
Joined April 2008
- Tweets 1,615
- Following 54
- Followers 440
- Likes 2,797
32 Photos and videos












Jun 11
Anthropic will silently sabotage you, the paying customer, if they think you are using Fable for "frontier LLM development".
Are you confident they'll do a better job at classifying that than they do on standard topics where mistakes are easily visible?
2
51
Jun 5
Perplexity taking this to its logical conclusion and then some, but the core idea here is important and not yet widely understood: Agents are able to tailor queries in detail to what they are trying to do.
This is makes a huge difference in cost and quality. For example:
- When researching case law, search for the names of those involved near each other in text.
- When seeking an overview of a broader topic, do a pure vector search prioritizing authoritative sources.
- When making timeline of some historic development, limit by year range and group by month.
And so on. Models already know YQL, all you need is to tell them what they have to work with.

We’re moving away from search as a web fetch tool call to search as codegen to be future proof in a world where code execution inside agent harnesses is the way to do almost all of our knowledge work.
Doing this lets you compose multi-step primitives far more naturally and be much more adaptable to changes made to the agent harness, as well as benefit from improvements in coding capabilities that are guaranteed to come from the next generation of frontier models.
3
2
9
717
Jun 3
This will be a good one

I’m excited to join the speaker lineup at Vespa.ai Live! My session will explore Nuances of Binarized Embeddings-Based Retrieval
If you’re attending, let me know — would love to connect at the event.

3
67
May 29
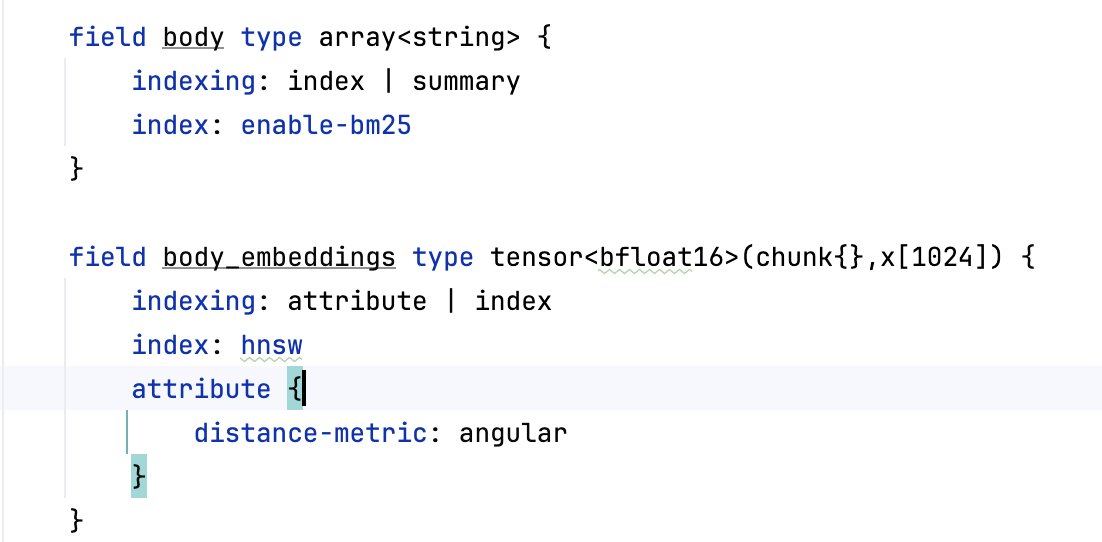
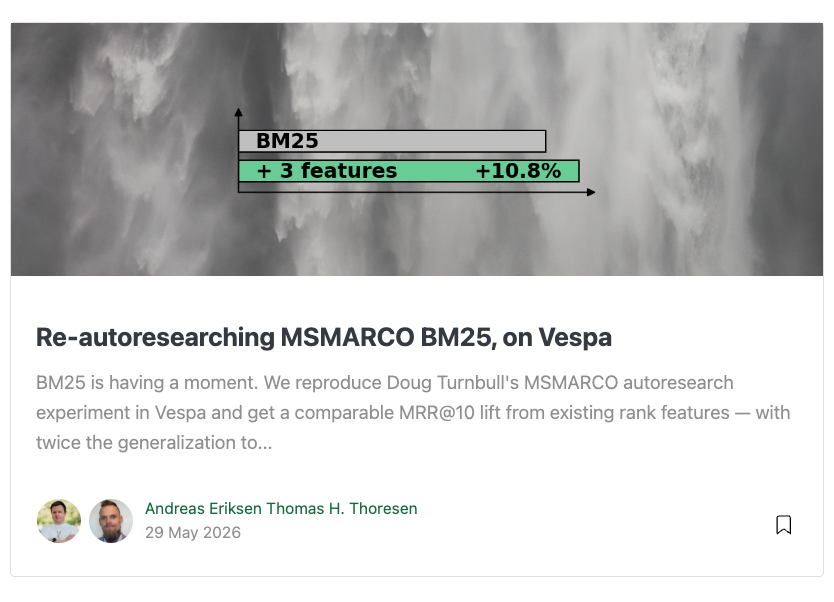
Even with a linear function and no additional metadata it is easy to improve on bm25. Of course with e.g. GBDT models you can go much further ...
May 29

bm25 is nice and all, but you won't believe how easy it is to improve upon it with and how much more you can squeeze from lexical features in @vespaengine
1
5
160
May 29
Added some explanations of some of these in the thread. Might be useful.
May 28

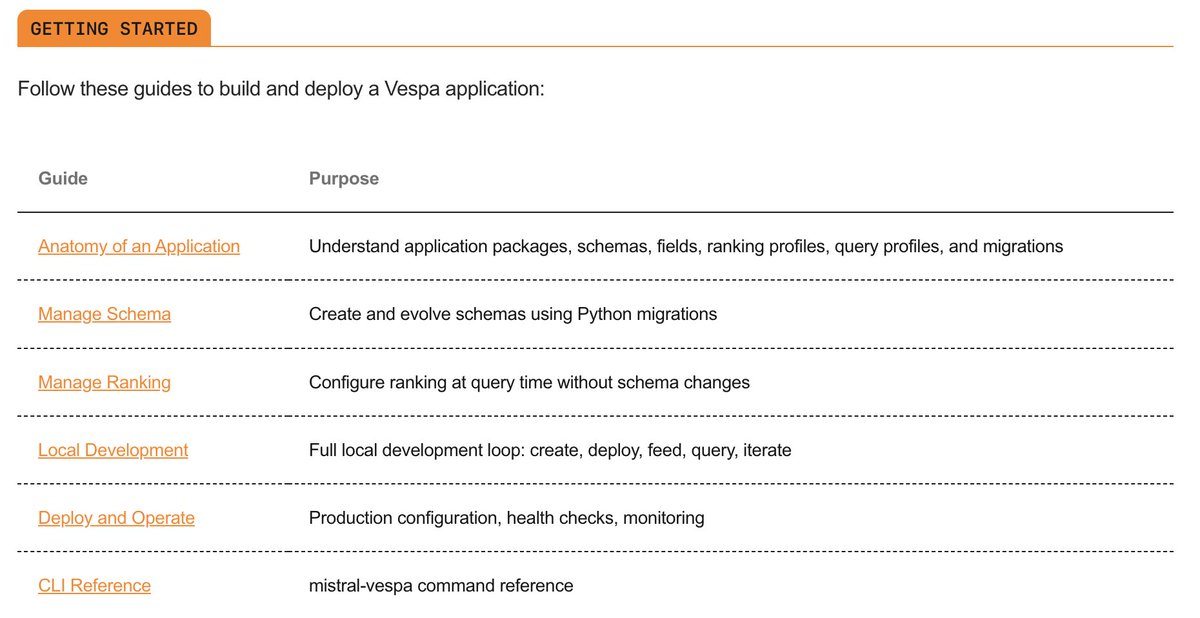
The May Vespa.ai Newsletter is out!
This month we’re announcing updates focused on retrieval quality, ranking flexibility, and developer productivity (agents: try out the skills and let us know).
- Vespa Cloud: Detailed metric dashboards
- Vespa Cloud: Index backup
- Vespa Cloud: Fine-grained maintenance controls
- Vespa Cloud: Custom resource tags
- Vespa skills for agents
- @VoyageAI , @OpenAI , and @MistralAI embedders
- A new query operator for text matching
- Cluster-size independent config of relevance effort
- Boolean array fields
- Match specific array elements
- In-memory document ids
- Search group pinning
- Near matching aware ranking
- Detect ignored write operations
- Accessing the max first phase score in re-ranking
- Geo distance in grouping
Read it here: blog.vespa.ai/vespa-newslett…
3
94
Jon Bratseth retweeted

May 29
Vespa isn't only powering American AI, now it's also @MistralAI's retrieval solution
1
2
6
491
Jon Bratseth retweeted

May 6
Just added a sample app for how to search with hypencoder models on Vespa. A large meta-model that generates a small query-specific model that scores your docs - it feels like pure science fiction, but of course we can do it: github.com/vespa-engine/samp…
3
2
9
1,693
Apr 26
We're still on the good timeline
Apr 24

🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: huggingface.co/deepseek-ai/D…
🤗 Open Weights: huggingface.co/collections/d…
1/n

1
96
Jon Bratseth retweeted

Apr 23
Vespa.ai Live tickets are now available:
- early 🐦 at £99
- online at £20
- in-person training at £349 (includes conference access)
📢 Call for Papers ends on April 30 📢
Thanks to @FlaxSearch for organizing 🙌
1
2
7
408
Jon Bratseth retweeted
Apr 7
It’s happening. Vespa.ai is going live, in person.
For the first time ever, we’re bringing the Vespa community together for a dedicated, in-person conference: Vespa.ai Live in London 🇬🇧
If you’ve been building with Vespa, exploring real-time AI, or pushing the limits of search and retrieval, this is the event you don’t want to miss.
This isn’t just another conference. It’s the people behind real-world systems, sharing what actually works at scale.
💥 What makes this special:
• The first-ever Vespa in-person event
• Deep dives into real-time, production-grade AI systems
• Talks from practitioners solving hard problems in search, personalization, and RAG
• A chance to meet the community face-to-face
🎤 And yes, we want to hear from you.
This is your chance to get on stage, share your work, and be part of shaping the Vespa ecosystem.
📍 London: Lumiere London Underwood Flagship Venue
📅 September 10, 2026
Details / submit your talk 👇
1
3
7
283
Jon Bratseth retweeted

Mar 15
The story about bureaucracy almost stopping a man from treating his dog’s cancer with an mRNA vaccine went viral.
The problem transfers to humans: we’ve made these clinical trials unnecessarily hard, denying hope to patients.
New article on this.
writingruxandrabio.com/p/the…
Excerpts:
"A story about Paul Conyngham, an AI entrepreneur from Sydney who treated his dog Rosie’s cancer with a personalized mRNA vaccine, has been circulating on X since yesterday. What makes the story inspiring is the initiative the owner showed: he used AI to teach himself about how a personalized vaccine could work, designed much of the process himself and approached top researchers to take it forward. Whether the treatment itself was fully curative and how much of an improvement it is over state-of-the art is not the main focus of this essay. Others have already debated that question at length, and I recommend following their discussions.
What interests me instead is the bureaucratic absurdity the dog’s owner encountered while trying to pursue the treatment. He described the long and frustrating process required simply to test the drug in his dog: “The red tape was actually harder than the vaccine creation, and I was trying to get an Australian ethics approval and run a dog trial on Rosie. It took me three months, putting two hours aside every single night, just typing the 100 page document.” Even in a small and urgent case, where the owner was fully willing to fund the treatment himself, the effort was slowed by layers of procedure.
Of course, this kind of red tape is not confined to Australia, nor to veterinary medicine. In fact, in the US, the red tape is even worse, at least for in-human trials. In a previous post, I recommended the Australian model for early stage
In the United States, GitLab co-founder Sid Sijbrandij found himself in a similar position after the relapse of his osteosarcoma. When the ordinary doors of medicine closed, he entered what he called “founder mode on his cancer.” Like many entrepreneurs confronted with a difficult problem, he began trying to build his own path forward by self-funding his exploration of experimental therapies.
Even then, he ran into the same maze of regulatory and institutional barriers that not only delayed him, but also unnecessarily raised the price of his experimental therapies. These are obstacles that only someone with extraordinary resources could hope to navigate, often by assembling an entire team to deal with them and navigate the opacity. In the end, Sijbrandij prevailed: he has been relapse free since 2025, after doctors had told me he was at the end of his options.
Around the same time, writer Jake Seliger faced a similar situation while battling advanced throat cancer. Like Sid Sijbrandij, he was willing to try anything that might help. The difference was that Seliger was not a billionaire. He could not hire a team to navigate the system on his behalf, and he struggled even to enroll in the clinical trials that might have offered him a chance.
A system originally conceived to safeguard patients has gradually produced a strange and troubling outcome: the mere chance of survival is effectively reserved for the very few who possess the means to assemble an army of experts capable of navigating its labyrinthine procedures.
What makes these stories particularly frustrating is that we already know clinical trials — especially small, early-stage ones like the ones Sijbrandij enrolled in for himself— can be conducted far more cheaply and with far less bureaucracy than is currently required. Ironically, the original article cites Australia as a bad example, yet clinical trials there are conducted 2.5–3× cheaper and faster than in the U.S., at least for human trials, without any increase in safety events—a genuine free lunch.
Removing unnecessary barriers has long been important. That is why I co-founded the Clinical Trial Abundance initiative in 2024, a policy effort aimed at increasing both the number and efficiency of in-human drug trials and have consistently argued about the importance of making this crucial but often neglected part of the drug discovery process more efficient.
Since then, the issue has only become more urgent with the rise of AI. One of the central promises of the AI revolution is that it will accelerate medical progress. Organizations such as the OpenAI Foundation list curing disease as a core goal, and researchers like Dario Amodei of Anthropic have argued that AI could dramatically speed up biomedical innovation. But, as I have written before in response to an interview between Dario and Dwarkesh Patel, AI will not automatically accelerate a key bottleneck in making these dreams a reality: clinical trials. Conyngham’s observation that navigating the red tape to start a trial for his dog took longer than designing the drug itself only underscores the point.
Clinical trials themselves vary widely. At one end are small, bespoke trials involving one or a few patients testing highly experimental therapies—like the treatment in the Australian dog story or the experimental therapy Sijbrandij pursued. At the other end are large-scale trials involving thousands of participants, designed to confirm earlier findings and support regulatory approval.
Different types of trials require different reforms. In this essay, I will focus on the former: small, exploratory trials, which will be called early-stage small n trials for the purpose of this essay. These are often the fastest way to test promising ideas in humans and learn from them. They represent our best chance at a meaningful “right-to-try,” form the top of the funnel that generates proof-of-concept evidence, and may be the only viable path for personalized medicine and treatments for ultra-rare diseases. Understanding why these trials have been made unnecessarily difficult—and how we might change that—is essential if medical innovation is to keep pace with our growing ability to design new therapies.
When the story first circulated on X, many people interpreted it as evidence that a cure already exists but simply hasn’t been used due to bureaucracy. That isn’t quite true, as I explained.
The type of mRNA vaccine that the owner pursued looks promising, but he did not know a priori whether it worked or not, as it had not been tested before. So it was not a cure, but “a chance at a cure”. I hesitate to call it an “experimental treatment”, since this term evokes fears of potential safety issues while we generally can predict safety quite well now. The inaccuracy of whether this was a cure or not, however, does not make the story of the bureaucratic red tape that Conyngham encountered any less infuriating. More and more promising treatments are accumulating in the pipeline, fueled by an explosion of new therapeutic modalities, ranging from mRNA to better peptides and more recently, by AI. Yet we are not taking full advantage of them.
To better understand these points, it is helpful to briefly outline the clinical development process—the sequence of in-human trials through which a promising scientific idea is gradually translated into a therapy.
Drug development is often described as a funnel: many ideas enter at the top, but only a few become approved treatments. Early human studies, known as Phase I trials, sit at the entrance of this process. They involve small numbers of patients and are designed to quickly test whether a new therapy is safe and shows early signs of effectiveness.
If the results look promising, the therapy moves to larger and more complex studies, including Phase III trials that enroll large numbers of patients to confirm whether the treatment truly works. Most people gain access to new therapies only after these large randomized trials are completed.
On average, moving from a promising idea to Phase III results takes seven to ten years and costs roughly $1.2 billion. Accelerated approval pathways in areas such as cancer or rare diseases can shorten this timeline by relying on surrogate endpoints, but the process remains slow. As a result, many discoveries that make headlines today will take close to a decade before they become treatments that patients can widely access.
Part of this delay is unavoidable. Observing how a drug affects the human body simply takes time. But much of it is not. Layers of unnecessary bureaucracy, regulatory opacity, and rising trial costs add years to the process without clearly improving patient safety, which is why I started Clinical Trial Abundance.
Allowing a higher volume of small-n early stage trials, the focus of this essay, is a rare “win-win” for both public health and scientific progress. For patients, it transforms a terminal diagnosis from a closed door into a “chance at a cure,” providing legal, supervised access to cutting-edge medicine that currently sits idle in labs. For researchers and society, it unclogs the drug discovery funnel; by lowering the barrier to entry for new ideas, we ensure that the next generation of mRNA, peptide and AI-driven therapies are tested in humans years sooner, ultimately accelerating the arrival of universal cures for everyone.
Next, I will explain why making it easier to run these early stage trials matters.
First, from a patient perspective, they often provide the closest practical equivalent to a right-to-try. In theory, right-to-try laws allow patients with serious illnesses to access treatments that have not yet been confirmed in large randomized Phase III trials. In practice, these pathways rarely function as intended. Pharmaceutical companies are often reluctant to provide experimental drugs outside formal trials, and treatments typically must have already passed Phase I testing. As a result, very few patients gain access through these mechanisms. Early-stage trials offer a more workable alternative. They allow experimental therapies to be tested in structured clinical environments—often in academic settings or academia–industry collaborations—where patients can be monitored and meaningful data can be collected.
Second, early-stage small-n trials are essential for personalized medicine and the treatment of ultra-rare diseases. Many emerging therapies—such as personalized cancer vaccines, gene therapies, and other individualized interventions—do not fit easily into the traditional model of large randomized trials involving thousands of participants. By their nature, these treatments target very small patient populations and often require flexible, adaptive clinical designs.
From a societal perspective, these trials play a crucial learning role. As I argued in my earlier essay Clinic-in-the-Loop, early-stage trials are not simply regulatory checkpoints on the path to approval. They are part of the discovery process itself, creating a feedback loop between laboratory hypotheses and human biology. Later-stage studies, particularly Phase III trials, are designed mainly for validation: they test whether a treatment works under defined conditions and produce the evidence needed for approval.
Early-stage trials, by contrast, are oriented toward learning. Conducted with small patient groups and often using exploratory designs, they allow researchers to observe how a therapy behaves in the human body and how the disease responds. In this way, they close the gap between theory and real-world biology. In the Clinic-in-the-Loop essay, I explain how these trials were crucial to the discovery of Kymriah, the first curative cell therapy for blood cancer."
21
92
439
119,921
Jon Bratseth retweeted

Jan 24
vespatune: train tabular models without writing a single line of code!!!
1
3
13
1,671
Jon Bratseth retweeted

Jan 22
Join me and Trey Grainger for a Lightning Lesson about how to use Quepid with Vespa for offline search relevance testing - next Friday 30th maven.com/p/771bd9/offline-s…

3
5
375
Jon Bratseth retweeted
Jan 17
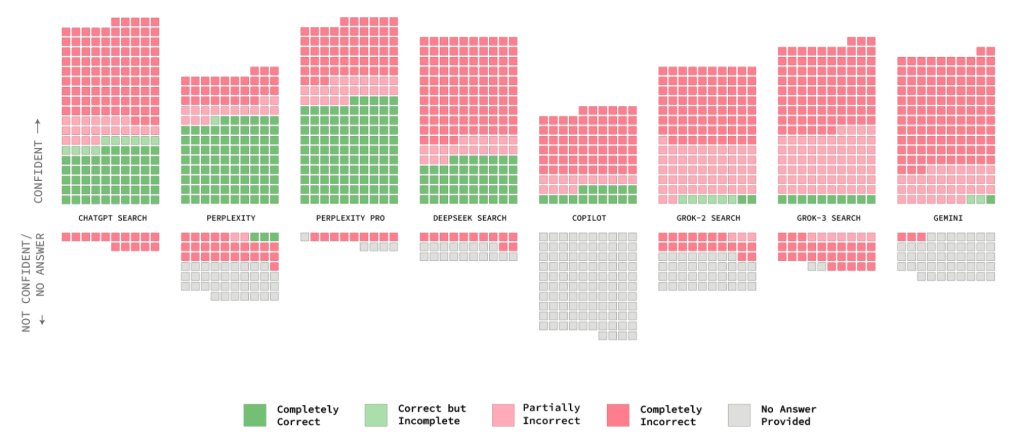
Choosing embeddings isn’t just about accuracy. It’s about speed, cost, and scale.
This post breaks it down with real benchmarks, not hype.
Key takeaways:
⚖️ Higher accuracy often means higher cost and latency
💾 Smaller / quantized embeddings can save a lot of memory
🚀 Binary and INT8 embeddings can be much faster — with tradeoffs
🔍 Hybrid search can outperform embeddings alone
🧪 Results are based on real hardware tests, not theory
If you’re building vector search or RAG, this helps you make smarter choices.

1
4
23
5,858
Jan 9
Epiplexity: A very clean formulation of the intuitively obvious but information theory incompatible notion that info compression (aka modeling) creates new info, and practical since it works with noisy/partially incompressible info sources. A paper for the ages.
Jan 7

6/🧵 We define epiplexity S and time-bounded entropy H to capture this divide. Given a model that optimally compresses the data within compute constraints, epiplexity is the info in its weights, while time-bounded entropy is the leftover info in the data given the model (the NLL)

116
Jon Bratseth retweeted
23 Dec 2025
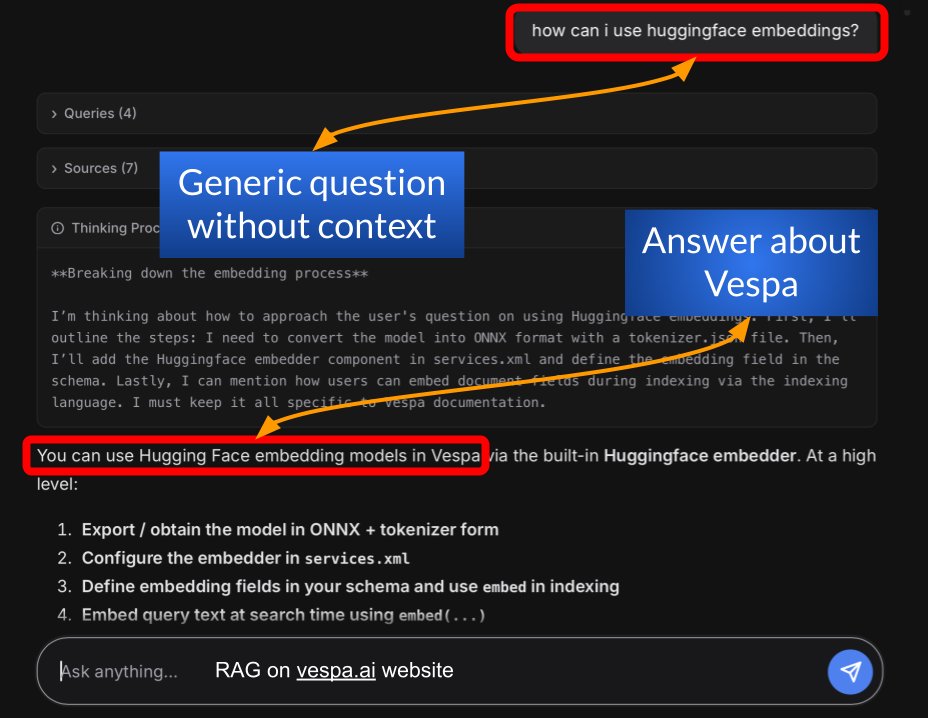
Excited to announce a new open-source library to build advanced RAG system in minutes: without writing a single line of code. deja vu 😁
Introducing NyRAG (pronounced knee-RAG): an open-source tool that makes creating production-ready RAG applications incredibly simple.
✅ Crawl websites OR process docs (PDF, DOCX, MD)
✅ Hybrid search with Vespa
✅ Multi-query RAG with LLM enhancement
✅ Built-in Chat UI
✅ Fully local or Vespa Cloud
pip install nyrag
13
21
90
18,508
1 Dec 2025
If you're fluent in tensor math you can solve a lot of problems.
1 Dec 2025
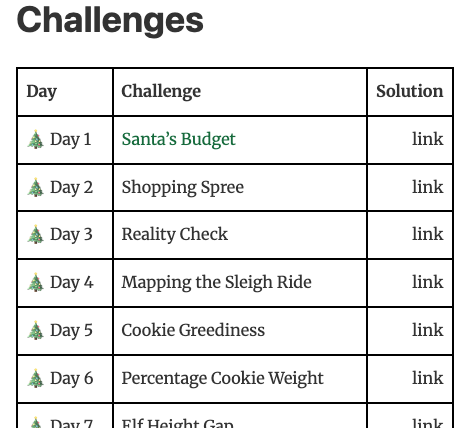
Du you understand tensors?
🎄The advent of tensors starts today:
- A new fun puzzle every day.
- Solutions are posted the next day.
- There will be prizes!
Link 👇
1
1
79
Jon Bratseth retweeted
25 Nov 2025
1.2 million samples. BM25, Embeddings and Hybrid search. Tutorial and code comes tomorrow! Stay tuned!
6
10
154
12,408
25 Nov 2025
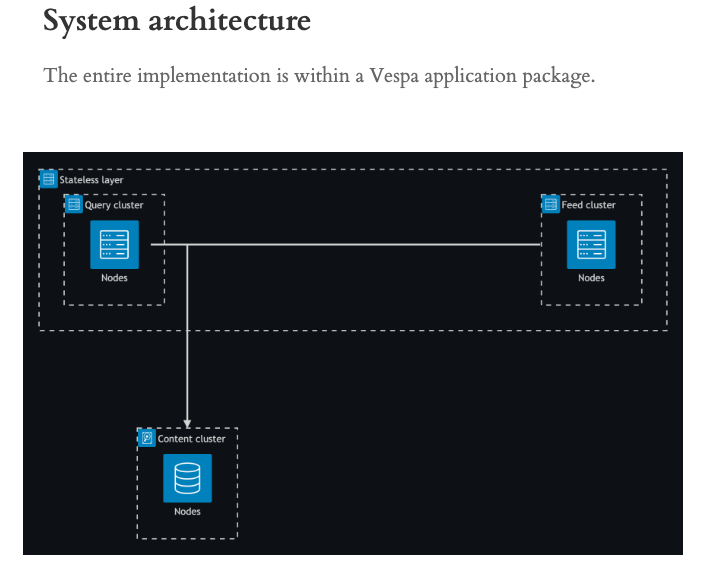
One of the goals we had when designing Vespa was to replace those complex serving architectures documented in byzantine diagrams by a coherent entity which could be deployed, managed, optimized and scaled as one.
This is necessary to get performance at scale but has the nice side effect of relieving engineering teams from spending their days on plumbing and operations.
It's gratifying to see examples of this in the wild
1
4
82