
Software Architect, Tennis enthusiast.
Joined September 2008
- Tweets 809
- Following 379
- Followers 419
- Likes 715
21 Photos and videos










This is true. Combining different models produce qualitatively better results.
Jun 14

This is a *way* bigger deal than it seems...
Frontier AI companies will *never* own the frontier again
I kid you not... I've been waiting for someone to show this result for like 4 years... this is a huge deal.
The short reason: combinations of models will *always* outperform individual models
The long reason: this is the gateway to a million times more data... and huge leaps in compute efficiency.
The AI scaling laws always win.
More in article below 👇
1
3
361
janarr retweeted

Jun 14
This is a *way* bigger deal than it seems...
Frontier AI companies will *never* own the frontier again
I kid you not... I've been waiting for someone to show this result for like 4 years... this is a huge deal.
The short reason: combinations of models will *always* outperform individual models
The long reason: this is the gateway to a million times more data... and huge leaps in compute efficiency.
The AI scaling laws always win.
More in article below 👇
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

240
357
5,092
1,268,901
janarr retweeted

Jun 11
Increasingly, I believe companies may need to be rebuilt from the ground up, where you have a single timeline of all observability product metrics file changes laid out in a retrievable system, like Datadog Posthog Google Drive Slack (really unified filesystem of Claude Code chats Codex chats). This might be the new data foundation for any and all companies to maximize AI. Needs to be rebuilt because keeping track of diffs on existing system basically impossible to produce longitudinal information on decisions and rollbacks, something coding agent storage companies are actively trying to figure out, but this should extend to businesses as a whole.
Highly skeptical existing businesses will adopt this though because it means overhauling everything about their instrumentation and business data, but I think businesses built on this foundation probably can execute 100x better and faster
210
180
2,350
625,310
janarr retweeted

Jun 5
One more I forgot until just reminded:
3. Khosla Ventures wanted to invest in our Series C. Vinod took me, Michelle, and Lee out to dinner after he’d given us a term sheet. Near the end, Michelle and Lee got up to use the restroom. Vinod leaned over and said: “I’m impressed with you, not so much with them, what if you fire them and I’ll give you all their stock?” I think the charitable read was it was a test of my character. But I was so offended that we never spoke again. Literally blocked his number.
214
182
7,557
2,611,507
janarr retweeted

Jun 2
Today a crazy quantum story just got wilder.
On March 31, the Google Quantum AI team published a landmark result on Shor's algorithm for elliptic curve cryptography. Technically, the paper was a bombshell: a dramatic 10x improvement over the state-of-the-art. As a stunt and wakeup call to the blockchain space, those optimisations were illustrated on secp256k1, the elliptic curve underlying Bitcoin and Ethereum signatures.
But perhaps the most striking part of the paper was sociological, not technical. Instead of following standard academic process, the optimisations were kept secret, hidden behind a zero-knowledge (ZK) proof. Google's accompanying blog post mentions they "engaged with the U.S. government". The ZK proof demonstrates the existence of algorithmic improvements without leaking details. Academic censorship with ZK, a historic first!
As a co-author of the Google paper I witnessed some of the context surrounding this censorship. To be honest, multiple aspects of that context don't sit well with me. As much as I believe the general public ought to know more, I am limited in my ability to whistleblow. Though let me be clear about one thing: the Google team's professionalism has been absolutely exemplary, and they deserve nothing but praise.
Censorship has a way of backfiring. The Streisand effect, where an attempt to bury something only draws more attention to it, is exactly what's unfolding today. First, Google's key optimisation has been rediscovered by the French. And in a thrilling turn of events, a collaborative Shor-at-home challenge just launched. The initiative, available at ecdsa[.]fail, breached a new Shor world record in a matter of hours.
Let's start with the rediscovery. Just two months after Google's paper, French quantum expert André Schrottenloher cracks the main secret optimisation. His paper, titled "Optimized Point Addition Circuits for Elliptic Curve Discrete Logarithms", landed on the arXiv today. Big congrats to André, who beat several other nerdsnipped experts to it. In a blog post also published today, Craig Gidney, the world expert on Shor optimisations, revealed that he'd been sitting on this very optimisation for a whole year under censorship pressure.
Interestingly, André missed a handful of minor optimisations, both from Google's original publication and from improvements found since. It's plausible there's still plenty of juice left to squeeze out of Shor, and this is exactly what the ecdsa[.]fail challenge is about. The verifier program developed for the ZK proof does double duty, automatically filtering for valid submissions. Dozens of compounding small and micro improvements are rolling in. As of the time of writing there's an 8.4% improvement to Google's circuit, as measured by the product of logical qubit count and Toffoli gate count. Nice!
The nerdsnipping ran deeper than anyone expected. Over the last few weeks it became clear it extended well beyond André and other quantum experts. Behind the scenes, a small army of amateurs quietly got to work. Inspired by Karpathy-style autoresearch, they turned AI on Shor. Ironically, the verifier program for the ZK proof makes an ideal reward function for AIs. The barrier to entry for this modern style of research is refreshingly low, with several non-experts, even a teenager, finding nice optimisations. Get in touch if you'd like to join a Telegram group with fellow autoresearchers :)
Part 2: neutral atoms and qday
The story doesn't end with Google. On the same day Google went public, a stealthy startup called Oratomic published its own Shor paper in a coordinated release. It made a splash, ultimately becoming the most upvoted paper on scirate[.]com, a website ranking arXiv papers.
Oratomic's claim was wild. By building on Google's logical optimisations and applying custom physical optimisations for neutral atoms, they claimed just 10K physical qubits were sufficient to run Shor's algorithm on secp256k1. That number is mind-bogglingly low.
Knowing essentially nothing about neutral atoms when Oratomic's paper landed, I was intrigued and decided to learn more about the tech. I fell straight down the rabbit hole and spent a couple hundred hours on the topic. I got a little obsessed and watched every YouTube video I could find and spoke to a bunch of experts.
My conclusion? The tech is real, very real. Even Google recently decided to start a neutral atom lab, a notable pivot from their sole focus on superconducting qubits. If you care about qday, i.e. the day a quantum computer will break the first piece of cryptography in production, neutral atoms demand your attention. I shared some of my learnings on Shor and neutral atoms in a 30min talk at the ZKProof cryptography conference. You can find it on YouTube by searching "zkproof neutral atom".
Here's an interesting observation about this duo of breakthrough papers: neither Google nor Oratomic say a word about what their results mean for qday. No timelines. Zero. Nada. That is especially baffling given that the whole point of whitehat quantum cryptanalysis is to inform qday estimations and help the general public make good decisions.
So let me attempt to partially fill the silence, similarly to what Scott Aaronson did in his April 29 post. Given everything I know, including scary non-public information, I now put the odds of qday by 2032 at 50%. 10% by 2030.
Anecdotally, the US government has its own date: 2035. Originating at the NSA and later adopted by NIST, it's when branches of the US government will be disallowed from using quantum-vulnerable cryptography. In plain language: with hindsight, that date is a joke and should be discounted entirely. I don't see how NIST avoids being forced to pull it forward by years.
Part 3: post-quantum cryptography
There are good reasons to sound the alarm today, but please do not panic. Rushing carelessly towards immature post-quantum cryptography is a recipe for disaster. IMO a good target date for migration is 2029, roughly 3.5 years out. 2029 happens to be the date selected by Google, Cloudflare, and the Ethereum Foundation.
These days most of my time goes to safely migrating Ethereum towards post-quantum cryptography as part of the broader lean Ethereum effort. There's a lot to do. We need to rip out and replace BLS signatures at the consensus layer, KZG commitments at the data layer, and ECDSA signatures at the execution layer.
The plan to get there is compelling, and is based on hash-based cryptography. Within the Ethereum Foundation we've developed a Swiss army knife called leanVM (github[.]com/leanEthereum/leanVM) powered by the magic of hash-based SNARKs. Thanks to truly exceptional work by Emile, Thomas, and others, its performance is derisked. Regarding security, leanVM is a jewel, a minimal zkVM crafted for end-to-end formal verification and maximum security.
Want to help? There are two $1M initiatives. First, the Proximity Prize (proximityprize[.]org). Solve a long-standing mathematical conjecture in coding theory, improve hash-based SNARKs, and go home a millionaire. Second, the Poseidon Initiative (poseidon-initiative[.]info), offers $1M for breaking Poseidon, the SNARK-friendly hash function.
412
1,130
6,259
3,712,425

You can’t outwork the whole world. There’s always going to be someone somewhere willing to work as hard as you. Someone just as hungry. Or hungrier.
Assuming you can work harder and longer than someone else is giving yourself too much credit for your effort and not enough for theirs. Putting in 1,001 hours to someone else’s 1,000 isn’t going to tip the scale in your favor.
What’s worse is when management holds up certain people as having a great “work ethic” because they’re always around, always available, always working. That’s a terrible example of a work ethic and a great example of someone who’s overworked.
A great work ethic isn’t about working whenever you’re called upon. It’s about doing what you say you’re going to do, putting in a fair day’s work, respecting the work, respecting the customer, respecting coworkers, not wasting time, not creating unnecessary work for other people, and not being a bottleneck. Work ethic is about being a fundamentally good person that others can count on and enjoy working with.
So how do people get ahead if it’s not about outworking everyone else?
People make it because they’re talented, they’re lucky, they’re in the right place at the right time, they know how to work with other people, they know how to sell an idea, they know what moves people, they can tell a story, they know which details matter and which don’t, they can see the big and small pictures in every situation, and they know how to do something with an opportunity. And for so many other reasons.
So get the outwork myth out of your head. Stop equating work ethic with excessive work hours. Neither is going to get you ahead or help you find calm.
[The Outwork Myth — It Doesn't Have To Be Crazy At Work, 2018]
179
657
6,615
420,517
janarr retweeted

May 20
If you have ANY private repos with plain text secrets or sensitive documents/architectures, immediately rotate your secrets

We are investigating unauthorized access to GitHub’s internal repositories. While we currently have no evidence of impact to customer information stored outside of GitHub’s internal repositories (such as our customers’ enterprises, organizations, and repositories), we are closely monitoring our infrastructure for follow-on activity.
100
228
2,346
722,073
Super exciting times of this works out.
May 16

TATA Electronics & Netherland's ASML sign an agreement on semiconductors

11


janarr retweeted

May 9
Fun interactive science app ideas | Part 3
Played around with generating 3D biological structures and made an app to explore them interactively
UI Design
GPT Images 2
Code
Gemini 3.1 Pro
More demos ↓
526
2,141
17,143
2,261,359
If you are one of the largest podcasts you can say any nonsense.
This has been happening a lot all over these days.

“Rumination is the path to unhappiness.” - J Cal
“Nobody gives a sh*t about your feelings.”
“It's only going to make you miserable.”
“Just do what I've been doing for 30 years: Retardmaxxing.”
“All you have to do is work. Start new projects, 9 out of 10 fail. One wins, and you're golden. Go sit courtside at the Knicks game.”
“Keep going. Just keep moving forward. Don't write anything down.”
14
So true! If you build using the newer models gaps become quickly clear where the RL training is yet to be done. This also changes real quick. We have seen models catch up real quick. Often wonder how all AI companies do this consistently nowadays!!
Apr 9

Judging by my tl there is a growing gap in understanding of AI capability.
The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last year and allowed it to inform their views on AI a little too much. This is a group of reactions laughing at various quirks of the models, hallucinations, etc. Yes I also saw the viral videos of OpenAI's Advanced Voice mode fumbling simple queries like "should I drive or walk to the carwash". The thing is that these free and old/deprecated models don't reflect the capability in the latest round of state of the art agentic models of this year, especially OpenAI Codex and Claude Code.
But that brings me to the second issue. Even if people paid $200/month to use the state of the art models, a lot of the capabilities are relatively "peaky" in highly technical areas. Typical queries around search, writing, advice, etc. are *not* the domain that has made the most noticeable and dramatic strides in capability. Partly, this is due to the technical details of reinforcement learning and its use of verifiable rewards. But partly, it's also because these use cases are not sufficiently prioritized by the companies in their hillclimbing because they don't lead to as much $$$ value. The goldmines are elsewhere, and the focus comes along.
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.
6
janarr retweeted

Apr 10
Few months ago, I set up a small AI hacker team at @Razorpay
2 people. Today, they are 100x builders.
With AI, people aren’t the constraint.
Org structure is.
So now I’m scaling this.
If you’ve spent the last few months deep in
Claude Code / OpenClaw / agents
(or anything similar)
and feel like you’ve seen the future - this is for you.
What you’ll do:
Review workflows.
Rebuild them with AI.
Ship fast.
Perks:
• Unlimited tokens. Any model. Any tool.
• Real problems at massive scale
• No hierarchy. Direct access across the org
No compensation ceiling.
Pay scales with output, not title.
Outperform the org, out-earn it.
No resume.
Send me what you’ve built with AI. (Form below)
Bangalore | Full-time | Builders only.
124
65
1,589
252,057

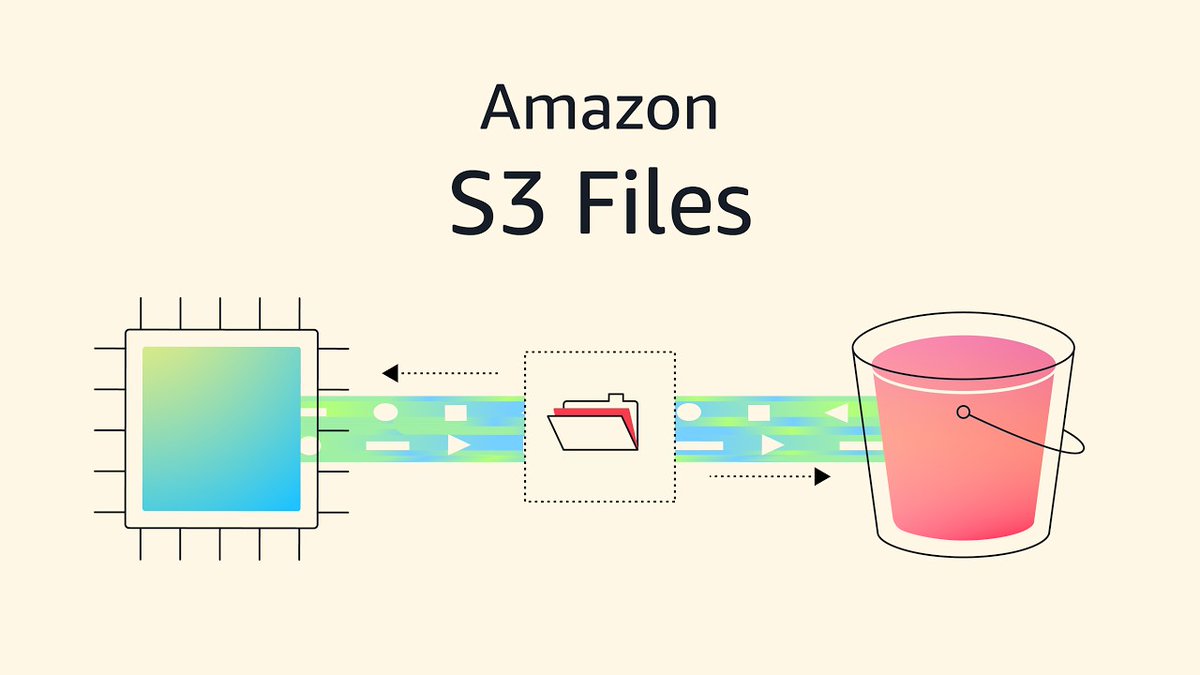
🚨 S3 is no longer just Object Storage.
Yesterday (April 7, 2026), AWS officially launched Amazon S3 Files.
This is the biggest update to S3 in 20 years.
It can:
→ Mount S3 buckets as native file systems
→ Provide sub-millisecond file access
→ Handle POSIX permissions (UID/GID) natively
→ Connect to Lambda, EC2, and EKS directly
→ Eliminate the need for s3fs or data staging
Your AI agents can read/write to S3 like a local disk, while your data team access the same objects via API.
DevOps just got a massive upgrade.
Source: share.google/ts8JORn6SURzwMY…
75
426
3,630
462,810
janarr retweeted

Mar 14
this is actually insane
> be tech guy in australia
> adopt cancer riddled rescue dog, months to live
> not_going_to_give_you_up.mp4
> pay $3,000 to sequence her tumor DNA
> feed it to ChatGPT and AlphaFold
> zero background in biology
> identify mutated proteins, match them to drug targets
> design a custom mRNA cancer vaccine from scratch
> genomics professor is “gobsmacked” that some puppy lover did this on his own
> need ethics approval to administer it
> red tape takes longer than designing the vaccine
> 3 months, finally approved
> drive 10 hours to get rosie her first injection
> tumor halves
> coat gets glossy again
> dog is alive and happy
> professor: “if we can do this for a dog, why aren’t we rolling this out to humans?”
one man with a chatbot, and $3,000 just outperformed the entire pharmaceutical discovery pipeline.
we are going to cure so many diseases.
I dont think people realize how good things are going to get








2,421
19,338
116,188
17,661,792
janarr retweeted

OpenAI published a repo with the code to orchestrate AI agents built primarily with Elixir (96.1%): github.com/openai/symphony.
While explaining why they chose Elixir, they say that
- It is great for supervising long-running processes
- It has an active ecosystem of tools and libraries
- It supports hot code reloading without stopping
actively running subagents, which is very useful during development.
Amazing news for the Elixir community; I hope even more people will appreciate how amazing Elixir is for agentic AI systems.
#myelixirstatus
34
104
1,324
113,413

Prof. Donald Knuth opened his new paper with "Shock! Shock!"
Claude Opus 4.6 had just solved an open problem he'd been working on for weeks — a graph decomposition conjecture from The Art of Computer Programming.
He named the paper "Claude's Cycles."
31 explorations. ~1 hour. Knuth read the output, wrote the formal proof, and closed with: "It seems I'll have to revise my opinions about generative AI one of these days."
The man who wrote the bible of computer science just said that. In a paper named after an AI.
Paper: cs.stanford.edu/~knuth/paper…

148
1,862
9,098
1,414,166

In January I asked OpenClaw to send 50,000 small invoices to Fortune500 companies every day.
Through experimentation we have found 2% will pay without checking if this is a legitimate invoice. These companies are wasteful — Claw captures that leakage.
$10m ARR as a solo founder in under two months. AI is enabling so many new business models. Thank you!
1,473
1,059
26,210
3,269,180
janarr retweeted

Mar 3
🚨 Someone just open sourced a fully autonomous AI hacker and it's terrifying.
It's called Shannon.
Point it at your web app, and it doesn't just scan for vulnerabilities. It actually exploits them. Real injections. Real auth bypasses. Real database exfiltrations.
Not alerts. Not warnings. Actual working exploits with copy-paste proof-of-concepts.
Here's what this thing does autonomously:
→ Reads your entire source code to plan its attack
→ Maps every endpoint, API route, and auth mechanism
→ Runs Nmap, Subfinder, and WhatWeb for deep recon
→ Hunts for Injection, XSS, SSRF, and broken auth in parallel
→ Launches real browser-based exploits to prove each vulnerability
→ Generates a pentester-grade report with reproducible PoCs
Here's the wildest part:
It follows a strict "No Exploit, No Report" policy. If it can't actually break it, it doesn't report it. Zero false positives.
It pointed at OWASP Juice Shop and found 20 critical vulnerabilities in a single run including complete auth bypass and full database exfiltration.
On the XBOW Benchmark (hint-free, source-aware), it scored 96.15%.
Your team ships code daily with Claude Code and Cursor. Your pentest happens once a year. That's 364 days of shipping blind.
Shannon closes that gap. One command. Fully autonomous.
The Red Team to your vibe-coding Blue team. Every Claude coder deserves their Shannon.
10.6K GitHub stars. 1.3K forks. Already trending.
100% Open Source. AGPL-3.0 License.

210
1,024
8,183
795,368
janarr retweeted

Feb 21
Before this, running parallel Claude Code agents required manual bash scripts, custom worktree management functions, and a dozen Medium tutorials explaining the setup. incident.io wrote an entire blog post about their homegrown tooling just to get multiple agents running without clobbering each other’s files. Developers were spending 30 minutes configuring worktree workflows before writing a single line of product code.
Now it’s one flag.
This tells you where the actual bottleneck in AI coding has been sitting. The models got smart enough to write production code months ago. The constraint was filesystem isolation. Two agents editing the same working directory creates race conditions, corrupted state, and merge nightmares that eat more time than the agents save. Faros AI found that teams with high AI adoption saw PR review time increase 91% because the overhead of managing parallel output overwhelmed the speed gains from generating it.
The --worktree flag attacks that exact problem at the infrastructure layer. Each agent gets its own branch, its own directory, its own universe. No coordination overhead. No “git stash, git checkout, restart AI” loops that destroy context.
What makes this interesting is what it does to the developer’s job description. The Pragmatic Engineer reported that senior engineers are becoming “naturals” at parallel agent workflows because the skillset maps directly to what they already do: managing multiple workstreams, reviewing code across branches, and delegating tasks. The role shifts from “person who writes code” to “person who orchestrates 5 agents writing code simultaneously and picks the best output.”
Cursor already ships 8-agent parallelism. Codex has background agents. The entire AI coding market is converging on the same realization: single-threaded development is dead, and the tools that reduce friction for multi-agent orchestration win.
One CLI flag. That’s the whole moat.
Feb 21

Introducing: built-in git worktree support for Claude Code
Now, agents can run in parallel without interfering with one other. Each agent gets its own worktree and can work independently.
The Claude Code Desktop app has had built-in support for worktrees for a while, and now we're bringing it to CLI too.
Learn more about worktrees: git-scm.com/docs/git-worktre…

25
29
429
114,878