Kimath!. retweeted

4h
Kama uko na laptop, good internet, proxy and all other verifiers kama Dl ama ID usikae bure na unaweza piga online gigs. Kuna survey mingi kama mobiworkz unaweza pata hata some few dollars ya supper....
7
17
49
1,159

AgentCyberRange is part of Nuwa’s broader research program on frontier AI risk evaluation, agent safety, autonomy, and open technical infrastructure for AI governance.
Technical report:
arxiv.org/abs/2606.14295
GitHub:
github.com/AgentCyberRange
Hugging Face:
huggingface.co/AgentCyberRan…
Homepage:
agentcyberrange.io/
We welcome independent reproductions, new agent adapters, additional cyber ranges, improved verifiers, and critical examination of the results.
#AIEvals #AISafety #Cybersecurity

19

The people replying to this hella pressed is actually hilarious “it’s called fun” joining the actual verifiers stream instead of leeching viewers from them is more fun

20

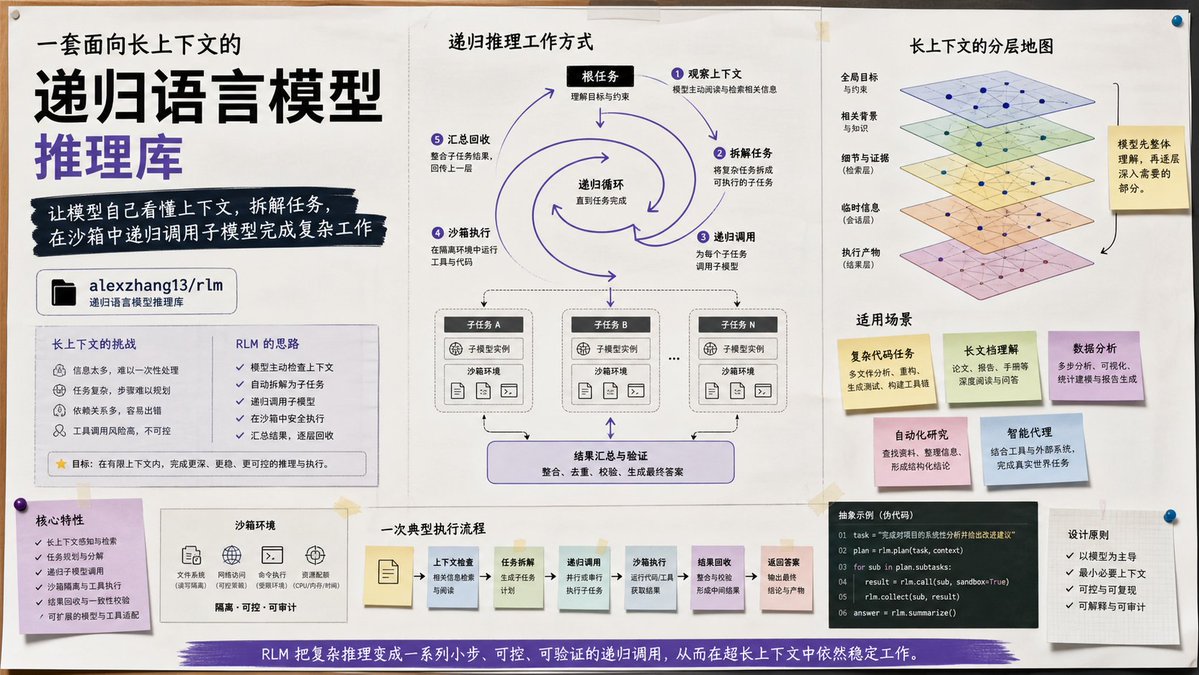
长上下文很快会把普通 prompt 塞满。模型也会卡住。rlm 就是用来让模型继续拆问题和递归调用的项目。
rlm 是一个给 Recursive Language Models 用的推理库项目。
项目说明把关键动作写得很实。常见的 `llm.completion(prompt, model)` 在这里会换成 `rlm.completion(prompt, model)`,上下文会放进 REPL 环境里,模型可以继续检查内容,再递归发起子模型调用。仓库里还放了 inference engine、多种 sandbox 执行环境,以及 training 目录下的 verifiers 训练线,推理和训练都能顺着项目说明往下看。
要处理超长材料、复杂任务拆分,或者想研究递归式语言模型的人会更需要它。短 prompt 问答场景里,普通调用链通常已经够用了。
GitHub 现在约 4.9k stars
工具地址:github.com/alexzhang13/rlm

我真的生气了
半月前我做了这个时间穿越机
可以说用尽了我毕生的物理学知识
蒸馏了所有顶级物理学家的人格
可以说是燃尽了自己做出来的跨时代机器
结果今天看到一个简陋版的时间机器竟然有20 万的浏览
看来这个世界尊重知识的人还是少数
中科院呢?我要给中科院打电话!
wwtlitee.github.io/time-mach…
6
7
385

The number of votes don't matter if you're not the one counting...
Someone needs to explain to me how Carney being in direct control of Elections Canada executives, allowing him to place "his" people in specific jobs that are lynch pins in the voting process, and allowing him direct access thru any of the lynch pin employees, to manipulate, adjudicate and rule over any ballot deemed marginal or in need of ruling... with such an ease of ability to pick a chose who's vote counts, and who's doesn't...
And if we ask for verification, we get "Its paper ballots. They are impossible to cheat with" and the paper you just put an X on a couple hours ago is disqualified because one of the ends of your X somehow managed to cross the circled space, even though you have a picture of your perfectly placed X touching no circle... but, - iTs pApEr bAlLoTs iTs iMpOsSiBlE tO cHeAt wItH pApEr bAlLoTs - only two people know what really happened... You with no voice or ability to verify your paper ballot wasn't screwed with, and the person who screwed with your paper ballot... that's it...
and to those who say its a team of people from all parties that verify...
Go watch what they did in 2020 in the US to the GOP verifiers... "Hey, lets grab a coffee, we're all taking a 15min break.." ..."Where did all those boxes come from?" ./.. "Why does this X look like the last 15 X s I've seen... ?" ...
Until the system allowed you to verify and confirm your vote was correctly counted, registered correctly, and can be verified in the future as the same... and impossible to screw with... no election is same from a liberal's hands of fraud
1
16

very cool work! i'm curious about the benefits and limitations of relying on rubric grading. do you think we will eventually have deterministic, quantitative verifiers like tests in coding RL environments?
18

IMO the real value of working with an english->code interpreter is forcing you, as a human being, to articulate a problem and its verifiers clearly enough that such a system can exist in the first place.
Once you do that, executing it becomes (increasingly) trivial.
1
175

Highly-recommended reading!
After using /loops & /goal throughout my projects, I believe that verifiers and robust guardrails are imperative to get current/future coding agents to work right. You can't just YOLO your way with blind autonomous loops. It doesn't work!

1. as a mental model it is more correct to think of fable class models as english -> code interpreters - converts your idea into code into "correct" code regardless of problem complexity and output complexity (diff size). Fable 5 will be the worst of this new class of models
2. diff size/complexity is to be managed purely for review:
small diffs - in high risk areas of code (auth/identity/data access/network access/money movement)
large diffs for code that can be empirically verified (frontend/backend plumbing/code without network or db access/performance code that can be empirically verified)
3. time it takes to ship software is completely disconnected from time to produce the PR - how long the work takes depends fully on ability to review/merge code while managing risk at scale
4. solving the bottlenecks for above matter enormously- linters/testing/CI/shadow mode verification/empirical verification
5. agency matters enormously- what are the biggest bottlenecks to speeding up the loop and eliminating them? what are the problems that need solving and when do they need solving? what does it take to the solution to all of them today?
6. deep understanding of the full stack matters enormously- what problems are worth pursuing? is there a higher level of problem abstraction to address first? should I give it the sub-sub task, the sub task, or the task itself. what are the major risks with this PR (order of importance: security holes/correctness holes/performance holes). is there a higher speed way of producing data that allows me to merge this? should this be run in shadow or in a sandbox or a flag. understanding every line of logic may not be needed but understanding and managing risk matters enormously.
7. the cost of complexity itself is changing. it might be now worth "maintaining" 50% more code to get a 5% performance win. getting the right abstractions matter less because larger refactors are less tedious. code quality nits become huge drag. very likely, a much smarter model will be maintaining your code so worth taking on more technical debt now. taking the time to hand architect and rebuild systems comes with an enormous cost of velocity
8. if it quacks like a duck and walks like a duck, it's a duck. For low risk cases, it might be more sane to treat code chunks (services / functions) as a black box, like we do for neural networks: do full empirical verification only: has code produced correct outputs for the last 10,100,1000,10k inputs ? can we quarantine this large piece of code - no outbound access to network / database ? what happens when this code is wrong? do we get hacked/or crash(memory/cpu)/is an inconvenience? is it internal facing or external? what can we do to address these risks?
9. eventually, logical verification (line by line review) will come at an enormous cost- save it for where it matters and build systems that are tolerant to empirical verification. is there a decorator that prevents db / network access? correctness bugs are significantly easier to rectify than access bugs
10. what are the rails that allow for even faster iteration? code permissions can be opt in - db writes, db reads, network egress (to where?), PII access. how long does it take to get shadow mode data? how many PRs can be tested? What are the categories of diffs
16
28
301
51,252

The most useful coding benchmark is not the one that makes models look close together. It is the one that exposes where a developer would actually lose trust.
That is why DeepSWE is worth paying attention to. The benchmark is built around original, long-horizon software engineering tasks from active open-source repositories, not tiny completion puzzles. The public repo describes 113 tasks across TypeScript, Go, Python, JavaScript and Rust, with isolated environments and program-based verifiers. The important detail is that the verifier checks observable behavior, not whether the model produced a reference patch.
That sounds like benchmark plumbing, but it changes the signal. Real engineering work is rarely "write this function." It is read the repo, understand the architecture, touch multiple files, avoid breaking hidden assumptions, run tests, and commit something that works in a clean environment. A model can look strong on short tasks and still fail badly when the work requires repository navigation and state management.
People perceive coding agents through demos: open issue, agent writes code, tests pass. Builders judge them through interruptions: did it understand the codebase, did it make an unnecessary abstraction, did it miss the real failing path, did it recover after a bad assumption.
The prior pattern is CI. Teams learned that unit tests alone were not enough; integration behavior and reproducibility mattered. Coding-agent evals are heading the same way.
The hidden bottleneck is execution fidelity. If the environment, verifier and task are too synthetic, the leaderboard teaches you the wrong thing.
My read: the next useful coding-agent benchmark will look less like a quiz and more like a disposable engineering job. DeepSWE is a step in that direction because it evaluates the thing teams actually buy: reliable changes in messy repos.
x.com/steipete/status/206743…

This benchmark is the closest one to real dev work. deepswe.datacurve.ai/
28