
south-east asia, tech, health
Joined June 2011
- Tweets 1,038
- Following 892
- Followers 134
- Likes 897
18 Photos and videos
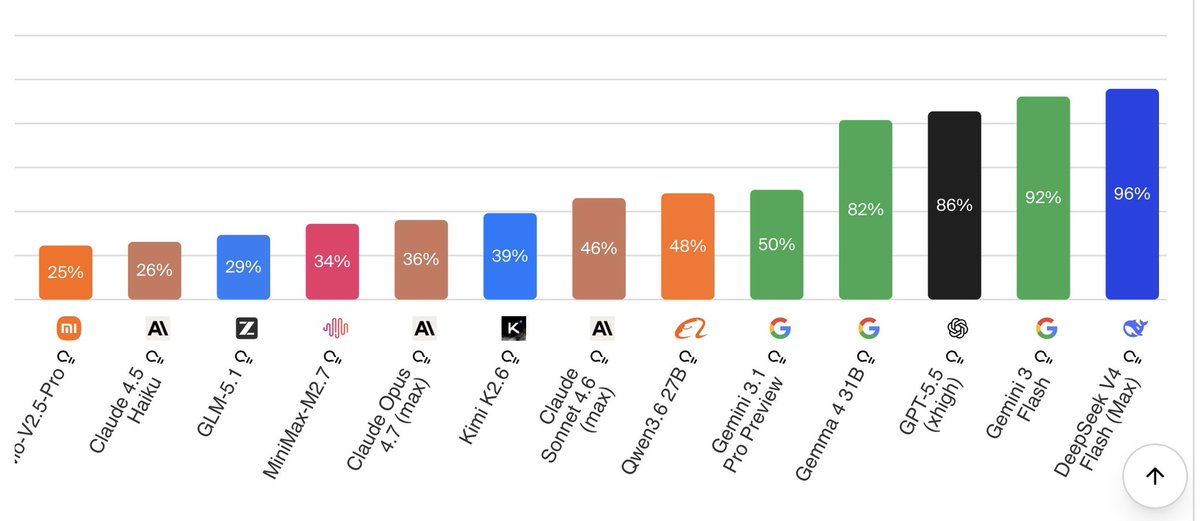



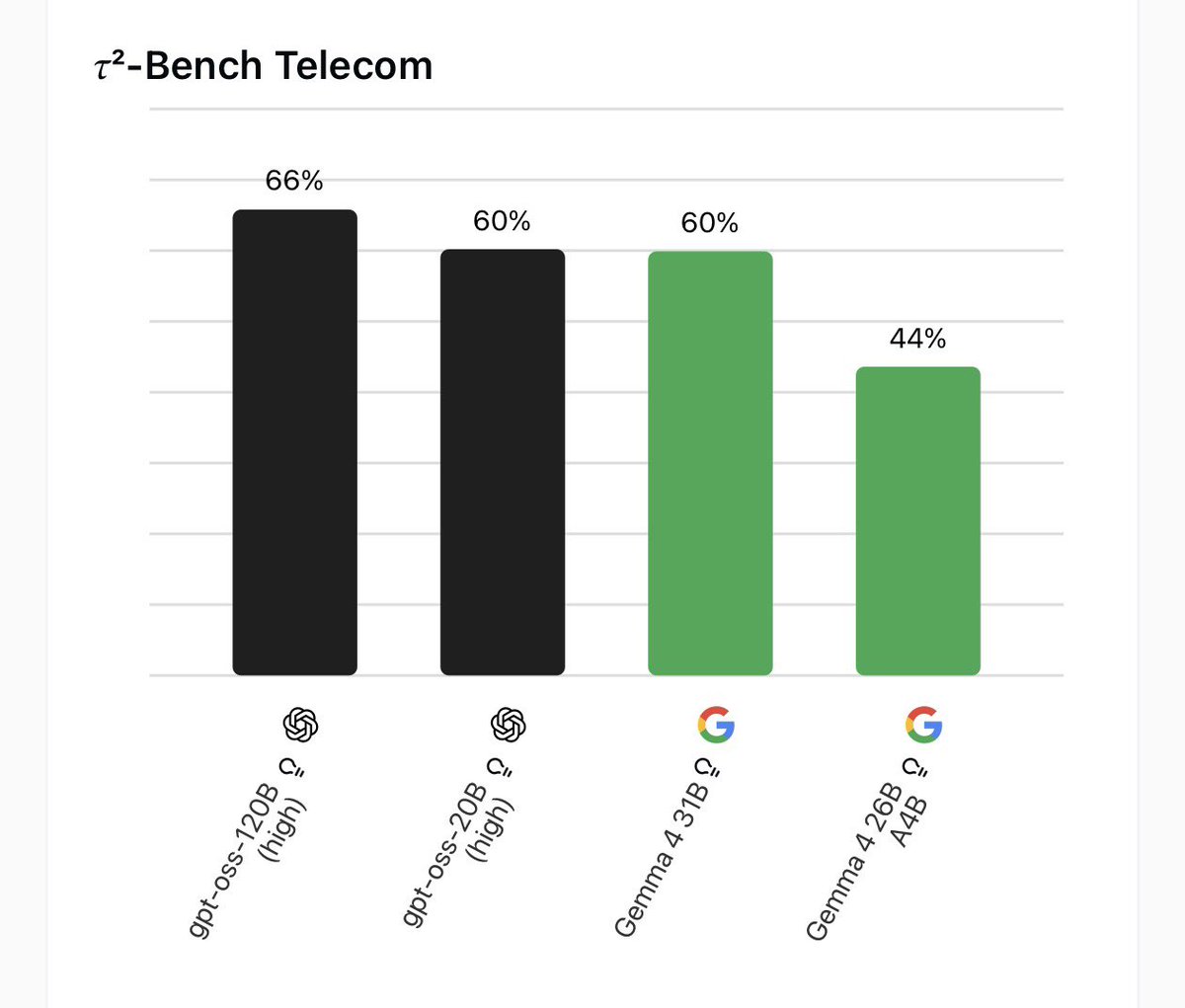
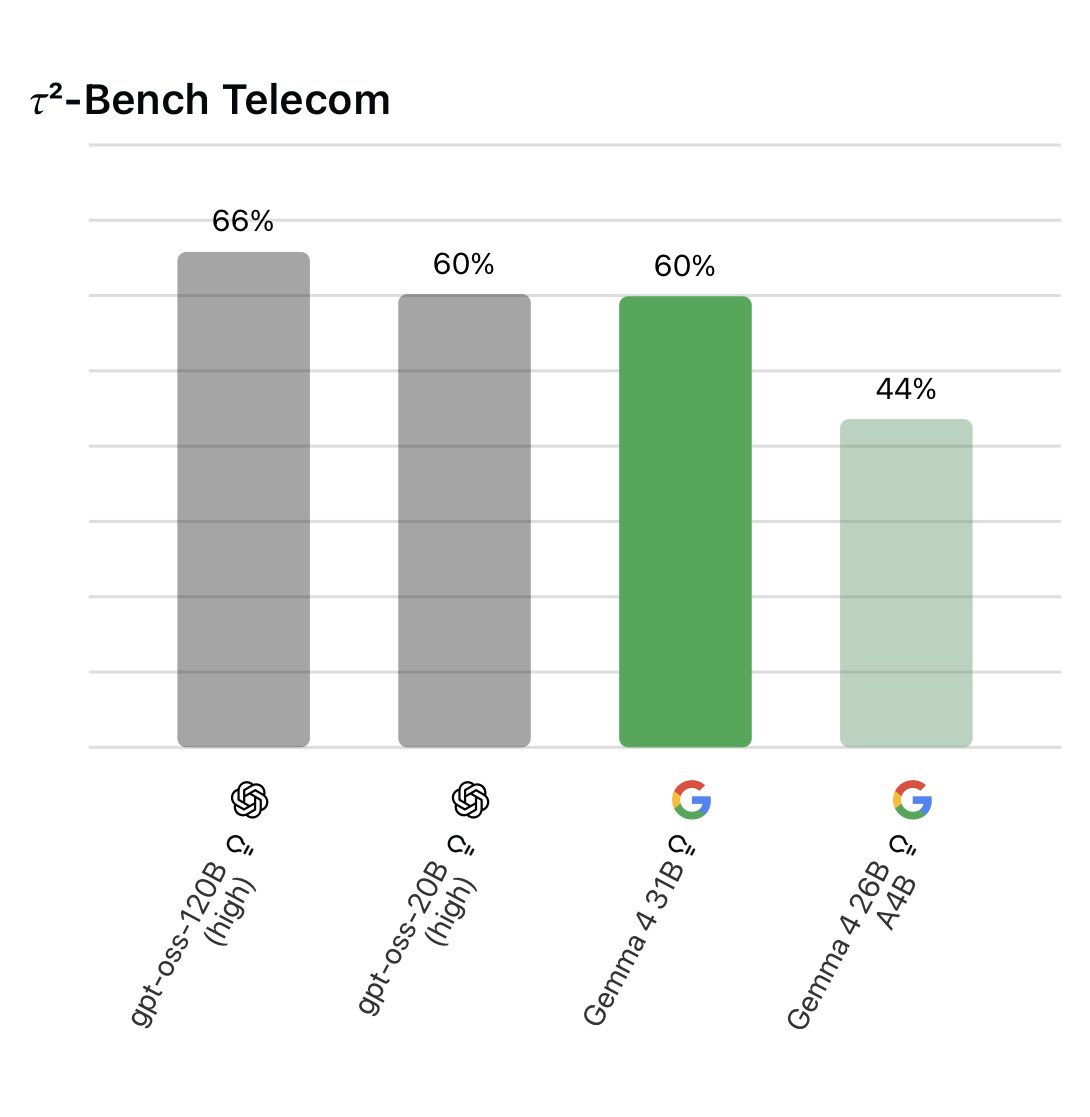

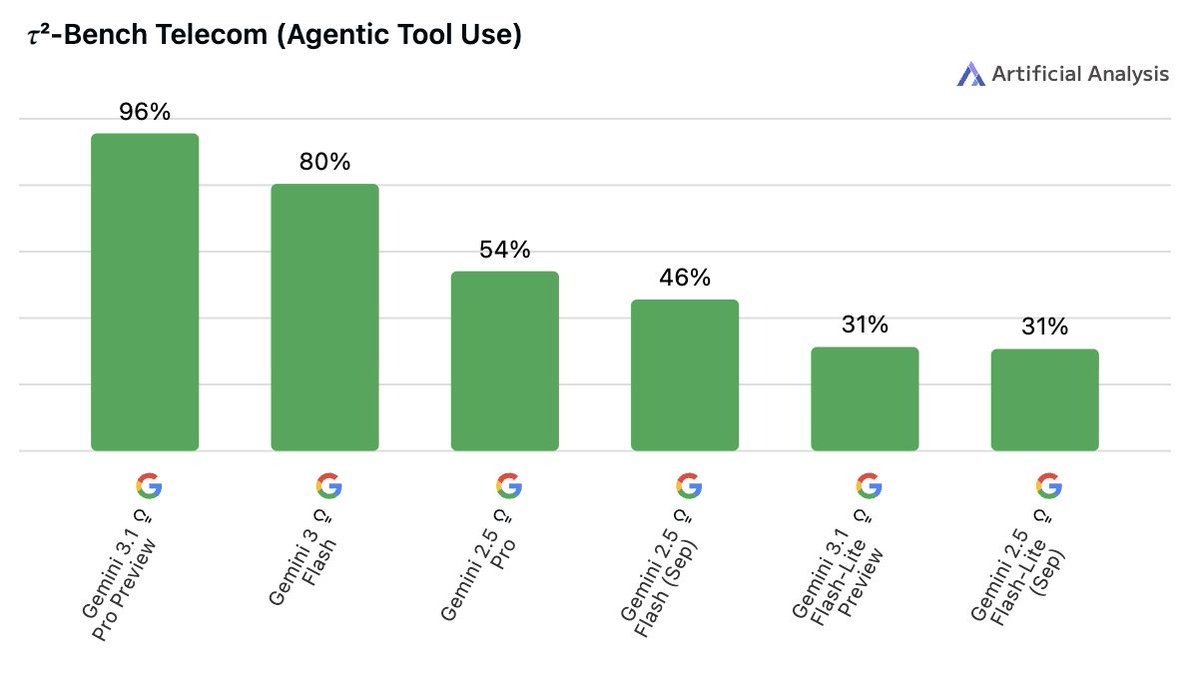
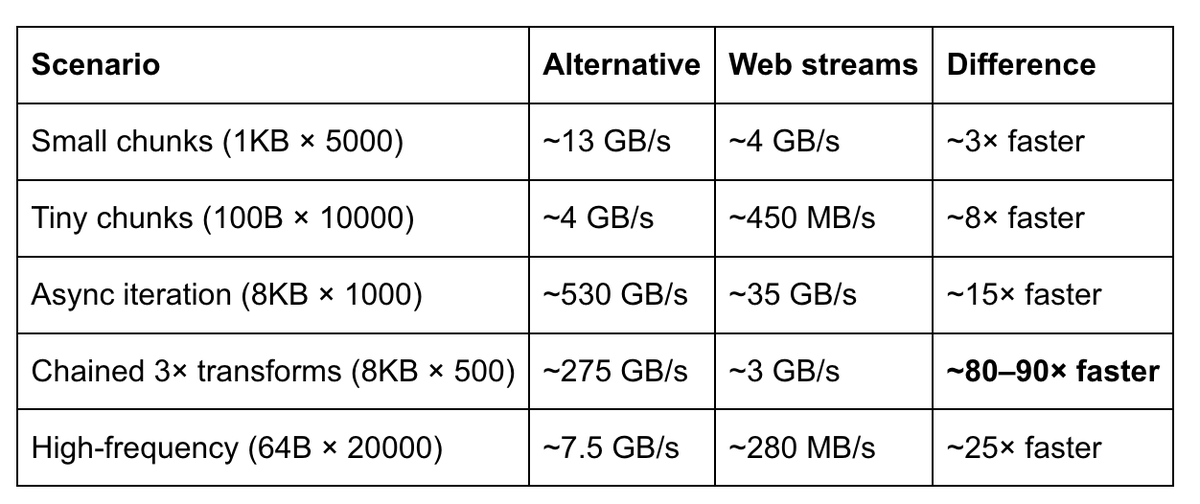
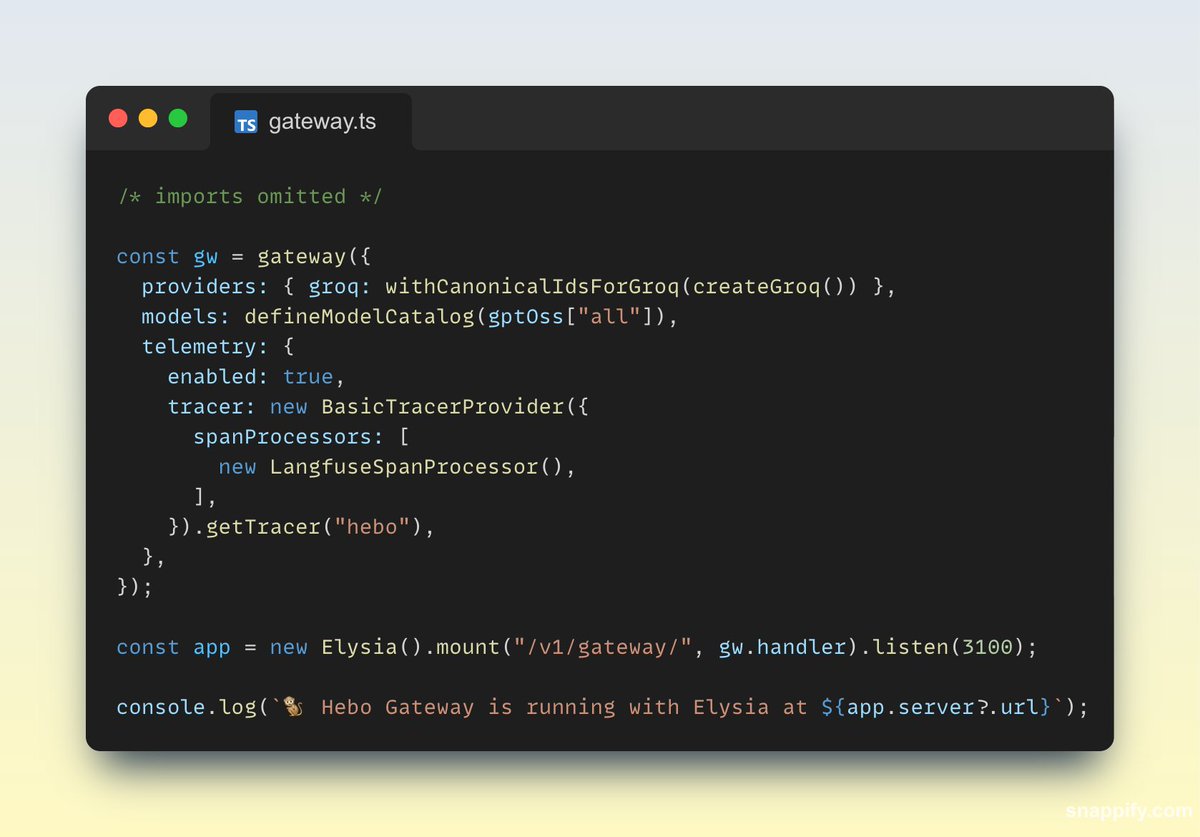
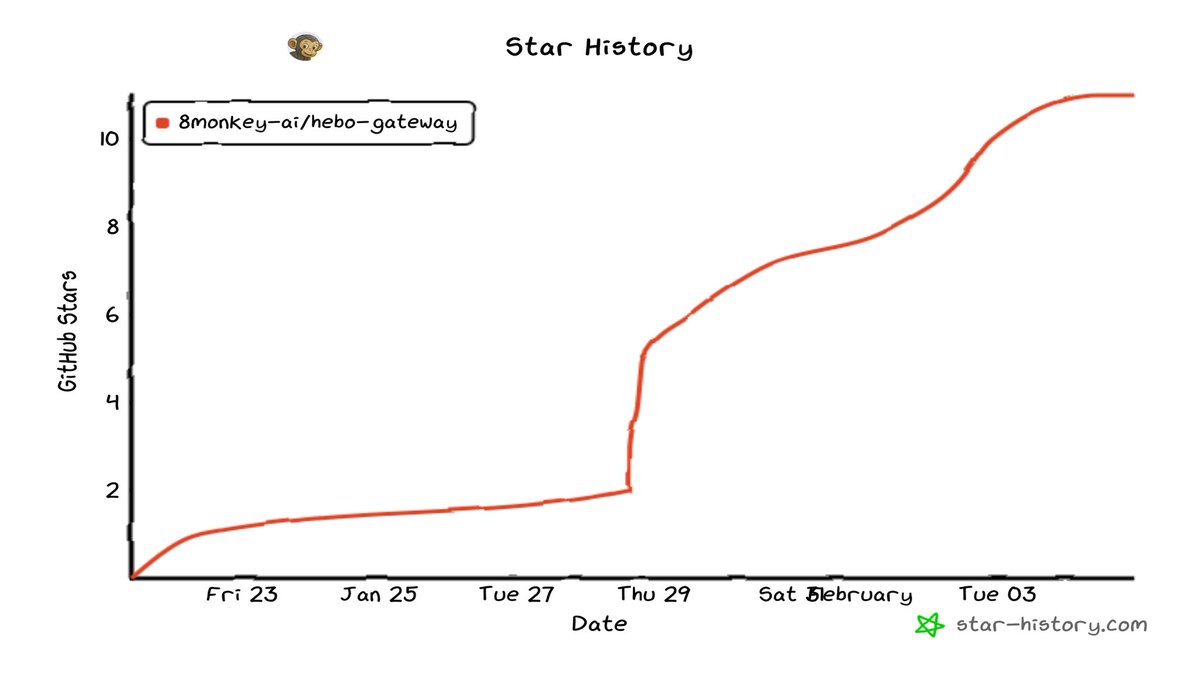
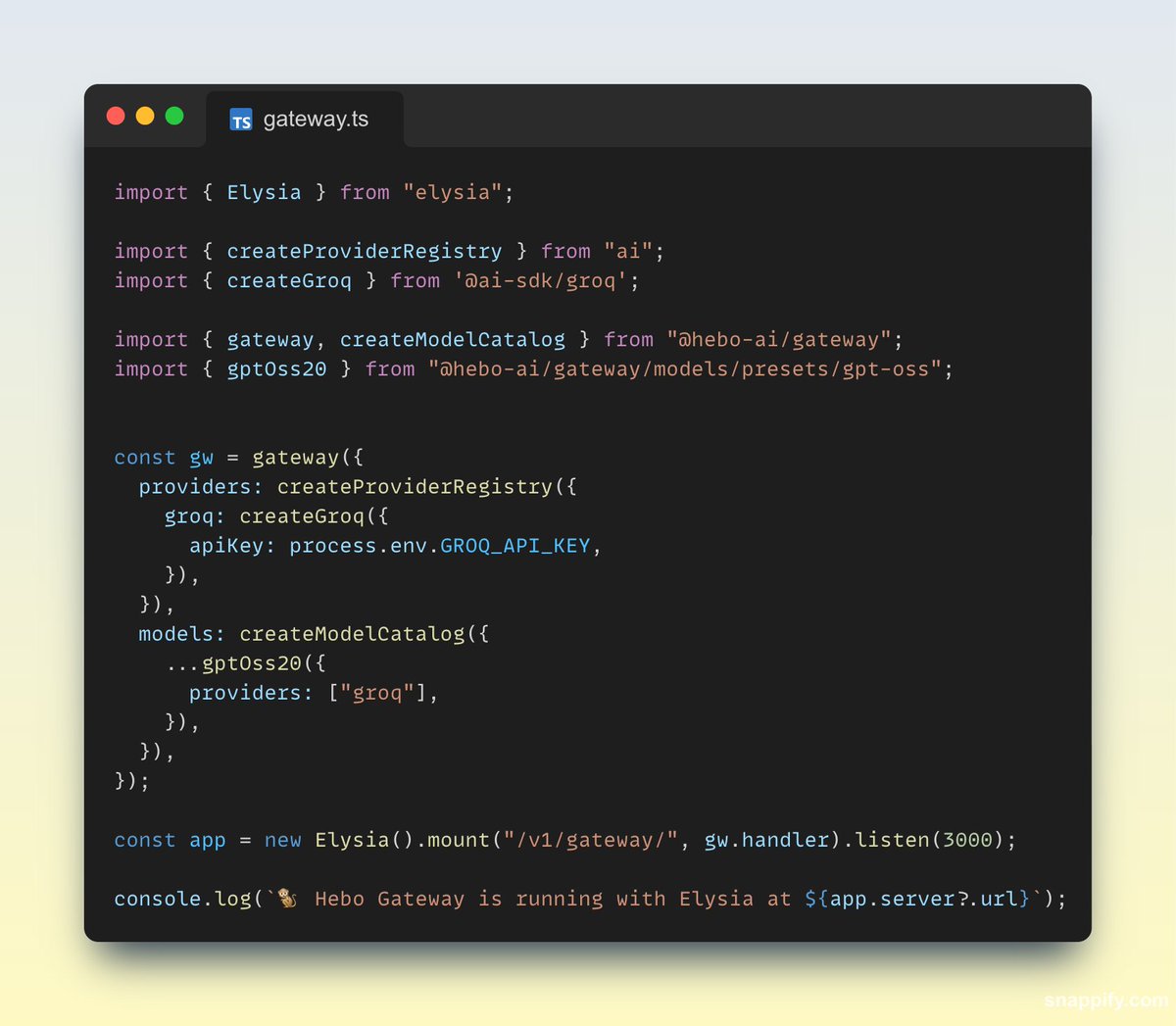


May 20
This is big for self hosting of OSS models
May 20

KV cache shouldn't disappear every time vLLM restarts. With @novita_labs, we're sharing PegaFlow — a production-grade external KV cache service that plugs into vLLM through the external KV connector interface.
PegaFlow runs as a standalone Rust daemon owning the host KV pool, SSD cache, and RDMA resources. vLLM workers attach via CUDA IPC gRPC, and cache survives engine crashes, upgrades, and model switches.
In production-oriented evaluations:
🚀 2.15× faster vLLM startup with a pre-warmed 500 GiB host pool
📈 56% higher throughput for 8 Qwen3-8B instances sharing one cache
⚡ 72% higher throughput for DeepSeek-V3.2 MLA TP8 (logical KV stored once, not per rank)
🌐 194 GB/s average remote-read throughput across nodes
Three-level hierarchy: pinned DRAM, remote DRAM over RDMA, local SSD on io_uring. Integrates through the existing `kv_transfer_config` path — no vLLM source changes.
📖 vllm.ai/blog/2026-05-18-pega…
27
May 4
What workstation / home server hardware do I need to serve Qwen 3.6 27b / Gemma 4 31b with 32k context window for 20 concurrent generations of ~150 output tokens at 10s latency?
CC @DrFriesOfficial @jun_song @__tinygrad__ @sudoingX
2
1
128
May 1
I tried @zeddotdev today.
Couldn't get used to it (yet):
1/ Default fonts feel way too big with too much tracking, not optimiezd for code
2/ Claude code in agent panel pauses for long times and doesn't seem to finish; can't connect my Codex Pro subscription
3/ Search bar layout breaks all the time, fits about five characters before overflowing into the next line
Love the direction of more simplicity, but might need another month or so of polishing.
104
Apr 29
A handful of small but impactful fixes to @aisdk that matter when running real agents in production:
github.com/vercel/ai/issues/…
github.com/vercel/ai/issues/…
github.com/vercel/ai/issues/…
Any chance to get them looked at?
CC @gr2m @aayushkapoor_ @lgrammel @felixarntz
1
1
151
Apr 29
Seems OpenResponses API has largely failed to become the universal layer. Everyone still defaults to /chat/completions (with some minor variations). Am I missing something?
36
Apr 28
This in itself would boost the S&P 500 by 5-6%.
Apr 28

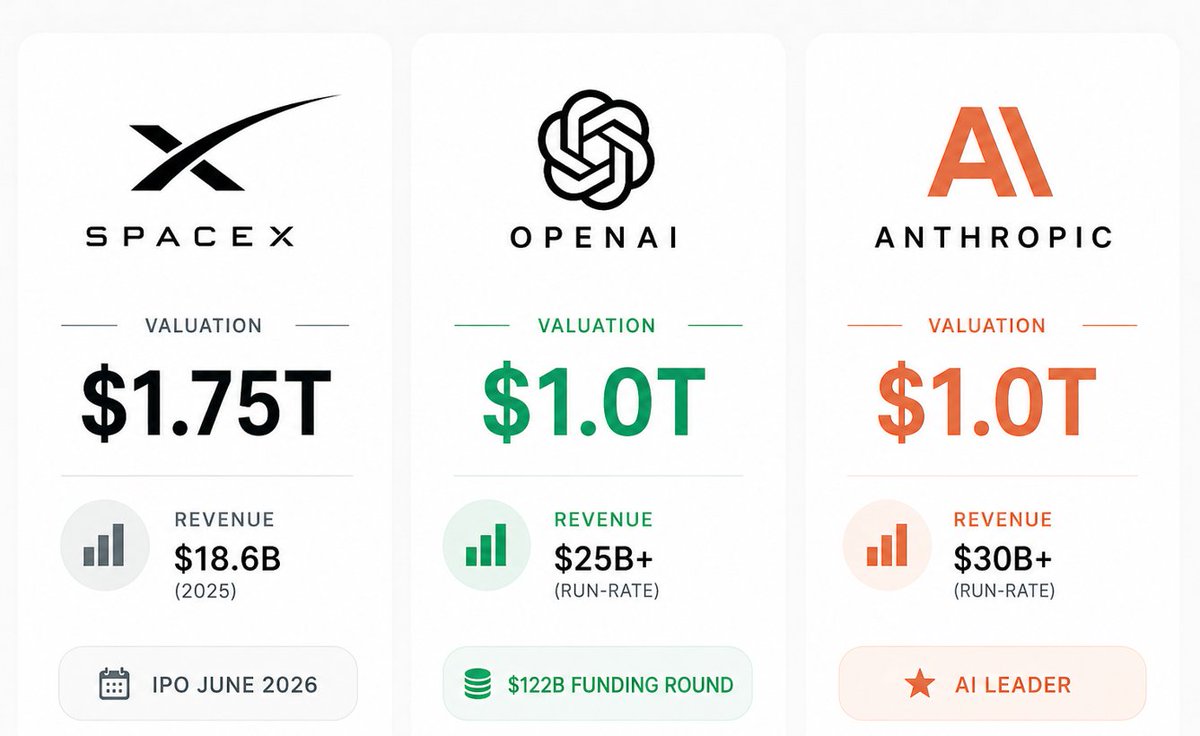
The biggest IPO run in the history of the market
three $1T companies. possibly all going public in the next 12 months.
SpaceX IPO: $1.75T.
OpenAI IPO: $1T
Anthropic IPO: $1T
we're living through the greatest technological wealth creation in history.
56
Apr 27
Smart. AWS distribution of OpenAI GPT models will outgrow any lock-in to Azure. Win-win.
Apr 27

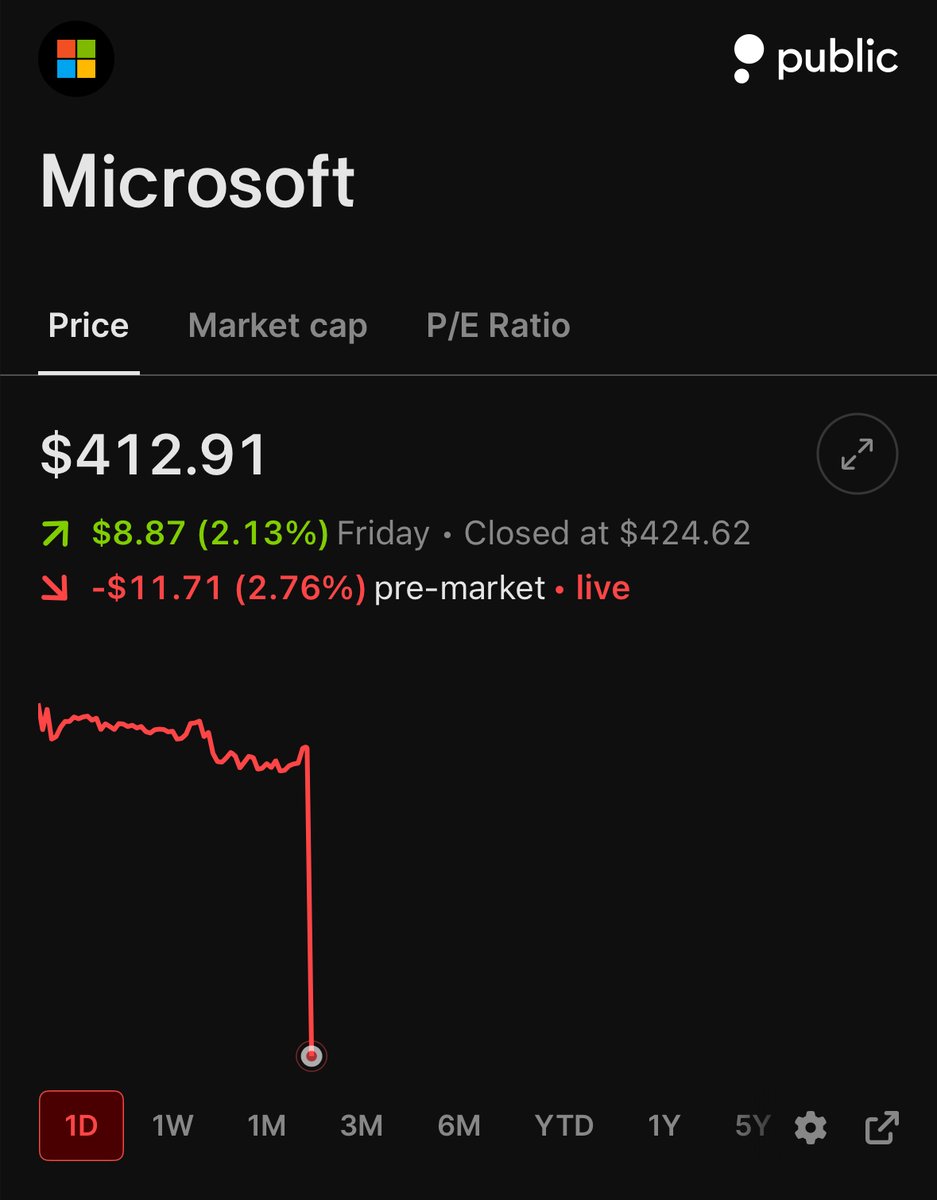
OPENAI AND MICROSOFT $MSFT JUST ANNOUNCED AN AMENDED PARTNERSHIP AGREEMENT
Here's what changes:
Microsoft will no longer pay a revenue share to OpenAI
OpenAI can now serve its products to customers across any cloud provider
Microsoft continues to participate in OpenAI's growth as a major shareholder and retains a license to OpenAI IP through 2032
Revenue share payments to Microsoft continue through 2030
(Source Reuters)
58
Apr 27
How many data centers could you build for that, powering the next generation of Malaysia - when the fuel runs out?

Malaysia is spending about RM8.28 million per hour, or RM2,300 per second, on fuel subsidies to cushion the impact of global supply disruptions.
The surge in crude oil prices has significantly increased fiscal pressure on the government, reports Berita Harian.
nst.com.my/news/nation/2026/…
🧵1

35
Apr 26
I love taking long range buses in Malaysia for exactly the same reason.
Apr 24

Yesterday I drove my @tesla 900 miles on FSD from Miami to Nashville and I realized it’s genuinely the better option.
I fly that route 2 to 3 times a month. Flights are never under $400. Most times $600. Sometimes $800.
Add Uber to and from both airports, or parking garage fees. Then factor in the delays, the cancellations, the security theater, the chaos, the guy next to you who hasn’t met deodorant yet.
On the other hand: I pack healthy snacks, press one button, and the car just goes.
I took calls. Replied to emails. FaceTimed my family. Ate without pulling over. Did everything I normally do on a travel day, except none of the stuff that makes travel days miserable.
My biggest concern going in was range and charging. Here’s what actually happened:
My bladder needed one extra stop the car didn’t even suggest. Most charging stops were under five minutes. Total cost for the whole trip was less than just the uber to the airport.
And this was the base model Y.
Now I’m thinking I should get something comfier and just make this the default.
34
Apr 26
Love the idea of @__tinygrad__ . Can you put the specs in some more relatable terms. Like:
1/ What’s the biggest model that it can run? (DeepSeek V4?)
2/ How many tokens/s can it produce with a common OSS model (Qwen 3.6 27B?).
3/ How many users can it serve in parallel at that speed?
4/ If I run this at 60/70/80% utilization, what’s my effective token price?
5/ What will be the real intelligence score when running at FP4/8 quantization?
48
Apr 21
The @aisdk team is doing an incredible job, but I‘d love them to put a bit more attention to community contributed PRs.
1
34
Apr 21
A few provider fixes that matter when using Agents at scale:
github.com/vercel/ai/issues/…
github.com/vercel/ai/issues/…
github.com/vercel/ai/issues/…
20
Apr 20
At this point of time @bunjavascript should change their release notes to; „Agents can now …“:
Bun 1.3.13: Agents can now develop faster by running tests in parallel across all CPUs (bun test —parallel)
Bun 1.3.12: Agents can now test UI workflows using a headless Browser (Bun.WebView)
Bun 1.3.11: Agents can now be scheduled to run automatically every n-hours (Bun.cron)
Bun 1.3.0: Agents can now expose a native TUI to communicate with users (Bun REPL)
…
86
Apr 20
Who is winning the race of creating the most and most confusing model names, OpenAI with GPT-* or Alibaba with the Qwen series?
28