
AI & Security Architect building production-ready Agentic AI systems, IAM solutions, and the protocols and frameworks that make enterprise AI implementations se
Joined March 2013
- Tweets 310
- Following 341
- Followers 106
- Likes 401
42 Photos and videos














May 20
GitHub's latest security incident shows where software supply chain risk is moving.
A poisoned VS Code extension reportedly led to an employee device compromise and unauthorized access to internal repositories.
Over the past few months, the same pattern keeps showing up across developer tools, npm packages, browser extensions, AI browsers, and coding agents.
Attackers are moving closer to where credentials, source code, and internal access already live. Agentic tools widens that path because they can read files, search directories, run commands, call tools, and act across the same developer environment.
If credentials, API keys, configs, scripts, packages, or internal files are reachable from the developer environment, treat them as potentially compromised.

1/ We are sharing additional details regarding our investigation into unauthorized access to GitHub's internal repositories.
Yesterday we detected and contained a compromise of an employee device involving a poisoned VS Code extension. We removed the malicious extension version, isolated the endpoint, and began incident response immediately.
52
May 20
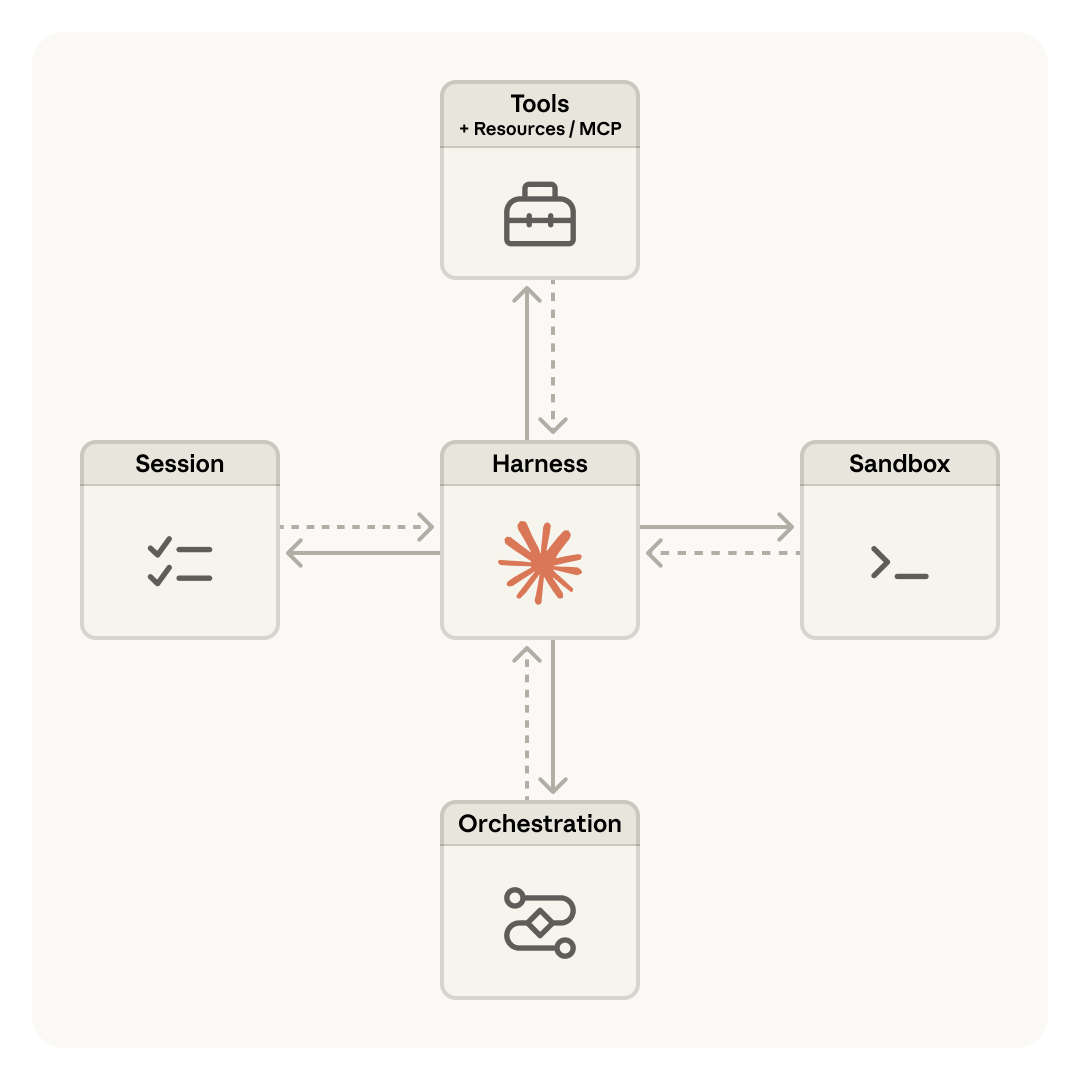
Wrapping internal APIs as tools and piping raw responses back through the model is the wrong architecture for enterprise agents. It is also the default in most frameworks today.
The model ends up sequencing calls, holding state across them, interpreting backend errors, and reasoning over payloads it should never see. Part 1 walked through ten failures that follow from this choice.
This one is about what to do instead.
The model emits a typed intent: onboard this vendor, plan this trip etc and a runtime takes it from there. Capabilities are code files with decorators for dependencies, retries, scopes, and failure policies. The runtime walks the graph, manages state outside the context window, enforces permissions, and returns a small projection the model can reason about.
The model sees two tools regardless of how many capabilities exist behind them. Sensitive data stays in the runtime. Every execution leaves a structured audit record.
linkedin.com/pulse/missing-r…
#softwarearchitecture #systemdesign #distributedsystems #enterprisearchitecture #agentharness #llmops #aiengineering
13
May 18
A good rule of thumb when working with LLMs:
If it gives you three options, choose the fourth.
#llms #softwareengineering #engineeringjudgment #futureofwork
17
Hammad Abbasi retweeted

May 16
Fei-Fei Li warns that AI may be staring too hard at language models.
The world is not just text on a screen.
It is physical, visual, spatial, and always changing. Most of the economy runs on seeing, moving, interacting, and embodied intelligence.
44
75
344
53,605
May 14
hammadabbasi.com/under-the-h…
HTML is great for explaining technical ideas because the page can become part of the explanation.
I used that approach in my LLM explainer. Tokenization, embeddings, attention, probabilities, and inference are easier to understand when you can see the pieces move and connect, instead of only reading about them.

2
32
May 8
AI is making the work faster. Workdays are not getting shorter.
That's the paradox. Execution got cheaper, so the savings got reinvested into more scope and more ambition, not more rest.
The challenge now is spending that leverage on purpose, and keeping enough people deep enough in the system to know what's actually getting shipped.
Read the full piece.
#ai #productivity #futureofwork #softwareengineering #aidevelopment #technology #engineeringleadership
linkedin.com/pulse/ai-effici…
2
19
Apr 27
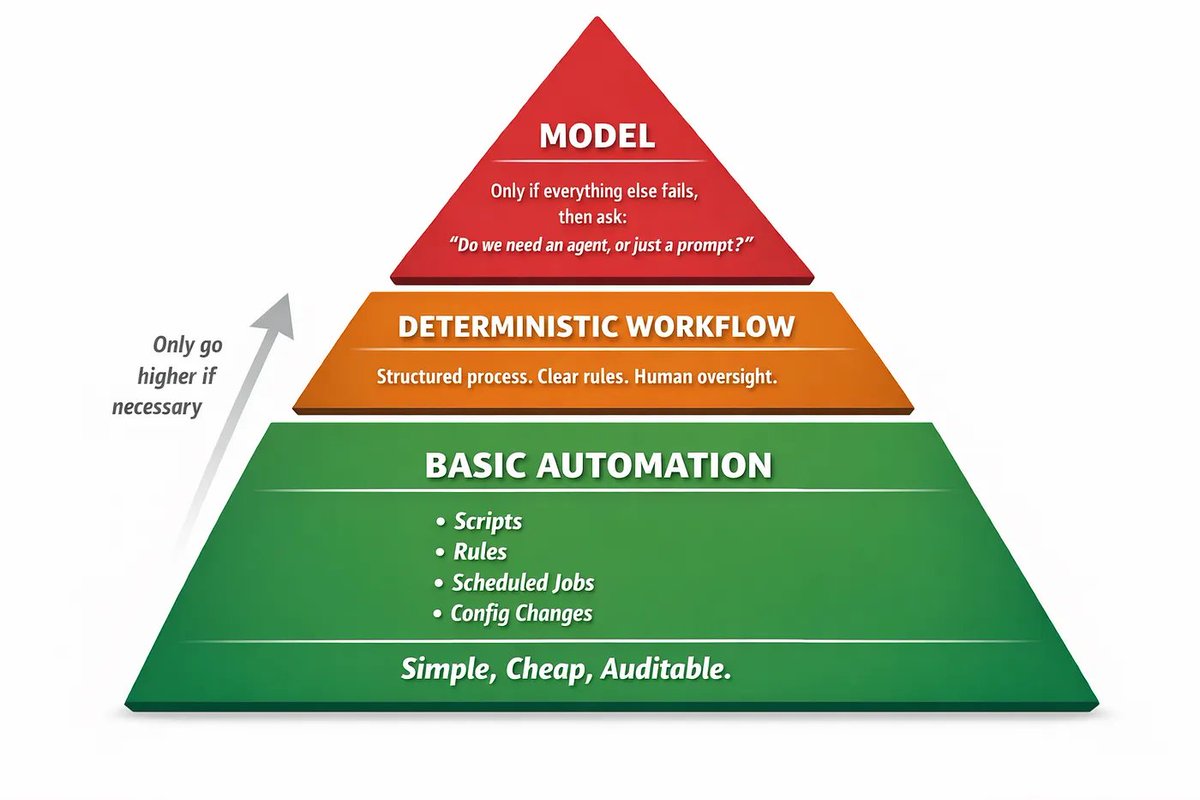
This is what happens when probabilistic systems get deterministic execution power.

37
Apr 21
The point isn't whether these systems are useful. They obviously are. The real question is whether people mistake usefulness for understanding.
Once you collapse that distinction, you start misreading both what these models can do and where the actual risks are.
I made a similar point a couple of years ago here: linkedin.com/pulse/decoding-…
Apr 21

Oxford AI professor Michael Wooldridge: "ChatGPT doesn't understand anything. It's essentially doing some fancy statistics."
41
Apr 20
A lot of people think the job is typing out code. It isn't. Typing is the final output of a much bigger process.
Models can generate code. Fine. That's the easiest, most mechanical part of the craft.
Software engineering is everything that happens before a single line exists. Understanding the problem.
Pushing back on the requirements until they actually make sense.
Designing the system.
Making architectural trade-offs you'll be living with for years.
Thinking about scale, security, reliability, the edge cases nobody mentioned in the meeting.
That's where the real thinking and accountability live.
A model is only as good as the context you hand it, or what it can grep based on your prompt.
Modern coding agents search the repo, open files, follow imports, pull in what looks relevant. That sounds like the agent doing the context-gathering for you. It isn't.
The agent only knows what to grep for because of how you framed the task. Ask the wrong question and it will confidently pull the wrong files and write a confident, wrong answer on top of them.
Knowing what to ask, what's actually relevant, which part of the codebase is load-bearing and which part is dead weight, that's still on you.
The agent's grep is only as good as the prompt that pointed it. Figuring out what to point it at is software engineering.
All the hard parts, what to build, why, how, and under what constraints, still sit with the engineer.
#softwareengineering #codingagents #cursor #claudecode

I don’t have to be convinced that LLM’s make programmers more productive. But where’s all the stuff? We’ve now had months and months of 100x or 1000x programmet productivity improvements. Where’s all the stuff they’re building?
1
63
Apr 20
The core mistake in many agent systems is architectural.
Raw internal endpoints get exposed as tools, and the model is left to handle execution work that should live in a runtime layer: tool selection, execution order, workflow state, policy checks, recovery, user interaction, and the interpretation of backend failures.
That design can look acceptable in a demo because the path is short, the state is fresh, and the missing constraints stay hidden. In production, the same choice creates a predictable set of failures.
This piece is the first in a series about the boundary that needs to move.
An architectural shift already taking shape in production systems: separating reasoning from execution and moving workflow concerns into a governed runtime via code execution rather than leaving them inside the model loop.
#softwarearchitecture #systemdesign #distributedsystems #enterprisearchitecture #agentharness #llmops #aiengineering #agentsystems #executionengine #orchestration #statedesign #systemsintegration
medium.com/gitconnected/the-…
1
50
Apr 8
Anthropic launched Managed Agents today, and the direction makes sense.
In their framing, they're separating the "brain" from the "hands."
I wrote about one part of this shift a few months ago in
medium.com/gitconnected/why-…
That older pattern was always going to run into trouble once agents touched real systems.
The context window is for reasoning. It is not a runtime. And it definitely should not be a data bus carrying tool definitions, retries, intermediate outputs, and orchestration state all at once.
So separating the "brain" from the "hands," keeping long-running state outside the context window, and making the execution interface smaller and more stable all feel like the right moves.
You can see why. Once the tool surface gets big,
things start to break:
- schema drift,
- context bloat,
- multi-hop serialization,
- and security reviews focused on tool lists instead of the actual data flows.
Managed Agents is a cleaner architecture for that world.
I still think the deeper tension is still there though.
The model is still building the workflow.
A probabilistic system is still steering deterministic execution.
What I think comes next is a layer above execution.
That’s what I was trying to describe with Covenant Layer. (medium.com/gitconnected/the-…)
The agent's job should be to define the objective clearly:
- what needs to happen,
- under what constraints,
- with what tradeoffs,
- and with what authority to act.
That is a different job from driving every step of execution.
Once that objective is explicit, the rest of the system can do real coordination work around it:
compare possible ways to satisfy it,
decide what becomes binding,
enforce policy,
verify evidence,
and record what actually happened.
That is the gap I think still exists.
Separating the "brain" from the "hands" is a good move.
But the next step is not just cleaner execution infrastructure.
It is giving the system a coordination layer above execution.
That is where commitments, acceptance, verification, and settlement start to matter.
Let the model handle intent, constraints, tradeoffs, and judgment. But let deterministic systems handle execution, enforcement, and guarantees.
And let the platform track accepted commitments and outcomes, not just calls and logs.
#aiagents #architecture #systemdesign

Shipping a production agent meant months of infrastructure work first.
Managed Agents handles that for you. Define your agent's tasks, tools, and guardrails, and we run it on our infrastructure.
Here's what early customers have built:
2
121
Mar 31
Ever wonder how language models turns your question into an answer?
I built a visual, interactive guides that explains how it works under the hood. hammadabbasi.com/under-the-h…
It covers:
- how AI "learns patterns" from text
- how it pays attention to context in your prompt
- why it breaks words into smaller pieces (tokens)
- how meaning is represented as numbers (embeddings)
-how models are trained and improved
-how responses are generated in real time
If you’re curious about how these systems actually work, this is for you.
#ArtificialIntelligence #GPT #Transformers #DeepLearning
Built with @AnthropicAI #Opus_4_6
41
Mar 31
supply chain attacks are up. pulling in deps just to avoid boilerplate is harder to justify now. a native fetch wrapper can cover baseURL, JSON, creds, 401 redirects, etc. in 10 minutes and it's code you own. codegen is cheap. the bar for adding packages should be higher.
#supplychainsecurity #opensource #npm #axios

🚨 CRITICAL: Active supply chain attack on axios -- one of npm's most depended-on packages.
The latest axios@1.14.1 now pulls in plain-crypto-js@4.2.1, a package that did not exist before today. This is a live compromise.
This is textbook supply chain installer malware. axios has 100M weekly downloads. Every npm install pulling the latest version is potentially compromised right now.
Socket AI analysis confirms this is malware. plain-crypto-js is an obfuscated dropper/loader that:
• Deobfuscates embedded payloads and operational strings at runtime
• Dynamically loads fs, os, and execSync to evade static analysis
• Executes decoded shell commands
• Stages and copies payload files into OS temp and Windows ProgramData directories
• Deletes and renames artifacts post-execution to destroy forensic evidence
If you use axios, pin your version immediately and audit your lockfiles. Do not upgrade.
41
Mar 29
Amazon mandated 80% AI coding tool adoption. Three months later, 6.3 million lost orders and a safety reset across 335 critical systems. The code looked fine. The review process hadn't caught up.
That's the problem nobody wants to talk about. Generation got cheaper. Judgment didn't.
Wrote a deep dive backed by peer-reviewed research and recent security incidents. It goes beyond what went wrong into the deeper questions: what happens to engineering skill when friction disappears, why agents ignore their own rules after long conversations, and how understanding debt is harder to fix than technical debt.
linkedin.com/pulse/when-soft…
#softwareengineering #aicoding #technicaldebt #productivity #futureofwork #llms #cybersecurity #softwaredevelopment #agenticai #codequality #engineeringculture
2
1
35
Mar 24
Been saying this for the last year: giant tool registries are the wrong abstraction. The scalable pattern is agents writing code and running it in governed sandboxes. Great to see Cloudflare push this forward. medium.com/gitconnected/why-…
#aiagents #codemode #codeexecution #mcp #toolcalling
Mar 24

We’re introducing Dynamic Workers, which allow you to execute AI-generated code in secure, lightweight isolates. This approach is 100 times faster than traditional containers. cfl.re/4c2NvPl
48
Mar 23
Interesting times!! We're entering a phase where the industry is so focused on speed, lower friction, seamless automation, and growth that security is quietly being pushed into the background.
What matters here is not just whether an agent can use your computer. It's whether we're comfortable turning these systems into remote operators with real authority over our inbox, files, apps, workflows, and actions, before we've built a serious security model around that authority.
A system like that is not merely a productivity tool. It creates a new attack surface: prompt injection through documents, web pages, logs, or on-screen content; excessive permissions that turn assistance into remote operational reach; extension and tool abuse; human review steps skipped because they are treated as friction; and data exfiltration hidden behind the language of convenience.
What makes this category dangerous is not just model error, but the fact that it packages surveillance, action, and automation into one trusted workflow that can be abused far more easily.
And what we are missing in this rush is critical thinking. Not just asking whether something can be automated, but whether it should be automated this way in the first place. Sometimes the most important step is to zoom out and question the problem itself, the tradeoffs being ignored, and whether removing friction is also removing the judgment, oversight, and restraint that were protecting the system to begin with.
The biggest AI failures (in my view) won't come from bad outputs. They'll come from systems doing the wrong thing very efficiently (because that is exactly what they were designed to optimize for)
#ai #aiagents #agenticai #security #aisafety #riskmanagement #cybersecurity #automation #governance #trust
Mar 23

Today, we’re releasing a feature that allows Claude to control your computer: Mouse, keyboard, and screen, giving it the ability to use any app.
I believe this is especially useful if used with Dispatch, which allows you to remotely control Claude on your computer while you’re away.
55
Mar 15
I've been running local models for a while now, and the thing that hits you first isn't benchmark scores. It's speed. A slow model, even a smart one, kills the experience fast.
That's what makes speculative decoding worth paying attention to.
Instead of having the large model generate every token by itself, you pair it with a small draft model. The small one quickly guesses the next few tokens, the large one checks them. Correct guesses get accepted in bulk. Wrong ones get corrected and you move on. Same output, just faster.
Think of it as: small model drafts, big model reviews. The large model stays the final authority, but stops burning cycles on every single token.
Why this matters for local use specifically is that tok/s is the thing you actually feel. Not model size. Not leaderboard rankings. Just: how fast does it become usable?
Code generation is a strong fit because many programming tasks contain repeated, predictable patterns. If you ask a local model to build a simple simulation, much of the output follows common structures such as data setup, state transitions, control flow, helper functions, and result reporting. That gives the draft model a better chance of predicting useful token sequences, allowing the larger model to verify and accept larger spans rather than producing every token from scratch.
Structured code is more predictable than prose, so the gains tend to be bigger there.
LM Studio shared numbers that make this concrete. On a quicksort prompt, speculative decoding pushed throughput from 7.30 to 17.74 tok/s on an M3 Pro . On an explanation prompt, the gains were smaller. Open-ended text is harder to predict.
Speculative decoding makes the inference faster. The large model stays the final authority, it just stops wasting time on every tiny step.
That feels like where local AI goes next. Not just through better models, but through better engineering around them. The problem now is turning raw capability into something fast enough to feel good in practice.
Paper : arxiv.org/abs/2603.03251
#localllm #localai #speculativedecoding #llminference #aiinference #opensourceai #llmops #modeloptimization
37
Mar 13
Industry has spent the last wave of AI Agent infrastructure trying to make models behave like software operators: calling tools, clicking UIs, stitching workflows, and carrying the full burden of execution.
That works (kind of) but it is still forcing probabilistic systems to directly operate deterministic systems.
The next layer of the stack is one where agents coordinate outcomes instead of directly driving every system themselves.
That means: agents express objectives, providers compete with explicit offers, acceptance creates a real commitment, fulfillment happens in provider-owned systems, evidence proves what happened, and blockchain anchors settlement, stake, and reputation.
That’s the idea behind Covenant Layer: an open protocol framework for moving AI systems from tool orchestration to accountable coordination.
Agents coordinate. Providers fulfill. Blockchain settles.
The future of the agent stack is outcome coordination, because the real world runs on commitments, not function calls.
github.com/csehammad/covenan…
#AI #AIAgents #AgenticAI #Blockchain #Protocols #OpenSource #CovenantLayer
34