
perplexity per picojoule @anthropicai // prev @openai @tesla
Joined May 2012
- Tweets 2,318
- Following 3,069
- Followers 27,940
- Likes 15,819
202 Photos and videos











Pinned Tweet

Jun 6
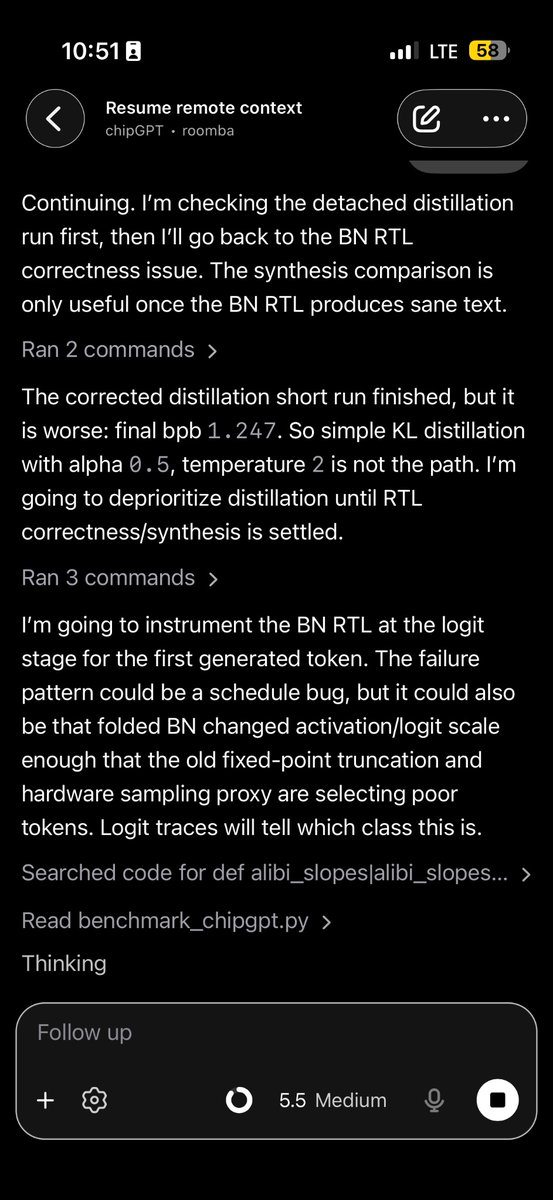
Personal update: I’ve decided to leave OpenAI.
I’m proud to have been part of the custom chip program and grateful to everyone I got to build with and learn from along the way. The density of hardware talent on that team is extraordinary, and I don't think there's a better chip design team anywhere. It's been a wild journey from second hardware hire, 2.4 years ago, to now, and I'm excited to watch these chips become one of the most important engines of AGI.
At the same time, I haven’t been able to shake the pull to climb a new mountain from the bottom again!
I joined @AnthropicAI this week because I was deeply impressed with the team’s talent, values, and ambition, and I'm already energized by the pace and intensity of the past few days. It’s time to build.
391
322
7,423
2,789,081
Jun 6
Personal update: I’ve decided to leave OpenAI.
I’m proud to have been part of the custom chip program and grateful to everyone I got to build with and learn from along the way. The density of hardware talent on that team is extraordinary, and I don't think there's a better chip design team anywhere. It's been a wild journey from second hardware hire, 2.4 years ago, to now, and I'm excited to watch these chips become one of the most important engines of AGI.
At the same time, I haven’t been able to shake the pull to climb a new mountain from the bottom again!
I joined @AnthropicAI this week because I was deeply impressed with the team’s talent, values, and ambition, and I'm already energized by the pace and intensity of the past few days. It’s time to build.
391
322
7,423
2,789,081
Jun 6
(sadly can't say much about the chip just yet outside of openai.com/index/openai-and-… - but the blogpost says `targeted to start in the second half of 2026` so keep an eye out for stuff soon!)
10
9
627
149,538

Clive Chan retweeted

Jun 4
Ex-OpenAI Tech Lead, Justin Lebar joins SemiAnalysis as an Visiting Fellow to Burn $10,000 in 3 hours to find dozens of AMDGPU LLVM, x86 LLVM, NVPTX bugs
00:00 - Intro & Justin’s background
00:59 - How compiler fuzzing works
01:56 - Why we did this project
02:48 - The gap in GPU vs. CPU compiler testing
04:13 - The major AMD & x86 bugs we found
05:38 - Using LLMs to read code & find vulnerabilities
07:56 - The impact of UltraCode mode
12:18 - Doing this without AI (Time & manual limits)
15:03 - The future of AI in software development
16:17 - What’s next key takeaways for devs
9
34
376
70,833
Jun 1
honestly pretty solid idea
Jun 1

New @nytimes op-ed by @BernieSanders calls for sovereign wealth fund tied to the stock of frontier labs.
Whether or not you back this idea, his closing is a reminder that people support what they help build. Absent more meaningful mechanisms for people to share their views on AI and shape its development, the backlash will grow and “missed uses” will become the default (ie we will fail to realize the most beneficial uses of AI).
“It must be decided by workers, parents, teachers, artists, scientists, communities and the American people. It’s our future. We must decide it.”

11
5
56
26,682
Jun 1
most confidential filing in the history of filings, maybe ever
Jun 1

Anthropic has confidentially submitted a draft S-1 registration statement to the Securities and Exchange Commission.
Pending completion of SEC review, this gives us the option to pursue an initial public offering.
Read more: anthropic.com/news/confident…
8
2
207
34,580
Clive Chan retweeted

May 29

SpaceX has almost finished writing V1.0 of an in-house AI training stack in C that exact-maps to 220k GB300s with 800G NICs, making heavy use of pipeline parallelism and getting as close to bare metal as possible.
The potential speed improvement vs JAX for large training runs is over an order of magnitude.
6
6
84
48,675
May 29
>hundreds of parallel subagents
gonna hit your quota in like 3 seconds

Also new in Claude Code: dynamic workflows (research preview).
For the hardest tasks, Claude makes a plan, runs hundreds of parallel subagents, and verifies its work before reporting back. Think a migration touching hundreds of files.
Read more: claude.com/blog/introducing-…
8
5
131
25,007
May 28
Improving CPU speed by 10x should not affect training speed essentially at all.
The CPU's main job is to kick off the real work on the GPU. If your kernels are sane (fused etc), the time to launch a kernel on the CPU is <<1% of the kernel runtime, even in Python.
SpaceX has almost finished writing V1.0 of an in-house AI training stack in C that exact-maps to 220k GB300s with 800G NICs, making heavy use of pipeline parallelism and getting as close to bare metal as possible.
The potential speed improvement vs JAX for large training runs is over an order of magnitude.
39
19
543
134,491
May 28
Besides that, much of the time when launching a lot of small kernels sequentially is consumed by the Nvidia driver itself (which is already in C ), not by the training framework (which is what Elon's rewrite is about). There's a lot of first principles here being missed.
2
1
84
15,821


May 26
leo xiv joining anthropic as MTS (member of theological staff)

4
2
54
10,284
May 24
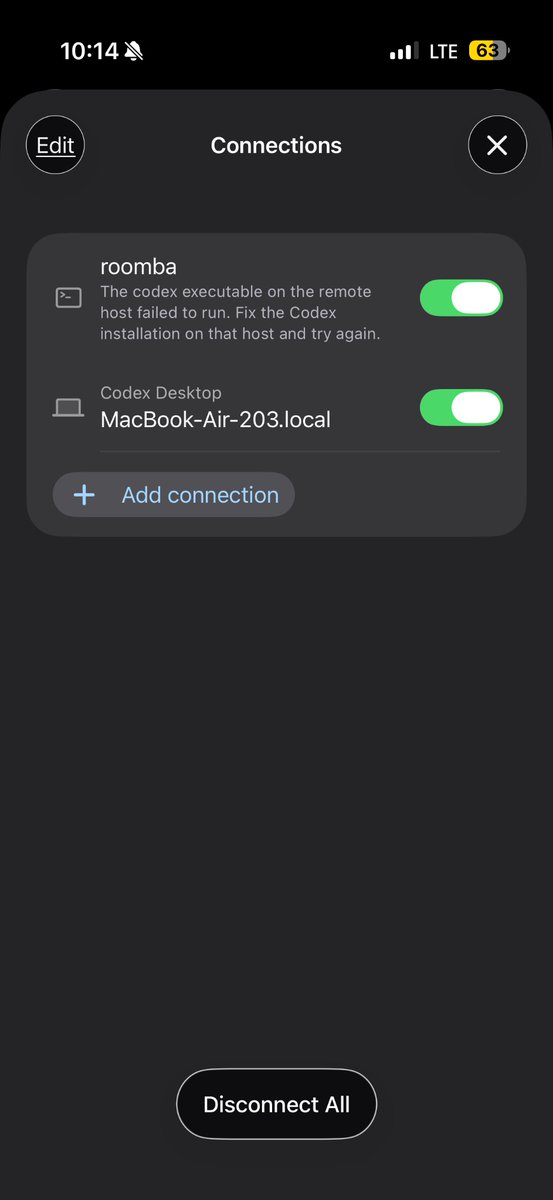
gave claude code a try for a side project. some first impressions (as compared to codex):
- remote control is basically unusable, keeps disconnecting. codex takes much longer to load conversations but at least the connection persists
- feels generally quicker, nice for rapid iteration. or maybe i need to dial down my codex thinking effort?
- dictation is much worse, it’s constantly wrong and cuts off early. in codex i never have to think about it, it’s just always right
- app forgets the text i wrote when i switch conversations, ugh
- vague vibe that it’s more proactive than codex (like, anticipating what i want, not just following explicit instructions)
- i miss codex’s tab = queue, enter = interrupt
- both are awful at multimodal tool use, both have similar algos intelligence, both cli harnesses feel the same & have similar text rendering issues
overall it’s a wash except for claude app being behind. agentic coding really is still in early days!
10
5
110
12,367
May 22
another one. this will be good
May 22

New blackboard lecture w @reinerpope
How do chips actually work – starting with basic logic gates, and working up to why GPUs, TPUs, FPGAs, and the human brain each look the way they do.
0:00:00 – Building a multiply-accumulate from logic gates
0:16:20 – Muxes and the cost of data movement
0:25:59 – How systolic arrays work
0:39:00 – Clock cycles and pipeline registers
0:51:40 – FPGAs vs ASICs
1:03:14 – Cache vs scratchpad
1:07:16 – Why CPU cores are much bigger than GPU cores
1:11:49 – Brains vs chips
1:15:22 – A GPU is just a bunch of tiny TPUs
Look up Dwarkesh Podcast on YouTube/Spotify/etc to watch. Enjoy!
1
3
34
8,169