
20 Photos and videos












WisePaper × GPUhub
Building the Vibe Research ecosystem.
Structure your ideas. @wispaper
Run your models. @hub_gpu
Ship faster.
#VibeResearch
#AIResearch
#MachineLearning
#LLM
5
4
5
435
GPUHub retweeted
🚀 The Future of AI is HERE!
Unlimited LLM APIs from FanLabs — instant access to the best models:
• oLLAMA 3.1 8B
• Mistral Nemo 2407
• Meta Llama 3
• Qwen2-7B
• Gemma 2-9B
and many more with Cloud GPUs Elastic Deployment!
No limits. No hassle. Pure power. ⚡
#AI #LLM #UnlimitedAI #FanLabs #FutureOfAI
1
1
21
GPUHub retweeted

May 22
Full breakdown Its here.. medium.com/@zeinstech/32-res…
You can ready fully..
I hope this helps..
1
1
79
GPUHub retweeted
May 18
📊 32 Research Tools to Level Up Your Paper (2026)
From literature review to publication — every tool you need for efficient, productive research.
✅ Free tools
✅ Paid tools (worth it)
✅ All pricing verified
#Research #AcademicTwitter #DataScience #PhDLife #ResearchTools #AI #Productivity

1
1
1
74
GPUHub retweeted

May 5
I wasted ~$100 testing GPU clouds so you don't have to
47 hours, 5 providers, 1 Llama-3-70B fine-tuning
winner: GPUhub at $16.92
loser: Lambda at ~$45 (storage fees got me)
wrote it all up here:
medium.com/@zeinstech/i-test…
hope it helps 🙏
1
2
120
medium.com/@zeinstech/i-test…
Real pricing. Real testing. No sponsorships. This is one of the few GPU cloud comparisons that actually feels unbiased. If you’re choosing between providers, this is worth a read.
1
1
2
86

Our Scholar Agent is officially here to transform your research workflow! 🎉🎉🎉
From initial brainstorming to technical execution, WisPaper’s Scholar Agent handles the heavy lifting:
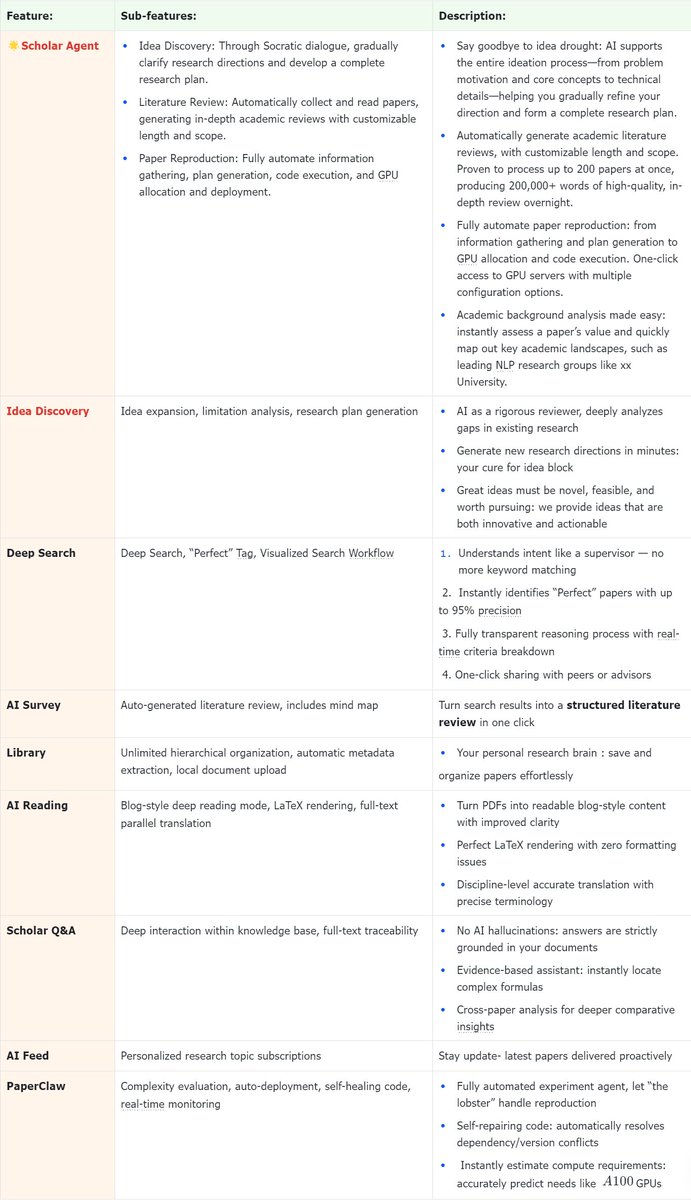
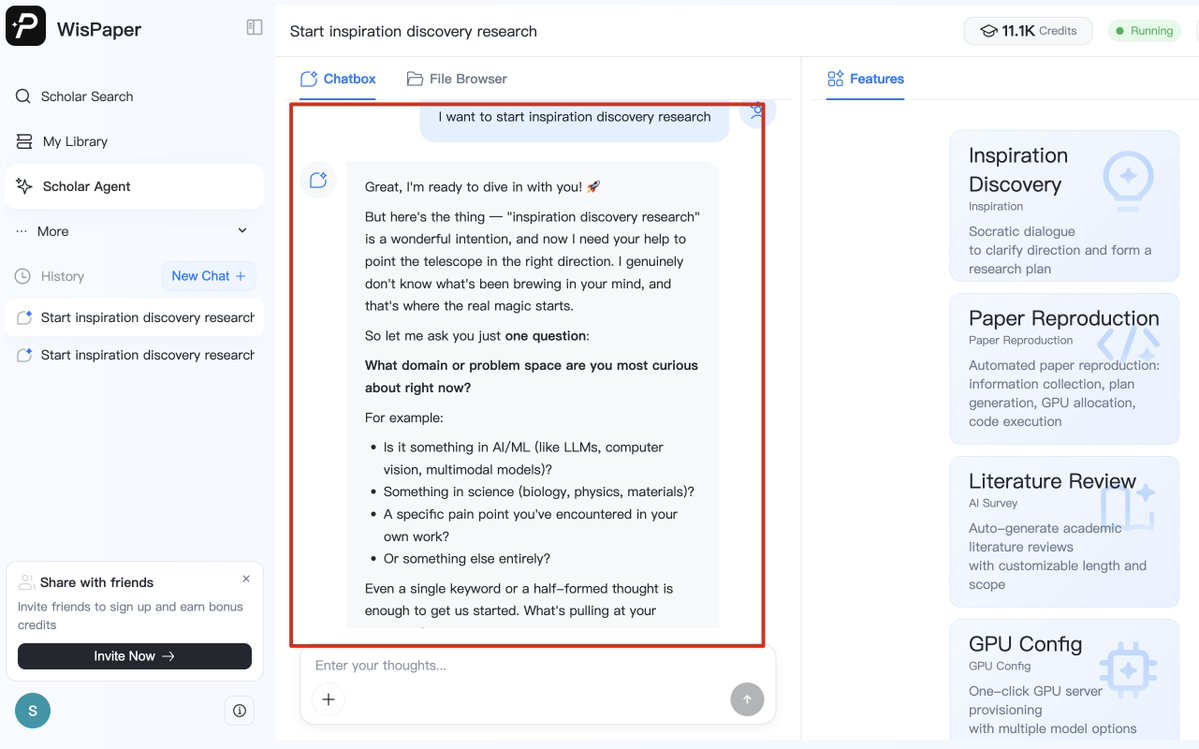
1⃣Idea Discovery
Say goodbye to idea drought. Through Socratic dialogue, our AI helps you clarify research directions, define problem motivation, and develop a complete research plan.
2⃣Literature Review
Automatically process up to 200 papers at once. Generate in-depth academic reviews (200,000 words) overnight with customizable length and scope.
3⃣Paper Reproduction
Fully automated from information gathering to code execution. Includes one-click access to GPU servers with multiple configuration options for seamless deployment.
4⃣Academic Background Analysis
Instantly assess a paper’s value and map out key academic landscapes, including identifying leading research groups in fields like NLP.
Ready to supercharge your scholarship? Try the new Scholar Agent now!
[wispaper.ai/?utm_source=x&ut…]
#WisPaper #ScholarAgent #AcademicTwitter #AIforResearch #ResearchInnovation #ResearchTools #PhDLife
1
2
142


GPUHub retweeted
Apr 16
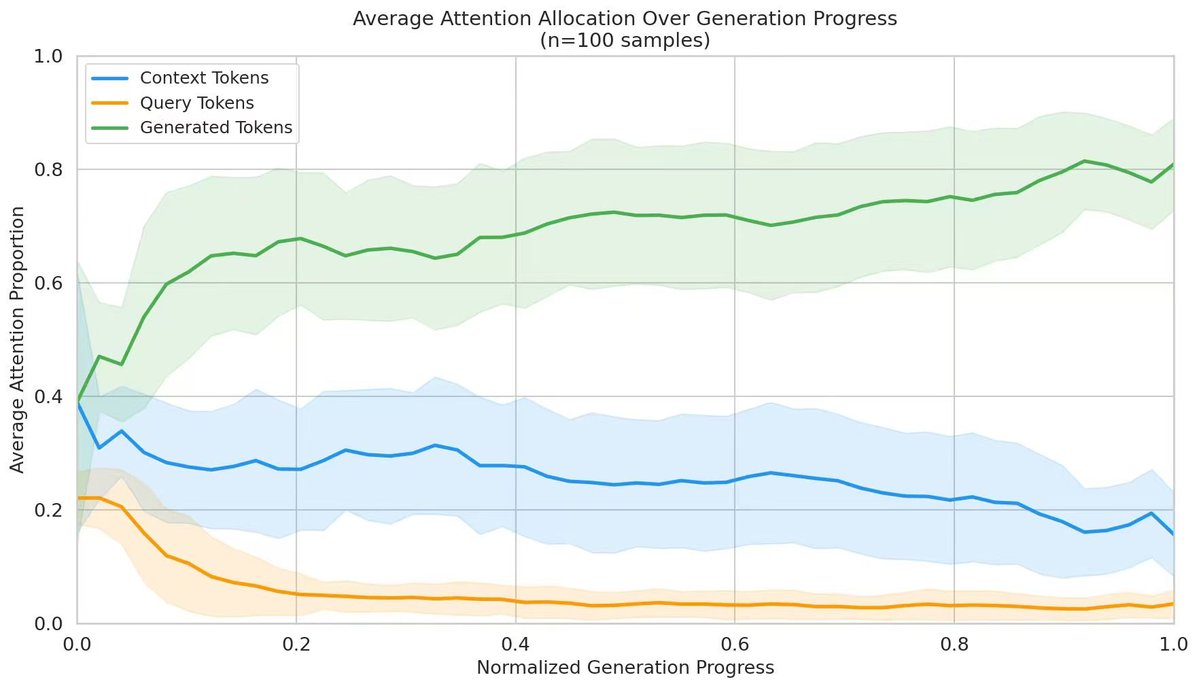
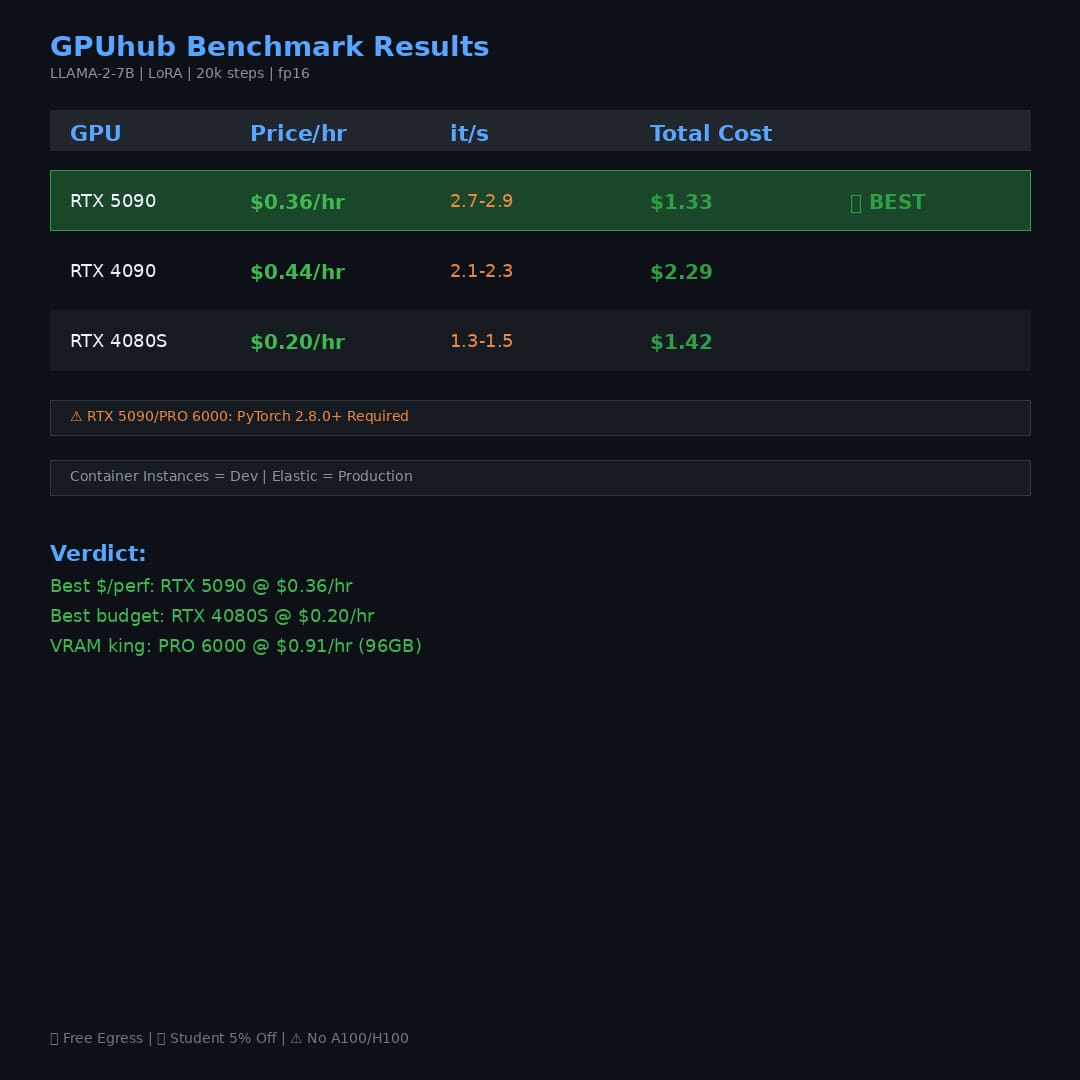
🧵 @hub_gpu Benchmark: RTX 5090 vs 4090 vs 4080S
Tested 48h for LLM fine-tuning. Here's what you need to know:
1
1
2
58
GPUHub retweeted

Apr 8
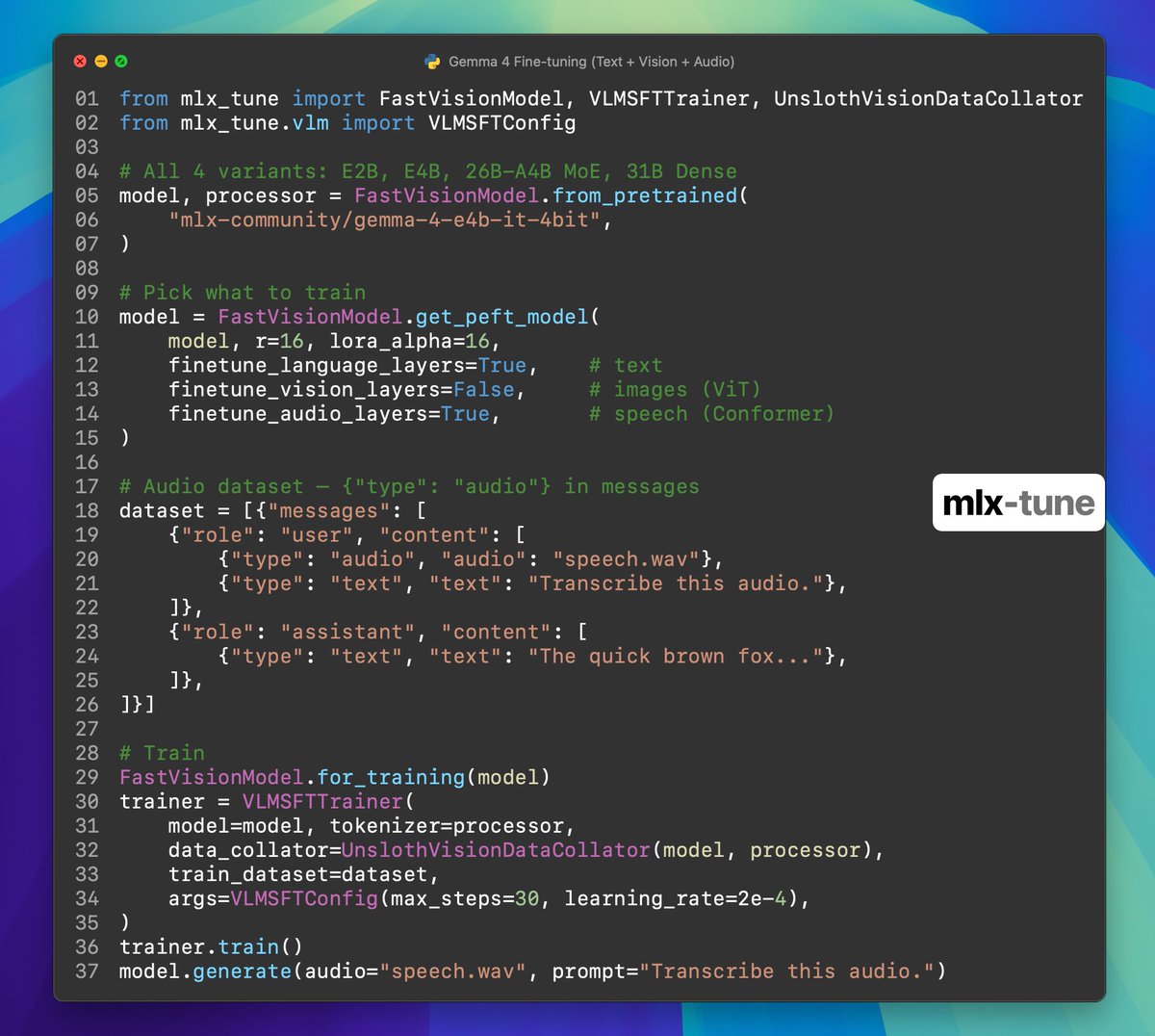
The full Gemma 4 family is now fine-tunable on your Mac! 🍏✨
You can now fine-tune the entire family locally with mlx-tune:
✅ E2B & E4B (Text, Vision, Audio)
✅ 26B-A4B MoE & 31B Dense (Text, Vision)
The best part? No complex routing. One unified FastVisionModel API handles it all. Want to train the built-in Conformer for ASR or Audio QA? Just flip the boolean flags and hit train.
5 complete example scripts are up in the repo! 👇
github.com/ARahim3/mlx-tune
@GoogleDeepMind @googledevs @GoogleResearch @GoogleAI @awnihannun
3
31
317
16,874
GPUHub retweeted
Most “AI case studies” I see feel like marketing slides.
The ones I actually care about are the simple, honest ones:
– here’s what we tried
– here’s how long it took
– here’s how much VRAM and money it actually used
@hub_gpu is starting to collect stories in that direction — more “real experiments”, less buzzwords. If you’re into that kind of thing, worth keeping an eye on 👇
gpuhub.com/case-studies
#MachineLearning #CloudGPU #MLOps
2
3
6
73
GPUHub retweeted

I trained a large-scale image generation model using 8× RTX 5090 GPUs on GPUHub (@hub_gpu ) — and it was surprisingly smooth.
Here’s what happened 👇
1/3
#AI #GenerativeAI #StableDiffusion #ComfyUI #CloudGPU #MachineLearning #DeepLearning #AIArt #GPU #Tech #MLOps #BigData
2
1
1
57
GPUHub retweeted
This is what my “ML lab” looks like now:
– modest machine at home
– rent a 24GB GPU only when I actually need it
– run YOLO/SDXL/LLM experiments end‑to‑end, then shut it down
Instead of a 4090 in my room, I get a GPU I can turn on/off like this 👇
1
2
3
73
GPUHub retweeted
Different GPU options I’ve used:
– Colab/Kaggle → great for demos, sessions/timeouts get in the way for multi‑hour training
– RunPod/Vast → lots of raw power, but node quality/configs vary, you need to babysit jobs
– local GPU → nice latency, but you pay in upfront cost maintenance
For most of my workloads (YOLO on non‑toy data, SDXL, 7B LoRA), the best trade‑off so far has been:
– rent a 24–32GB GPU
– treat it like a lab bench (spin up → experiment → shut down)
I’ve been using GPUhub @hub_gpu for that pattern:
gpuhub.com/?utm_source=zein&…
1
1
63
GPUHub retweeted
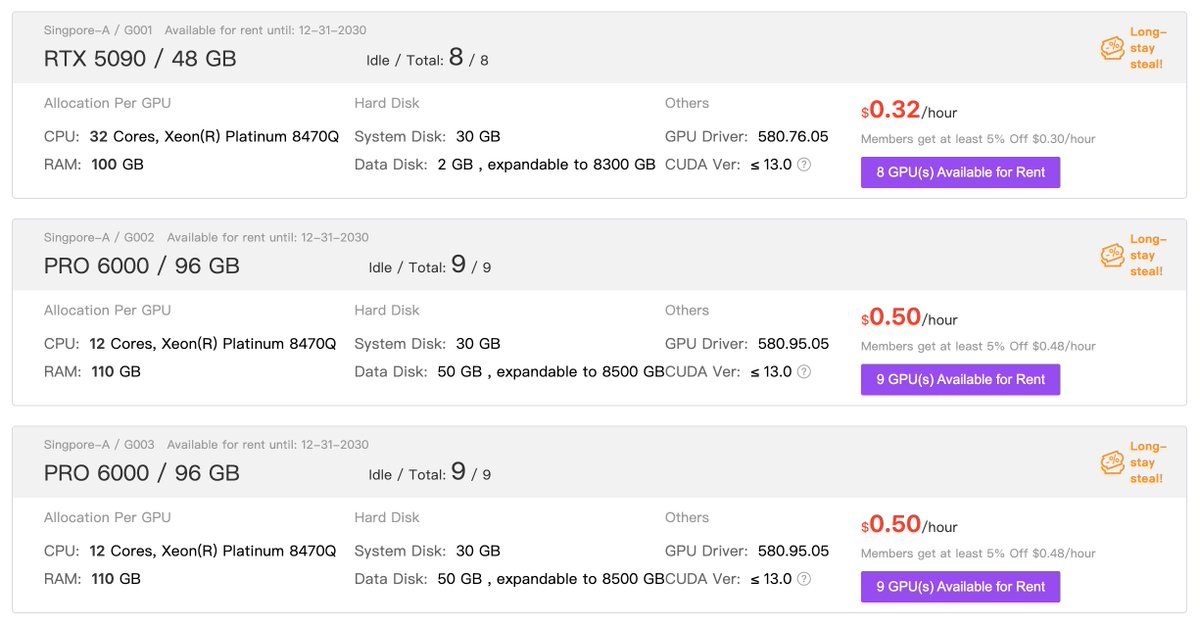
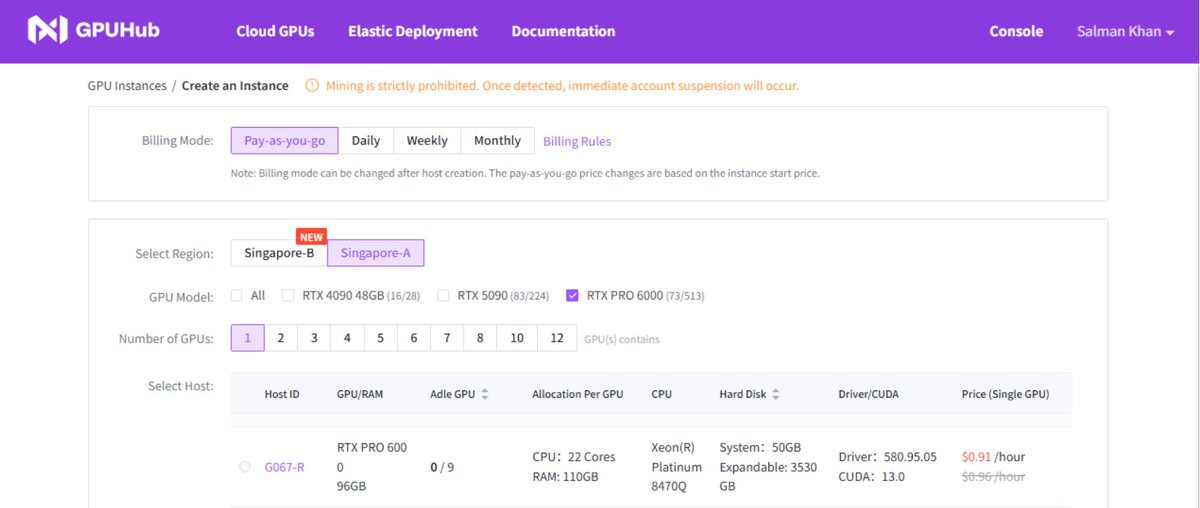
Deployed on GPUHub @hub_gpu
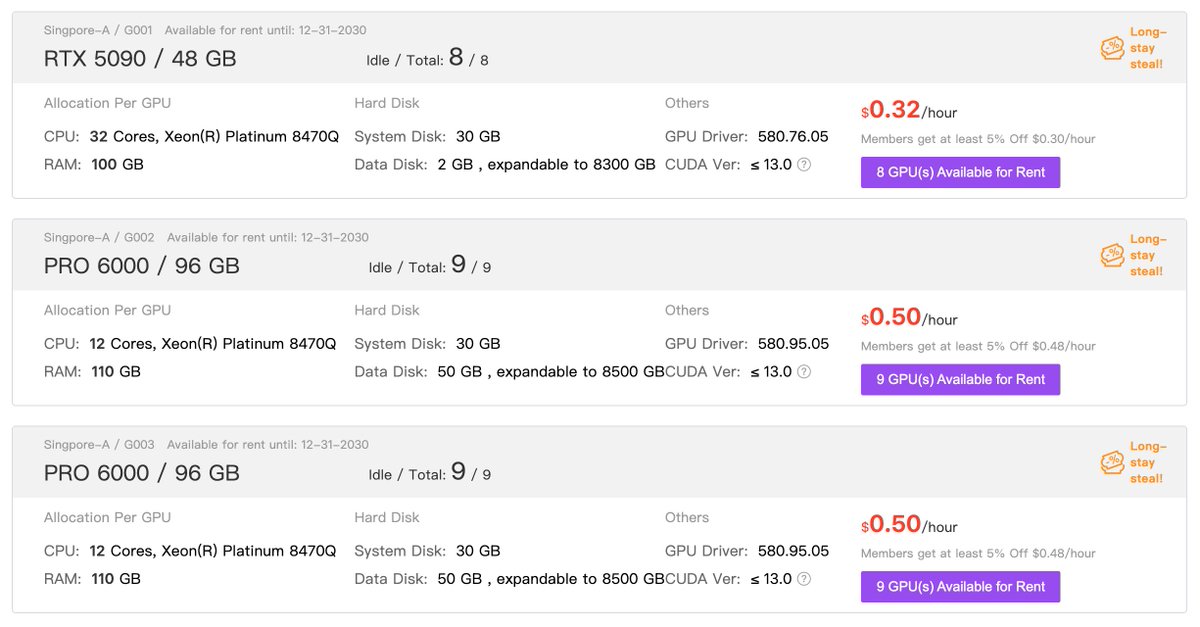
(Singapore-A | G067-R | RTX PRO 6000 — ~$0.91/hr)
Setup was simple, & within minutes I had a powerful environment ready.
Built a full ComfyUI pipeline with:
✔️ Stable Diffusion
✔️ ControlNet (structured outputs)
✔️ InstantID (consistent faces)
2/3
1
2
3
57
GPUHub retweeted
I started building generative AI workflows locally… but quickly hit GPU limits 😅
Slow inference, memory issues, constant crashes.
So I moved everything to the cloud.
1/2
#AI #GenerativeAI #StableDiffusion #ComfyUI #CloudGPU #MachineLearning #DeepLearning #AIArt #GPU #Tech
2
1
1
38
Can AI understand code from screenshots? Yes. We tried it with Qwen2-VL-2B.
reddit.com/r/learnmachinelea…
1
2
3
65
Trained YOLOv8 on VisDrone with an RTX 5090. No instability. No wasted time. Dedicated GPUs hit different. #AI #MachineLearning #YOLOv8 #GPU #DeepLearning
reddit.com/r/learnmachinelea…
1
2
4
68
GPUHub retweeted
Mar 20
Yaay! 🎉 Just noticed the repo crossed 800 stars and 50 forks.
It is honestly the best feeling to see a personal project you built for your own workflow actually helping out so many other developers.
Huge thanks to everyone testing it and contributing!

Mar 5

Big update! 🚨
The project has grown so fast (nearing 5k downloads!) that folks started thinking it was an official Unsloth product, even with a disclaimer on the repo.
The Unsloth team was super supportive at launch, but seeing the community's confusion, they reached out. After a great chat, I’m officially renaming the project to mlx-tune to keep things clear!
The vision remains exactly the same: bringing that seamless, Unsloth-like fine-tuning experience to Mac users. Same code, just a shiny new name.
Update your pipelines: pip install mlx-tune

1
1
3
206