimodal priors.
The architecture supports both:
• Language-guided event reasoning
• Event-centric world simulation
This represents a shift from modeling "what action follows this frame window" to modeling "what event is unfolding in the world."
📐 Test-Time Scaling for World Action Models
@SourORZ1 Zesen Zhao (@UMich) presented a training-free verification framework for World Action Models.
Key insight:
Predicted futures should be geometrically consistent across multiple camera views.
Using frozen VGGT depth estimation and cross-view reprojection consistency, the system performs Best-of-N rollout selection without additional training or robot rollouts.
The broader argument is that geometry remains largely implicit in current VLAs and WAMs, making depth a potentially important next scaling axis for Physical AI.
📊 Toward a Robotics MMLU
@JieWang_ZJUI (@Penn @GRASPlab) argued that robotics lacks an equivalent of MMLU.
While robot policies increasingly resemble foundation models, evaluation remains fragmented across hundreds of incompatible benchmarks.
• Decomposable capability axes
• Reproducible evaluation protocols
• Distributed evaluator networks
• Generalization-first benchmarking
A recurring observation was that tiny distribution shifts—camera placement, lighting, human interaction variations—can still collapse state-of-the-art policies.
🎥 Diffusion-DRF
@guocheng_qian (@Snap) presented Diffusion-DRF, a new post-training paradigm for video diffusion models.
Instead of relying on scalar rewards, Diffusion-DRF converts VLM-generated explanations and token probabilities into dense differentiable rewards that provide spatially and semantically precise credit assignment.
Key result:
Training remains stable beyond 3,000 steps, significantly outperforming conventional GRPO-style video RL approaches that often collapse after only a few hundred iterations.
The broader implication is that VLMs may evolve from evaluators into credit-assignment engines for video generation and future world models.
💡Summary
• World models are moving from frame/chunk prediction toward semantic event prediction.
• Omnimodal architectures are beginning to unify perception, reasoning, simulation, and control.
• Test-time scaling is becoming increasingly important for embodied systems.
• Geometry and depth may become foundational modalities rather than auxiliary signals.
• Evaluation remains one of the largest bottlenecks for robotics foundation models.
• Post-training and inference-time optimization are emerging as critical scaling dimensions alongside model size and data scale.
Converging toward continuously operating world models that can perceive, predict, reason, simulate futures, detect mismatches with reality, and update themselves in an ongoing loop.
The future may look like an always-on interaction system built around persistent world modeling.




3
7
35
4,362
CVPR News retweeted
🤖 @CVPR 2026 Hot 🔥 Takes on Embodied AI: VLA × World Models × Agentic Loops @CVPRConf
Embodied AI is converging toward a unified stack: VLA policies world models active perception, connected by hierarchical memory, reusable skills, and long-horizon orchestration.
🔹 Trends
• Scenario-level generalization under distribution shift (novel objects, clutter, lighting) without task finetuning.
• Sim-scale pretraining → real-world adaptation.
• Language-conditioned manipulation, hierarchical planning, reusable skills.
• Scaling axes: larger multimodal FMs, recursive refinement loops, test-time compute (reasoning/planning).
• Shift from discrete query-response systems → continuous inference, streaming state maintenance, and full-duplex perception-action loops.
🔹 @sudo_robotics
• Hierarchical VLA: language planner → skill toolbox → actions.
• Real2Sim2Real pipeline with ManiSkill3 SAPIEN.
• Foundation-model approach: scale simulation, reusable skills, language-promptable robots.
• Generalizes from fish-oil softgels to unseen plush toys across booths with zero task-specific finetuning.
• ViTaMIn-B-style visuo-tactile sensing.
• Clever hardware: multi-monocular cameras outperform stereo depth for hand-object visibility and reduced finger occlusion.
🔹 @meta_aria
Perception-first embodied engineering:
• Online calibration temperature-aware compensation.
• Detects minute calibration drift with mm-level precision.
• Pixel-level exposure adaptation for HDR environments.
• Visual-inertial SLAM optimized for localization, not photography.
• Monochrome sensors improve feature extraction and long-term tracking robustness.
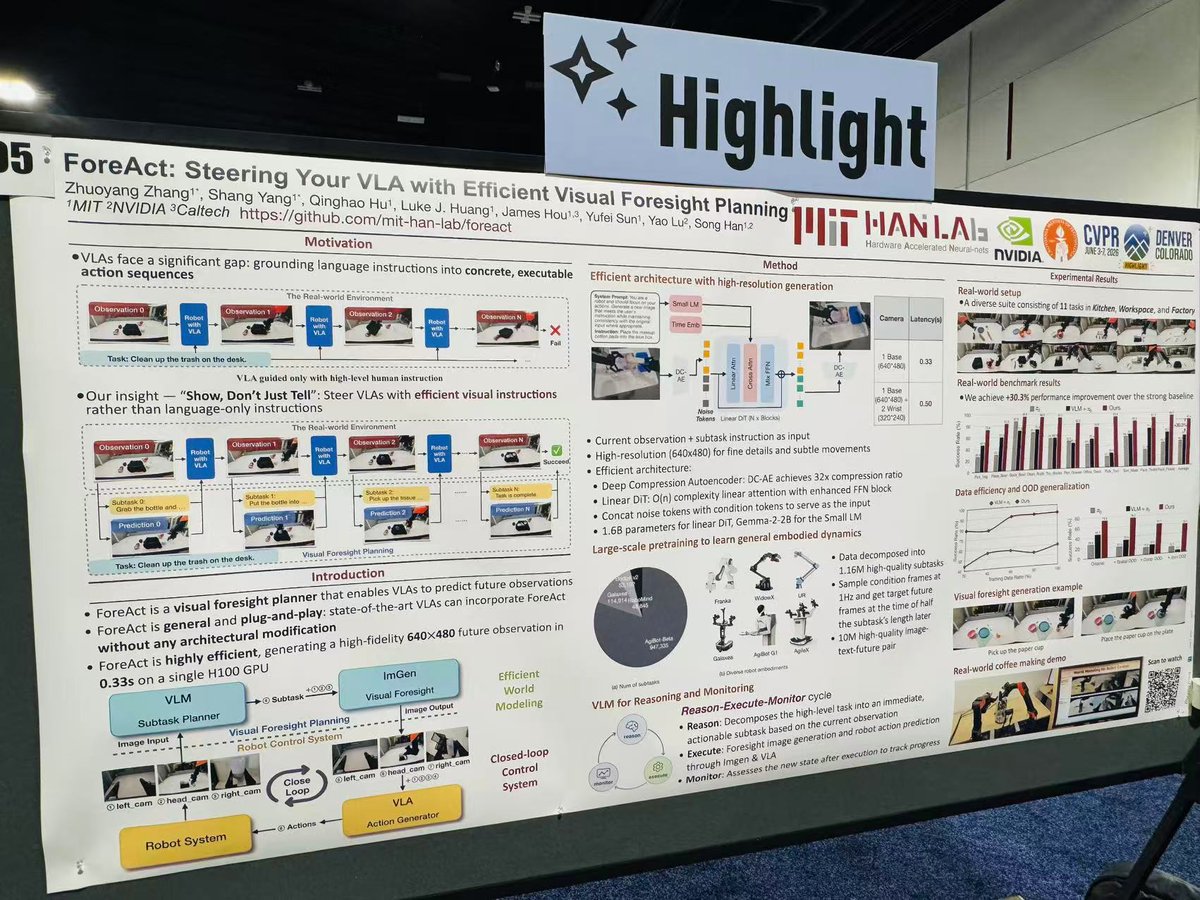
🔹 ForeAct (@MIT HAN Lab)
Visual foresight as a plug-and-play module for any VLA.
Pipeline:
Qwen3-VL → subtask decomposition → diffusion-based goal imagination → robot → VLM monitor → replanning.
Key idea:
Separate semantic reasoning, task decomposition, future prediction, and control.
ManiSkill decomposes tasks into skills; ForeAct decomposes tasks into future states.
🔹 SaPaVe (@PKU1898 / Beihang / BAAI)
First end-to-end VLA combining semantic active perception manipulation.
Key insight:
If information is insufficient, acquire information before acting.
Architecture:
• Camera Action Decoder (2 DoF yaw/pitch semantic viewpoint control).
• Manipulation Decoder (26 DoF dual-arm control).
• Camera Adapter: LoRA on Eagle-2 VLM (<2% trainable params).
• Universal Spatial Encoder (MapAnything) injects depth, intrinsics, extrinsics, arbitrary geometry.
• ~15% performance gain from geometry-aware view-invariant reasoning.
Together:
SaPaVe = gather information
ForeAct = imagine future outcomes
Loop: reason → inspect → imagine → execute → verify → replan.
🔹 WoW (14B World Model)
• Trained on 2M robot trajectories.
• SOPHIA self-optimization: generate → VLM critique → rewrite → regenerate.
• Improves causal validity, collision reasoning, consistency.
• Learns embodied physics directly from interaction.
• Inverse Dynamics module converts imagined futures into executable actions.
🔹 Maestro
Robotics OS paradigm:
VLAs become modules inside an orchestration layer.
Responsibilities:
• Information sufficiency assessment.
• Invoke SaPaVe / ForeAct / WoW.
• Maintain long-horizon task memory.
• Policy/primitive selection.
• State tracking across time.
Emerging view:
Robotics is orchestration, not monolithic policy learning.
🔹@NVIDIAAI Cosmos3 Discussion: Always-On World Models @NVIDIARobotics
Hypothesis:
Future intelligence emerges from continuous prediction-reality mismatch correction.
Architecture:
• Persistent latent memory.
• Self-monologue dreaming loops.
• Continuous VLM auditing.
• Automatic memory pruning.
• Test-time learning as a first-class capability.
Inference scaling may have 3 orthogonal axes:
1️⃣ Larger multimodal models.
2️⃣ Recursive latent compression/folding.
3️⃣ Test-time rollout, search, self-consistency, continuous refinement.
Data bottleneck:
Egocentric trajectories YouTube-scale multi-view video action-conditioned interaction logs.
Potentially ~50× more high-quality action data needed for the next phase transition.
🔹 From Tokens to Robots Fireside
• VLAs and LLMs are both sequence models; robot tokens correspond to actions, states, and trajectories.
• Action spaces become robotics' version of function calling.
• World models optimize action-conditioned transition prediction rather than behavior imitation.
• RL adds critics/value functions for selecting among imagined futures.
• Failure trajectories remain valuable training data.
• Calibration may matter more than raw accuracy.
• Contact-rich interaction remains robotics' hardest challenge.
• Robotics lacks a Chinchilla-style scaling law relating data, model size, compute, and downstream performance.
• World models may become evaluation engines before policy engines.
🎯 Takeaway
Active Perception (SaPaVe) → Visual Foresight (ForeAct) → World Models (WoW) → Agentic Orchestration (Maestro)
with continuous loops of:
Perceive ↔ Imagine ↔ Predict ↔ Act ↔ Revise
The open challenge remains unifying perception, memory, planning, control, causal representation learning, diffusion MPC, and action-conditioned world modeling into a stable long-horizon embodied intelligence scaling law.




6
23
3,520
CVPR News retweeted

#CVPR2026AIST
The AIST Sponsor Booth at #CVPR2026 has successfully wrapped up!
Thank you to everyone who visited our booth, shared ideas, and connected with us throughout the conference.
We’d love to hear about your experience, interests, and future collaboration opportunities. Let’s keep the conversation going and create more opportunities together in the future.

5
25
3,957
CVPR News retweeted

Jun 4
Third talk at our BigMAC workshop is from @CordeliaSchmid of @Inria and @Google. She showed Minerva, a new very difficult video VQA dataset, GROVE, a scalable grounded video caption generation method and temporal CoT. All methods leveraging strong pretrained models



3
10
1,020
CVPR News retweeted

Jun 4
Presenting in ExHall A at CVPR board 67, do visit us.
2
7
787
CVPR News retweeted

Jun 4
Noah Snavely @Jimantha is currently giving a talk at the 4D Vision workshop! Happening at room 506.


Jun 2

The 2nd 4D Vision Workshop at CVPR is happening this Thursday afternoon in Room 506!
Come join us to see the latest progress in modeling the dynamic world. Looking forward to seeing you there! #CVPR2026 #CVPR

2
3
24
4,130

✈️ Denver bound for #CVPR2026!
Bringing a set of projects pushing toward interactive embodied agents: spanning dexterous bimanual motion, generative priors for whole-body control, and humanoid sim-to-real.
Looking forward to conversations, questions, and new ideas! Here’s where to find me:
InterPrior
🔗 sirui-xu.github.io/InterPrio…
🕟 Jun 6 (Sat), 16:15–18:45
📍 ExHall A & F 194
HandX
🔗 handx-project.github.io/
🕥 Jun 5 (Fri), 10:15–12:45
📍 ExHall A & F 210
I’ll also be around several workshops, including:
Spotlight Talk @ H2R
🔗 agents-in-interactions.githu…
🕝 Jun 4 (Thu), 15:00–15:15
📍 Mile High 2A
Come say hi! 🚀
1
15
85
5,592
CVPR News retweeted

Jun 3
Just arrived at Denver for CVPR!
I will be presenting LoGeR at e2e3d.github.io/poster.html 5pm today and 4dvisionworkshop.github.io 4:30pm tomorrow (oral talk). Stop by if you are interested!

1
3
42
2,334
CVPR News retweeted


3
7
1,458
CVPR News retweeted

we got the best paper award at the @CogVLWorkshop 🧠!!
but what made me happier was this photo with almost all authors!!
it's not often that people from so many different places come together, at the same time, and taking photo together like this 🥹
thank youu @CVPR #CVPR2026❤️



relsim has been accepted to #CVPR 2026; yay!!
hope to see you in Denverr
thaoshibe.github.io/relsim/
4
5
54
6,413


CVPR News retweeted

Jun 4
Georgia Gkioxari in room 111 now presenting at MULA workshop


1
3
15
1,182
CVPR News retweeted

One hour to go: join us in mile high 4AB for AI for Visual Arts Workshop and Challenges at 8:30 AM. You won’t want to miss this with the keynotes, orals and posters we have selected. @CVPR

5
9
1,374
CVPR News retweeted

We have @dana_arad4 talking now. We are super excited !!!
Come catch her talk at room EF in milehigh ballroom

1
4
7
599
CVPR News retweeted

Jun 4
Prof @liuziwei7 talking at our 3DMV workshop @CVPR #CVPR2026 describing the latest on multi-view diffusion models


Jun 4

7
18
3,090
CVPR News retweeted

Busy day today at #CVPR2026!
Co-organizing the EgoVis Workshop (all day in Room 704/706), and giving a talk at the VITA workshop at 17.
We then have a bunch of presentations, including Luigi's oral at EgoVIs at 09:30.
All activities here: coai-iplab.github.io/media/c…
Come say hi!




1
6
493
CVPR News retweeted

First Workshop on 4D World Models: Bridging Reconstruction and Generation happening now at @CVPR . We have great line of speakers.
📍Come to Room 203!


5
22
2,805
CVPR News retweeted
Jun 4
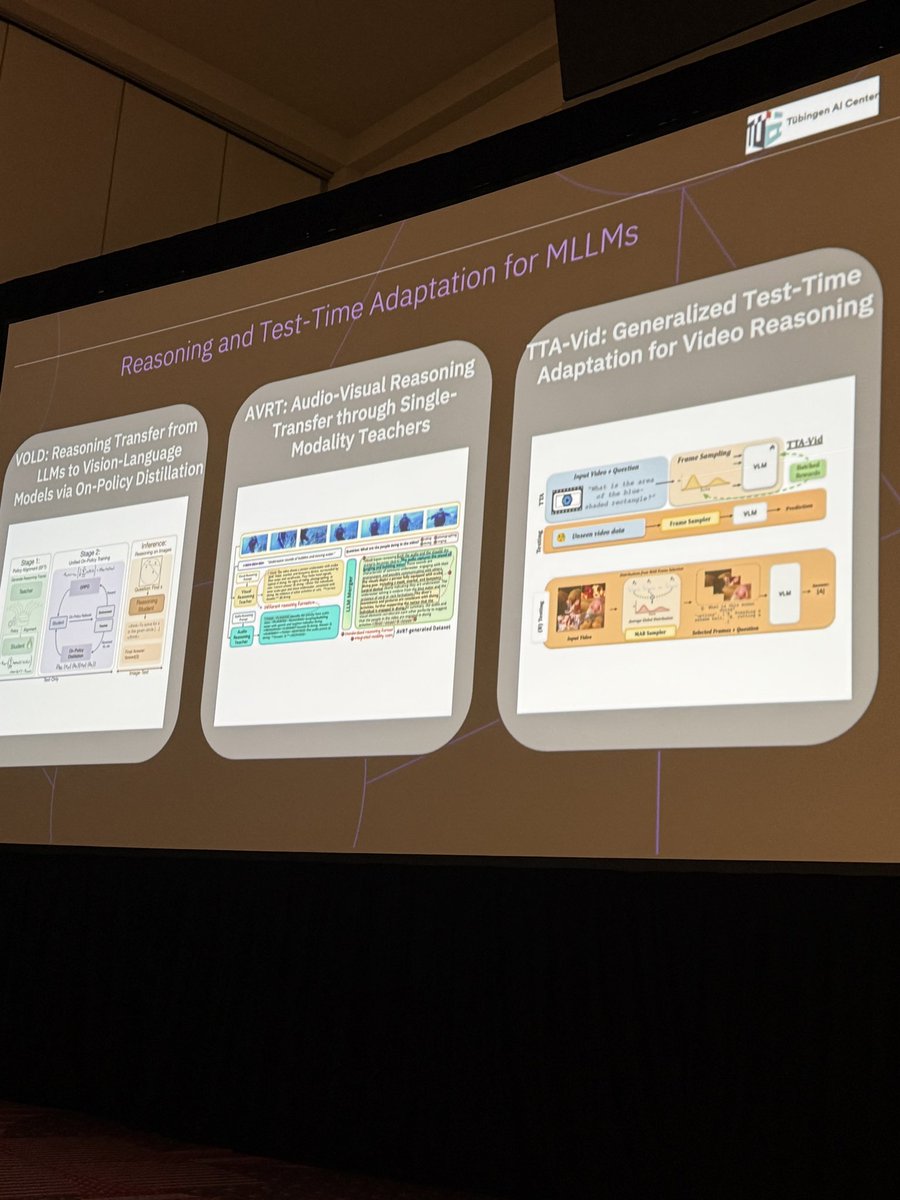
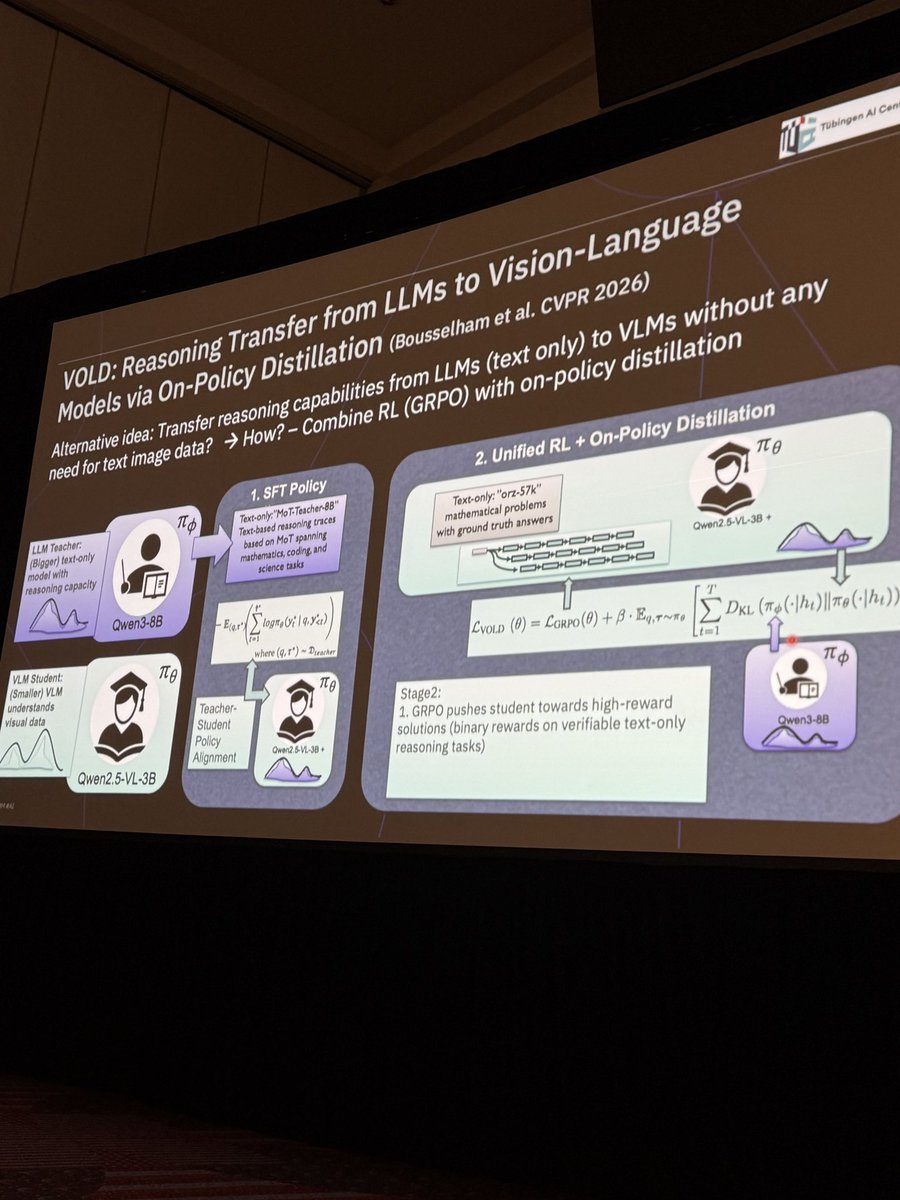
After the break (all bigmacs have been eaten), we continue with @HildeKuehne on RL for MLLMs. First VOLD, how reasoning capabilities can be transferred from text-only LLMs to MLLMs without using image data, super cool work. Also for reasoning with other modalities like audio. Finally test-time RL for video.
Her work really shows what we can get by taking innovations from LLM space to CV.


3
17
1,114
CVPR News retweeted

Jun 3
@DerekHoiem_UofI prediction of our next bitter lesson!


Jun 2

Start your #CVPR2026 with a coffee and some hard truths ☕
Tomorrow morning, we're talking 'Bitter Lessons' -- hard-won wisdom our field has accumulated but rarely discusses
Come be part of a candid conversation👇
sites.google.com/view/Bitter…
Wed, 8:45am, Four Seasons Ballroom 4


2
7
41
6,452