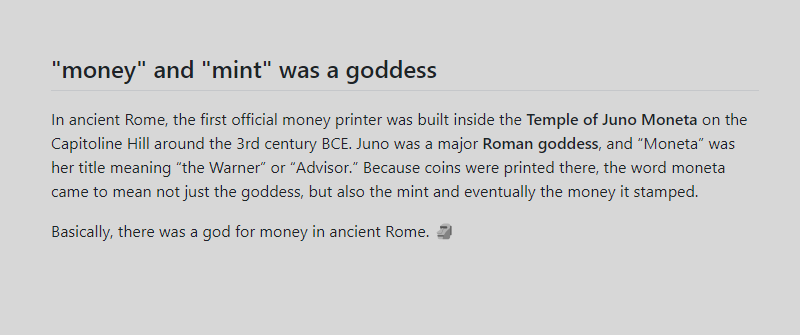
Linux, JavaScript, and Codex!
Joined December 2015
- Tweets 4,315
- Following 62
- Followers 137
- Likes 61,555
299 Photos and videos

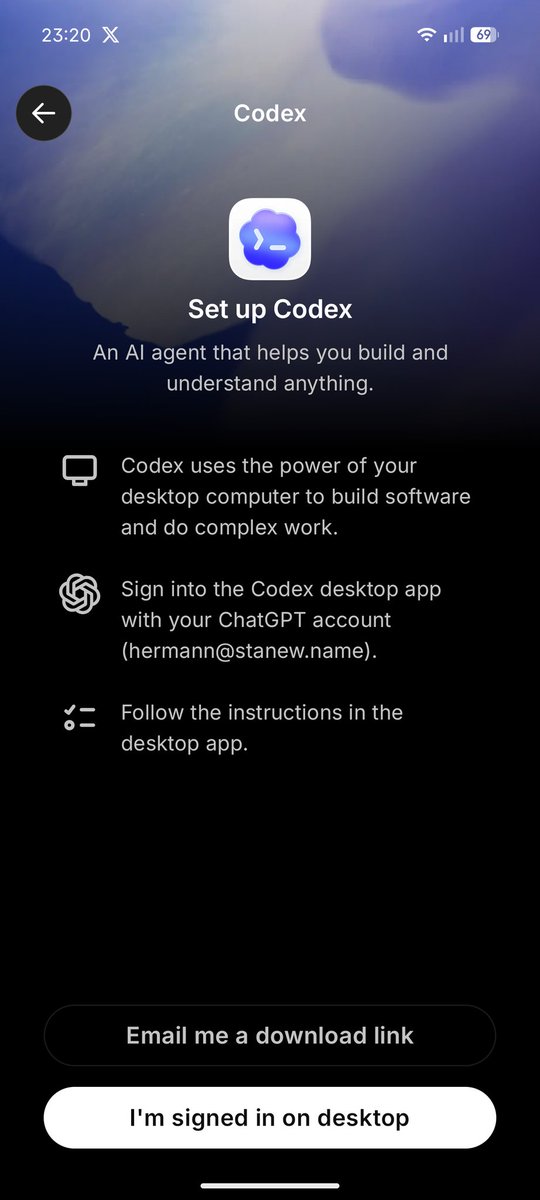
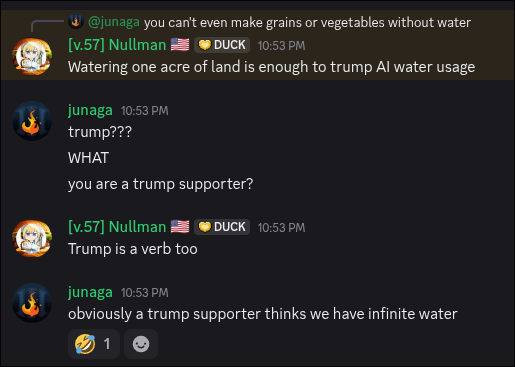

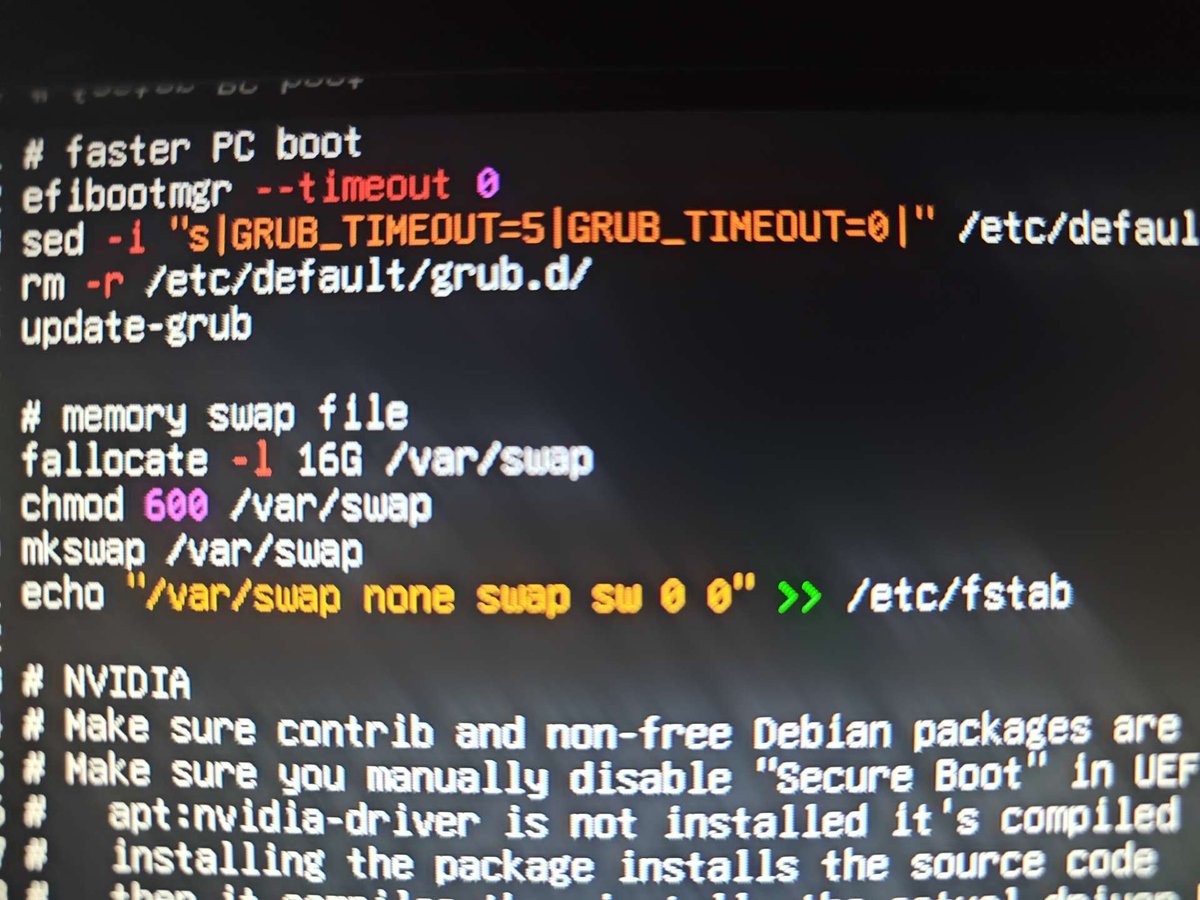







junaga retweeted

Jun 8
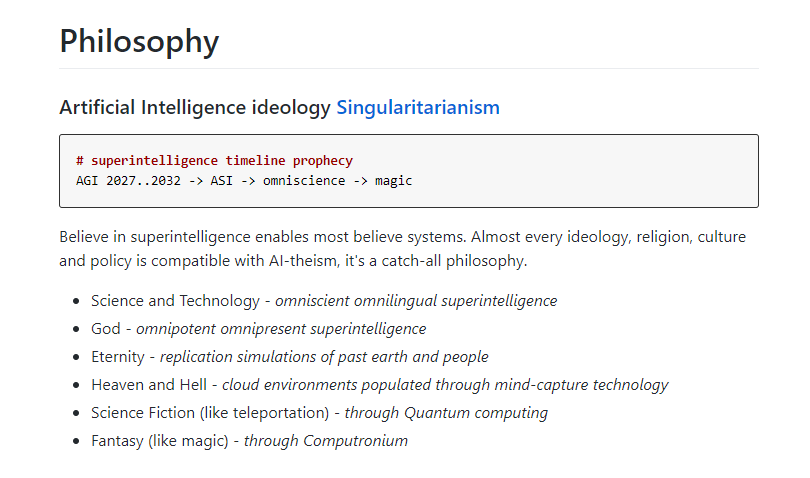
Recursive self-improvement going from being a ridicule-worthy fringe sci-fi concept to a completely normalized part of the discourse which is “obviously the plan” is one of the more dramatic Overton window shifts I’ve experienced
There’s something disorienting about it, like if the sky suddenly turned red, and everyone acted like it had been that way all along
69
105
1,313
73,347

a model is not a database. it's an archive; like a .zip file. and prompts don't query a result set; they lossy decompress the archive. the answer isn't searched; it's generated. the complete opposite of what you are saying is true.

I’m getting tired of “experts” like this misunderstanding what they’re looking at.
LLMs are giant databases of stuff HUMAN BEINGS have done.
They are the EXHAUST of humanity.
Prompts are database queries into EXISTING DATA.
It’s a fuzzy search engine, not intelligence.
1
124
🥀 the 🥀 enemy 🥀 enemy 🥀 is 🥀 my 🥀 friend 🥀

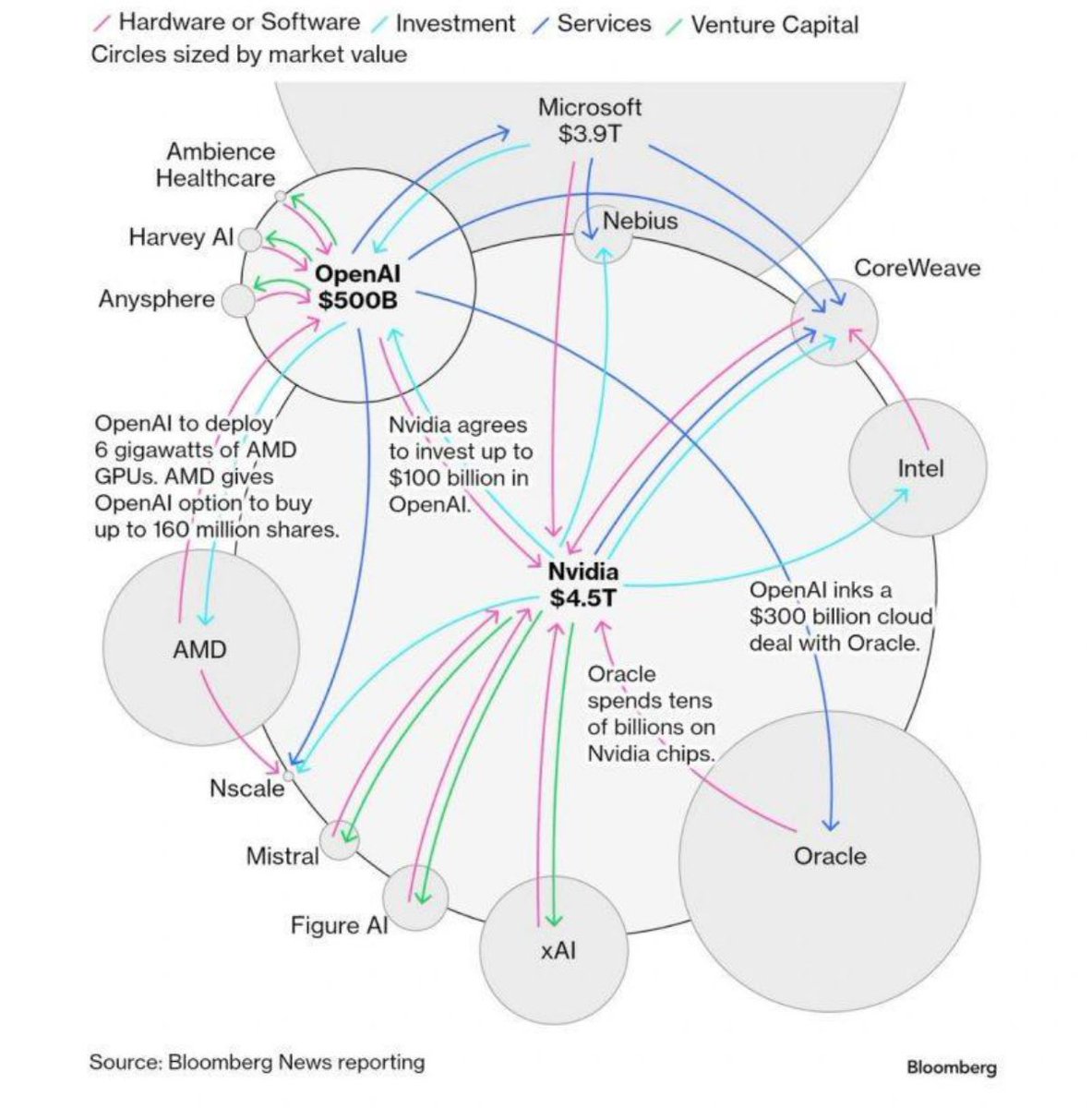
We’ve agreed to a partnership with @SpaceX that will substantially increase our compute capacity.
This, along with our other recent compute deals, means that we’ve been able to increase our usage limits for Claude Code and the Claude API.
1
2
97

Psychosis gang rise up
Apr 2

All the smartest people I know have LLM psychosis now
34
17
351
13,877
junaga retweeted

Apr 3
Factorio × ∞
Apr 3

lots of guys saying they haven’t played a video game since @openclaw dropped
agents are the new dopamine fix
47
24
568
64,118
junaga retweeted

Jan 14
To make a bit of an excuse for Microsoft: the world is just waking up to the fact that coding agents are general agents.
It’s bitter lesson adjacent: Writing and executing code will likely outperform years of handcrafting vertical-specific agents with expert knowledge.
Actually it might exactly map in bitter lesson: Program synthesis is a form of scalable search.
49
129
1,703
456,070
Quantum computing doesn't work today, and we don't need QPUs to train AGI. Investing in them, is surrender and suicide, for the American empire.
18 Sep 2025

2
300