
AI builder, author, and Christian
Joined January 2012
- Tweets 1,105
- Following 168
- Followers 510
- Likes 810
43 Photos and videos



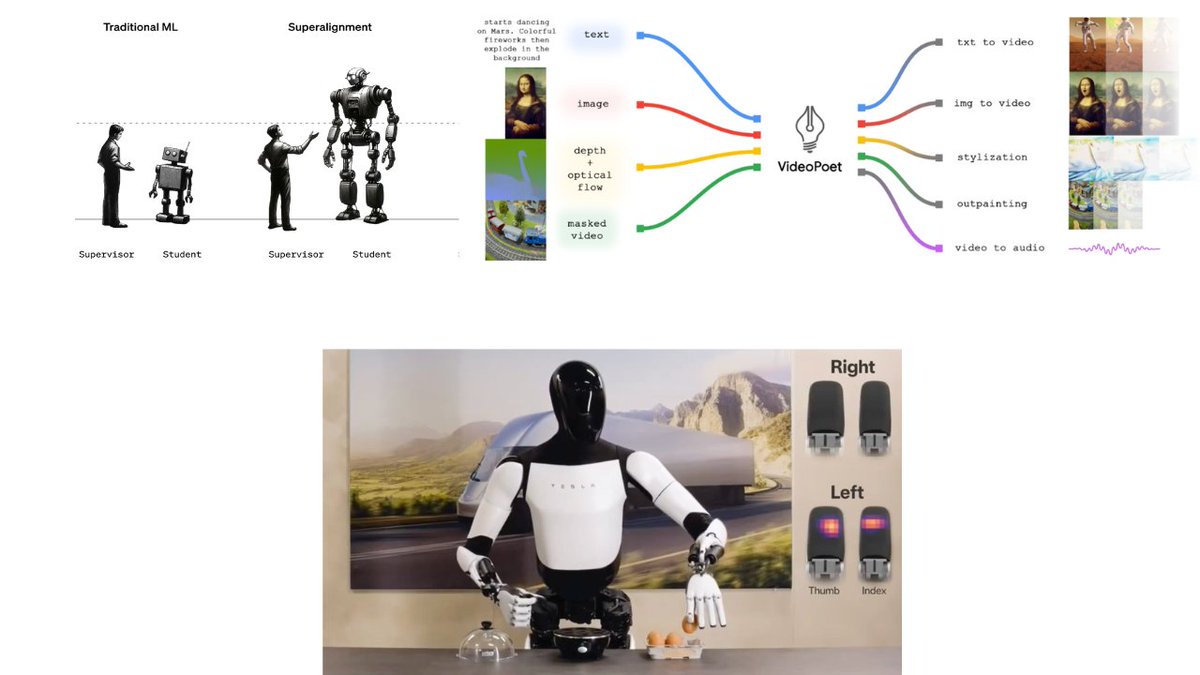





15h
This is an interesting way to introduce robots to home. One big concern of a household robot is safety. A child-like robot is more acceptable: Cute, warm, low risk. It also has less demand on the robot’s functionality.
1
10
Jun 10
Very interesting! This really puts agents through rigorous testing and makes them much easier to compare.
We always need high-quality evaluation datasets — not just for models, but for agents too!

“AI agents will outperform humans at almost all jobs by 2026–2027.” - The forecast is everywhere.
So we built the exam to test that claim, on real labor-market aligned work. On the hardest tier, top agents pass 2.6%.
Meet Agents' Last Exam (ALE), a rolling benchmark measuring whether agents can actually do real jobs. 🧵👇
23

Today, we released Gemini 3.5 Live Translate, our latest audio model for live speech-to-speech translation.
It supports over 70 languages and starts translating as soon as you start talking, streaming translations while listening to what you say next. No awkward pauses or choppy audio, just real connection without language barriers.
So, how does it work? 🤔
The model is able to make split-second decisions to juggle speed and translation quality so conversations actually feel fluid, human, and natural. In order to do this, the model must receive and contextualize the input while simultaneously outputting the translated speech.
Through this process, Gemini 3.5 Live Translate manages to stay mere seconds behind each speaker and can even maintain pacing, pitch, and intonation across extended sessions.
See it in action below, or try it yourself in the Google Translate app on iOS & Android.
143
408
3,035
280,936
Jun 10
Highly recommend this talk by Cursor founder:
The next era of AI coding youtu.be/8h9j2rskP14?si=BeSf…
1
1
22

Junling Hu retweeted

Jun 2
I've written thousands of articles over the past 20 years, but this is the most important one I have contributed to the age-old debate between "viruses don't exist" and "viruses are lethal." I encourage you to share it with health practitioners, who probably have no idea that common environmental exposures, such as microplastics and metals, can mimic EXACTLY the symptomology of contagious infectivity, commonly misdiagnosed as viral in origin. And for those who think this is "magical thinking," they can consult the 60 references at the end of the article. This is a REAL problem, and it contributes significantly to what the WHO and CDC promote as the cause of the majority of epidemics and pandemics. I don't think you'll be disappointed. I encourage comments and criticisms.
📎sayerji.substack.com/p/infec…

22
117
316
8,173
Jun 2
This seems to be new buisness line of Nvidia. The company is no longer a chip company, but positioning for the upcoming robotics era.

NVIDIA announces the first open humanoid robot reference design built for robotics research.
The NVIDIA Isaac GR00T Reference Humanoid Robot combines the @UnitreeRobotics H2 humanoid robot, @SharpaRobotics Wave five-fingered hands for dexterous manipulation, Jetson Thor onboard compute, and Isaac GR00T open software and models, giving researchers a full-stack platform from data capture to model deployment.
Read the #NVIDIAGTC Taipei announcement: nvda.ws/4ef9VOr
9
Junling Hu retweeted

NVIDIA announces the first open humanoid robot reference design built for robotics research.
The NVIDIA Isaac GR00T Reference Humanoid Robot combines the @UnitreeRobotics H2 humanoid robot, @SharpaRobotics Wave five-fingered hands for dexterous manipulation, Jetson Thor onboard compute, and Isaac GR00T open software and models, giving researchers a full-stack platform from data capture to model deployment.
Read the #NVIDIAGTC Taipei announcement: nvda.ws/4ef9VOr
59
244
1,301
160,532
May 31
Spotted a cybercab today in Mountain View. It seems cybercab is coming to Bay Area. It’s exciting.
4
151
Junling Hu retweeted

May 25
Google Omni might be too powerful 🫥
333
979
15,323
1,303,093
Junling Hu retweeted

May 11
Wait... someone just open-sourced the entire AWS cloud in a 90MB Docker image 🤯
Every local AWS emulator before this needed gigabytes of RAM.
Cold starts took seconds just to test one single function, and free tiers are increasingly getting locked down.
Meet Floci.
It's a natively compiled emulator that completely rethinks local cloud testing.
What runs locally with zero dependencies?
→ Storage & Databases: S3, DynamoDB, RDS, ElastiCache
→ Compute: Lambda, EC2, ECS, EKS
→ Events & Messaging: SQS, SNS, EventBridge, Kinesis
→ Security & Auth: IAM, KMS, Cognito, STS
It handles 46 AWS services natively, boots in ~24 milliseconds, and idles at just 13 MiB of memory.
The average Chrome tab uses 15x more than that!
Point your standard AWS SDK at localhost:4566 and your existing scripts work untouched.
No auth tokens, no feature gates, and tests finish before legacy emulators even pull their image.
It's 100% free and open-source.
Repo link in 🧵↓

5
10
54
5,839
Apr 29
Amazing agility from the robots

D1 is a robot developed by the Hong Kong–based startup Direct Drive Tech.
It can automatically assemble into a larger robot or separate into smaller units depending on the task.
This helps it move through tight spaces or carry heavier loads for inspection and maintenance work.
19
Junling Hu retweeted

Apr 23
Anthropic's applied AI team just dropped a 24-minute workshop on how to actually prompt Claude properly.
Free. From the people who built it.
You've been prompting Claude for months without the 6 elements they teach in this.
I built a skill that applies them automatically. Full guide below.
Bookmark it.
Follow @codewithimanshu for more high-signal content that actually moves your skills forward.
43
278
2,507
1,013,753
Junling Hu retweeted
Apr 21
The Head of Claude Code at Anthropic hasn't written code by hand in months.
In 2 days he shipped 49 full features. 100% written by AI.
He just dropped a 30-minute talk on exactly how he does it.
More valuable than any $500 vibe coding course. Bookmark it.
82
522
4,129
589,156
Junling Hu retweeted
Apr 28
Andrej Karpathy just sat down and built GPT from scratch, line by line, in 2 hours.
For Free. From the man who co-founded OpenAI.
This video is enough to become an AI engineer.
Bookmark it. Watch it tonight. Build your own GPT this week.
$5,000. $15,000. $40,000.
That's what bootcamps charge to teach less than what's in this 2-hour video.
This video fixes that this week.
Follow @codewithimanshu for more high-signal AI content that actually moves your engineering career forward.
↓
Karpathy doesn't explain GPT. He builds it.
Live. From "Attention is All You Need" the original paper. To the same architecture powering GPT-5.
Founding member of OpenAI in 2015. Senior Director of AI at Tesla. Now running Eureka Labs.
He's not teaching you how to use GPT. He's teaching you how it actually works at the source code level.
Most engineers will never understand transformers this deeply. The ones who do build the next generation of AI products.
Follow @codewithimanshu for breakdowns of every must-watch AI lecture worth your time.
↓
Here's what gets built in 2 hours. No fluff.
Tokenization and data loading.
The foundation of every modern LLM. Train/val splits done right. Batch loaders that don't break in production.
Most tutorials skip this. You can't ship anything serious without it.
The bigram baseline.
The simplest possible language model. Karpathy builds it first because it teaches you what every fancier model is actually trying to improve.
Once you understand bigrams, transformers become obvious. Skip this and the rest never clicks.
Follow @codewithimanshu for daily breakdowns of what AI engineers actually need to know.
↓
Self-attention. From scratch. Live.
This is the section that should have its own course.
Karpathy builds self-attention in 4 versions:
> Version 1: averaging past context with for loops
> Version 2: matrix multiply as weighted aggregation
> Version 3: adding softmax
> Version 4: full self-attention
Each version teaches you why the next one exists. Why attention works. Why matrix math replaces explicit loops. Why scaling matters.
You'll never look at "attention is all you need" the same way again.
Follow @codewithimanshu for production transformer breakdowns weekly.
↓
The 6 attention notes that change everything.
Karpathy drops 6 insights most engineers never hear:
> Attention as communication between tokens
> Attention has no notion of space, operates over sets
> No communication across batch dimension
> Encoder blocks vs decoder blocks
> Attention vs self-attention vs cross-attention
> Why we divide by sqrt(head_size)
Each one of these explains a different failure mode in production AI systems.
Most "AI engineers" can't answer these. The ones who can charge $300K.
Follow @codewithimanshu for the engineering insights that turn into job offers.
↓
Building the full transformer block.
Single self-attention head. Then multi-headed self-attention.
Feedforward layers. Residual connections. LayerNorm.
Each piece added with the reason it exists. Why residuals stop the model from collapsing. Why LayerNorm replaced BatchNorm. Why dropout matters at scale.
This is the architectural understanding that lets you debug any modern AI system.
Once you've built one transformer by hand, every paper you read becomes 10x clearer.
Follow @codewithimanshu for transformer architecture content every week.
↓
Scaling up to a real model.
Karpathy goes from baseline to a working GPT.
Hyperparameters. Dropout. Model dimensions. The exact tradeoffs every production model makes.
By the end you have a Shakespeare-generating language model running on your machine. From scratch. Built by you. Understood by you.
That's not a tutorial. That's an architectural unlock.
Follow @codewithimanshu for production model scaling breakdowns.
↓
Encoder vs decoder vs both.
The architecture choice that defines every modern AI product.
Why GPT is decoder-only. Why BERT is encoder-only. Why translation models use both.
Once you understand this, you can read any AI paper and immediately know what kind of system you're looking at.
This is the difference between someone who follows AI hype and someone who builds it.
Follow @codewithimanshu for AI architecture deep dives weekly.
↓
NanoGPT walkthrough.
Karpathy ends with a quick walk through nanoGPT. The repo every serious AI engineer has cloned at least once.
Batched multi-headed self-attention. Production-grade code. The clean version of everything you just built.
This is the bridge from "I built a toy GPT" to "I can read and modify production AI code."
Follow @codewithimanshu for repos every AI engineer should know.
↓
ChatGPT, pretraining, finetuning, RLHF.
The video closes with the full lineage. From your toy GPT to ChatGPT.
What changes when you scale up. Why RLHF matters. The exact path from research model to product.
You finish the video understanding the entire stack from raw paper to deployed product.
Most "AI experts" can't draw this map. After 2 hours, you can.
↓
What you'll be able to do after this.
Read "Attention is All You Need" and understand every line.
Debug attention layers when they break in production.
Build a custom language model on your own dataset.
Modify transformer architectures for specific use cases.
Have technical conversations with AI engineers without faking it.
Train a GPT on any data you want. Shakespeare. Code. Your own writing.
That's not "AI literacy." That's the foundation of an AI engineering career.
The kind of foundation that turns into senior roles and consulting contracts most people will never access.
↓
2 hours. Free. From the engineer who built it.
You'll spend longer in meetings this week and learn nothing.
This compounds for the rest of your career.
People who watch it can build GPT from scratch by Friday.
People who skip it stay confused about why their prompts fail in production.
Save the video. Watch it this week. Build something with the knowledge by the weekend.
Follow @codewithimanshu for more high-signal AI content from the people actually building the future.
52
272
1,698
167,572

This is AWESOME... Some guy just sequenced his entire DNA genome on his kitchen table 🧬🧪
It tells his cancer risk, drug responses, what his kids will inherit, and which diseases are coming decades before the symptoms.
Your genome is a 3.2 billion letter source code that predicts more about your health than any other test in existence. Almost no one has ever read their own.
This used to require a hospital, a specialist, and a referral that most doctors won't write. The raw data would sit in a medical record you'd never see.
Until now.
Here's how he did it:
→ Rubbed a cheek swab against the inside of his mouth for 60 seconds
→ Extracted the DNA from his cells using a $150 kit
→ Prepped the DNA for sequencing with enzymes that attach a motor protein to each strand
→ Loaded the sample onto a nanopore device the size of a highlighter, plugged into a MacBook
The device works by pulling single strands of DNA through holes one atom wide. As each letter passes through, it changes the electrical resistance in a tiny but measurable way. A neural network listens to the signal and reconstructs the sequence. 48 hours later, he had his full genome on his hard drive.
The data never touched a server. No spit kit in the mail. No company owning his most sensitive biological information. No risk of the whole thing getting auctioned off in a bankruptcy, which is exactly what happened to 23andMe's 15 million customers earlier this year.
AI is unlocking personal health in a way that has been impossible. We're still so early.


Apr 19

I sequenced my genome at home, on my kitchen table.
I wrote up exactly how I did it - the equipment, protocol, theory, and cost:
iwantosequencemygenomeathome…
47
452
3,824
612,546

138
467
4,248
1,636,040
Junling Hu retweeted

Apr 14
Boris Cherny created Claude Code. he thinks IDEs are dead by end of year.
This is a 28-minute masterclass on how Anthropic uses it internally.
I wrote 5 pipelines you can sell with it. none of them are coding.

66
339
3,565
650,396

Junling Hu retweeted

Apr 14
SOMEONE built an AI agent that sells pool installations on autopilot
10 "boring" cash-flowing startup ideas YOU can build on autopilot using the OpenClaw/Hermes etc:
1. find commercial buildings with flat roofs in sunny states and calculate their solar savings, render the install, mail the building owner a custom ROI report. become the broker between building owners and solar installers, take a cut of every deal or charge $$
2. find shopify stores doing $1M /yr with no international shipping and build them a localized storefront for their top non-US traffic countries, pitch a rev share to unlock revenue they're leaving on the table
3. find businesses paying for 10 SaaS tools via public job postings and tech stack data and build a custom "consolidation audit" showing how to cut 40% of their software spend, sell the migration as a service
4. find commercial properties with high water bills using public utility data and render a xeriscaping or rainwater capture plan with projected savings, sell to property management companies at scale
5. find ecom brands running meta ads to products with 1-2 star reviews and build a better version of their top SKU with a manufacturer, launch against them with their own keyword data
6. find small banks and credit unions with websites from 2012 and render a modern site mobile app with their branding, pitch it as a turnkey digital transformation. they have budget but no one's calling on them
7. find warehouses and industrial spaces near EV corridors with no charging infrastructure and model the revenue from installing chargers, pitch landlords a lease install package
8. find franchisees posting complaints in public forums about their franchisor's tech and build a shadow operating system (POS, scheduling, inventory) that plugs into their existing franchise, sell directly to franchisees
9. find medical practices billing under specific CPT codes with low reimbursement rates and build an AI billing optimization engine that reclassifies and appeals claims, take a % of recovered revenue
10. find DTC brands with 100k instagram followers but no subscription offering and model their repeat purchase data from reviews, build a subscription flow with retention math, pitch it as a done-for-you program with rev share
the framework is basically this
use AI agents to surface a gap in public data, build the solution before anyone asks for it, and show up with the math already done.
you use info arbitrage OpenClaw is the ultimate wedge
i dont know how long this lasts
but i do know there's a ton of ways to make $$ using this
and i won't hold back
i'll be sharing more ideas here, @startupideaspod and @ideabrowser
today is a beautiful day to be building
Apr 12

someone built an OpenClaw agent that SELLS pool installations on autopilot.
finds $500k–$1.2M homes without pools
renders a pool in their backyard
and mails a before/after postcard.
70
39
518
117,973