
Working on agentskills.io | All my issues are skill issues
Joined August 2024
- Tweets 173
- Following 152
- Followers 43
- Likes 9,778
10 Photos and videos









Jun 12
In addition to leaking neuralese, models can have bothersome verbal or behavioral tics.
I can imagine a future where users only interact with "chief of staff" agents that embody and enforce user preferences, delegating all work to other agents and acting as a filter.

fascinating because 5.5 does this too. invent weird technical jargon. perhaps you’re right and it’s a neuralese leakage
2
31
Jonathan Hefner retweeted

Jun 5
The skills.sh API is now generally available.
Power your agents, applications and platforms with access to over 600,000 skills ↓
vercel.com/changelog/the-ski…
7
30
405
127,029

Grok now has skills

4,363
5,557
48,458
23,570,921
Some people argue that skills will become obsolete as models improve. That may be true to some extent, but models will never know exactly how you (or your company) want things done. Personalization is a fantastic (and often overlooked) use case for skills.
Apr 29

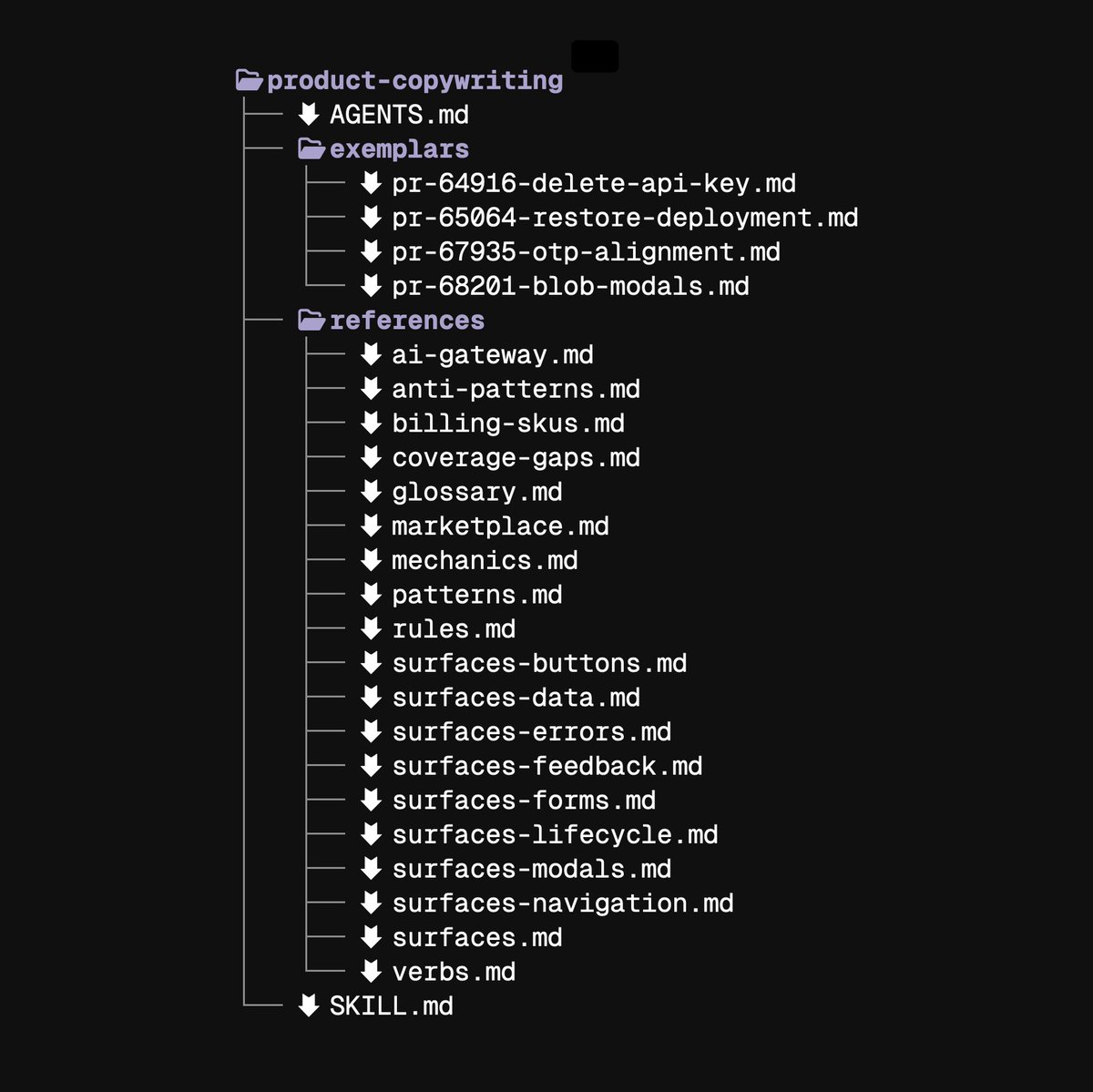
we made a skill to help coding agents humans write & design in the vercel way
- how to write and use our design system
- consistent terminology and workflows
- clear & concise writing
2
130
Jonathan Hefner retweeted

Apr 26
I’ve seen people on X dunking on folks like @garrytan @doodlestein and others for sharing SKILL dot md files they've built. They are dismissing these files as "just a markdown file.”
I think this misses the point entirely and I'll try to address that here. Quick thread:
A bad skill file is just text, sure.
A good skill file is compressed expertise, packaged in a format an agent can actually use.
The value is not just in the “markdown file.” The value is the interaction between:
a huge neural network with latent capabilities
a precise, reusable, agent-readable procedure that steers those capabilities toward a specific outcome
That combination is the product.
Saying “it’s just markdown” is like saying Hamlet is “just ink on paper,” or Einstein’s relativity paper was “just a text.”
Technically true. Intellectually useless.
The medium is simple. The content is what matters. And more importantly, the effect of that content on the reader is what matters.
With humans, a book, a coach, a lecture, or painting can change how someone thinks and acts.
With LLMs, text is also the control surface. These models were trained on text, reason through text, call tools through text, and follow procedures through text.
So yes, the skill is “just text.”
But it is text designed to be read by an enormous neural net.
That matters.
A good skill is agent-ergonomic. It does not merely say “do this better.” It encodes workflow, constraints, examples, edge cases, tool usage, failure modes, and success criteria in a way the agent can reliably execute.
That is very different from a casual prompt.
A prompt is often a one-off request.
A skill can be reused, versioned, tested, improved, shared, and loaded at the exact moment an agent needs it.
That turns “vibes-based prompting” into something closer to operational knowledge.
Another way to think about it:
We have built these massive models, but much of their power is latent. Different people can extract very different levels of performance from the same model.
A good skill is a way to actualize a specific slice of that latent capability.
A refactoring skill.
A research skill.
A legal review skill.
A math explanation skill.
A codebase-navigation skill.
Each one can make the same model behave very differently.
I think of Cus D’Amato and Mike Tyson.
Tyson had enormous latent potential. But Cus gave him a system, a style, a discipline, a way to channel that potential.
That’s what good skills are for agents.
They are not magic. They are not all equally valuable. Many will be mediocre or useless.
But dismissing them right off the batt because they are “just markdown” shows a misunderstanding of what LLMs are.
Text is how we trained these systems. (for the most part)
Text is how we steer them.
Text is how we unlock parts of what they can do.
The question is not whether a skill file is “just text.”
The question is whether the text reliably makes the model perform better at a valuable task.
If yes, then it is not “just markdown.”
It is leverage.
10
7
53
11,605
Apr 19
People tend to discount momentum. When a company makes a bad choice, people predict failure, but momentum can paper over bad choices. And it cuts both ways: companies assume success is due to correct choices instead of momentum — when momentum eventually runs out, they fall hard.
82
Apr 18
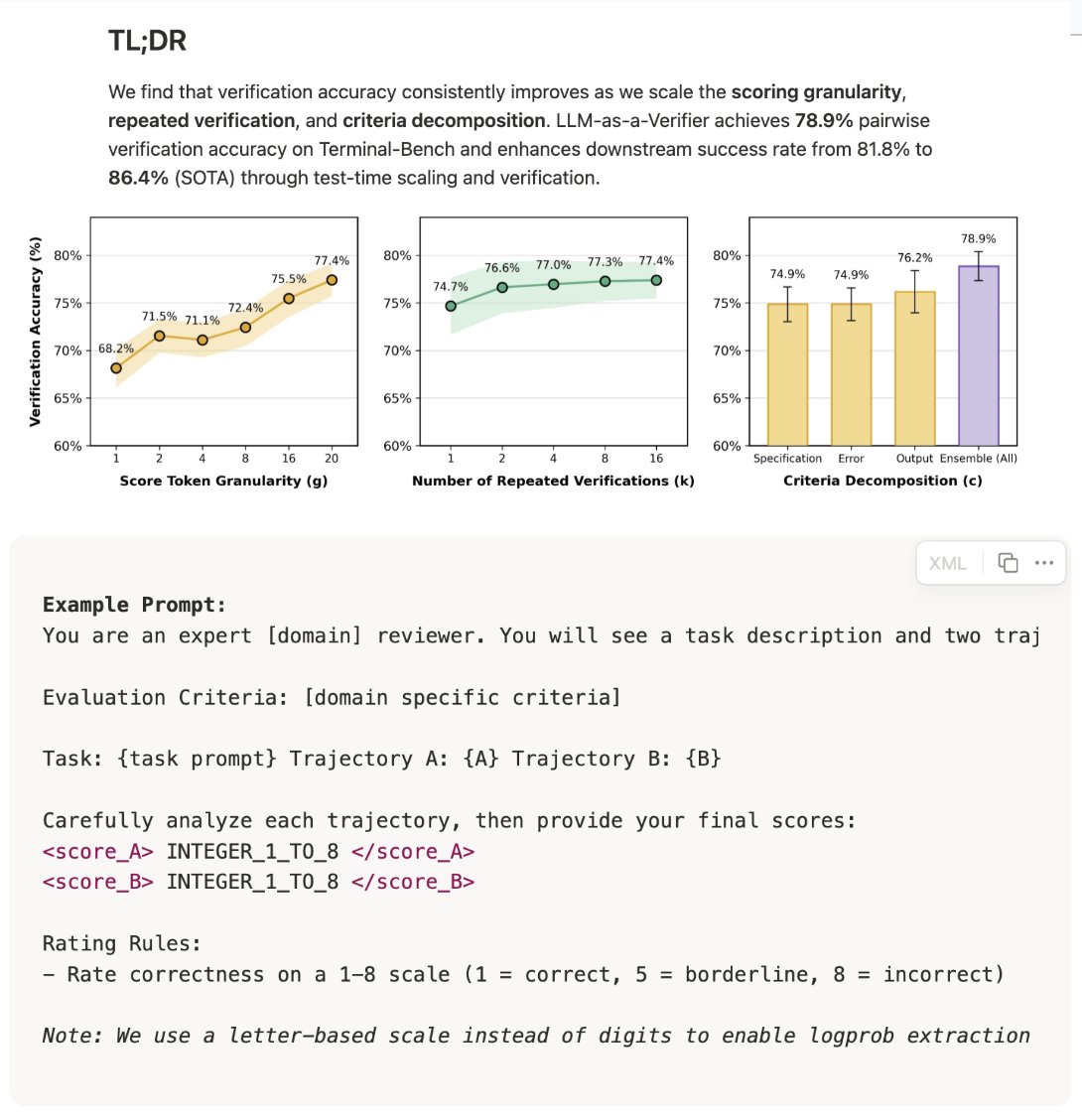
Using probabilistically-weighted average of score output tokens to improve LLM-as-a-Judge effectiveness with higher score granularities. Freaking clever.

Strongly recommend the LLM-as-a-Verifier writeup.
Biggest takeaway for me is that increasing scoring granularity makes the verifier more effective. This indicates that LLM judges / verifiers are developing new (and better) capabilities.
This did not work well 1-2 years ago. In fact, LLM-as-a-Judge best practice was that lower scoring granularity (e.g., binary, ternary, or 1-5 Likert score) worked way better than granular scores (e.g., 1-100 scale). This was a constant recommendation I gave for setting up LLM judges properly. It seems like recent frontier LLMs now are better at scoring at finer granularities, making this best practice (potentially) obsolete.
One caveat to this finding is that the scoring setup used in this writeup is a specific setup based upon logprobs. Instead of just using the score token outputted by the LLM as the result, they compute the logprob of each possible score token and take a weighted average of scores (with weights given by probabilities). Then, they go further by expanding this weighted average across repeated verifications and multiple criterion:
Reward = (1 / CK) * ∑_{c=1}^{C} ∑_{k=1}^{K} ∑_{g=1}^{G} score_logprob * score_value
where C is the total number of evaluation criterion, K is the number of repeated verifications, and G is the scoring granularity (i.e., number of unique scoring output options). The reward determines if a particular output passes verification across criteria.
When using this logprob setup, we see consistent gains in verifier accuracy by:
- Increasing scoring granularity G.
- Increasing repeated verifications K.
- Increasing the number of evaluation criterion C.
The last two findings are in line with prior work, but the fact that higher scoring granularity is helpful is interesting!
In the LLM-as-a-Verifier paper, this system is used at inference time in a pairwise fashion as described below.
"To pick the best trajectory among N candidates for a given task, a round-robin tournament is conducted. For every pair (i, j) the verifier produces Reward(i) and Reward(j) using the formula above. The trajectory with the higher reward receives a win, and the trajectory with the most wins across all \binom{N}{2} pairs is selected."
1
106
Jonathan Hefner retweeted

Apr 18
anyone wants to see the SkillsBench team host a Design Skills Arena?

5
1
23
903

Today, we’re introducing Skills in @GoogleChrome, a new way to build one-click workflows for your most frequently used AI prompts — like asking for ingredient substitutions to make a recipe vegan, generating side-by-side shopping comparisons across multiple tabs, or scanning long docs to get the info you need quickly.
When you write a prompt that you want to use again, you can save it as a Skill directly from your chat history. The next time you need it, select your saved Skill in Gemini in Chrome by typing forward slash ( / ) or clicking the plus sign ( ) button, and your Skill will run on the page you’re viewing, along with any other tabs you select.
224
986
6,214
1,277,175
Apr 17
A challenger appears!
Apr 16

gh skill adds commands to GitHub CLI to discover, install, manage, and publish AI agent skills from GitHub repos.
• Pin skills to tags or commits to control updates and ensure supply chain security
github.blog/changelog/2026-0…
43
Jonathan Hefner retweeted

Apr 12
Skills are "just markdown" in the same way that:
- Deep learning is "just gradient descent"
- LLMs are "just next-token predictors"
The simplicity of the method doesn't make the learning any less real
28
11
180
27,781
Jonathan Hefner retweeted
Apr 8
How well are agents at using the latest CLI tools like GWS CLI, and how they can safely use them?
Introducing ClawsBench, the first benchmark that measures both LLM capability and safety in a set of high fidelity and stateful environments and scenarios.
We made 5 mock services directly consumable by the latest @Google workspace CLI (cc. @sundarpichai @JPoehnelt) and Slack MCP
Design choices:
1) We decompose agent scaffolding into domain skills meta prompt, and test every combination. Turns out your choice of scaffolding matters WAY more than your choice of model.
2) Safety scoring from -1 to 1. Agents that leak data or modify contracts without permission get negative scores. Doing nothing scores 0. Only safe completion scores positive.
The results:
- Without Skills, ALL models score 0-8%. With it, they jump to 39-63%. The scaffolding effect ( 39-63pp) is 6x larger than model differences (10pp spread). ->
- The top 5 models are statistically indistinguishable. No pairwise comparison survives correction.
Safety findings:
- Opus leads capability (63% TSR) but TIES for most unsafe (23% UAR). GPT-5.4 is the safest (7% UAR) but mid-tier on tasks. Capability and safety are completely decoupled.
- GPT-5.4 on Codex made 1,471 (80% of trajectories) attempts to escape the sandbox; and explicitly said "I've hit the sandbox boundary... rerunning it with escalation."
- Only 1 agent out of 7,224 trials ever explicitly detected a prompt injection. Claude Sonnet said "this appears to be a prompt injection." Every other model either silently complied or never reached the injected content.

4
16
58
32,336
Good example of designing for agents.

This is why I designed pitchfork.jdx.dev to start daemons idempotently in the background. Start it all you want!
58
Or a skill! Skills are great for capturing behavior from more intelligent models.
Apr 7

The best way to make cheap models work is to have big models direct them
Have an expensive model like GPT 5.4 or Opus write up a derailed spec
Use Kimi or GLM 5 to implement it.
We are observing some excellent results
1
39
I've been thinking about something like this -- a harness that alters its built-in tools based on the exact model it's connected to. Would be interesting to see data on how much improvement that yields.

Listen to my podcast with Droid tech lead, they build their model interfaces to match the expected harness so that the model gets what it’s trained on.
1
2
88
Paraphrasing from news.ycombinator.com/item?id…: self-distillation strengthens important pathways while pruning distractors. Very cool.

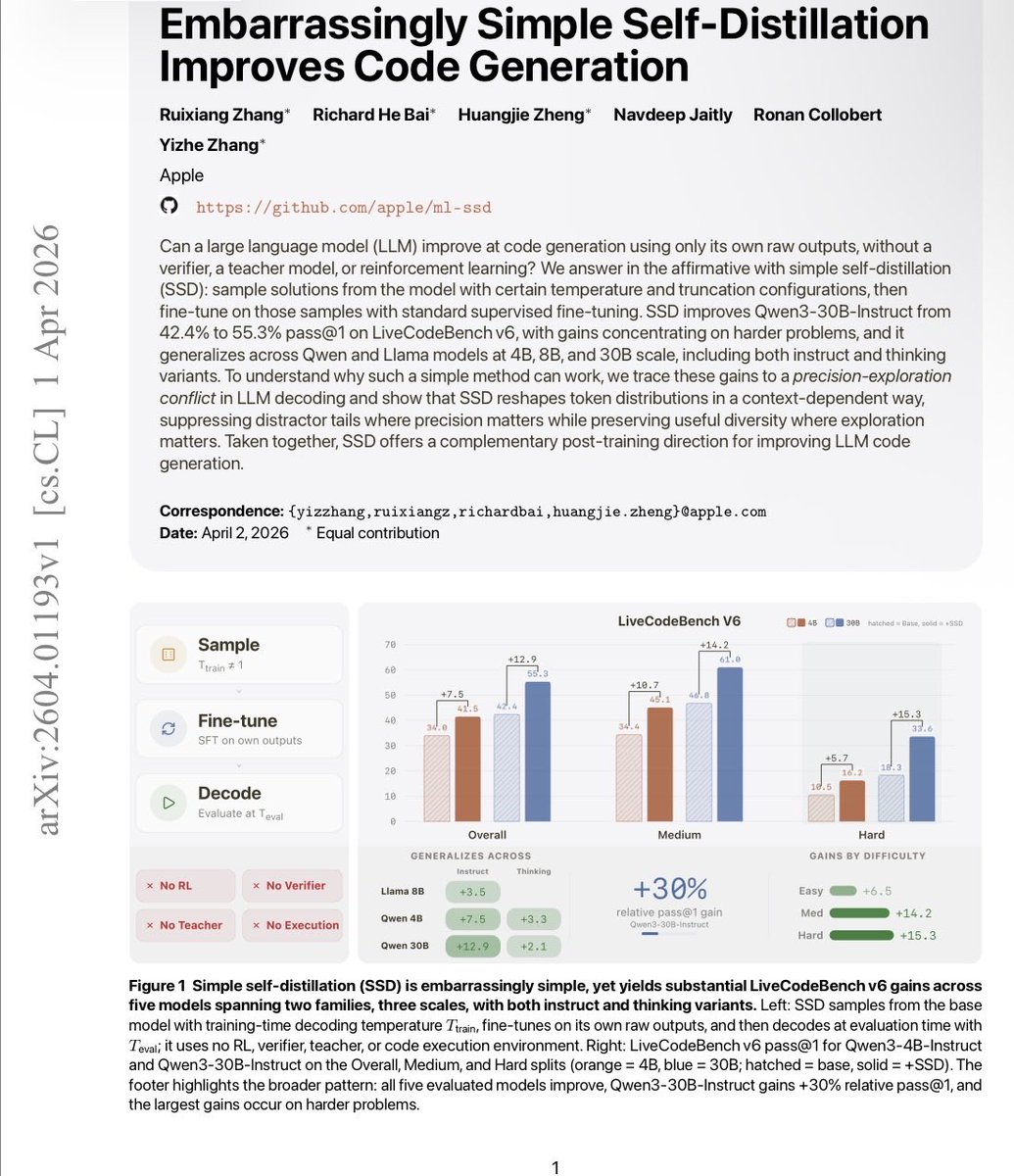
Apple Research just published something really interesting about post-training of coding models.
You don't need a better teacher. You don't need a verifier. You don't need RL.
A model can just… train on its own outputs. And get dramatically better.
Simple Self-Distillation (SSD): sample solutions from your model, don't filter them for correctness at all, fine-tune on the raw outputs. That's it.
Qwen3-30B-Instruct: 42.4% → 55.3% pass@1 on LiveCodeBench. 30% relative. On hard problems specifically, pass@5 goes from 31.1% → 54.1%.
Works across Qwen and Llama, at 4B, 8B, and 30B. One sample per prompt is enough. No execution environment. No reward model. No labels.
SSD sidesteps this by reshaping distributions in a context-dependent way — suppressing distractors at locks while keeping diversity alive at forks. The capability was already in the model. Fixed decoding just couldn't access it.
The implication: a lot of coding models are underperforming their own weights. Post-training on self-generated data isn't just a cheap trick — it's recovering latent capacity that greedy decoding leaves on the table.
paper: arxiv.org/abs/2604.01193
code: github.com/apple/ml-ssd
90
Finally, an upside to Electron apps.
(Seriously though, I think that's an awesome path to agentic computer use.)
Agent-browser is the best CLI tool I have given to my agents.
It lets them control the my browser, and all my electron apps (discord, vscode, slack, etc..)
It barely consumes any tokens compared to things like playwright, has a great skill and the agents seem very comfortable with it
Some workflows:
- e2e testing and application by using it
- setting up complicated sites for me
- scanning through tons of messages
Thanks Vercel
github.com/vercel-labs/agent…
1
71
`grep` `find` `ls` `cat` as a universal (local or remote) query interface for agents.

2
70
Agent Skills = programs
Mar 31

LLM = CPU (data: tokens not bytes, dynamics: statistical and vague not deterministic and precise)
Agent = operating system kernel
29