
PhD student at @SeoulNatlUni #WorldModel #PhysicalAI #RepresentationLearning #Robotics
Joined November 2023
- Tweets 16
- Following 382
- Followers 38
- Likes 353
2 Photos and videos

1/n
Come find us at #CVPR2026!
Poster #630
Jun 5 (Fri), 10:45-12:45
ExHall A-F
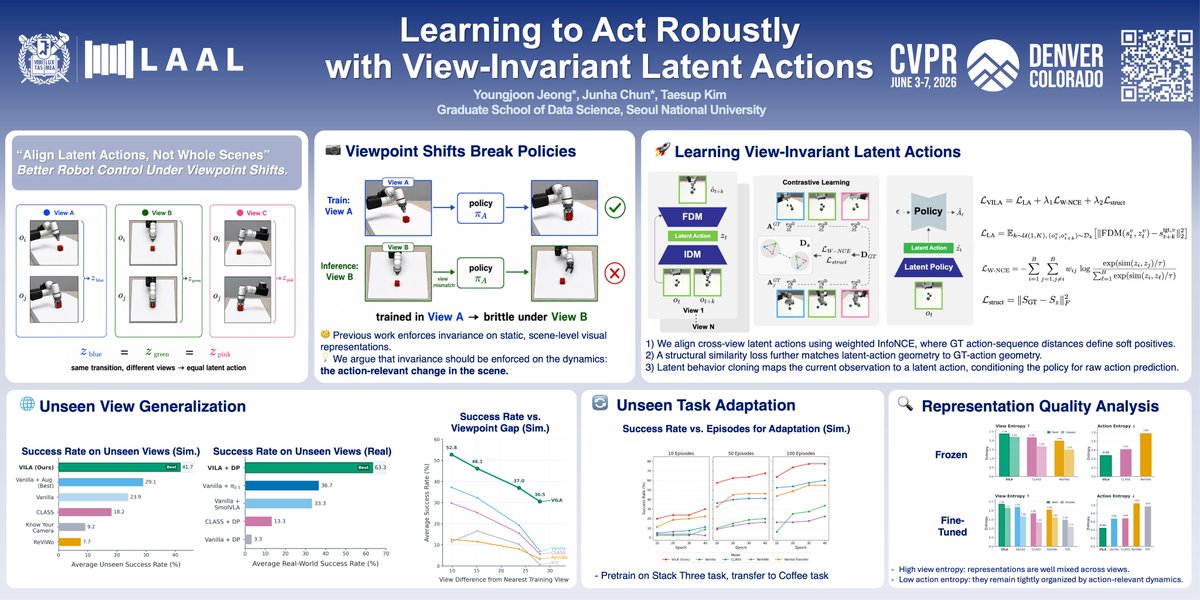
I’m excited to present our paper, Learning to Act Robustly with View-Invariant Latent Actions (VILA).
Paper: arxiv.org/abs/2601.02994
Project: joon-stack.github.io/VILA/
Code: github.com/joon-stack/vila-c…
1
2
118
3/n
VILA learns compact, view-invariant latent actions that capture state transitions, instead of a whole scene representation.
By focusing on action-relevant dynamics, VILA avoids spending encoder capacity on modeling the entire scene, leading to more robust policy learning.
1
82
4/n
Happy to connect with anyone interested in representation learning, world models for robotics!
#CVPR2026 #RobotLearning #Robotics #RepresentationLearning #WorldModels #LatentActions #EmbodiedAI
53
Youngjoon Jeong retweeted

May 21
We built a bipedal robot for about $2,500.
A real, mostly 3D-printed robot you can build, repair, simulate, train, and control.
Today we’re releasing LeRobot Humanoid: an open robot-learning platform with hardware, runtime, identification tools, and training environments.
Blog post: huggingface.co/blog/VirgileB…
Repo: github.com/Virgileboat/lerob…
32
180
1,036
197,434
Youngjoon Jeong retweeted

Apr 27
World Models workshop today! 💥
Coming to the second floor Room: 202A/B!
Speakers: @SchmidhuberAI Juergen Schmidhuber, Sarah Parisot, @svlevine Sergey Levine, @mido_assran Mido Assran, @michaelrabbat Michael Rabbat,@jiajunwu_cs Jiajun Wu, @sirbayes Kevin Murphy,@fredsala Frederic Sala, @shaneguML @shanegJP Shane Gu, @haosu_twitr Hao Su。


1
4
50
10,857
Youngjoon Jeong retweeted

Apr 8
Liner is partnering with @spoticlr at #ICLR2026 — supporting Best Paper and Travel Awards for LLM research.
And to celebrate, we're giving away:
✈️ Round-trip flights hotel to #ICML2026 in Seoul
🎁 $300 Liner Credits
Follow @search_liner repost to enter by 4/27.
Liner is built for research workflows. Find papers, verify sources, and write with citations in one place.
See you in 🇧🇷 and 🇰🇷!
@iclr_conf @icmlconf

5
238
228
14,151

Apr 21
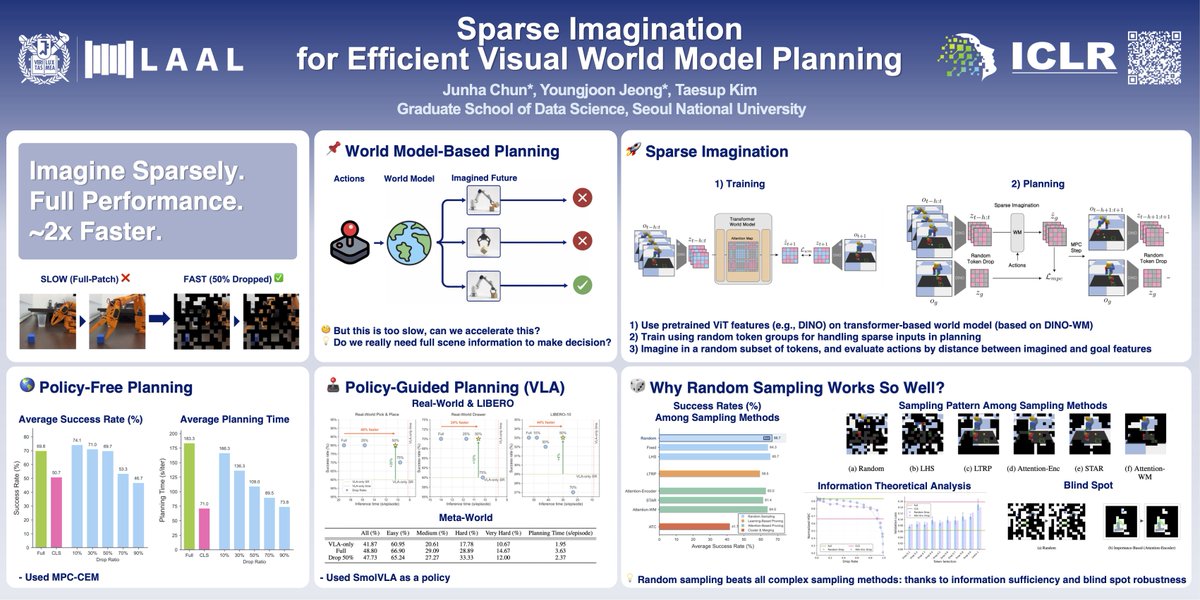
🇧🇷 Excited to present Sparse Imagination at #ICLR2026 in Rio this week!
If you're into World Models, Robotics or Representation Learning, come say hi or DM me! ☕ Always happy to chat.
📍 Pavilion 3, P3-1203
🗓️ Fri, Apr 24, 3:15–5:45 PM-03
6
131
📌 [CVPR 2026] VILA
We enforce viewpoint invariance in the latent action space. By focusing on dynamics, our representation generalizes better to unseen views. 🤖
📄Paper: arxiv.org/abs/2601.02994 (CVPR version coming soon)
🌐Project Page: joon-stack.github.io/VILA/
1
2
271
🙏 Deepest thanks to Prof. Taesup Kim and my co-first author Junha Chun for the amazing collaboration.
Huge thanks to the @LeRobotHF team! Your library significantly enabled and accelerated these works.
See you in Rio and Denver! Feel free to reach out if you'd like to chat.
2
100