

20 Dec 2025
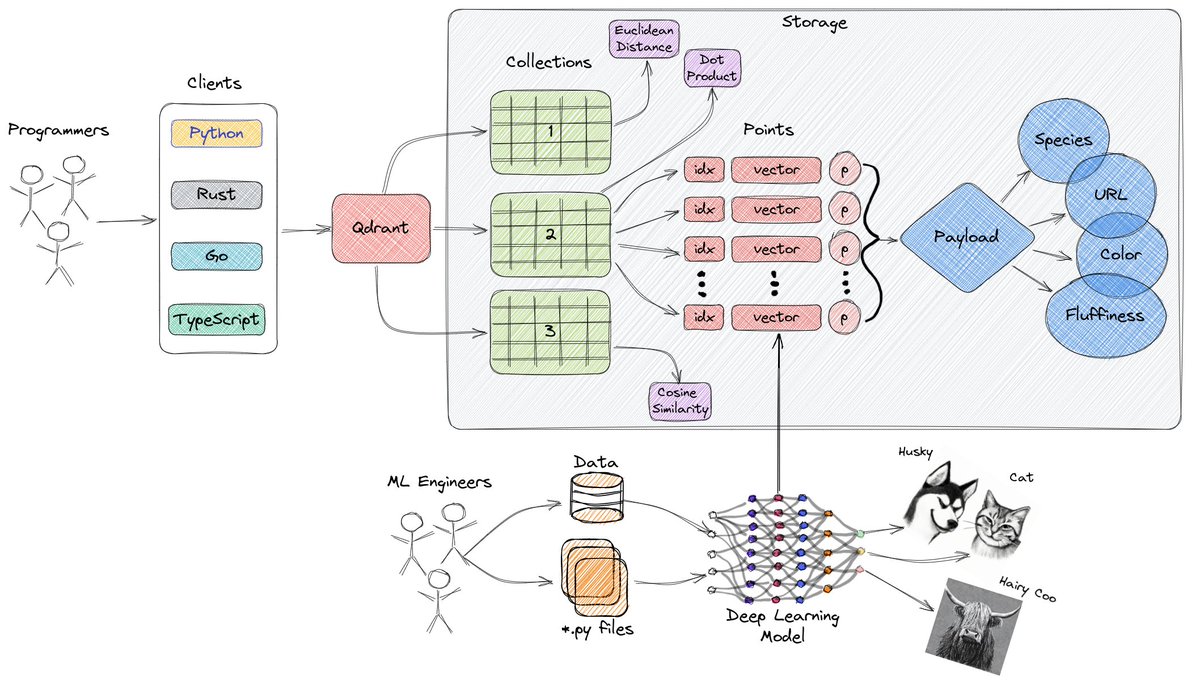
Qdrant shines when you need low-latency vector search with strong filtering
Semantic search metadata filters? That's its home turf
RAG pipelines love Qdrant because payload filtering happens inside the index, not after search
Compared to FAISS: Qdrant is production-ready (REST/gRPC, persistence, replicas), FAISS is a fast library, not a DB
Compared to Milvus: Qdrant is simpler to operate, lighter, fewer moving parts — less infra pain
Strong side: HNSW tuned well payload indexes → predictable p99 latency even with filters
A few tips:
- pre-normalize vectors and pin distance metric early — changing it later means full reindex
- split collections by embedding model/version to avoid silent relevance decay
Limitation:
- not built for massive write-heavy streams or complex analytics — it's search, not OLAP
If you want boring, fast, and correct vector search in prod, @qdrant_engine seems like a solid bet
#qdrant #search #search_engine #machine_learning #mlops #devops #ai #vector_database
4
37
1,798

27 Jul 2024
Generated from Claud with no prior context except the seed:
"Hi Claude I want to serve search results from a Github codebase using vector search over the chunks of the code base. Tell me some high level software architecture designs for this description:"
And had a couple of phases of conversation. And it managed to produce this. Very based Claude, very based
/vector-search-github/
├── data_ingestion/
│ ├── github_api_client.py
│ │ class GitHubAuth:
│ │ - token: str
│ │ __init__(token: str)
│ │ get_headers() -> dict
│ │
│ │ class GitHubRepo:
│ │ - name: str
│ │ - api_url: str
│ │ __init__(name: str, api_url: str)
│ │ get_file_list() -> list[str]
│ │
│ │ class GitHubClient:
│ │ - auth: GitHubAuth
│ │ __init__(auth: GitHubAuth)
│ │ fetch_repository(repo: GitHubRepo) -> dict
│ │ get_file_content(repo: GitHubRepo, file_path: str) -> str
│ │ get_commit_history(repo: GitHubRepo, file_path: str) -> list
│ │
│ ├── code_chunker.py
│ │ class ChunkConfig:
│ │ - chunk_size: int
│ │ - overlap: int
│ │ __init__(chunk_size: int, overlap: int)
│ │
│ │ class Chunk:
│ │ - content: str
│ │ - start_line: int
│ │ - end_line: int
│ │ __init__(content: str, start_line: int, end_line: int)
│ │
│ │ class CodeChunker:
│ │ - config: ChunkConfig
│ │ __init__(config: ChunkConfig)
│ │ chunk_code(code_string: str) -> list[Chunk]
│ │ process_file(file_content: str) -> list[Chunk]
│ │
│ ├── text_embedding.py
│ │ class EmbeddingModel:
│ │ - name: str
│ │ - dimension: int
│ │ __init__(name: str, dimension: int)
│ │ load() -> None
│ │
│ │ class TextEmbedder:
│ │ - model: EmbeddingModel
│ │ __init__(model: EmbeddingModel)
│ │ embed_text(text: str) -> np.ndarray
│ │ embed_chunks(chunks: list[Chunk]) -> list[np.ndarray]
│ │
│ │ class SimilarityCalculator:
│ │ compute_similarity(vec1: np.ndarray, vec2: np.ndarray) -> float
│ │
│ ├── code_analyzer.py
│ │ class CodeStructure:
│ │ - functions: list[str]
│ │ - classes: list[str]
│ │ __init__(functions: list[str], classes: list[str])
│ │
│ │ class ComplexityMetrics:
│ │ - cyclomatic_complexity: int
│ │ - cognitive_complexity: int
│ │ __init__(cyclomatic_complexity: int, cognitive_complexity: int)
│ │
│ │ class CodeAnalyzer:
│ │ extract_structure(code: str) -> CodeStructure
│ │ analyze_complexity(code: str) -> ComplexityMetrics
│ │ detect_language(code: str) -> str
├── vector_database/
│ ├── vector_store.py
│ │ class VectorEntry:
│ │ - id: str
│ │ - vector: np.ndarray
│ │ - metadata: dict
│ │ __init__(id: str, vector: np.ndarray, metadata: dict)
│ │
│ │ class VectorStore:
│ │ - database: DatabaseManager
│ │ __init__(database: DatabaseManager)
│ │ insert_vector(entry: VectorEntry) -> None
│ │ search_similar(query_vector: np.ndarray, top_k: int) -> list[VectorEntry]
│ │ delete_vector(vector_id: str) -> None
│ │ update_vector(vector_id: str, new_entry: VectorEntry) -> None
│ │
│ ├── indexing.py
│ │ class IndexConfig:
│ │ - algorithm: str
│ │ - parameters: dict
│ │ __init__(algorithm: str, parameters: dict)
│ │
│ │ class VectorIndex:
│ │ - config: IndexConfig
│ │ - index: Any # Placeholder for the actual index structure
│ │ __init__(config: IndexConfig)
│ │ build_index(vectors: list[np.ndarray]) -> None
│ │ query(query_vector: np.ndarray, num_results: int) -> list[int]
│ │ add_to_index(vector: np.ndarray, id: int) -> None
│ │ remove_from_index(id: int) -> None
│ │
│ ├── database_manager.py
│ │ class DatabaseConfig:
│ │ - url: str
│ │ - max_connections: int
│ │ __init__(url: str, max_connections: int)
│ │
│ │ class DatabaseManager:
│ │ - config: DatabaseConfig
│ │ - connection: Any # Placeholder for the actual database connection
│ │ __init__(config: DatabaseConfig)
│ │ create_tables() -> None
│ │ execute_query(query: str, params: tuple) -> None
│ │ fetch_all(query: str, params: tuple) -> list
│ │ close_connection() -> None
├── search_api/
│ ├── query_handler.py
│ │ class Query:
│ │ - text: str
│ │ - filters: dict
│ │ __init__(text: str, filters: dict)
│ │
│ │ class SearchResult:
│ │ - content: str
│ │ - similarity: float
│ │ - metadata: dict
│ │ __init__(content: str, similarity: float, metadata: dict)
│ │
│ │ class QueryHandler:
│ │ - vector_store: VectorStore
│ │ - text_embedder: TextEmbedder
│ │ __init__(vector_store: VectorStore, text_embedder: TextEmbedder)
│ │ process_query(query: Query) -> list[SearchResult]
│ │ format_results(search_results: list[SearchResult]) -> list[dict]
│ │
│ ├── vector_converter.py
│ │ class VectorConverter:
│ │ - text_embedder: TextEmbedder
│ │ __init__(text_embedder: TextEmbedder)
│ │ text_to_vector(text: str) -> np.ndarray
│ │
│ │ class VectorCompressor:
│ │ - compression_method: str
│ │ __init__(compression_method: str)
│ │ compress_vector(vector: np.ndarray) -> np.ndarray
│ │ decompress_vector(compressed_vector: np.ndarray) -> np.ndarray
│ │
│ ├── similarity_search.py
│ │ class SearchConfig:
│ │ - top_k: int
│ │ - similarity_threshold: float
│ │ __init__(top_k: int, similarity_threshold: float)
│ │
│ │ class SimilaritySearch:
│ │ - vector_store: VectorStore
│ │ - vector_index: VectorIndex
│ │ - config: SearchConfig
│ │ __init__(vector_store: VectorStore, vector_index: VectorIndex, config: SearchConfig)
│ │ search(query_vector: np.ndarray) -> list[SearchResult]
│ │ range_search(query_vector: np.ndarray, radius: float) -> list[SearchResult]
│ │
│ ├── search_optimizer.py
│ │ class QueryCache:
│ │ - cache: dict
│ │ - max_size: int
│ │ __init__(max_size: int)
│ │ add(query: str, results: list[SearchResult]) -> None
│ │ get(query: str) -> list[SearchResult]
│ │
│ │ class SearchOptimizer:
│ │ - similarity_search: SimilaritySearch
│ │ - query_cache: QueryCache
│ │ __init__(similarity_search: SimilaritySearch, query_cache: QueryCache)
│ │ optimize_query(query: str) -> str
│ │ cache_frequent_queries(query_history: list[str]) -> None
│ │ suggest_related_queries(query: str) -> list[str]
├── web_interface/
│ ├── app.py
│ │ class FlaskApp:
│ │ - app: Flask
│ │ - query_handler: QueryHandler
│ │ __init__(query_handler: QueryHandler)
│ │ index() -> str
│ │ search() -> str
│ │ advanced_search() -> str
│ │ api_search() -> dict
├── background_jobs/
│ ├── update_codebase.py
│ │ class UpdateTask:
│ │ - repo: GitHubRepo
│ │ - last_update: datetime
│ │ __init__(repo: GitHubRepo)
│ │
│ │ class CodebaseUpdater:
│ │ - github_client: GitHubClient
│ │ - vector_store: VectorStore
│ │ - tasks: list[UpdateTask]
│ │ __init__(github_client: GitHubClient, vector_store: VectorStore)
│ │ check_for_updates() -> list[str]
│ │ process_updates(updates: list[str]) -> None
│ │
│ ├── refresh_vector_db.py
│ │ class RefreshTask:
│ │ - chunk: Chunk
│ │ - last_refresh: datetime
│ │ __init__(chunk: Chunk)
│ │
│ │ class VectorDBRefresher:
│ │ - vector_store: VectorStore
│ │ - code_chunker: CodeChunker
│ │ - text_embedder: TextEmbedder
│ │ - tasks: list[RefreshTask]
│ │ __init__(vector_store: VectorStore, code_chunker: CodeChunker, text_embedder: TextEmbedder)
│ │ refresh_database() -> None
│ │ process_chunk(chunk: Chunk) -> None
│ │
│ ├── job_scheduler.py
│ │ class Job:
│ │ - id: str
│ │ - func: callable
│ │ - trigger: str
│ │ - kwargs: dict
│ │ __init__(id: str, func: callable, trigger: str, **kwargs)
│ │
│ │ class JobScheduler:
│ │ - jobs: list[Job]
│ │ __init__()
│ │ add_job(job: Job) -> None
│ │ remove_job(job_id: str) -> None
│ │ start() -> None
│ │ shutdown() -> None
├── config/
│ ├── settings.py
│ ├── logging_config.py
│ │ class LogConfig:
│ │ - level: str
│ │ - format: str
│ │ - file: str
│ │ __init__(level: str, format: str, file: str)
│ │
│ │ setup_logging(config: LogConfig) -> None
│ │ get_logger(name: str) -> Logger
├── utils/
│ ├── performance_monitor.py
│ │ class Timer:
│ │ - start_time: float
│ │ - end_time: float
│ │ start() -> None
│ │ stop() -> float
│ │
│ │ class PerformanceMonitor:
│ │ - timers: dict[str, Timer]
│ │ - memory_usage: list[float]
│ │ start_timer(operation: str) -> None
│ │ stop_timer(operation: str) -> float
│ │ log_memory_usage() -> None
│ │ generate_report() -> dict
│ │
│ ├── error_handler.py
│ │ class ErrorContext:
│ │ - module: str
│ │ - function: str
│ │ - parameters: dict
│ │ __init__(module: str, function: str, parameters: dict)
│ │
│ │ class ErrorHandler:
│ │ - logger: Logger
│ │ __init__(logger: Logger)
│ │ handle_error(error: Exception, context: ErrorContext) -> None
│ │ log_error(error: Exception, context: ErrorContext) -> None
│ │ notify_admin(error: Exception, context: ErrorContext) -> None
├── tests/
│ ├── test_github_api_client.py
│ ├── test_code_chunker.py
│ ├── test_text_embedding.py
│ ├── test_vector_store.py
│ ├── test_query_handler.py
│ ├── test_similarity_search.py
│ └── test_web_interface.py
└── main.py
initialize_components() -> tuple
setup_background_jobs(job_scheduler: JobScheduler) -> None
main() -> None
1
1
71

20 Mar 2024
Current state of AI engineering and theory with focus on LLMs and its future
Large language models are using variations of gradient descent to minimize loss function over predicting tons of text data with artificial neural networks, attention, and other tricks in the Transformer architecture! en.wikipedia,org/wiki/Transformer_(machine_learning_model) (now often with better routing of information thanks to mixture of experts architecture en.wikipedia,org/wiki/Mixture_of_experts )" which means tons of inscrutable matrices with trillions of emergent patterns in dynamics which we mathematically understand insufficiently. Reverse engineering what happens inside and controllability is being solved by the whole mechanistic interpretability field [GitHub - JShollaj/awesome-llm-interpretability: A curated list of Large Language Model (LLM) Interpretability resources.](<github,com/JShollaj/awesome-llm-interpretability> youtube,com/watch?v=7t9umZ1tFso youtube,com/watch?v=2Rdp9GvcYOE ), or [Statistical learning theory](<en.wikipedia,org/wiki/Statistical_learning_theory>) and deep learning theory field, [[2106.10165] The Principles of Deep Learning Theory](<arxiv,org/abs/2106.10165> A New Physics-Inspired Theory of Deep Learning | Optimal initialization of Neural Nets youtube,com/watch?v=m2bXL5Z5CBM ), or other alignment and empirical alchemical methods [[2309.15025] Large Language Model Alignment: A Survey](<arxiv,org/abs/2309.15025>)
Now the biggest limitations in current AI systems are probably: to create more complex systematic coherent reasoning, planning, generalizing, search, agency (autonomy), memory, factual groundedness, online/continuous learning, software and hardware energetic and algoritmic efficiency, human-like ethical reasoning, or controllability, into AI systems, which they have relatively weak for more complex tasks, but we are making progress in this, either through composing LLMs in multiagent systems, scaling, higher quality data and training, poking around how they work inside and thus controlling them, through better mathematical models of how learning works and using these insights, or modified or overhauled architecture, etc.... or embodied robotics is also getting attention recently... and all top AGI labs are working/investing in these things to varying degrees. Here are some works:
Survey of LLMs: [[2312.03863] Efficient Large Language Models: A Survey](<arxiv,org/abs/2312.03863>), [[2311.10215] Predictive Minds: LLMs As Atypical Active Inference Agents](<arxiv,org/abs/2311.10215>), [A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications](<arxiv,org/abs/2402.07927>)
Reasoning: [Human-like systematic generalization through a meta-learning neural network | Nature](<nature,com/articles/s41586-023-06668-3>), [[2305.20050] Let's Verify Step by Step](<arxiv,org/abs/2305.20050>), [[2302.00923] Multimodal Chain-of-Thought Reasoning in Language Models](<arxiv,org/abs/2302.00923>), [[2310.09158] Learning To Teach Large Language Models Logical Reasoning](<arxiv,org/abs/2310.09158>), [[2303.09014] ART: Automatic multi-step reasoning and tool-use for large language models](<arxiv,org/abs/2303.09014>), [AlphaGeometry: An Olympiad-level AI system for geometry - Google DeepMind](<deepmind,google/discover/blog/alphageometry-an-olympiad-level-ai-system-for-geometry/>) (Devin AI programmer cognition-labs,com/introducing-devin ) (Automated Unit Test Improvement using Large Language Models at Meta arxiv,org/abs/2402.09171 ) (GPT-5: Everything You Need to Know So Far youtube,com/watch?v=Zc03IYnnuIA ), (Self-Discover: Large Language Models Self-Compose Reasoning Structures arxiv,org/abs/2402.03620 twitter,com/ecardenas300/status/1769396057002082410 ) , (How to think step-by-step: A mechanistic understanding of chain-of-thought reasoning twitter,com/fly51fly/status/1764279536794169768?t=up6d06PPGeCE5fvIlE418Q&s=19 arxiv,org/abs/2402.18312 ), magic,dev , (The power of prompting microsoft,com/en-us/research/blog/the-power-of-prompting/ ), Flow engineering ( codium,ai/blog/alphacodium-state-of-the-art-code-generation-for-code-contests/ ), Stable Cascade ( stability,ai/news/introducing-stable-cascade ), ( RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners arxiv,org/abs/2403.12373 )
Robotics: [Mobile ALOHA - A Smart Home Robot - Compilation of Autonomous Skills - YouTube](<youtube,com/watch?v=zMNumQ45pJ8>), [Eureka! Extreme Robot Dexterity with LLMs | NVIDIA Research Paper - YouTube](<youtu,be/sDFAWnrCqKc?si=LEhIqEIeHCuQ0W2p>), [Shaping the future of advanced robotics - Google DeepMind](<deepmind,google/discover/blog/shaping-the-future-of-advanced-robotics/>), [Optimus - Gen 2 - YouTube](<youtube,com/watch?v=cpraXaw7dyc>), [Atlas Struts - YouTube](<youtube,com/shorts/SFKM-Rxiqzg>), [Figure Status Update - AI Trained Coffee Demo - YouTube](<youtube,com/watch?v=Q5MKo7Idsok>), [Curiosity-Driven Learning of Joint Locomotion and Manipulation Tasks - YouTube](<youtube,com/watch?v=Qob2k_ldLuw>)
Multiagent systems: [[2402.01680] Large Language Model based Multi-Agents: A Survey of Progress and Challenges](<arxiv,org/abs/2402.01680>) (AutoDev: Automated AI-Driven Development arxiv,org/abs/2403.08299 )
Modified/alternative architectures: [Mamba (deep learning architecture) - Wikipedia](<en.wikipedia,org/wiki/Mamba_(deep_learning_architecture)>), [[2305.13048] RWKV: Reinventing RNNs for the Transformer Era](<arxiv,org/abs/2305.13048>), [V-JEPA: The next step toward advanced machine intelligence](<ai.meta,com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/>), [Active Inference](<mitpress,mit,edu/9780262045353/active-inference/>)
Agency: [[2305.16291] Voyager: An Open-Ended Embodied Agent with Large Language Models](<arxiv,org/abs/2305.16291>), [[2309.07864] The Rise and Potential of Large Language Model Based Agents: A Survey](<arxiv,org/abs/2309.07864>), [Agents | Langchain](<python.langchain,com/docs/modules/agents/>), [GitHub - THUDM/AgentBench: A Comprehensive Benchmark to Evaluate LLMs as Agents (ICLR'24)](<github,com/THUDM/AgentBench>), [[2401.12917] Active Inference as a Model of Agency](<arxiv,org/abs/2401.12917>), [CAN AI THINK ON ITS OWN? - YouTube](<youtube,com/watch?v=zMDSMqtjays>), [Artificial Curiosity Since 1990](<people.idsia,ch/~juergen/artificial-curiosity-since-1990.html>)
Factual groundedness: [[2312.10997] Retrieval-Augmented Generation for Large Language Models: A Survey](<arxiv,org/abs/2312.10997>), [Perplexity](<perplexity,ai/>), [ChatGPT - Consensus](<chat.openai,com/g/g-bo0FiWLY7-consensus>)
Memory: larger context window [Gemini 10 million token context window](<twitter,com/mattshumer_/status/1759804492919275555>), or [vector databases](<en.wikipedia,org/wiki/Vector_database>) (Larimar: Large Language Models with Episodic Memory Control arxiv,org/abs/2403.11901 )
Hardware efficiency: extropic extropic,ai/future , tinygrad, groq twitter,com/__tinygrad__/status/1769388346948853839 , techradar,com/pro/a-single-chip-to-outperform-a-small-gpu-data-center-yet-another-ai-chip-firm-wants-to-challenge-nvidias-gpu-centric-world-taalas-wants-to-have-super-specialized-ai-chips , new Nvidia GPUs youtube,com/watch?v=GkBX9bTlNQA , etched etched,com/ , techxplore,com/news/2023-12-ultra-high-processor-advance-ai-driverless.html , Thermodynamic AI and the fluctuation frontier arxiv,org/abs/2302.06584 , analog computing
twitter,com/dmvaldman/status/1767745899407753718?t=Xe5sDPbrBVayUaAGX4ikmw&s=19 neuromorphics en.wikipedia,org/wiki/Neuromorphic_engineering
Online/continuous learning: en.wikipedia,org/wiki/Online_machine_learning (A Comprehensive Survey of Continual Learning: Theory, Method and Application arxiv,org/abs/2302.00487 )
Meta learning: en.wikipedia,org/wiki/Meta-learning_(computer_science) (Paired open-ended trailblazer (POET) alpera,xyz/blog/1/ )
Planning: [[2402.01817] LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks](<arxiv,org/abs/2402.01817>), [[2401.11708v1] Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs](<arxiv,org/abs/2401.11708v1>), [[2305.16151] Understanding the Capabilities of Large Language Models for Automated Planning](<arxiv,org/abs/2305.16151>)
Generalizing: [[2402.10891] Instruction Diversity Drives Generalization To Unseen Tasks](<arxiv,org/abs/2402.10891>), [Automated discovery of algorithms from data | Nature Computational Science](<nature,com/articles/s43588-024-00593-9>), [[2402.09371] Transformers Can Achieve Length Generalization But Not Robustly](<arxiv,org/abs/2402.09371>), [[2310.16028] What Algorithms can Transformers Learn? A Study in Length Generalization](<arxiv,org/abs/2310.16028>), [[2307.04721] Large Language Models as General Pattern Machines](<arxiv,org/abs/2307.04721>), [A Tutorial on Domain Generalization | Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining](<dl.acm,org/doi/10.1145/3539597.3572722>), [[2311.06545] Understanding Generalization via Set Theory](<arxiv,org/abs/2311.06545>), [[2310.08661] Counting and Algorithmic Generalization with Transformers](<arxiv,org/abs/2310.08661>), [Neural Networks on the Brink of Universal Prediction with DeepMind's Cutting-Edge Approach | Synced](<syncedreview,com/2024/01/31/neural-networks-on-the-brink-of-universal-prediction-with-deepminds-cutting-edge-approach/>), [[2401.14953] Learning Universal Predictors](<arxiv,org/abs/2401.14953>), [Spectral bias and task-model alignment explain generalization in kernel regression and infinitely wide neural networks | Nature Communications](<nature,com/articles/s41467-021-23103-1>) (Natural language instructions induce compositional generalization in networks of neurons nature,com/articles/s41593-024-01607-5 ) (FRANCOIS CHOLLET - measuring intelligence and generalisation arxiv,org/abs/1911.01547 twitter,com/fchollet/status/1763692655408779455 youtu,be/J0p_thJJnoo ) (Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking arxiv,org/abs/2403.09629 )
Search: AlphaGo ( twitter,com/polynoamial/status/1766616044838236507 ), AlphaCode 2 Technical Report ( storage.googleapis,com/deepmind-media/AlphaCode2/AlphaCode2_Tech_Report.pdf )
It is quite possible (and a large % of researchers think) that research trying to control these crazy inscrutable matrices does not have sufficiently rapid development compared to capabilities research (increasing the amount of things these systems are capable of) and we might see more and more cases where AI systems do pretty random things we didnt intended.
Then we have no idea how to turn off behaviors with existing methods [Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training \ Anthropic](<anthropic,com/news/sleeper-agents-training-deceptive-llms-that-persist-through-safety-training>), which could be seen lately the last few days with how GPT4 started outputting total chaos after an update [OpenAI's ChatGPT Went Completely Off the Rails for Hours](<thedailybeast,com/openais-chatgpt-went-completely-off-the-rails-for-hours>), Gemini was more woke than intended ( businessinsider,com/google-gemini-woke-images-ai-chatbot-criticism-controversy-2024-2 alignmentforum,org/posts/9GyniEBaN3YYTqZXn/the-self-unalignment-problem ), or every moment I see a new jailbreak that bypasses the barriers [[2307.15043] Universal and Transferable Adversarial Attacks on Aligned Language Models](<arxiv,org/abs/2307.15043>).
Regarding definitions of AGI, this is good from DeepMind [Levels of AGI: Operationalizing Progress on the Path to AGI](arxiv,org/abs/2311.02462), or I also like, although quite vague, a pretty good definition from OpenAI: Highly autonomous systems that outperform humans at most economically valuable work, or this is a nice thread of various definitions and their pros and cons [9 definitions of Artificial General Intelligence (AGI) and why they are flawed](<twitter,com/IntuitMachine/status/1721845203030470956>), or also [Universal Intelligence: A Definition of Machine Intelligence](<arxiv,org/abs/0712.3329>), or Karl Friston has good definitions [KARL FRISTON - INTELLIGENCE 3.0](<youtu,be/V_VXOdf1NMw?si=8sOkRmbgzjrkvkif&t=1898>))
In terms of predictions when AGI arrives, people around Effective Accelerationism, Singularity, Metaculus, LessWrong/Effective Altruism, and various influential people in top AGI labs, have very short timelines, often possibly in the 2020s. [Singularity Predictions 2024 by some people big in the field](reddit,com/r/singularity/comments/18vawje/singularity_predictions_2024/kfpntso/), [Metaculus: When will the first weakly general AI system be devised, tested, and publicly announced?](<metaculus,com/questions/3479/date-weakly-general-ai-is-publicly-known/>) Then there is also this questionnaire about priorities and predictions from AI researchers, whose intervals are shrinking by about half each year in these questionnaires: [AI experts make predictions for 2040. I was a little surprised. | Science News](<youtube,com/watch?v=g7TghURVC6Y>), [Thousands of AI Authors on the Future of AI](arxiv,org/abs/2401.02843)
When someone calls LLMs "just statistics", then you may similarly reductively say that humans are "just autocompleting predictions about input signals that are compared to actual signals" (using a version of bayesian inference) [Predictive coding](<en.wikipedia,org/wiki/Predictive_coding> en.wikipedia,org/wiki/Visual_processing en.wikipedia,org/wiki/Free_energy_principle Inner screen model of consciousness: applying free energy principle to study of conscious experience youtube,com/watch?v=yZWjjDT5rGU&pp=ygUzZnJlZSBlbmVyZ3kgcHJpbmNpcGxlIGFwcGxpZWQgdG8gdGhlIGJyYWluIHJhbXN0ZWFk) (global neuronal workspace theory integrated information theory recurrent processing theory predictive processing theory neurorepresentationalism dendritic integration theory, An integrative, multiscale view on neural theories of consciousness cell,com/neuron/fulltext/S0896-6273(24)00088-6 ) (Models of consciousness Wikipedia en.wikipedia,org/wiki/Models_of_consciousness?wprov=sfla1 ) (More models ncbi.nlm.nih,gov/pmc/articles/PMC8146510/ ) or "just bioelectricity and biochemistry" ( link.springer,com/article/10.1007/s10071-023-01780-3 ) (Bioelectric networks: the cognitive glue enabling evolutionary scaling from physiology to mind) or "just particles" ( en.wikipedia,org/wiki/Electromagnetic_theories_of_consciousness) (On Connectome and Geometric Eigenmodes of Brain Activity: The Eigenbasis of the Mind? qri,org/blog/eigenbasis-of-the-mind ) (Integrated world modeling theory frontiersin,org/articles/10.3389/frai.2020.00030/full pubmed.ncbi.nlm.nih,gov/36507308/ ) (Can AI think on its own? youtu,be/zMDSMqtjays?si=MRXTcQ6s8o_KwNXd ) (Synthetic Sentience: Can Artificial Intelligence become conscious? | Joscha Bach youtu,be/Ms96Py8p8Jg?si=HYx2lf8DrCkMcf8b ). Or you can say that the whole universe is just a big differential equation. It doesn't really tell you specific things about concrete implementation details and about the dynamics that's actually happening there!
With functioning links, because Twitter won't let me post so many links in one post: pastebin,com/xMrmpXrk

2
14
2,335

27 Jun 2023
I implemented my very own vector database in Python this morning. Here's the code:
database = np.load("storage.npy", mmap_mode="r ")
def vector_database(query):
return np.argsort(np.linalg.norm(query - database, axis=-1))
So glad I took STATS 305 in college.
8
622

5
46