
Product & Growth | RAG & Knowledge Graph | Generative AI | LLMs | 15x Patents | 7x Author | Building for Growth
- Tweets 8,544
- Following 944
- Followers 2,170
- Likes 3,082
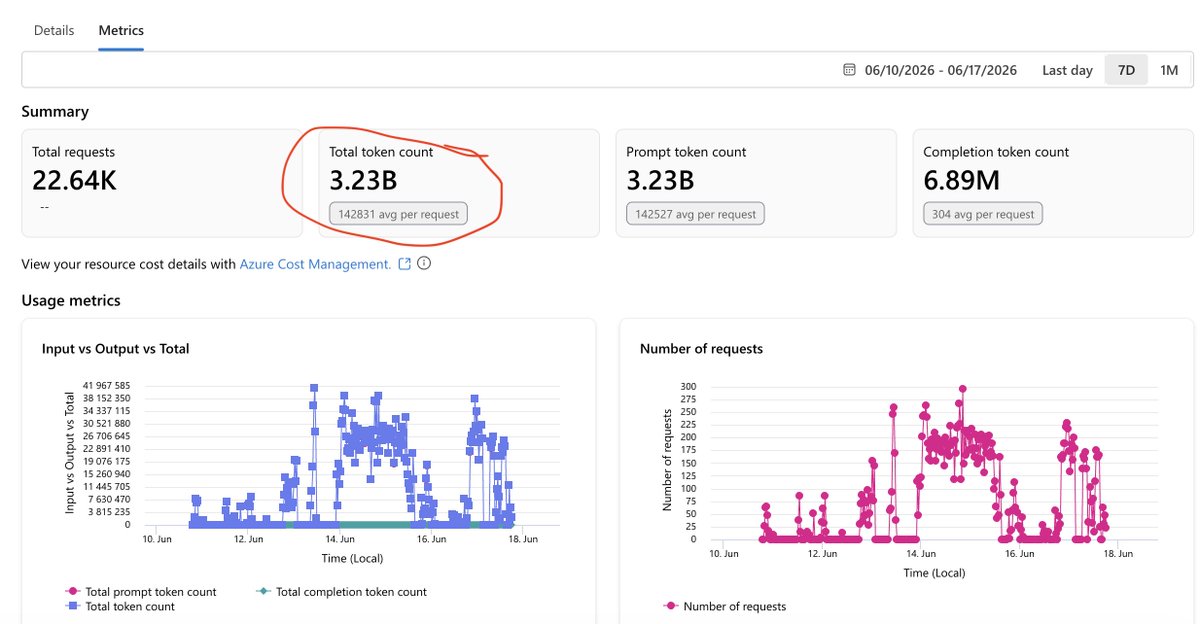
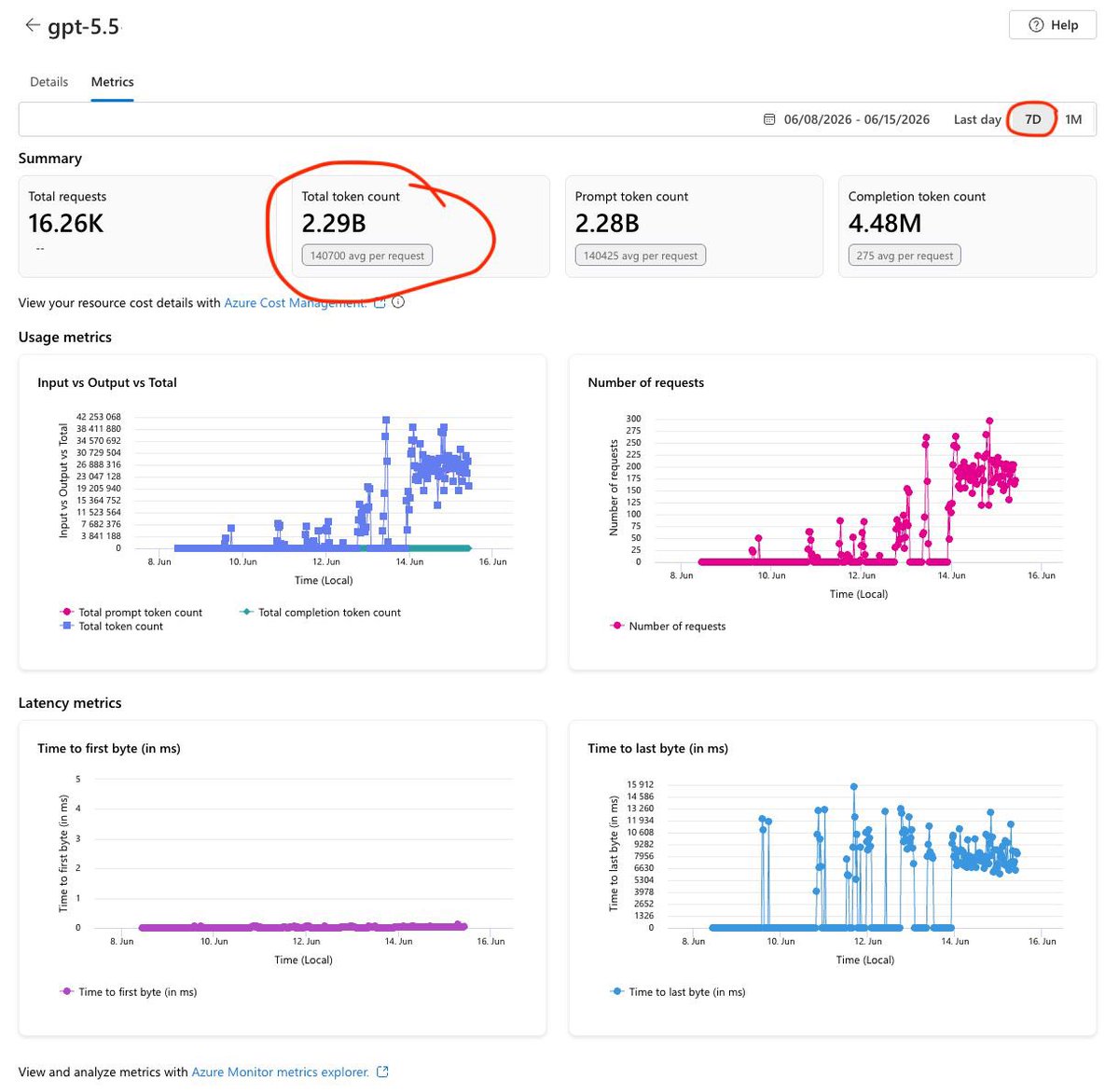
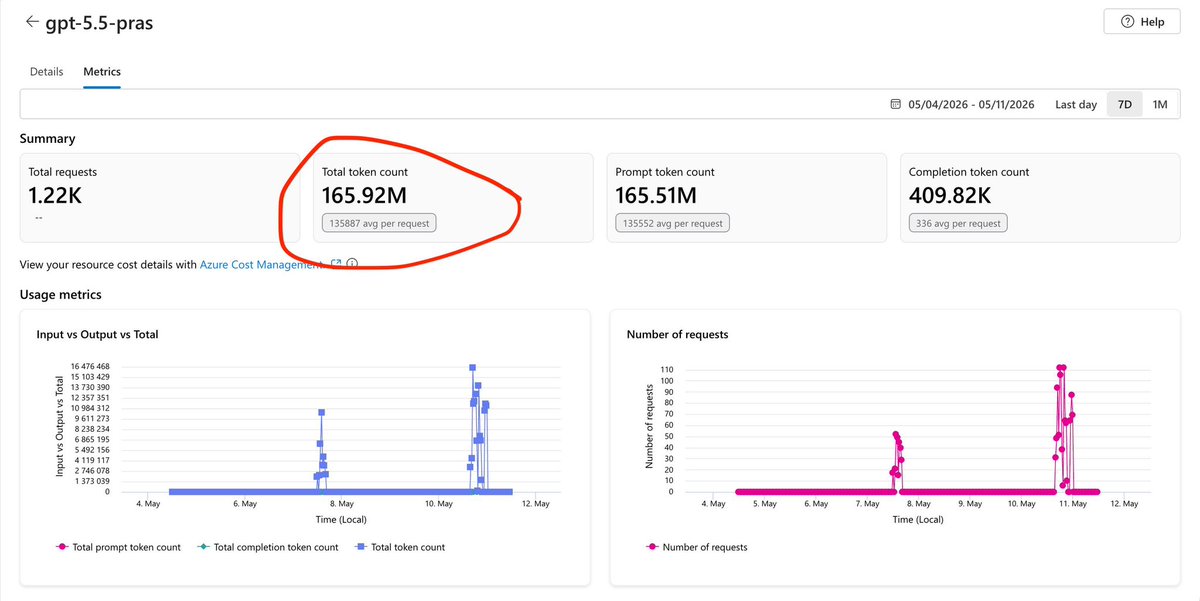









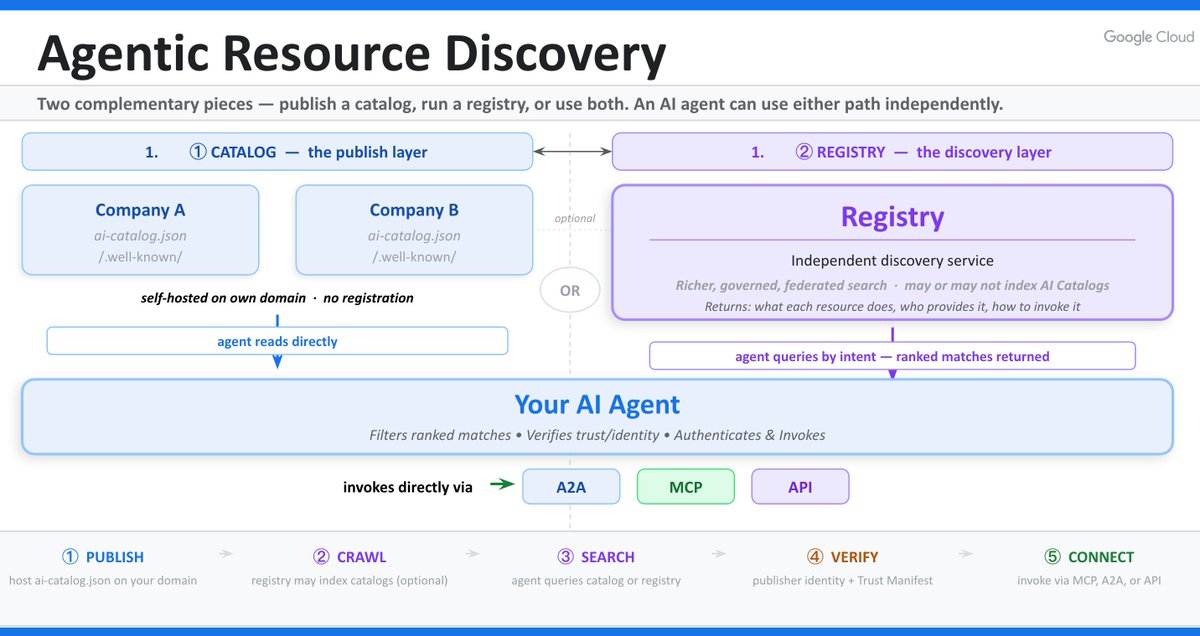
ALT This architectural diagram titled "Agentic Resource Discovery" illustrates two parallel paths for an AI agent to find resources: a direct "Catalog" layer where companies self-host discovery files and a centralized "Registry" discovery service. The AI agent searches these sources, then verifies and connects to resources via A2A, MCP, or API protocols. A five-step process flow at the bottom summarizes the workflow: 1) Publish, 2) Crawl, 3) Search, 4) Verify, and 5) Connect.



















ALT Logos of various companies listed as contributors to the Agentic Resource Discovery specification: Cisco, Databricks, GitHub, GoDaddy, Google, Hugging Face, Microsoft, NVIDIA, Salesforce, ServiceNow, Snowflake.