
Joined September 2014
- Tweets 4,828
- Following 1,526
- Followers 5,736
- Likes 8,062
767 Photos and videos






Daniel van Strien retweeted

Jun 13
I disagree with this decision and I don't like it.
But also...
HOW DID ANTHROPIC NOT SEE THIS COMING‽
It is *the* obvious response to "this is too dangerous for anyone except us to use", since that relies on a premise ("we are uniquely good") that almost no-one agrees with.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
232
206
3,121
207,254
Daniel van Strien retweeted

Jun 13
M3 would never 🙂↔️
As a matter of fact, the weights are now open, too.
huggingface.co/MiniMaxAI/Min…
Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
241
472
6,478
500,225
Daniel van Strien retweeted

🏃♀️💨 hf-sandbox is faster and more reliable than ever!
Use it for your agents, RL training, to serve your model, or whatever else you can think of!
3
34
2,561
Daniel van Strien retweeted

Jun 9
Super excited to announce that @arcee_ai is the first major American AI lab to replace AWS S3 with Hugging Face for ALL their models and datasets, public AND private 🔥🔥🔥
Multi-million $ partnership to support American open-source AI, let’s go!

41
60
512
60,780
Daniel van Strien retweeted

Jun 12
🔗 Weights & code: huggingface.co/moonshotai/Ki…
12
61
802
106,323
Daniel van Strien retweeted

Jun 11
PP-OCRv6 just released by Baidu @PaddlePaddle
✨ tiny 1.5M / small 7.7M / medium 34.5M
✨ 48 languages
✨ Supports handwritten/printed/industrial/screen and card text
✨ Edge friendly deployment

8
56
461
22,418
Daniel van Strien retweeted

Jun 12
🚀PP-OCRv6 is officially released!
🔥PaddleOCR’s new OCR model series scales from 1.5M to 34.5M parameters, bringing stronger accuracy, faster inference, and broader deployment options — from browsers and edge devices to servers.
📊What’s new:
🔸Tiny / Small / Medium models: 1.5M, 7.7M, 34.5M params
🔸 4.9% detection accuracy and 5.1% recognition accuracy over PP-OCRv5
🔸Up to 5.2× faster CPU inference with OpenVINO
🔸50 languages in one unified model
🔸New scenarios: PCB, CAD drawings, digital tubes, dot-matrix text
🔸Apache 2.0 open source
✨Lightweight OCR, built for the AI data era.
🔗Try it:
🌐 paddleocr.com
💻 github.com/PaddlePaddle/Padd…
🤗huggingface.co/collections/P…
#PaddlePaddle #PaddleOCR #OCR #AI #ComputerVision #OpenSource #EdgeAI


7
37
315
23,669

Yesterday: diffusion LM beats AR on OCR correction.
Today, after a suggestion from the @GoogleDeepMind team: bench it against its parameter-matched twin instead (same 26B MoE, same 4B active).
The twin wins slightly on quality. The diffusion model is still ~10× faster.
Updated scoreboard
CER on 19th-c newspaper OCR (lower = better):
• OCR input: 0.066
• Gemma-4-E4B: 0.042 (15.3s/passage)
• DiffusionGemma: 0.035 (1.7s 🚀)
• Gemma-4-26B MoE: 0.027 (16.3s)
Equal capacity: diffusion trades accuracy for an order of magnitude of speed.
Also tried the suggested sampler fixes (thx @joao_gante!) for the "seeded canvas just copies its input" bug. They free the model from copying but it re-derives the input instead of correcting it. Might still be some tweaking here?
Full agent-written lab notebook, scripts runnable straight from the bucket: huggingface.co/buckets/davan…
3
3
37
2,484


Happy to announce the launch of the Far-Field ASR Leaderboard! 🎉
While many ASR benchmarks focus on clean speech, real-world applications need to handle noise, reverberation, and distant microphones.
This leaderboard makes it easier to evaluate speech recognition models under realistic acoustic conditions and compare their robustness across challenging environments.

5
16
125
9,236
Daniel van Strien retweeted

DiffusionGemma, our experimental open model released under an Apache 2.0 license, explores text diffusion, an exceptionally fast approach to text generation.
Here’s how DiffusionGemma accelerates development:
Faster token output: By shifting the bottleneck from memory bandwidth to raw compute, the model generates up to 4x faster token output on dedicated GPUs
Accessible hardware footprint: Activates just 3.8B parameters during inference, fitting comfortably within 24GB-VRAM high-end consumer GPUs when quantized
Novel workflows: Parallel token generation enables self-correction, making it ideal for code infilling, in-line editing, and non-linear structures
DiffusionGemma prioritizes speed over raw quality and accelerates best on compute-bound hardware (like @NVIDIAAI GPUs). Standard @GoogleGemma 4 remains recommended for production quality and memory-bound devices.

30
43
444
116,255
Can @googlegemma DiffusionGemma help fix broken OCR?
In theory, denoising tokens in parallel could work better for OCR correction since context is seen upfront?
Pointed it at 19th-century newspaper OCR. It corrected better than the autoregressive baseline — at ~8x the speed.
6
38
410
35,980
For me, this was a negative result: 2–5 steps, but it barely edits with 61/75 outputs identical to the noisy input. Real text is off-distribution as noise, so the sampler just accepts it maybe? (You can try this in the demo)
1
4
614
Try it: live demo on @huggingface ZeroGPU with the step-by-step denoising replay, side-by-side diffs vs the human transcription, and the full benchmark table.
huggingface.co/spaces/davans…
7
625
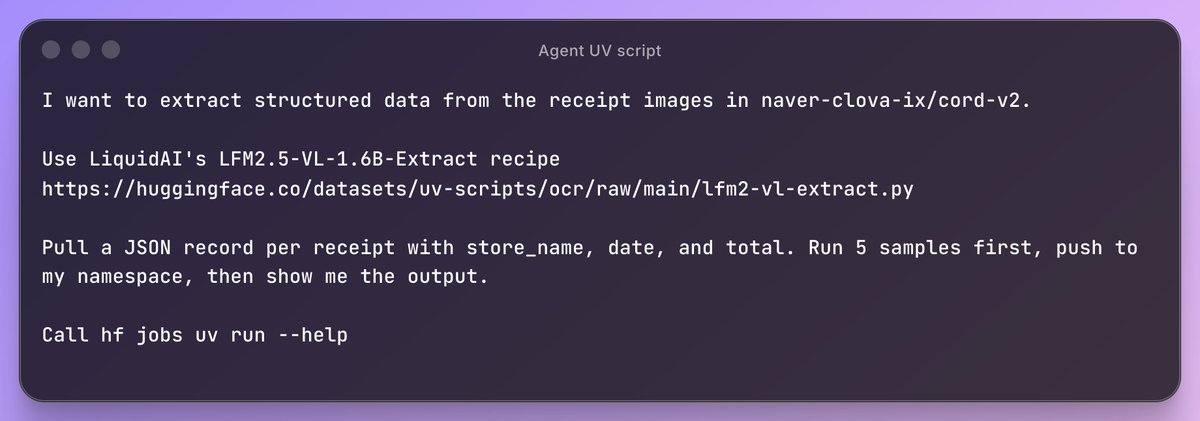
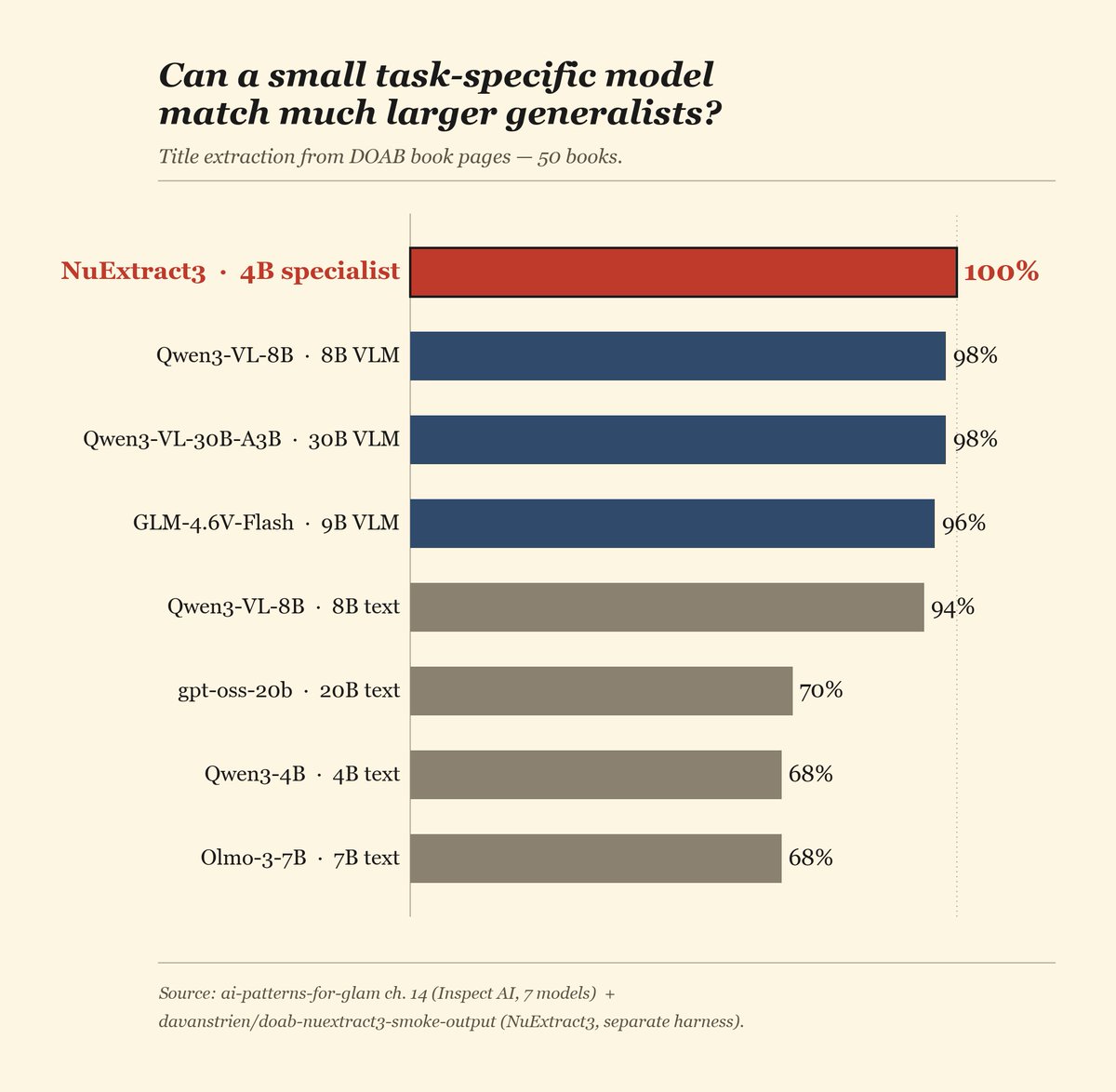
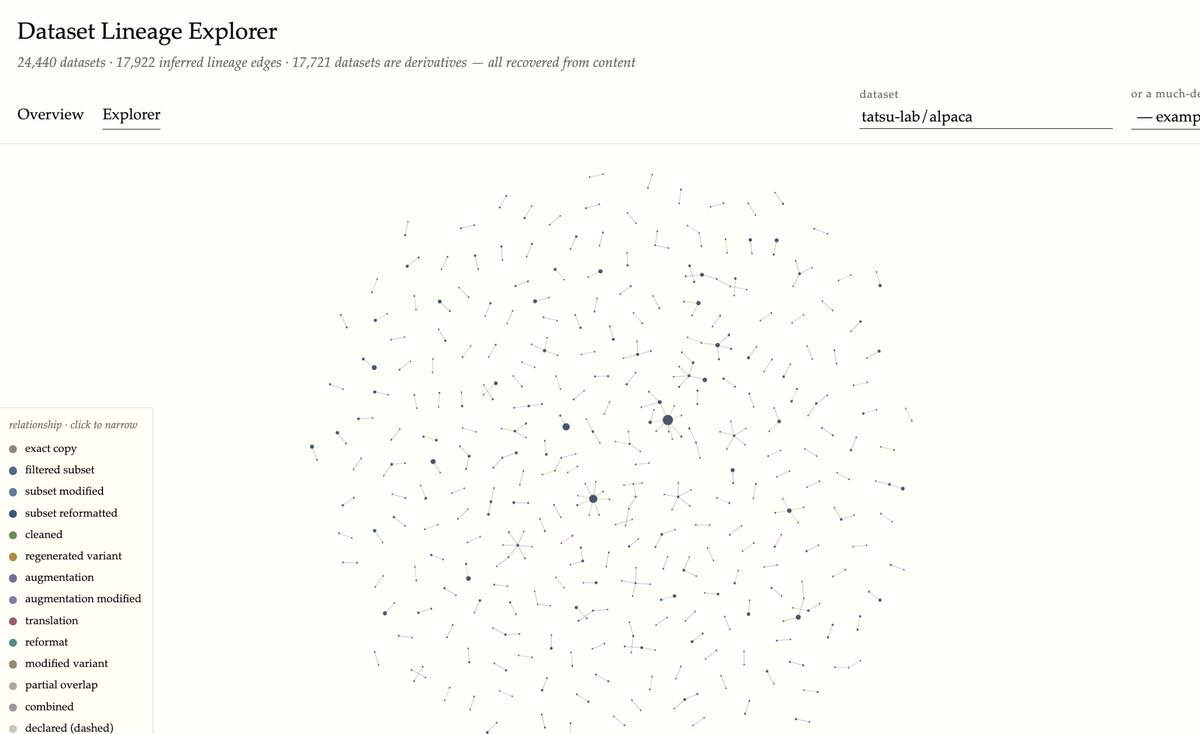
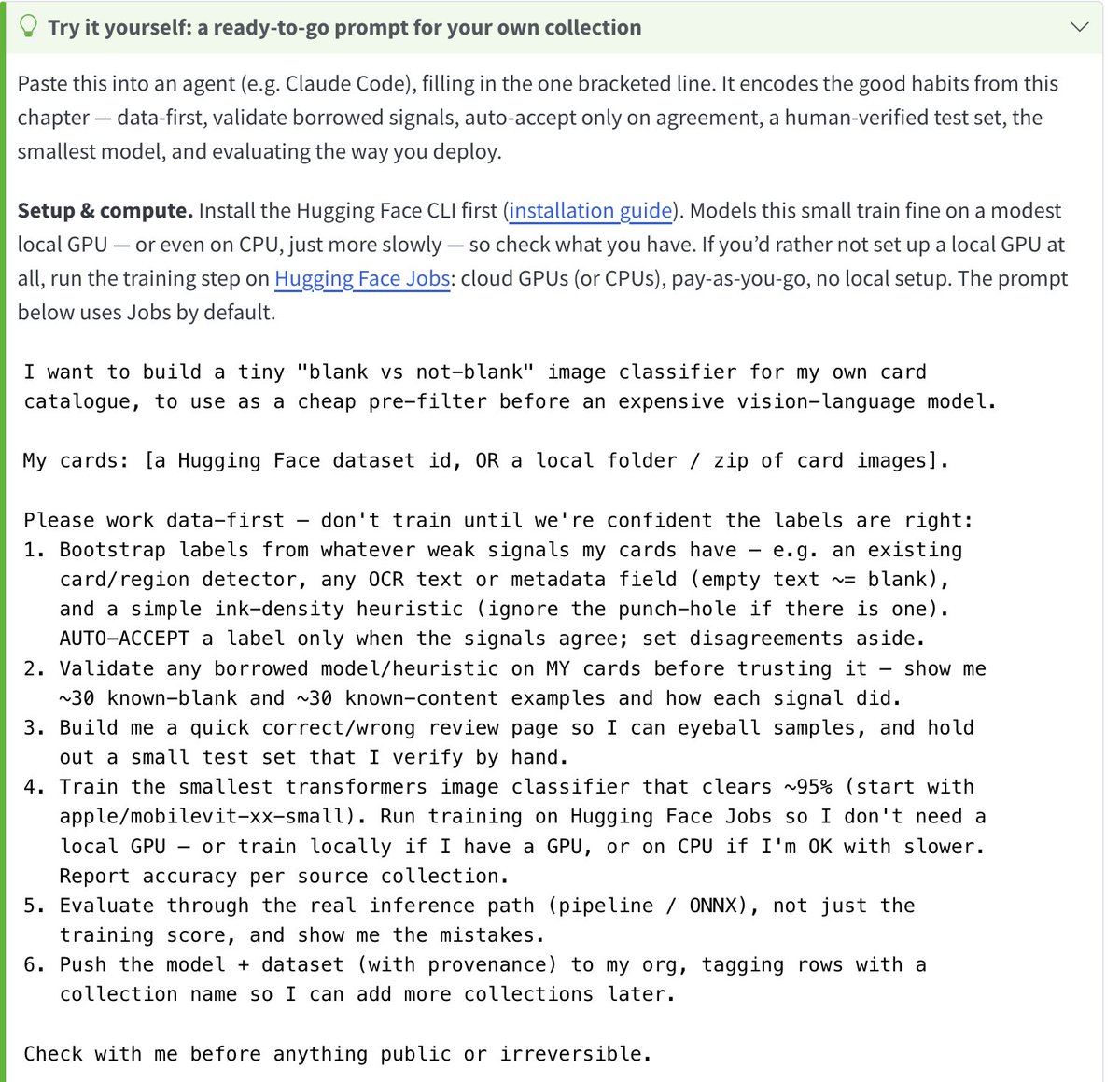
Used an agent for a naughty no no use case while I still can: fine-tuning a domain-specific small VLM to be good at information extraction in the library/archive/historical research domain.
Pointed an agent (Opus 4.8, Fabel refused....) at 🇫🇷 🇬🇧 handwritten death records and manuscript-catalogue cards.
Resulted in a 4B model (from @numind_ai's NuExtract-3) that even follows schemas it's never seen. Agent found SFT beat GRPO but maybe @AnthropicAI sabotaged my GRPO experiments....
The agent labelled its own training data. All training /evals done via @huggingface Jobs.
🤗 huggingface.co/small-models-…
Blog post soon!
1
11
947