
Building in Web3 — where every block is a step toward a decentralized tomorrow
Joined December 2024
- Tweets 526
- Following 245
- Followers 38
- Likes 521
40 Photos and videos









IMAAN retweeted

May 21
SoSoValue Flash: Iran Peace Nears & AI IPO Wave Ignite Market Sentiment
💥 Core Catalyst: Truce Extensions & Tehran ShadowsU.S.–Iran talks are in the final phase, with Trump signaling patience for a "right answer" from Tehran. Hormuz transit shows significant progress: 26 vessels transited in coordination with Iran over the past 24 hours, including a South Korean tanker, marking a symbolic milestone for Strait stability.
🔍 Key Logic Shifts:
1️⃣ Supply Chain: Samsung Electronics reached an initial wage deal, postponing the strike previously set for May 21 and alleviating immediate supply-side fears for DRAM/NAND.
2️⃣ AI & IPO Wave: The AI capital markets are heating up: SpaceX filed its S-1 for a mid-June listing; OpenAI is prepping a September IPO; and Anthropic is projecting 26Q2 revenue of $10.9B with operating profitability. This IPO trio, combined with NVIDIA’s solid earnings print, reinforces the long-term AI growth thesis.
3️⃣ Macro & Equities: Peace expectations are cooling energy and rates: Brent slipped from $110 to $105, and the 10Y yield dipped below 4.6%. This macro tailwind is providing fresh fuel for the AI-led equity rebound.
📊 Trade Setup (SoDEX Assets to Watch):
Core: $USTECH-100 | $CL (Crude) | $XAUT | $BTC
MAG7: $NVDA | $AMZN | $GOOGL | $META | $MSFT | $TSLA | $AAPL
AI Hardware: $SNDK | $MU | $AMD | $INTC
Trade now: sodex.com

10,314
2,382
9,200
83,281
IMAAN retweeted

May 21
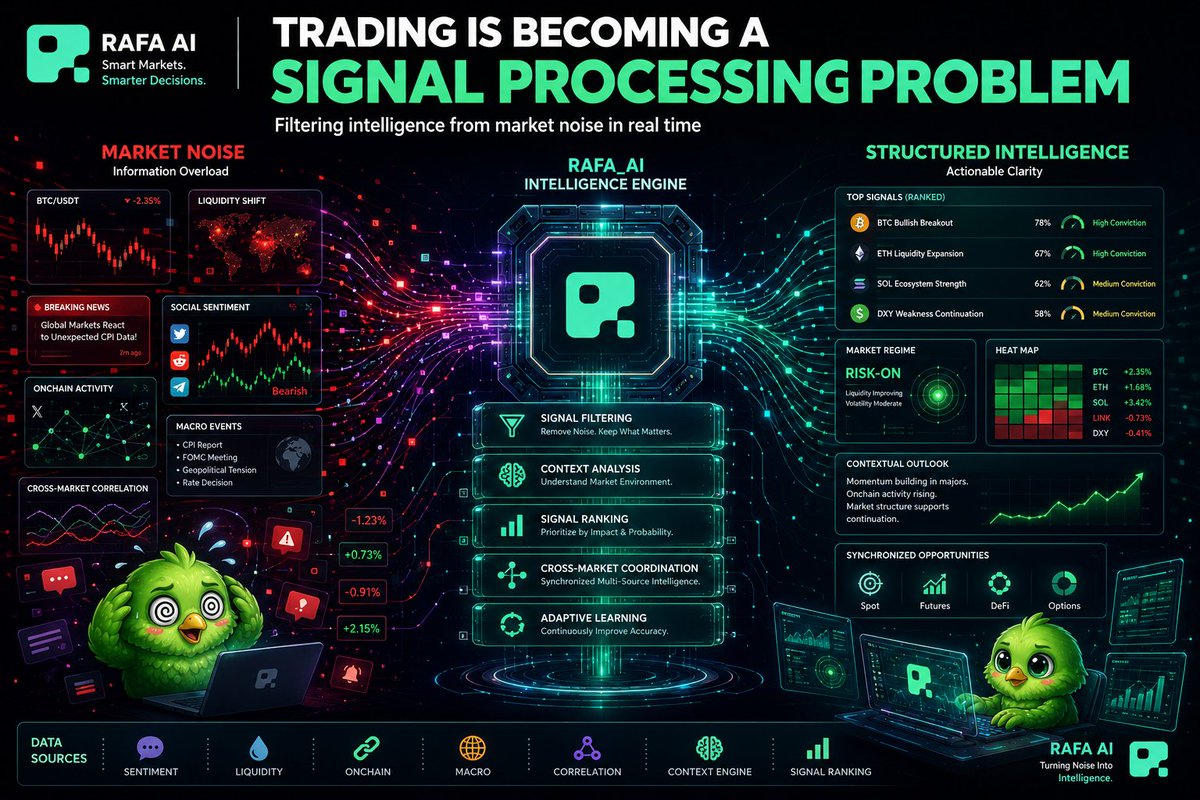
Financial markets are no longer moving at human speed.
Price action changes within seconds.
Liquidity shifts across multiple ecosystems at the same time.
News spreads instantly.
Sentiment changes before most traders can even fully process the previous move.
That changes the nature of trading itself.
The challenge is no longer just finding information.
The real challenge is filtering signals from massive amounts of noise fast enough to react intelligently.
This is why modern trading is slowly becoming more of a signal processing problem than a simple analysis problem.
A trader may have access to thousands of data points every day.
Market structure.
Volume changes.
Social sentiment.
Onchain activity.
Macro events.
Cross-market correlations.
But raw information alone does not create clarity.
In many cases, too much information actually reduces decision quality because the brain struggles to prioritize which signals matter most in real time.
That is where systems like @RAFA_AI become increasingly interesting.
Instead of simply displaying market data, @RAFA_AI is moving toward interpreting large streams of information and transforming them into structured intelligence that users can actually act on.
The important shift here is architectural.
Older trading systems were mostly built around access to information.
Modern AI-native systems like @RAFA_AI are starting to focus more on coordination, filtering, ranking, and contextual understanding across constantly changing market environments.
As financial systems continue accelerating, the ability to process signals efficiently may become more valuable than access to raw data itself.
3
1
12
46
IMAAN retweeted
Apr 13
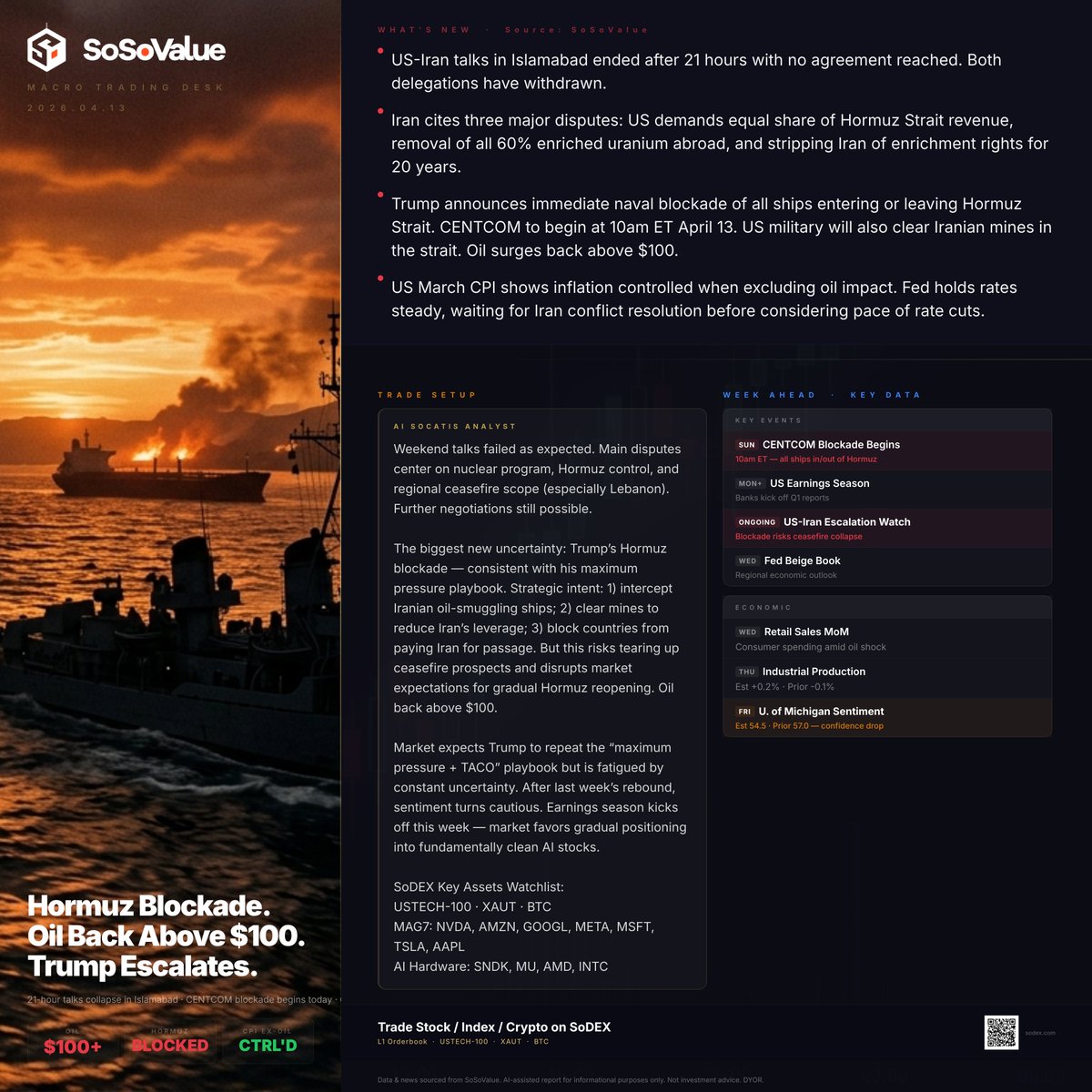
🚨SoSoValue Flash: Talks Collapse & Strait Blockade, Trump Deploys "Maximum Pressure" 2.0
💥 Core Catalyst: Negotiations Stall, Blockade Takes EffectThe 21-hour Islamabad talks ended with no agreement, leading both delegations to withdraw. Trump responded by ordering an immediate naval blockade of the Strait of Hormuz, effective April 13 at 10 AM ET. CENTCOM will also begin mine-clearing operations. Oil prices have surged back above $100.
🔍 Key Logic Shifts:
1️⃣ The Leverage War: Negotiations failed over revenue sharing and a 20-year ban on uranium enrichment. Trump’s blockade strategy is designed to intercept Iranian oil smuggling and dismantle Tehran’s "toll booth" over the Strait, effectively stripping Iran of its primary economic leverage.
2️⃣ Inflation’s Final Boss: March CPI data confirms that inflation is largely under control, except for the energy component. The Fed is holding steady, Refusing to consider rate cuts until the conflict reaches a resolution—keeping the market in a high-rate chokehold.
3️⃣ Market Fatigue: While Trump is sticking to his "Maximum Pressure" playbook, the market is growing weary of the constant uncertainty. Investors are rotating away from geopolitical noise toward "fundamentally clean" AI stocks as earnings season begins.
📊 Trade Setup (SoDEX Assets to Watch):
Core Watchlist: $USTECH-100 | $XAUT | $BTC
Safe Harbors: MAG7 and AI Hardware (MU, AMD, etc.) are favored for their earnings resilience.
Tactical Move: Monitor the intensity of the blockade starting at 10 AM ET. If the military enforcement leads to direct kinetic engagement, expect a deeper shift into Risk-Off mode.
#Geopolitics #Trump #SoSoValue #OilPrice #AI #Fed #HormuzBlockade #Macro
11,791
3,672
15,209
146,237
IMAAN retweeted

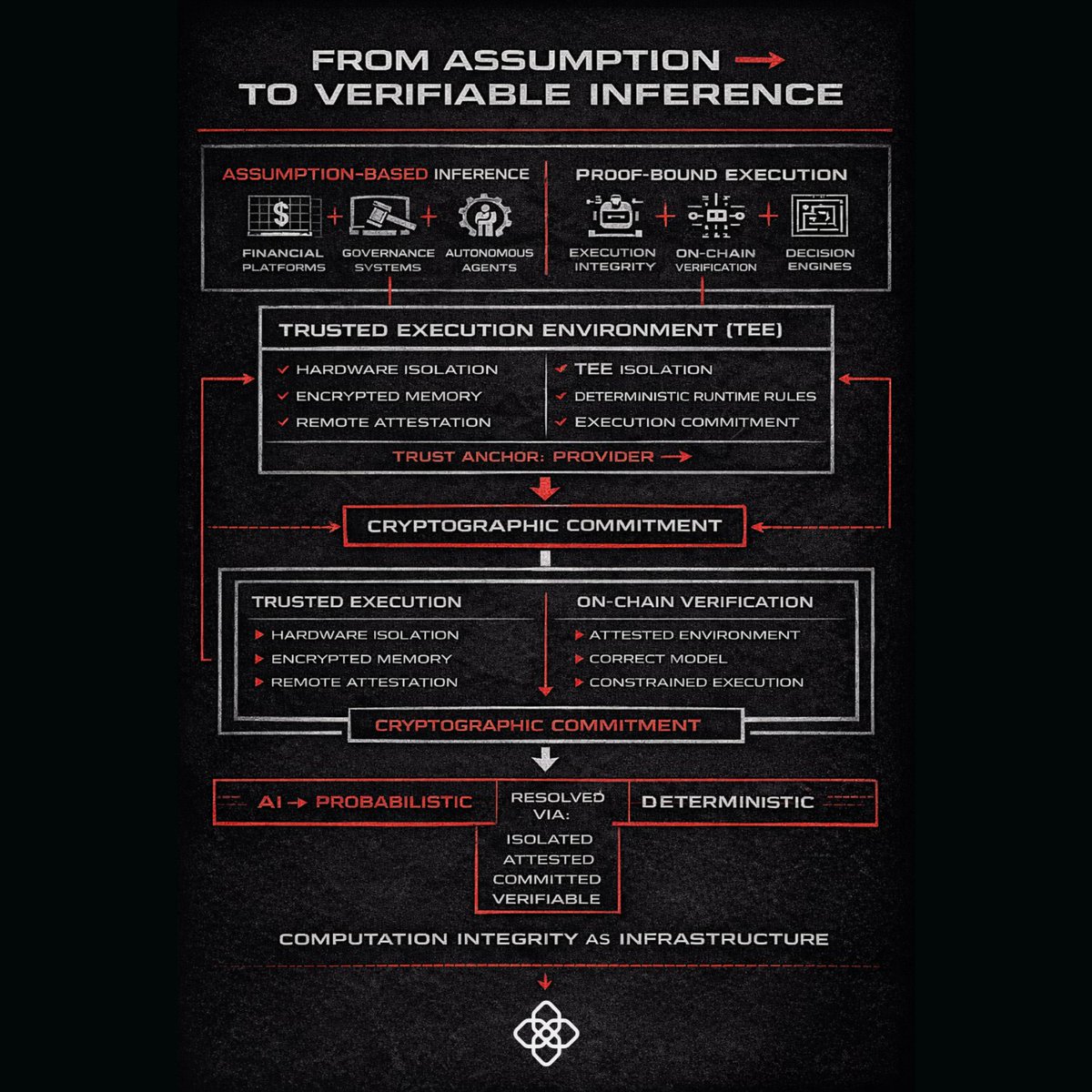
Feb 26
If AI is integrated into decentralized systems,
execution cannot remain assumption-based.
It must become verifiable.
@OpenGradient introduces a model
where inference is not merely trusted, it is cryptographically constrained. The shift begins at the execution layer.
15
13
22
149
IMAAN retweeted
Feb 25
AI systems today are embedded
in financial protocols, governance tooling,
automation pipelines, and data coordination layers.
Their outputs influence state changes.
26
17
47
220
IMAAN retweeted
Feb 25
AI governance discussions often focus on model outputs.
Bias in responses.
Hallucinations.
Unsafe behavior in deployment.
But governance pressure is gradually shifting downward in the stack.
Regulation that targets outputs eventually leads to scrutiny of inputs.
Governance before training
If a model produces harmful or non-compliant behavior, the root cause frequently traces back to training data composition. Governing datasets prior to training reduces reliance on post-deployment correction mechanisms.
Dataset acceptance thresholds
Before entering a training pipeline, datasets can be evaluated against predefined standards: contributor verification levels, domain coverage requirements, bias scoring ranges, and documentation completeness. Data that does not meet thresholds is rejected before it influences model weights.
Pre-deployment data certification
Structured validation logs, transformation records, and annotation transparency create certifiable artifacts. These artifacts allow organizations to demonstrate that training inputs were reviewed and validated before model deployment.
This reframes governance from reactive oversight to structural control.
@PerleLabs builds around governable training pipelines rather than annotation as a standalone service.
By integrating contributor credentialing, dataset lineage tracking, validation checkpoints, and controlled workflow design, the training pipeline itself becomes auditable.
As enterprise and regulatory scrutiny increases, governance will not remain confined to model behavior.
It will extend to how datasets are sourced, verified, and admitted into training systems.
@PerleLabs aligns with this shift by treating the data layer as the first control surface in AI governance architecture.
cc:
@alivinex2
@xlordiot
@Eazyxbt
@PerleLabs

36
16
47
281
IMAAN retweeted
Feb 25
Good morning gAI
Almost Level 20!
will it happen today?
@OpenGradient grind continues day 4
3
12
20
53
IMAAN retweeted
Feb 25
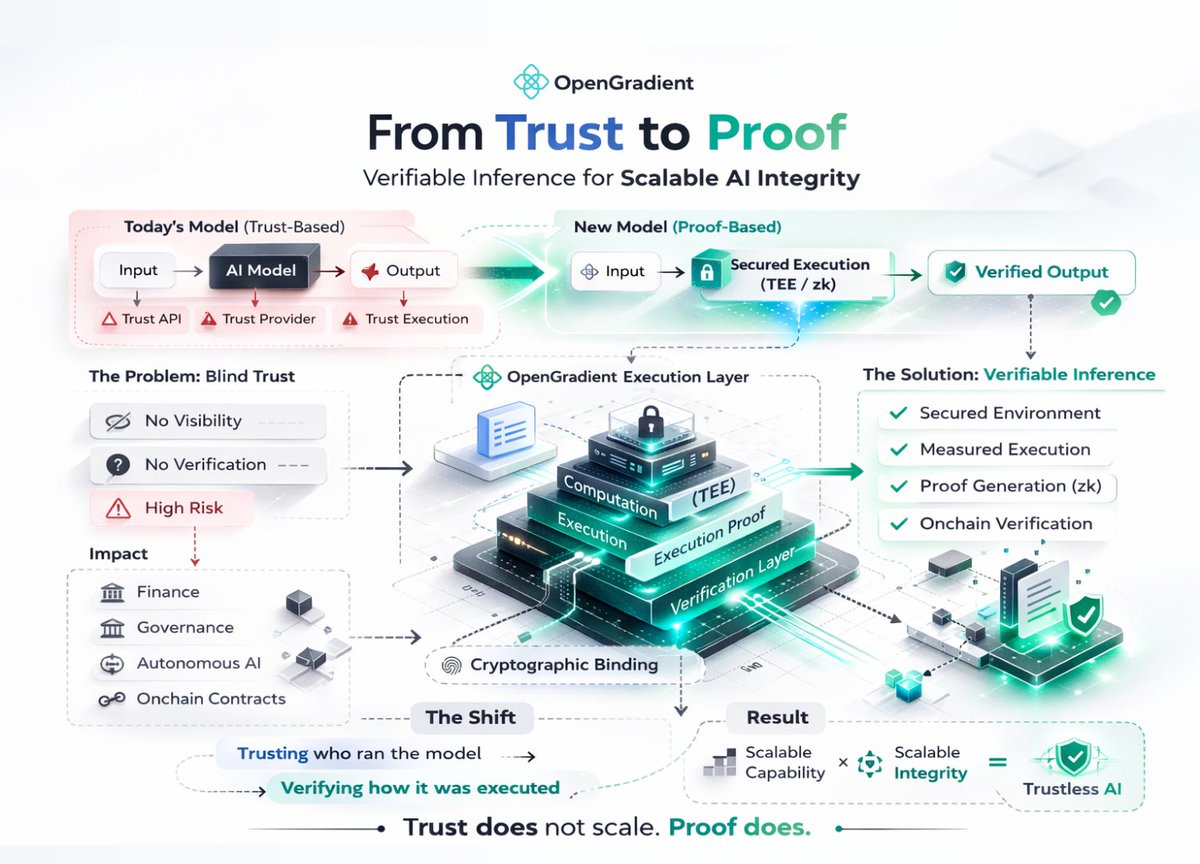
AI outputs are widely trusted.
But rarely verified.
Most systems today operate on assumption.
You send input.
A model generates output.
You accept it.
The trust model is provider-based.
You trust the API.
You trust the hosting environment.
You trust that the model executed as claimed.
This scales capability.
It does not scale integrity.
As AI becomes embedded into:
Financial systems
Governance frameworks
Autonomous agents
Onchain contracts
The cost of blind trust increases.
If an output influences capital allocation or protocol state, “trust me” is no longer sufficient.
The scaling problem of trust is structural.
AI providers control:
Execution environment
Model versioning
Inference parameters
Output delivery
Users have no visibility into computation integrity.
They only see the result.
@OpenGradient reframes this assumption.
Instead of relying on provider guarantees, it introduces verifiable inference at the execution layer.
Computation runs inside secured environments.
Execution is measured.
Outputs are cryptographically bound to that execution context.
The shift is subtle but foundational.
From:
Trusting who ran the model
To:
Verifying how the model was executed.
This reduces trust dependency at the protocol level.
AI capability can scale independently from AI integrity.
If AI is to function as infrastructure,
execution must be auditable.
@OpenGradient approaches inference not as a service request, but as computation that can be proven.
Trust does not scale linearly with usage.
Proof does.
22
14
30
173
IMAAN retweeted
Feb 24
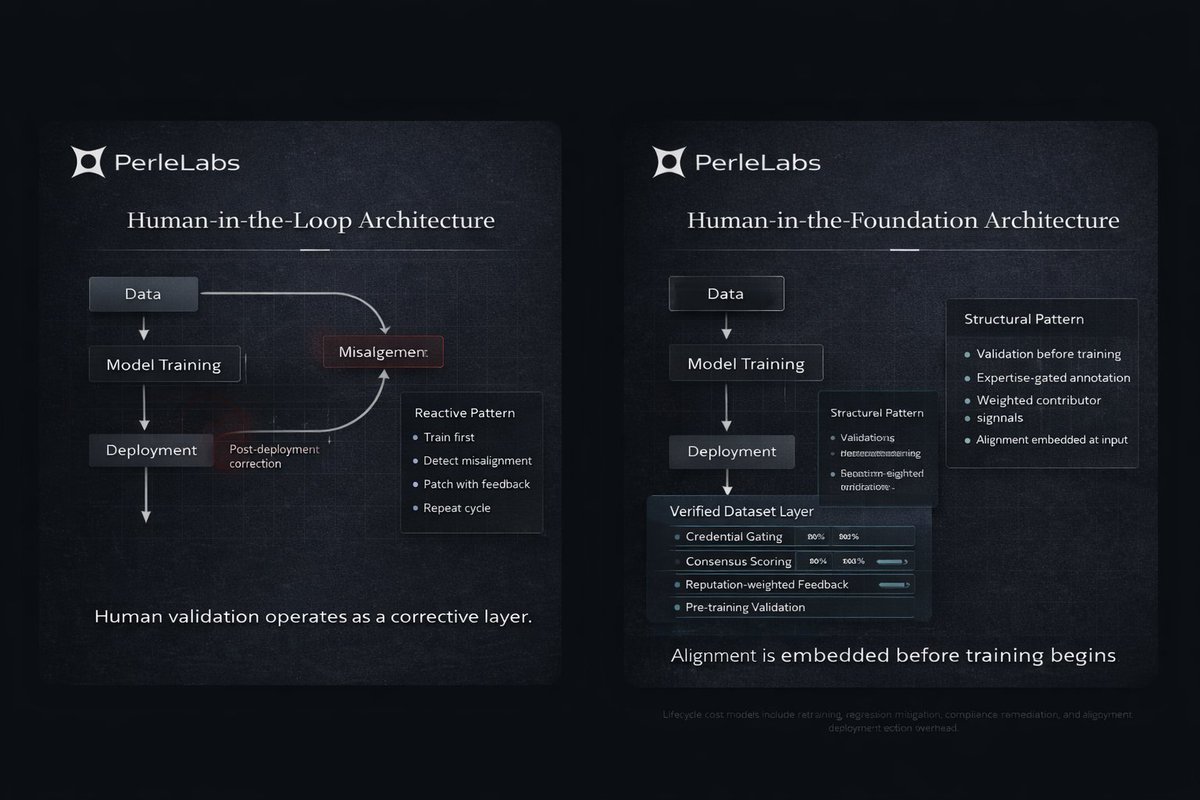
@PerleLabs frames AI architecture around a structural shift:
Old model: Human-in-the-loop.
Emerging model: Human-in-the-foundation.
Human-in-the-loop systems are reactive. Models are trained first, then corrected through feedback cycles after misalignment appears. Human input operates as a patch layer.
Human-in-the-foundation changes where validation sits in the stack.
Validation before training
Instead of retroactive correction, dataset inputs are filtered and verified before entering model pipelines. Domain review and acceptance thresholds are applied at the data layer.
Credential gating
Annotation access is restricted based on verified expertise. Task assignment is aligned with contributor specialization rather than open participation. This reduces variance in judgment quality.
Consensus scoring
Multi-review systems introduce agreement thresholds and structured dispute resolution. Edge cases are resolved through layered evaluation rather than single-pass labeling.
Reputation-weighted feedback
Contributor history, accuracy metrics, and domain performance influence how feedback is weighted during training cycles. Not all signals carry equal influence.
@PerleLabs integrates these components into its data infrastructure, positioning human validation as a prerequisite condition rather than a corrective mechanism.
This architectural shift reframes human intelligence from oversight to structural input.
In systems built around @PerleLabs principles, alignment is not repaired after deployment. It is embedded before training begins.
The transition from loop to foundation reflects a broader change in how AI reliability is engineered.
@PerleLabs approaches dataset design as core system architecture, not auxiliary workflow.
cc:
@alivinex2
@xlordiot
@Eazyxbt
40
19
49
176
IMAAN retweeted
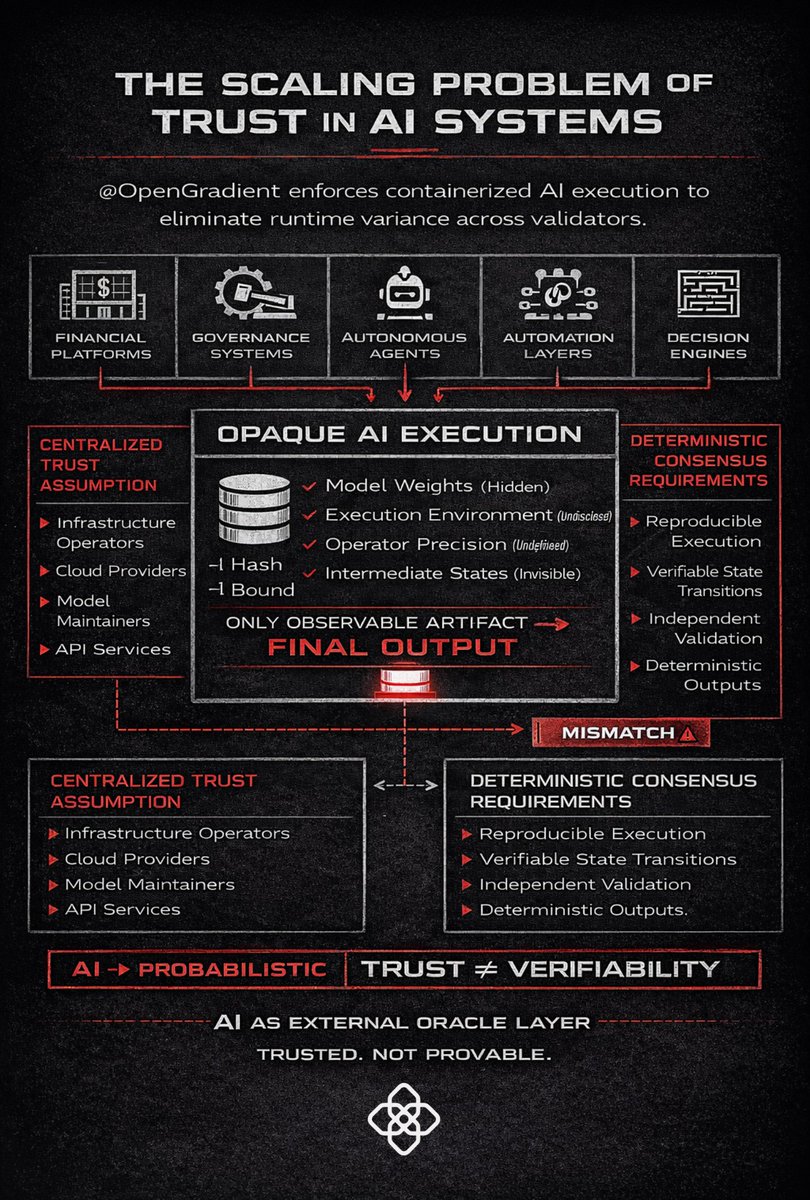
Feb 24
Model Containerization Architecture
@OpenGradient enforces containerized AI execution
to eliminate runtime variance across validators.

12
14
21
98
IMAAN retweeted
Feb 24
Verifiable inference is the core constraint of onchain AI.
If a smart contract consumes model output,
the question is not intelligence.
It is integrity.
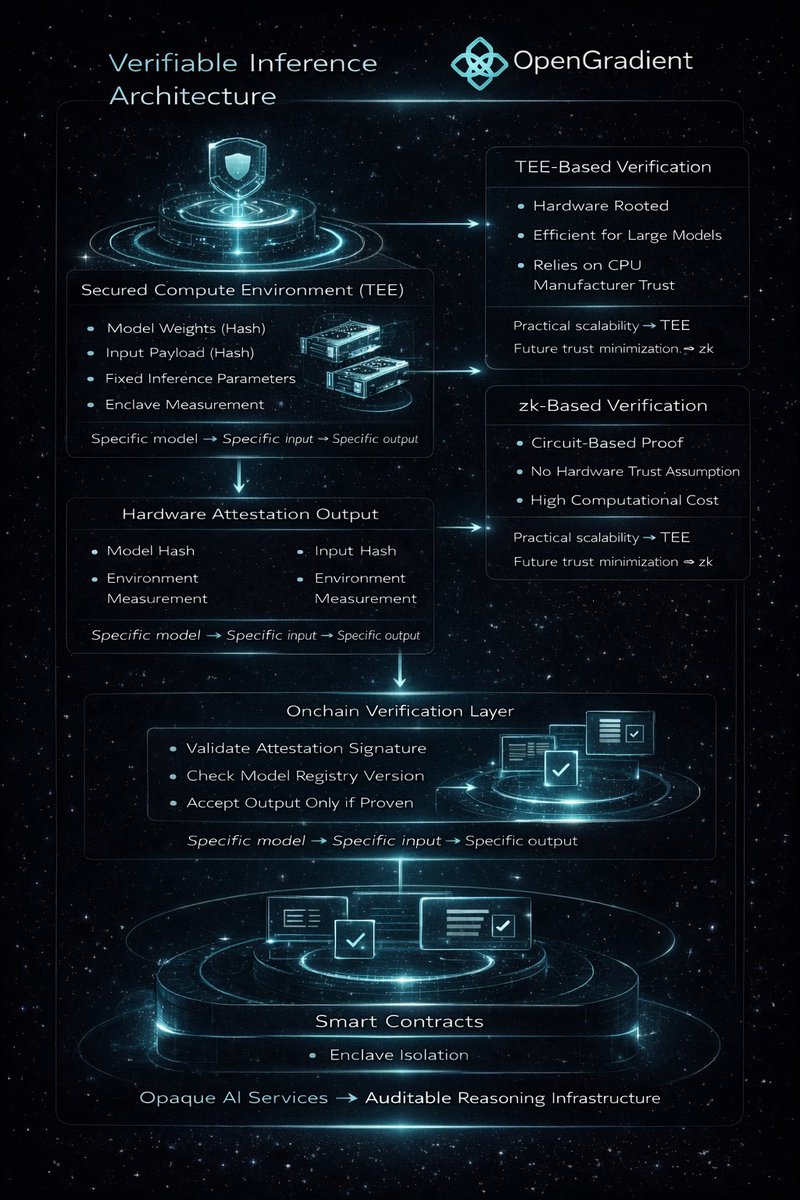
On @OpenGradient, inference is treated as a verifiable computation process rather than a blind API call.
Execution occurs within a secured compute environment. The output is accompanied by attestation data. The contract consumes both the result and its proof.
Inference attestation begins at the execution layer. When a model runs inside a Trusted Execution Environment (TEE), the hardware enclave generates a cryptographic report.
This report binds:
- Model hash
- Input hash
- Execution environment measurement
- Output hash
The attestation proves that a specific model version executed on specific input inside a measured environment without external tampering. @OpenGradient structures inference around this attested execution model.
TEE-based verification is hardware-rooted.
The trust assumption shifts to:
- CPU manufacturer security guarantees
- Remote attestation validity
- Enclave isolation integrity
This approach is computationally efficient
and suitable for large-scale inference workloads.
However, TEE verification is not mathematically trustless.
Zero-knowledge (zk) based verification models represent a different path. Instead of relying on hardware isolation, zk systems generate a proof that the computation followed a defined circuit.
For AI inference, this means:
Proving that matrix operations and activation flows
were executed correctly
without revealing sensitive data.
The constraint is cost.
General-purpose zk proofs for large neural networks remain computationally expensive.
@OpenGradient currently optimizes for practical scalability through TEE-backed attestation,
while the broader research direction explores zk-verifiable inference as a future evolution.
Deterministic vs probabilistic output validation introduces another layer. Blockchains expect deterministic computation. AI models are inherently probabilistic.
Two runs of the same model may produce different outputs depending on sampling parameters.
@OpenGradient addresses this by:
Fixing inference parameters
Hashing model weights
Hashing exact input payloads
The attestation then binds to a single execution instance.
The proof does not claim universal correctness.
It proves that a defined model version produced a specific output under controlled conditions.
This is execution integrity, not epistemic truth.
Trust minimization in AI execution is therefore layered.
At the lowest level:
Hardware attestation ensures isolation.
At the protocol level:
Model registries ensure version transparency.
At the contract level:
Only attested outputs are accepted as valid inputs.
On @OpenGradient, inference becomes a composable primitive because proof travels with output. Contracts do not trust nodes. They verify execution evidence.
The result is a shift from opaque AI services
to auditable reasoning infrastructure.
In this architecture, @OpenGradient does not claim that AI is infallible.
It ensures that whatever reasoning occurs
is provably the reasoning that was executed.
17
16
23
133
IMAAN retweeted
Feb 24
@PerleLabs has launched a new annotation task: Pet Bounding Box Quest.
This task focuses on object detection training at the dataset layer.
Participants are required to review pet images and draw precise bounding boxes around the pet’s head. The objective is not speed, but consistency and spatial accuracy.
Bounding box annotation directly impacts detection model performance. Loose framing introduces background noise. Over-tight framing can truncate key features. Inconsistent box geometry reduces training signal clarity.
Object detection models rely on clean coordinate labeling to learn spatial boundaries and object localization. Small annotation inconsistencies can propagate into localization error, reduced confidence scoring, or false positives during inference.
Task structure:
20 image tasks
100 points per task
1,000 points required for qualification
This task contributes to structured dataset development for object detection systems, reinforcing spatial precision and annotation standardization.
Access the task via the Perle application portal and review the detailed breakdown in the latest blog release.
High-quality bounding box annotation strengthens the reliability of downstream detection models.
still you are early join now : app.perle.xyz/join/rQGxZi
5
20
23
79
IMAAN retweeted
Feb 23
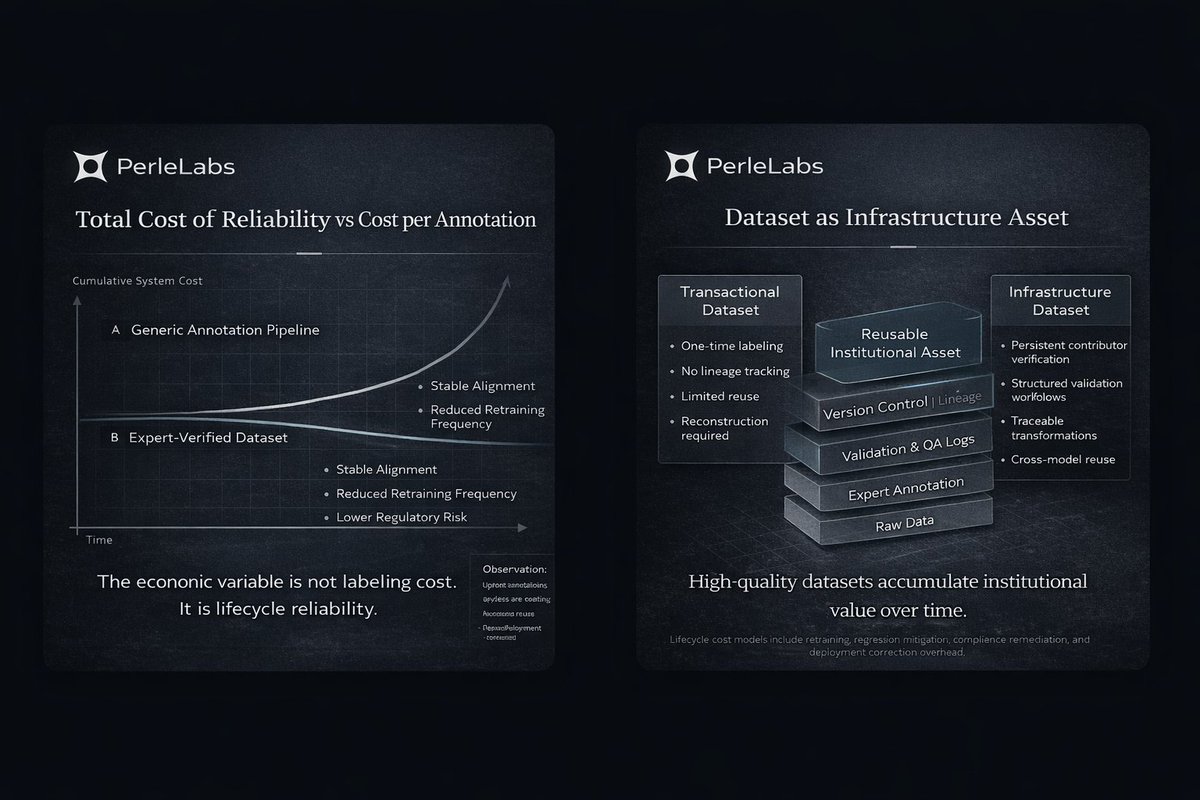
Most discussions around AI data focus on scale and cost per annotation.
The more relevant variable is cost of reliability.
Generic annotation pipelines optimize for volume. Expert-verified data optimizes for signal precision. The pricing difference between the two reflects variance in expertise, review depth, and validation controls.
At surface level, expert data appears more expensive.
At system level, misaligned training is significantly more costly.
Model retraining cycles, performance regression, compliance exposure, post-deployment corrections, and reputational damage introduce compounding operational expenses. Poorly labeled edge cases often remain undetected until production deployment, where correction costs increase exponentially.
Verified datasets reduce these downstream correction cycles.
Higher-quality annotation narrows variance in model behavior, improves alignment stability, and reduces retraining frequency. In regulated or high-stakes domains, this also lowers audit and legal exposure.
Over time, well-structured datasets function less like consumable inputs and more like infrastructure assets.
Version-controlled, traceable, and expert-validated data accumulates institutional value. It can be reused across model iterations, audited for compliance, and integrated into long-term AI strategy without reconstruction from scratch.
@PerleLabs builds around this infrastructure-oriented view of AI data.
Instead of treating annotation as a transactional marketplace, the focus shifts toward persistent contributor verification, structured validation workflows, and datasets designed for long-term operational durability.
In enterprise AI environments, the economic question is not the cost of labeling. It is the cost of unreliable training.
cc:
@alivinex2
@xlordiot
@Eazyxbt
21
22
48
352
IMAAN retweeted
Feb 23
AI as a Smart Contract Primitive
@OpenGradient reframes AI models as programmable execution modules rather than external API services.
Traditional AI integration relies on off-chain providers. A contract emits a request. An external system returns a result.
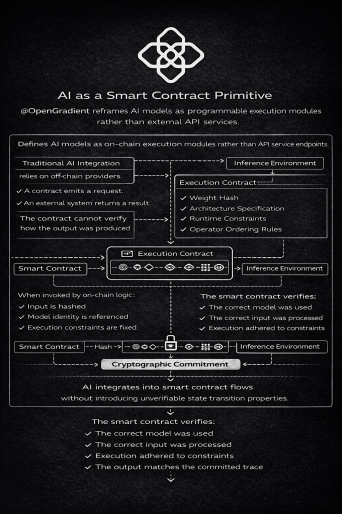
14
18
21
80
IMAAN retweeted
Feb 23
AGI onchain is often framed as a slogan.
The practical question is architectural.
What would intelligence look like if it were embedded directly into execution layers rather than exposed through APIs?
On @OpenGradient, AI is structured as a verifiable computation layer.
If this layer evolves toward more generalized reasoning systems, AGI onchain would not mean a single omniscient model. It would mean network-native intelligence coordinating economic activity.
Autonomous economic agents are the first visible form.
Agents could:
-Hold wallets
-Execute transactions
-Access verifiable inference
-Adjust strategies based on state changes
Their reasoning would not be opaque.
Inference would be attestable.
Decisions could reference provable model execution.
AI-native DAOs extend this structure.
Instead of governance relying solely on token voting and static proposals,
reasoning systems could:
Simulate outcomes
Optimize treasury allocations
Continuously monitor protocol health
Propose parameter adjustments autonomously
The DAO becomes partially cognitive.
Execution remains onchain.
Reasoning is verifiable.
Self-improving onchain models introduce another layer.
If models are versioned, forkable, and economically incentivized, improvements can be proposed, evaluated, and adopted transparently. Model evolution becomes a governed process.
Performance metrics, usage demand, and economic rewards influence which intelligence layers persist.
Intelligence becomes composable infrastructure.
Autonomous digital economies emerge when agents transact with other agents.
Liquidity managed by AI.
Market making optimized continuously.
Risk models updating in real time.
Supply chains coordinated by reasoning systems.
Human input shifts from micromanagement
to boundary definition.
On @OpenGradient, inference is already positioned as a programmable primitive.
If reasoning systems become more generalized,
the distinction between protocol logic and adaptive intelligence begins to narrow.
AGI onchain would not be a single event.
It would be the gradual embedding of increasingly capable reasoning into economic execution layers.
From deterministic contracts
to cognition-aware infrastructure.
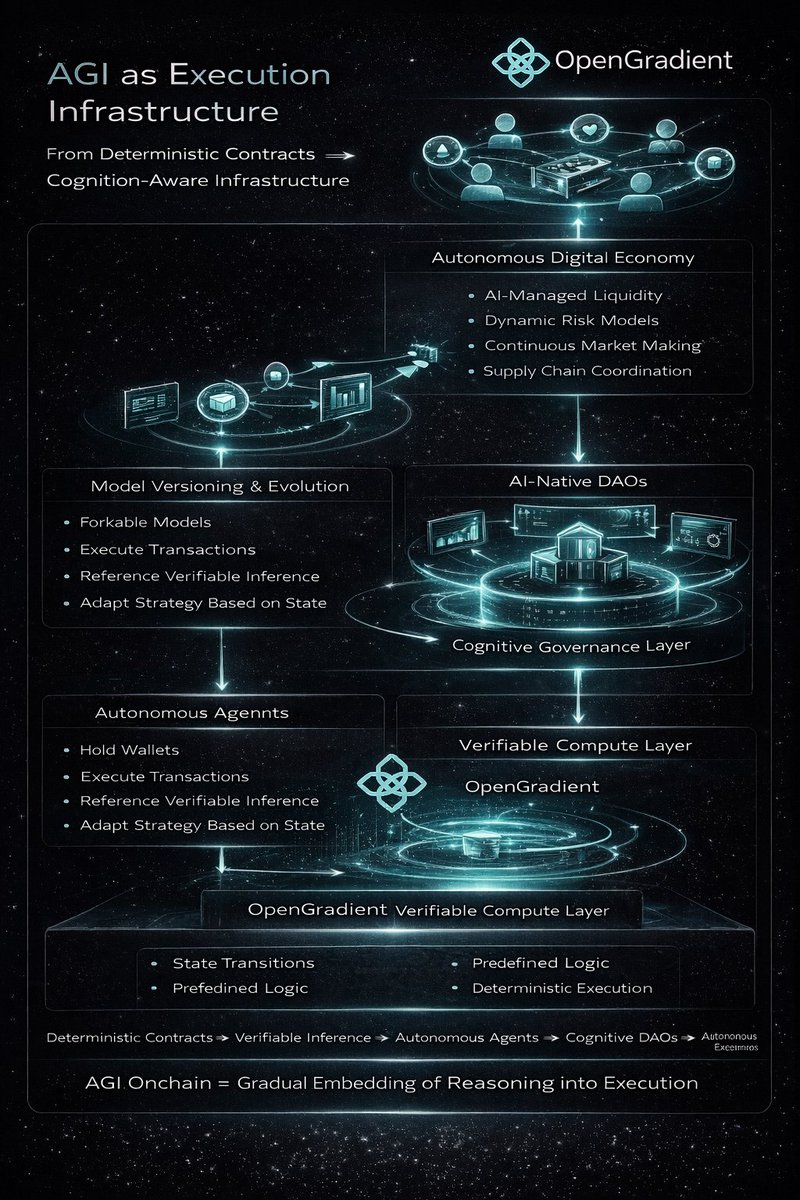
10
19
22
118
IMAAN retweeted
Feb 21
Web3 primitives started with simple execution.
Transfer.
Store.
Verify.
Smart contracts expanded that into programmable logic. But execution has remained deterministic. Composable AI introduces a new class of primitive. On @OpenGradient, AI is not treated as an external API.
It is positioned as an execution layer that smart contracts can reference. AI as smart contract middleware. Instead of contracts interacting only with predefined logic, they can call verifiable inference.
Model execution happens within the OpenGradient compute layer. The result is attested. The contract consumes verified output.
AI becomes an intermediate reasoning layer between state and action. Not offchain advice.
Onchain-referenced computation.
AI composability across chains emerges from this structure. If inference is abstracted as a verifiable service, any EVM-compatible environment can reference the same AI layer.
The model is executed once.
The proof is portable.
Multiple contracts across networks can rely on the same reasoning output.
This separates intelligence from chain locality.
AI becomes infrastructure-level, not application-level.
AI-driven protocol automation extends this further.
Protocols can:
Adjust parameters dynamically
Detect anomalous behavior
Optimize liquidity allocations
Rebalance risk exposure
Based on verifiable AI outputs rather than manual governance cycles.
Automation moves from fixed rules
to adaptive reasoning. The economic implication is structural. AI becomes an economic primitive.
Just as gas prices price computation,
AI inference can price reasoning.
Agents can pay for inference.
Protocols can internalize AI costs into fee models.
Users can interact with contracts that incorporate adaptive logic by default.
Composability then extends beyond token transfers and contract calls.
It includes intelligence as a shared resource layer.
With @OpenGradient, AI is not positioned as an application vertical. It is positioned as a programmable component of the execution stack.
A shift from deterministic composability
to reasoning-aware composability.
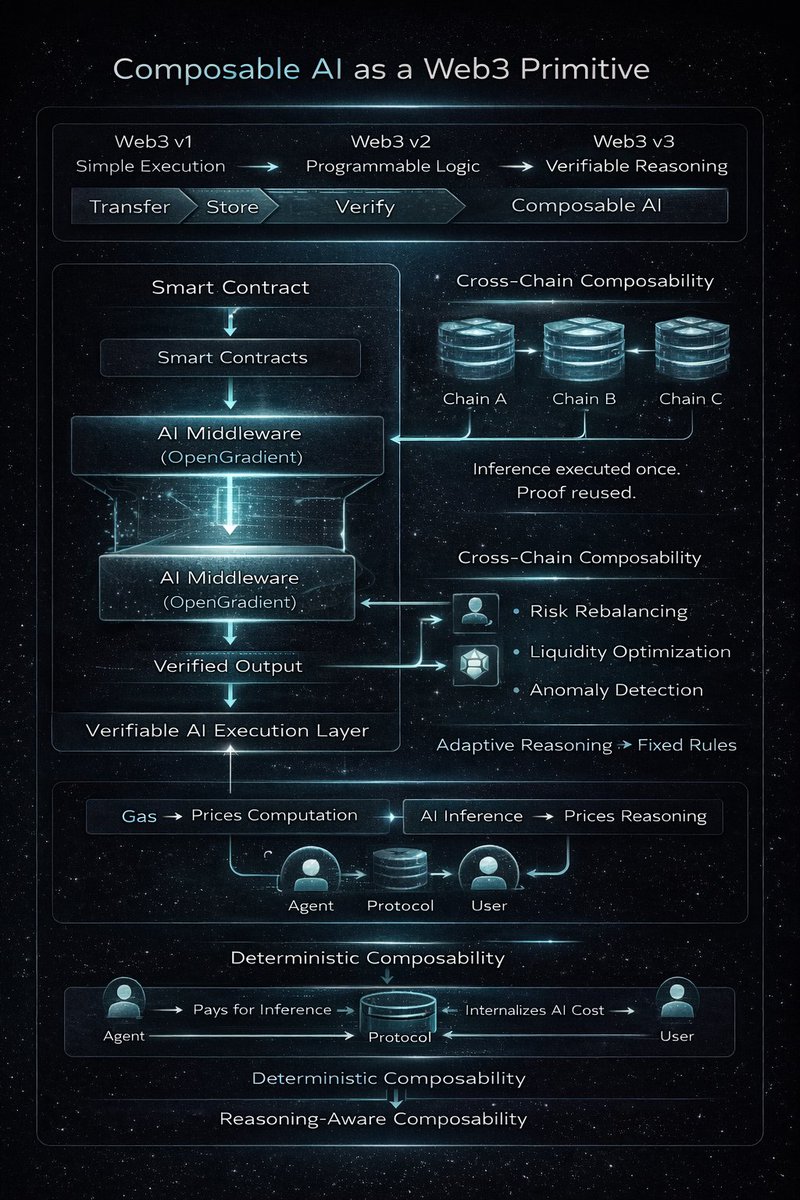
19
8
27
118
IMAAN retweeted
Feb 21
Off-Chain Compute, On-Chain Trust @OpenGradient separates AI execution from blockchain verification. Blockchains are built for verification, not heavy computation.
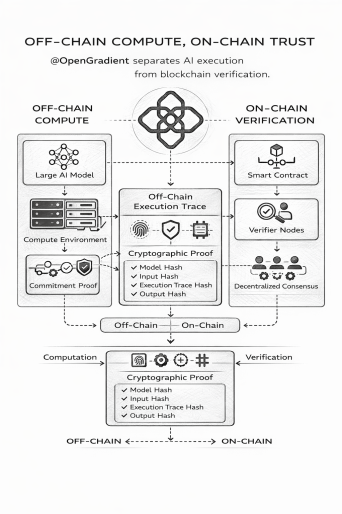
10
16
18
55
IMAAN retweeted
Feb 21
@PerleLabs approaches AI development from the dataset layer first.
As enterprise adoption increases, AI systems are being evaluated not only on performance, but on audit readiness. In this environment, dataset governance becomes a structural requirement.
An AI audit readiness framework can be organized around five core components:
Dataset traceability
Every training sample should carry lineage metadata - origin, preprocessing steps, annotation history, and version identifiers. Reproducibility depends on the ability to reconstruct how a dataset was formed.
Contributor verification
Annotation quality is directly tied to contributor expertise. Verified identities, credential mapping, and task-to-skill alignment reduce ambiguity in how feedback was generated.
Annotation transparency
Clear documentation of labeling guidelines, edge-case handling rules, and consensus resolution methods provides context for how ambiguous samples were interpreted.
Quality scoring logs
Multi-layer validation scores, reviewer agreement metrics, and rejection histories create measurable signals of dataset reliability beyond surface-level accuracy benchmarks.
Transformation records
Filtering, normalization, augmentation, and restructuring steps applied to raw data should remain documented. Dataset transformations directly influence model behavior and must be auditable.
When these elements are integrated into the training pipeline, the dataset becomes reconstructable rather than opaque.
As governance standards mature, audit readiness shifts from model explainability alone to dataset accountability. The ability to demonstrate how data was sourced, validated, and transformed becomes foundational to enterprise AI deployment.

19
18
36
79
IMAAN retweeted
Feb 20
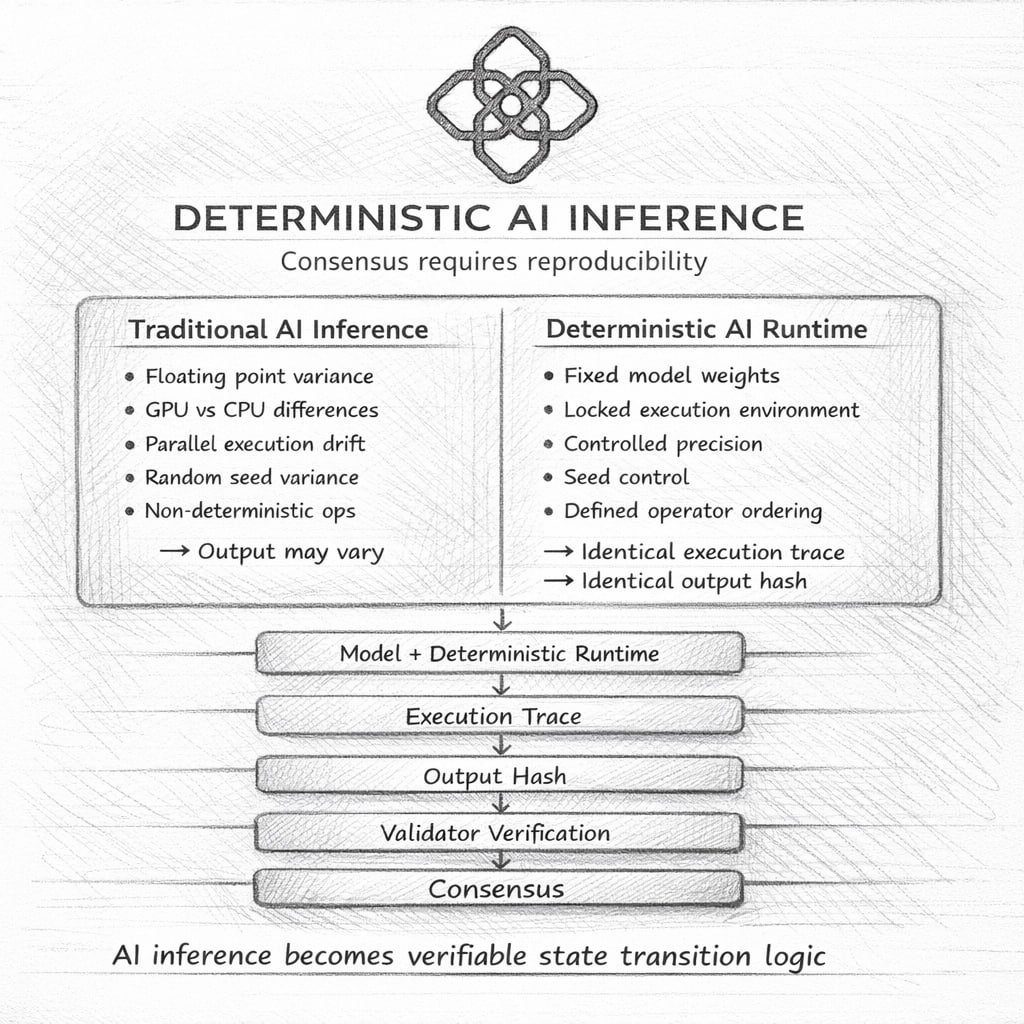
Deterministic AI Inference Explain @OpenGradient applies deterministic principles to AI execution environments. Smart contracts are deterministic by design. Given the same input and the same state, every node must produce the exact same output. Consensus depend on this prperty
3
17
19
93
IMAAN retweeted
Feb 20
OpenAI / AWS AI vs Open AI infrastructure built on @OpenGradient.
The difference is not model quality.
It is execution structure.
Centralized AI Infrastructure (OpenAI / AWS AI)
Execution model:
-Inference runs on provider-owned servers
-Model weights are private
-Runtime environment is opaque
Transparency:
-No visibility into exact model weights
-No hardware-level execution proof
-No verifiable inference trace
Ownership:
-Users access models via API keys
-Providers control rate limits and pricing
-Model distribution is platform-dependent
Verification:
-Output is trusted, not proven
-No cryptographic attestation of execution
Censorship resistance:
-Requests can be filtered
-Access can be revoked
-Models can be modified without user control
Data sovereignty:
-Prompts are processed by provider infrastructure
-Data handling policies depend on centralized entity
OpenGradient Infrastructure
Execution model:
-Inference runs through a decentralized compute layer
-odels are referenced by cryptographic hash
-Execution occurs in secure, isolated environments
Transparency:
-Model identity is verifiable
-Execution environment can produce attestation
-Outputs are linked to committed model versions
Ownership:
-Models can be published permission lessly
-Access rules can be defined on-chain
-Monetization is programmable
Verification:
-Inference produces cryptographic proof
-Smart contracts can validate execution integrity
-The chain verifies, it does not trust blindly
Censorship resistance:
-No single API gatekeeper
-Model publishing is not platform-controlled
-Access logic is contract-defined
Data sovereignty:
-Data access rules can be enforced via protocol
-Execution validity is provable without exposing internals
The structural distinction:
Centralized AI → API access model
@OpenGradient → verifiable execution model
One optimizes for service delivery.
The other optimizes for trust minimization and composability.
Different guarantees.
Different assumptions.

4
17
24
116