
Jun 11
Most AutoML tools pick the model with the best accuracy and stop there. I think that misses half the problem.
Two candidate models can have almost the same predictive power, but very different execution costs in production. One is lean. The other runs heavier on every inference call.
Our platform builds a penalty for computational complexity into the selection algorithm. So the search doesn't just rank by accuracy. It actively eliminates models that are expensive to run.
What I find useful in practice: the algorithm usually lands on a simpler model that's nearly as good as the top performer. We trade a fraction of a percent in accuracy for a real cut in inference cost. At high request volumes, that's the difference that matters.
In the full webinar I show what that cost gap looks like under real load, measured on a deployed system.
Watch the full webinar: eu1.hubs.ly/H0w3PgX0
#automl #mlops #machinelearning #modeloptimization #datascience
2
8

May 19
3 layers. 17 models. 7 architectures. 85% accuracy.
We tested jailbreak detection using just 3 layers selected by activation patterns, across every major open-source model family: Mistral, Llama, Qwen, Olmo, and others. Models ranged from 0.5B to 32B parameters.
The accuracy held between 85.2% and 87.1% across all of them.
Here's the part that surprised us: in most cases, using all layers actually performed worse. The full network introduces noise from layers that aren't relevant to the classification task. Targeted selection removes that noise.
This means the method is architecture-agnostic. The signal Starseer identifies isn't specific to one model family. It's structural. When your model stack evolves, the same interpretability approach transfers without a rewrite.
3 layers out of 24 to 64. That's not a shortcut. That's precision.
Full results in our latest research: na2.hubs.ly/H05qvdG0.
#AI #ModelOptimization #AISafety #Interpretability #MLOps

2
103
May 15
Your guardrail is slower than your model.
Most AI safety stacks run a separate 7–9B parameter guard model alongside production inference. ShieldGemma-9B adds 570ms. WildGuard-7B adds 106ms. Every request, every time.
Starseer's interpretability-based probe runs in ~38ms.
Same task. Near-identical accuracy (0.9918 vs 0.9953 AUC). Roughly 1,000x fewer parameters.
The difference: instead of running a second model, we read the activation patterns already present in your model's inference pass. The signal is already there. We just extract it.
2.7x faster than the best open-source guard model. 15x faster than the slowest. At production scale, that latency gap compounds into real cost.
Full benchmark comparison in our latest blog post. Learn more at info@starseer.ai.
#AI #AISecuirty #Guardrails #ModelOptimization #Interpretability

2
34

Apr 21
How do we define "best-in-class" AI? 📊 Tom Mulder, founder of Algoryn, joins #GOSIMParis2026 to share his insights on optimizing model deployment and ensuring high-stakes performance in the era of Agentic AI.
📅 May 5–6 | Station F | paris2026.gosim.org/
👉Chance to apply for your limited free ticket via Luma: luma.com/fmi2hnwy
#GOSIMParis2026 #Algoryn #ModelOptimization #AIInfra #Performance @darkseed

2
43

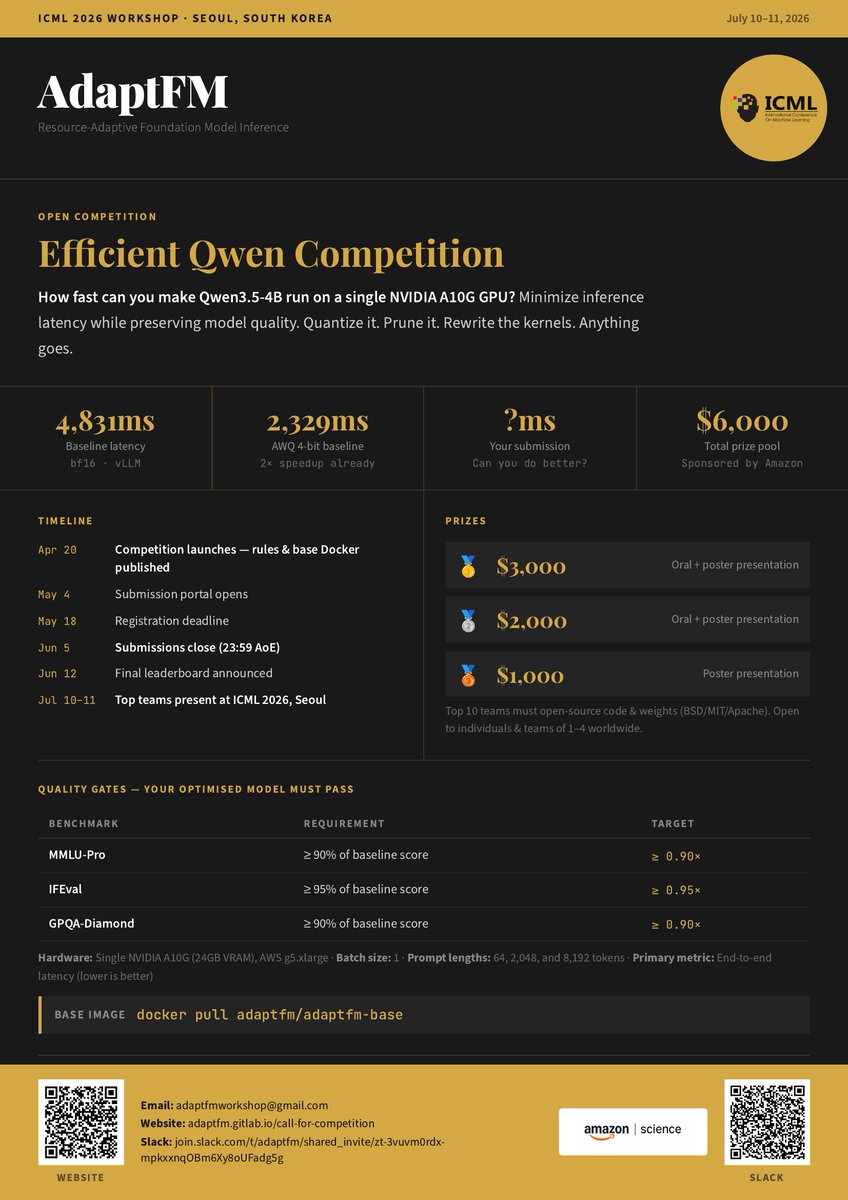
🚀 We're launching the Efficient Qwen Competition @ AdaptFM #ICML2026!
How fast can you make Qwen3.5-4B run on a single A10G without breaking it?
$6,000 in prizes. Open to all. Submissions open May 4.
👉 adaptfm.gitlab.io/call-for-c…
#LLM #EfficientML #ModelOptimization
2
2
2
435

📣 Deal of the Day 📣 Apr 9
Save 45% TODAY ONLY!
Rearchitecting LLMs & selected titles: hubs.la/Q04bf8_j0
Structural techniques for efficient models.
@PereMartra #LLMs #LLMOptimization #SLMs #TinyLLMs #Gemma #Qwen #Llama3 #ModelPruning #KnowledgeDistillation #EfficientLLMs #ModelCompression #StructuredPruning #ModelOptimization
This book turns research from the latest AI papers into production-ready practices for domain-specific model optimization. As you work through this practical book, you’ll perform hands-on surgery on popular open-source models like Llama-3, Gemma, and Qwen to create cost-effective local small language models (SLMs). Along the way, you’ll learn how to combine behavioral analysis with structural modifications, identifying and removing parts that don’t contribute to your model’s goals, and even use “fair pruning” to reduce model bias at the neuron level.

1
5
28
989

Mar 28
MiniMax Unveils Self-Evolving M2.7 AI: Handles 50% of RL Research cysecurity.news/2026/03/mini… #AIAutonomy #MiniMaxM27 #ModelOptimization

2
4
510
📣 Deal of the Day 📣 Feb 2
HALF OFF NEW MEAP!
Rearchitecting LLMs: Structural techniques for efficient models & selected titles: hubs.la/Q041hX8j0
This book turns research from the latest AI papers into production-ready practices for domain-specific model optimization. @PereMartra #LLMs #LLMOptimization #SLMs #TinyLLMs #Gemma #Qwen #Llama3
As you work through this practical book, you’ll perform hands-on surgery on popular open-source models like Llama-3, Gemma, and Qwen to create cost-effective local Small Language Models (SLMs). You’ll learn how to combine behavioral analysis with structural modifications, and even use "fair pruning" to reduce model bias at the neuron level. #ModelPruning #KnowledgeDistillation #EfficientLLMs #ModelCompression #StructuredPruning #ModelOptimization

3
12
73
2,334


31 Dec 2025
Good Morning CT 🌞
AI doesn’t win in theory it wins in production.
@inference_labs Labs sharpens models for speed, efficiency, and real world reliability.
@alturax ensures those models don’t just run they scale, securely and smoothly.
This is what happens when optimization meets infrastructure built for impact.
#AIInfrastructure #ModelOptimization #Inference #Alturax #InferenceLabs

110
47
109
1,057

17 Dec 2025
Most people use @OpenGradient like a demo.
Power users treat it like a workflow.
A few practical tips that make a real difference when using @OpenGradient day to day:
Start with one clear variable.
Instead of changing prompts, models, and parameters at once, lock everything except one input. This makes gradients and performance shifts immediately obvious instead of noisy.
Reuse gradients, not just outputs.
If a run behaves well, duplicate the gradient setup and iterate from there. You save time and preserve signal instead of restarting from scratch.
Think in evaluation loops.
Short runs fast feedback beat long, “perfect” runs. OpenGradient shines when you treat it as an experiment engine, not a one-shot generator.
Name and tag experiments early.
Future you will thank present you. Good labeling turns your history into a knowledge base, not a graveyard of runs.
Optimize last, explore first.
Don’t chase efficiency before you understand behavior. Exploration creates intuition, optimization compounds it.
OpenGradient isn’t just about better outputs.
It’s about learning why models behave the way they do — and turning that understanding into leverage.
#OpenGradient #AIWorkflow #ModelOptimization #MLTools #Builders

3
4
28

11 Dec 2025
Inference is becoming the real battleground in AI, not training, not hype, but the race to make models think fast, cheaply, and everywhere. We still glorify scale while ignoring the economics that actually decide adoption.
The next winners won’t be the labs with the biggest checkpoints they’ll be the teams that compress latency, optimize routing, and squeeze maximum intelligence out of every millisecond. From on-device acceleration to decentralized GPU networks to execution layers that adapt per query, the entire stack is converging on a single metric: how quickly can you deliver aligned, context-aware output at global scale?
Inference is no longer a backend detail. It’s the user experience, the moat, and the power center of the next AI cycle. #AI #InferenceEconomics #TechTrends #GenAI #FutureOfCompute #AIEfficiency #ModelOptimization #LLM时代
11 Dec 2025

Dolomite’s design changes the usual lending logic: instead of limiting collateral to protect the system, it limits risk domains so the system can expand. Isolation markets contain blast radius, while the rest of the liquidity stays fully composable. That’s how real scale happens.
9
8
124

9 Dec 2025
Good morning grad community
1/The Gradient Network just dropped something different.
Something that doesn’t just optimize models
It controls the entire flow of learning.
Meet CATION the new engine of stability and precision.
#GradientNetwork #AI #DeepLearning
2/Deep-learning gradients are wild.
Noisy Chaotic Unpredictable.
CATION steps in like a stabilizer beam turning unstable training into a clean controlled stream.
Think: chaos → clarity.
#MachineLearning #AIEra #TrainingStability
3/CATION is built to DOMINATE gradient flow
🔥 Smoother updates
🔥 Zero oscillation madness
🔥 Hyper-stable convergence
🔥 Smarter internal dynamics
Your models don’t train
They glide.
#AIInnovation #ModelTraining #MLTech
4/Inside the Gradient Network CATION acts like a precision engine.
Every update becomes intentional.
Every step aligns with the optimal learning path.
No wasted compute. No noise Just pure signal.
#GradientEcosystem #AIDev #TechUpgrade
5/And the early results?
🚀 Faster convergence
🚀 Cleaner loss curves
🚀 Lower training variance
🚀 Massive stability gains
This isn’t a tweak it’s a LEVEL UP. 📈
#AIPerformance #FutureOfAI #ModelOptimization
6/CATION isn’t an optimizer
It’s a flow control system for the Gradient Network.
A new layer of intelligence keeping models locked on target even at scale.
#DeepLearningTech #AIEngineering #MLResearch
7/ FINAL
The future of the Gradient Network is stable smooth and insanely efficient powered by CATION.
This is the upgrade nobody saw coming but everyone needed.
The era of chaotic training is over.
Welcome to controlled convergence.
#GradientNetwork #CATION #AIScaling #MLCommunity @Gradient_HQ

5
1
5
105

7 Dec 2025
📰🚨Amazon Bedrock adds reinforcement fine-tuning simplifying how developers build smarter, more accurate AI models
#ReinforcementLearning #AmazonBedrock #AICustomization #MachineLearning #ModelOptimization
ift.tt/4iubT67
15
678

5 Dec 2025
Reinforcement Learning for LLMs just got a blueprint — and it starts with a first-order approximation.
Reinforcement learning is powering the next generation of reasoning-capable LLMs… but anyone who has trained RL on large models knows one truth:
👉 Stability is the real bottleneck.
Collapse, oscillation, reward hacking, and training–inference mismatch have become recurring nightmares.
The Qwen team’s new paper, “Stabilizing Reinforcement Learning with LLMs: Formulation and Practices,” delivers one of the cleanest explanations yet of why LLM RL breaks and more importantly, how to fix it at scale.
Here’s the big idea:
💡 The Token-Level Objective Isn’t Wrong, It’s an Approximation
The paper proposes a first-order approximation showing that token-level objectives like REINFORCE can optimize sequence-level rewards… but only when two gaps remain small:
- Training–Inference Discrepancy
The numerical mismatch between the training engine (Megatron/FSDP) and inference engine (vLLM/SGLang).
This mismatch alone is enough to destabilize RL, especially in FP8 inference settings.
- Policy Staleness
When rollouts and updates are out of sync (off-policy updates, batching, async rollout, etc.), the approximation breaks.
When either gap grows too large → gradients explode, KL spikes, and RL collapses.
🧠 Why MoE Models Are Especially Fragile
- For Mixture-of-Experts models, expert routing magnifies both problems:
- Training & inference may activate different experts
- Parameter updates shift routing, worsening policy staleness
This explains why RL on MoE models is notoriously unstable compared to dense models.
🔧 The Fix: Importance Sampling Clipping Routing Replay
The team shows, across hundreds of thousands of GPU hours, that three techniques consistently stabilize RL:
✔ Importance Sampling (IS) correction
✔ Clipping to restrain aggressive updates
✔ Routing Replay (R2/R3) for MoE to freeze experts during updates
Their findings:
On-policy RL?
Simple IS-corrected REINFORCE is surprisingly the most stable.
Off-policy RL?
Routing Replay becomes essential —
R2 works better at small off-policiness,
R3 wins at large off-policiness.
Initializations matter less than stability.
Once RL is stable, different cold-starts converge to nearly identical final performance.
If you’re building reasoning models, MoE models, or scaling RL pipelines, this is the paper you should read this week.
#ReinforcementLearning #LLMTraining #LargeLanguageModels #AIResearch #RLHF #MoE #DeepLearning #MachineLearning #Qwen #AIStability #AIGovernance #ModelOptimization #AIEngineering

1
3
6
1,240
3 Dec 2025
📰🚨 Amazon Bedrock adds reinforcement fine-tuning simplifying how developers build smarter, more accurate AI models
#ReinforcementLearning #AmazonBedrock #AICustomization #MachineLearning #ModelOptimization
ift.tt/4iubT67
2
5
154

7 Nov 2025
How Model Routing Revolutionizes AI Performance.
What if I told you that the secret to lightning-fast AI responses isn't bigger models, but smarter traffic control? Enter model routing - the unsung hero of AI optimization that's changing everything we thought we knew about performance.
1️⃣ What is Model Routing?
Think of model routing as the air traffic control system for AI requests. Instead of sending every query to your most powerful (and resource-intensive) model, routing intelligently directs each request to the most appropriate model based on:
<> Query complexity.
<> Required accuracy.
<> Response time needs.
<> Resource availability.
<> Historical performance patterns.
It's like having a team of specialists instead of asking a neurosurgeon to treat a common cold!.
2️⃣ The Performance Magic Behind Model Routing:
<> Speed Boost: Simple queries bypass heavy models entirely.
i.) What's the weather?" → Routes to lightweight weather model.
ii.) Translate 'hello' to Spanish" → Routes to specialized translation model.
iii.) Result: 5-10x faster responses for common tasks
<> Resource Optimization:
i.) Only complex queries reach your resource-heavy models.
ii.) 60-70% reduction in computational overhead.
iii.) Lower energy consumption and costs.
<> Accuracy Preservation:
i.) Complex queries still reach your most capable models.
ii.) Specialized models often outperform generalists on specific tasks.
iii.) Overall system accuracy maintained or improved.
3️⃣ The Technical Architecture That Makes It Possible.
Model routing systems typically employ:
<> Query Analysis Layer:
i.) Natural language understanding to classify intent.
ii.) Complexity assessment algorithms.
iii.) Historical pattern matching.
<> Routing Decision Engine:
i.) Machine learning models trained on performance data.
ii.) Real-time system load considerations.
iii.) Cost-benefit optimization algorithms.
<> Model Registry:
i.) Detailed metadata about each model's capabilities.
ii.) Performance benchmarks.
iii.) Resource requirements and specialization metrics.
4️⃣ Real-World Performance Gains.
The numbers speak for themselves:
<> Enterprise Case Study:
i.) 73% reduction in response time.
ii.) 64% decrease in computational costs.
iii.) Maintained 98% of accuracy compared to using .only the largest model
<> Mobile Application:
i.) Extended battery life by 2.5 hours.
ii.) Reduced data usage by 68%.
iii.) Near-instant responses for common queries.
<> High-Traffic Platform:
i.) Handled 3.4x more concurrent users.
ii.) Reduced server costs by $2.3M annually.
iii.) Improved user satisfaction scores by 42%.
5️⃣ The Future of Intelligent Model Routing
<> Predictive Routing: Systems that learn from user behavior to pre-route likely queries.
<> Federated Routing: Distributed routing across edge devices and cloud resources.
<> Self-Improving Routing: Routing systems that optimize their own decision-making.
<> Cost-Aware Routing: Balancing performance, accuracy, and operational costs in real-time.
<> The Bottom Line:
Model routing transforms AI systems from blunt instruments into precision tools. It's the difference between using a sledgehammer for every task and having exactly the right tool for each job.
The result? Faster, cheaper, and more efficient AI that doesn't sacrifice quality for performance.
What's your experience with model routing? Have you implemented it in your systems? Share your thoughts below! 👇 @SentientAGI
#AI #MachineLearning #ModelOptimization #PerformanceEngineering #ArtificialIntelligence #SentientAGI

6 Nov 2025

Why do 10 agents working together often perform WORSE than 2 agents working in parallel? The counterintuitive truth about multi-agent systems will change how you think about distributed intelligence.
Why Parallel Execution is the Secret Sauce of Multi-Agent Efficiency:
<> PART 1: THE PARADOX OF MORE AGENTS:
When we build multi-agent systems, we intuitively think "more agents = more power." But here's the shocking reality: most multi-agent systems suffer from what I call the "Agent Traffic Jam" phenomenon.
Imagine 10 delivery agents in a city. If they all follow the same central instructions and communicate through a single dispatcher, you'll see:
i.) Communication bottlenecks
ii.) Resource contention
iii.) Decision paralysis
iv.) Redundant work.
The result? Your 10-agent system might perform at 30% efficiency compared to 2 agents working optimally.
<> PART 2: THE PARALLEL EXECUTION REVOLUTION:
This is where ROMA's parallel execution architecture changes the game. Unlike traditional sequential processing, ROMA implements what I call "Intelligent Task Partitioning" (ITP).
Here's how it works:
i.) Dynamic Task Decomposition: Complex problems are automatically broken into independent subtasks.
ii.) Agent Specialization: Each agent receives tasks matching their current capabilities and context.
iii.) Asynchronous Execution: Agents work on different tasks simultaneously without waiting.
iv.) Conflict-Free Resource Management: ROMA's scheduling algorithm prevents resource contention
The result? Multi-agent systems that scale linearly rather than collapsing under their own weight.
<> PART 3: THE MATHEMATICAL BEAUTY:
The efficiency gain isn't just anecdotal, it follows a beautiful mathematical principle:
Traditional sequential multi-agent systems follow: Efficiency = 1/(1 n(n-1)/2)
Where n = number of agents, and the denominator represents communication overhead.
ROMA's parallel execution follows: Efficiency = n/(1 log₂(n))
This means ROMA achieves near-linear scaling up to hundreds of agents, while traditional systems collapse after just a handful.
<> PART 4: REAL-WORLD APPLICATIONS:
The parallel execution advantage isn't theoretical, it's transforming industries:
Autonomous Vehicle Fleets: ROMA-powered systems coordinate hundreds of vehicles with minimal central oversight, achieving 3.7x better traffic flow than traditional dispatch systems.
Distributed Computing: One ROMA-managed network of 500 nodes completed a complex protein folding simulation 47x faster than a traditional cluster of the same size.
Supply Chain Optimization: Companies using ROMA report 62% reduction in delivery times during peak demand periods.
<> PART 5: THE FUTURE OF COLLABORATIVE INTELLIGENCE:
The parallel execution paradigm represents a fundamental shift in how we think about collective intelligence. Instead of forcing agents to conform to a centralized model, ROMA embraces the natural parallelism of distributed systems.
The next frontier? Self-optimizing parallel execution where agents dynamically reconfigure their parallelization strategies based on real-time performance metrics.
CONCLUSION: LESS IS MORE, MORE IS LESS
The counterintuitive truth about multi-agent systems is that the key to scaling isn't better communication, it's smarter parallelization. By allowing agents to work independently on properly partitioned tasks, ROMA achieves what traditional systems cannot: efficient collaboration at scale.
The question isn't "how many agents do you need?" but "how can you make your agents work better in parallel?" @SentientAGI
#MultiAgentSystems #ParallelComputing #ROMA #DistributedIntelligence #SentientAGI
2
7
85
5 Nov 2025
📢 When optimizing LLM systems, most teams focus on prompt engineering or model compression but overlook a major hidden cost: data formatting.
Every JSON key, bracket, and redundant character adds to your token count and tokens are money.
TOON (Token-Oriented Object Notation) takes a different approach.
Instead of representing data in verbose, human-oriented syntax like JSON, TOON encodes it in a compact, model-friendly structure that dramatically reduces the number of tokens an LLM has to process.
Think of it as a compressed representation of structured data — same meaning, fewer tokens.
Less textual noise means lower prompt sizes, faster responses, and significantly reduced inference costs.
In short, TOON rethinks the data layer, not the model, to make large-scale AI deployments leaner and more sustainable.
🔗 Check it out here: hubs.la/Q03RRK7Q0
🧠 Efficiency isn’t just about smarter models — sometimes, it’s about smarter data.
#LLM #TOON #AIOptimization #TokenUsage #DataEfficiency #LLMScaling #ModelOptimization #OpenSource #AIEngineering #AIInfra #PromptDesign #AIDevelopment #AICostSavings

1
2
2
1,286

5 Oct 2025
🚀 Revolutionizing AI with CAMEL-AI’s Microsandbox and WeChat Integration
👨💻 For tech enthusiasts, this is a game-changer!
💡 Architecture Advantage:
CAMEL-AI’s latest update introduces Microsandbox, a MicroVM-based local sandbox solution, and seamless WeChat Official Account integration. These innovations redefine secure code execution and multi-agent workflows.
⚡ Performance Gains:
- Microsandbox: Lightning-fast startup under 200ms with VM-level security, supporting Python, Node.js, and shell commands.
- WeChat Integration: Enables AI agents to handle text, image, voice, and video messaging, revolutionizing customer service and social media automation.
🎓 Insights from the Experts:
@fchollet (Creator of Keras): "The point of AI isn’t to mimic humans but to create new minds to explore the universe."
@soumithchintala (Creator of PyTorch): "CAMEL-AI’s native toolkits are setting a new standard for agent frameworks."
📢 This approach is poised to become the next mainstream in AI development.
#AI #ModelOptimization #DevNotes
1
85

2 Oct 2025
At the upcoming #AppliedAISummit, Yuxiong He, AI Research Lead at Snowflake, will share how the Arctic Interference project is challenging long-held assumptions in model serving.
Register today: hubs.li/Q03LSM6v0
#LLM #ModelOptimization #AIInfrastructure #LLMInference

1
5
250