
Joined March 2019
- Tweets 20
- Following 75
- Followers 160
- Likes 903
Photos and videos
Pinned Tweet

Jan 13
We trained models with MXFP4-quantized attention, but it turns out this can break causal modeling. Our latest post explains why this happens and how to fix it.
matx.com/research/leaky_quan…
1
17
103
32,165
tensorpro retweeted

Apr 29
Did a very different format with @reinerpope – a blackboard lecture where he walks through how frontier LLMs are trained and served.
It's shocking how much you can deduce about what the labs are doing from a handful of equations, public API prices, and some chalk.
It’s a bit technical, but I encourage you to hang in there - it’s really worth it.
There are less than a handful of people who understand the full stack of AI, from chip design to model architecture, as well as Reiner. It was a real delight to learn from him.
Recommend watching this one on YouTube so you can see the chalkboard.
0:00:00 – How batch size affects token cost and speed
0:31:59 – How MoE models are laid out across GPU racks
0:47:02 – How pipeline parallelism spreads model layers across racks
1:03:27 – Why Ilya said, “As we now know, pipelining is not wise.”
1:18:49 – Because of RL, models may be 100x over-trained beyond Chinchilla-optimal
1:32:52 – Deducing long context memory costs from API pricing
2:03:52 – Convergent evolution between neural nets and cryptography
150
598
6,563
1,281,008
tensorpro retweeted

Apr 15
I chatted with @ysmulki about MatX, chip design and where silicon designed for LLMs is headed
(8:17) Tightly coupling SRAM and HBM on one chip
(14:03) More MoE FLOPS, smaller KV cache load
(16:08) Numerics: from 32-bit to 4-bit
(19:02) Targeting both training and inference
(22:14) Chip timelines
(27:15) Logic and memory scarcity
(29:42) Compute costs
(32:07) Latency: from 20ms to 1ms as the new table stakes
(40:50) Programming the chip
(43:00) Starting MatX
(47:11) Codesign without seeing the models
(51:57) Interconnect design
(55:44) Performance modeling philosophy
(1:07:02) Prefill vs. decode
(1:13:47) What's next
15
45
326
69,631
tensorpro retweeted

Mar 1
Many Iranians have given more than anyone should ever have to give for a chance at freedom
Freedom to speak, think, love, learn, work, dress, create, gather, believe or not believe
2
1
4
309
tensorpro retweeted

Feb 26
Reiner Pope (@MatXComputing) just raised a $500m round led by @leopoldasch and Jane Street to build faster AI chips. I enjoyed having him on Cheeky Pint so I could ask all my questions about how chip design actually works, where the speed-up comes from, and how the industry will evolve.
00:00:15 Google’s AI revival
00:07:54 MatX
00:17:11 AI supply chain
00:21:48 Designing chips
00:37:11 TSMC
00:44:17 Token pricing
00:44:55 RL-ing chip design
00:49:26 Design to production
00:56:05 MatX culture
01:02:57 Rust
01:05:21 Cuckoo hashing
01:09:35 Unexplored model architectures
21
41
433
53,589
tensorpro retweeted

Feb 25
With the coming tsunami of demand for tokens, there are significant opportunities to orchestrate the underlying memory compute *just right* for LLMs.
The fundamental and non-obvious constraint is that due to the chip fabrication process, you get two completely distinct pools of memory (of different physical implementations too): 1) on-chip SRAM that is immediately next to the compute units that is incredibly fast but of very of low capacity, and 2) off-chip DRAM which has extremely high capacity, but the contents of which you can only suck through a long straw. On top of this, there are many details of the architecture (e.g. systolic arrays), numerics, etc.
The design of the optimal physical substrate and then the orchestration of memory compute across the top volume workflows of LLMs (inference prefill/decode, training/finetuning, etc.) with the best throughput/latency/$ is probably today's most interesting intellectual puzzle with the highest rewards (\cite 4.6T of NVDA). All of it to get many tokens, fast and cheap. Arguably, the workflow that may matter the most (inference decode *and* over long token contexts in tight agentic loops) is the one hardest to achieve simultaneously by the ~both camps of what exists today (HBM-first NVIDIA adjacent and SRAM-first Cerebras adjacent). Anyway the MatX team is A grade so it's my pleasure to have a small involvement and congratulations on the raise!
Feb 24

We’re building an LLM chip that delivers much higher throughput than any other chip while also achieving the lowest latency. We call it the MatX One.
The MatX One chip is based on a splittable systolic array, which has the energy and area efficiency that large systolic arrays are famous for, while also getting high utilization on smaller matrices with flexible shapes. The chip combines the low latency of SRAM-first designs with the long-context support of HBM. These elements, plus a fresh take on numerics, deliver higher throughput on LLMs than any announced system, while simultaneously matching the latency of SRAM-first designs. Higher throughput and lower latency give you smarter and faster models for your subscription dollar.
We’ve raised a $500M Series B to wrap up development and quickly scale manufacturing, with tapeout in under a year. The round was led by Jane Street, one of the most tech-savvy Wall Street firms, and Situational Awareness LP, whose founder @leopoldasch wrote the definitive memo on AGI. Participants include @sparkcapital, @danielgross and @natfriedman’s fund, @patrickc and @collision, @TriatomicCap, @HarpoonVentures, @karpathy, @dwarkesh_sp, and others. We’re also welcoming investors across the supply chain, including Marvell and Alchip.
@MikeGunter_ and I started MatX because we felt that the best chip for LLMs should be designed from first principles with a deep understanding of what LLMs need and how they will evolve. We are willing to give up on small-model performance, low-volume workloads, and even ease of programming to deliver on such a chip.
We’re now a 100-person team with people who think about everything from learning rate schedules, to Swing Modulo Scheduling, to guard/round/sticky bits, to blind-mated connections—all in the same building. If you’d like to help us architect, design, and deploy many generations of chips in large volume, consider joining us.
318
496
7,382
2,557,964
tensorpro retweeted

Feb 24
Congratulations to Reiner and the MatX team!
Combining the benefits of HBM and SRAM and the benefits of tile-based architectures and systolic arrays has been a clear gap in the accelerator design space for a while, and I’m excited to see how MatX One performs.
Feb 24
We’re building an LLM chip that delivers much higher throughput than any other chip while also achieving the lowest latency. We call it the MatX One.
The MatX One chip is based on a splittable systolic array, which has the energy and area efficiency that large systolic arrays are famous for, while also getting high utilization on smaller matrices with flexible shapes. The chip combines the low latency of SRAM-first designs with the long-context support of HBM. These elements, plus a fresh take on numerics, deliver higher throughput on LLMs than any announced system, while simultaneously matching the latency of SRAM-first designs. Higher throughput and lower latency give you smarter and faster models for your subscription dollar.
We’ve raised a $500M Series B to wrap up development and quickly scale manufacturing, with tapeout in under a year. The round was led by Jane Street, one of the most tech-savvy Wall Street firms, and Situational Awareness LP, whose founder @leopoldasch wrote the definitive memo on AGI. Participants include @sparkcapital, @danielgross and @natfriedman’s fund, @patrickc and @collision, @TriatomicCap, @HarpoonVentures, @karpathy, @dwarkesh_sp, and others. We’re also welcoming investors across the supply chain, including Marvell and Alchip.
@MikeGunter_ and I started MatX because we felt that the best chip for LLMs should be designed from first principles with a deep understanding of what LLMs need and how they will evolve. We are willing to give up on small-model performance, low-volume workloads, and even ease of programming to deliver on such a chip.
We’re now a 100-person team with people who think about everything from learning rate schedules, to Swing Modulo Scheduling, to guard/round/sticky bits, to blind-mated connections—all in the same building. If you’d like to help us architect, design, and deploy many generations of chips in large volume, consider joining us.
1
10
119
17,848
tensorpro retweeted

Feb 24
Reiner taught me much of what I know - goes without saying that I trust him to make the best chip in the world.
Feb 24
We’re building an LLM chip that delivers much higher throughput than any other chip while also achieving the lowest latency. We call it the MatX One.
The MatX One chip is based on a splittable systolic array, which has the energy and area efficiency that large systolic arrays are famous for, while also getting high utilization on smaller matrices with flexible shapes. The chip combines the low latency of SRAM-first designs with the long-context support of HBM. These elements, plus a fresh take on numerics, deliver higher throughput on LLMs than any announced system, while simultaneously matching the latency of SRAM-first designs. Higher throughput and lower latency give you smarter and faster models for your subscription dollar.
We’ve raised a $500M Series B to wrap up development and quickly scale manufacturing, with tapeout in under a year. The round was led by Jane Street, one of the most tech-savvy Wall Street firms, and Situational Awareness LP, whose founder @leopoldasch wrote the definitive memo on AGI. Participants include @sparkcapital, @danielgross and @natfriedman’s fund, @patrickc and @collision, @TriatomicCap, @HarpoonVentures, @karpathy, @dwarkesh_sp, and others. We’re also welcoming investors across the supply chain, including Marvell and Alchip.
@MikeGunter_ and I started MatX because we felt that the best chip for LLMs should be designed from first principles with a deep understanding of what LLMs need and how they will evolve. We are willing to give up on small-model performance, low-volume workloads, and even ease of programming to deliver on such a chip.
We’re now a 100-person team with people who think about everything from learning rate schedules, to Swing Modulo Scheduling, to guard/round/sticky bits, to blind-mated connections—all in the same building. If you’d like to help us architect, design, and deploy many generations of chips in large volume, consider joining us.
12
11
419
53,385
tensorpro retweeted
Feb 24
We’re building an LLM chip that delivers much higher throughput than any other chip while also achieving the lowest latency. We call it the MatX One.
The MatX One chip is based on a splittable systolic array, which has the energy and area efficiency that large systolic arrays are famous for, while also getting high utilization on smaller matrices with flexible shapes. The chip combines the low latency of SRAM-first designs with the long-context support of HBM. These elements, plus a fresh take on numerics, deliver higher throughput on LLMs than any announced system, while simultaneously matching the latency of SRAM-first designs. Higher throughput and lower latency give you smarter and faster models for your subscription dollar.
We’ve raised a $500M Series B to wrap up development and quickly scale manufacturing, with tapeout in under a year. The round was led by Jane Street, one of the most tech-savvy Wall Street firms, and Situational Awareness LP, whose founder @leopoldasch wrote the definitive memo on AGI. Participants include @sparkcapital, @danielgross and @natfriedman’s fund, @patrickc and @collision, @TriatomicCap, @HarpoonVentures, @karpathy, @dwarkesh_sp, and others. We’re also welcoming investors across the supply chain, including Marvell and Alchip.
@MikeGunter_ and I started MatX because we felt that the best chip for LLMs should be designed from first principles with a deep understanding of what LLMs need and how they will evolve. We are willing to give up on small-model performance, low-volume workloads, and even ease of programming to deliver on such a chip.
We’re now a 100-person team with people who think about everything from learning rate schedules, to Swing Modulo Scheduling, to guard/round/sticky bits, to blind-mated connections—all in the same building. If you’d like to help us architect, design, and deploy many generations of chips in large volume, consider joining us.
121
201
2,288
3,038,440
tensorpro retweeted

Feb 24
Banger


An AI chip startup founded by two Google alumni has raised more than $500 million in a new round to compete with Nvidia bloomberg.com/news/articles/…
5
7
246
102,412
tensorpro retweeted

Jan 13
Here's a non-obvious problem with block-scaled quantized Attention: at the edge of your causal mask, later tokens can leak information to earlier ones through the scale factor computation.
I wouldn't expect this leakage to matter very much since it affects scales, not values, but it turns out it does actually cause the loss to decrease a little too quickly! Very cool post by @tensorpro and team.
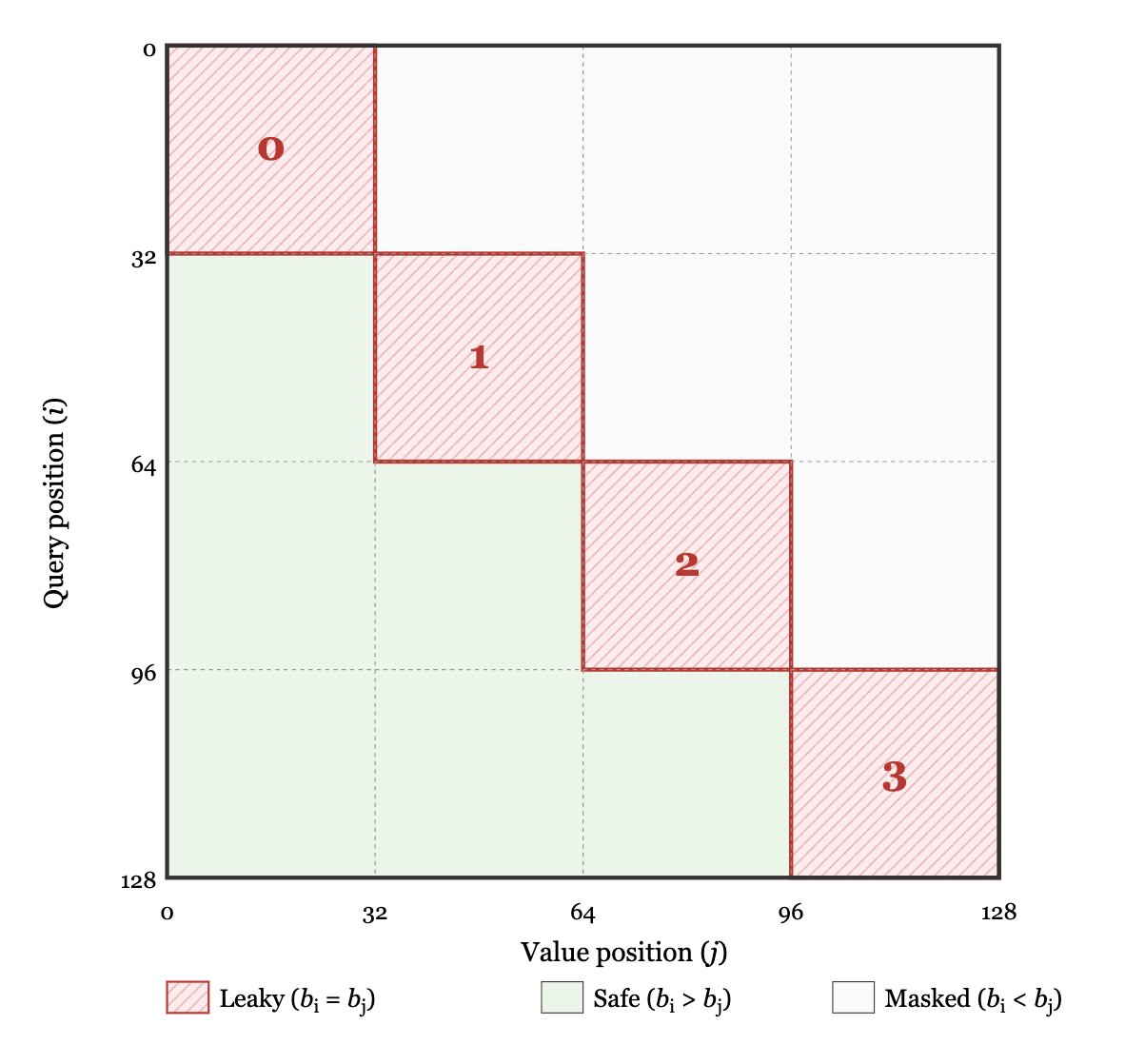

Jan 13

We trained models with MXFP4-quantized attention, but it turns out this can break causal modeling. Our latest post explains why this happens and how to fix it.
matx.com/research/leaky_quan…
3
18
2,580
tensorpro retweeted
27 Jul 2025
Prefill and Decode are very different workloads. We should optimize differently for them! Some ideas and speculation 🧵
4
15
146
30,295
tensorpro retweeted

30 Jul 2025
Speculative decoding (SD) and blockwise sparse attention both accelerate LLM decoding, but when combined naively, the KV cache may lose sparsity during the verification step of SD. A simple modification fixes this while preserving model quality. 1/5
1
2
13
3,880
tensorpro retweeted
30 Jul 2025
Some of our research on an interesting interaction between Native Sparse Attention and Speculative Decoding.
30 Jul 2025

Speculative decoding (SD) and blockwise sparse attention both accelerate LLM decoding, but when combined naively, the KV cache may lose sparsity during the verification step of SD. A simple modification fixes this while preserving model quality. 1/5
1
14
1,851
