
Product @ Cloudflare, CEO Human Native, ex-Google/DeepMind, Dad, Product Management practitioner
Joined August 2008
- Tweets 169
- Following 44
- Followers 211
- Likes 162
8 Photos and videos



Apr 13
Agents Week at Cloudflare starts today. We're shipping the infrastructure for what comes after the browser -- the tools, protocols, and payment rails that let AI agents interact with the web as first-class citizens. Not just crawling it. Transacting on it. blog.cloudflare.com/welcome-…
1
27
James Smith retweeted

Mar 12
we're not joking when we say our /crawl does not bypass Cloudflare's bot detection or Captchas
/crawl identifies as a bot respects robots.txt, which is that standard used by websites since (checks notes) 1994 to indicate to crawlers/bots which parts of a website they are allowed to visit.
see the blocking in action below
Mar 11

Saw a lot of misinformation around the new /crawl endpoint @CloudflareDev announced yesterday.
Go try scraping crawlmenot.org with the /crawl endpoint. We said we are going to protect your site, and we stand by it 🧡
4
4
36
5,628
James Smith retweeted

People are completely missing the point of this feature. Most accidentally and probably some on purpose.
They stated very clearly that this obeys all blocking and content rules for your site. It’s literally the opposite of bypassing those controls.
The purpose of the system is to get rid of all the halfassed AI crawlers all over the Internet that are doing a crappy job of pulling your content.
They are loud, rude, and wasteful. And they’re filling the internet and all our logs with massive amounts background noise.
Cloudflare knows they are going to crawl no matter what.
This feature is simply giving them a legit way to do it efficiently so that they don’t clog up the entire Internet doing it in a way that it’s 1000x less efficient.
And it’s still uses all your rules for what can and cannot be crawled. And all of your other Cloudflare controls around crawling are still enforced.
If this is adopted to any significant degree, Cloudflare will be absolute heroes for reducing terabytes of crawler-slop background noise.

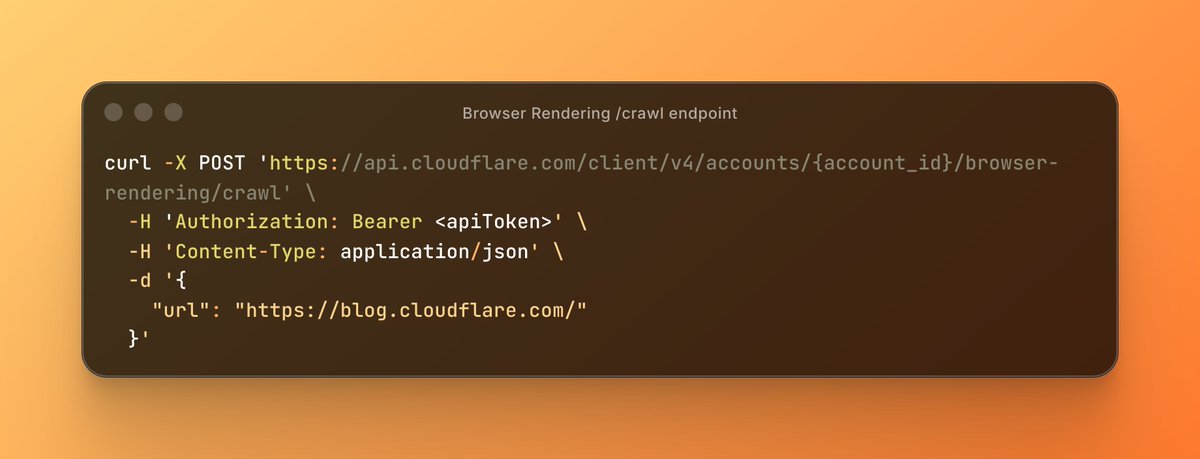
Introducing the new /crawl endpoint - one API call and an entire site crawled.
No scripts. No browser management. Just the content in HTML, Markdown, or JSON.
29
34
570
73,988
James Smith retweeted

Mar 11
Saw a lot of misinformation around the new /crawl endpoint @CloudflareDev announced yesterday.
Go try scraping crawlmenot.org with the /crawl endpoint. We said we are going to protect your site, and we stand by it 🧡
5
8
43
15,920
Mar 12
The web was built for humans reading HTML. AI agents are drowning in error pages meant for browsers. @Cloudflare just shipped RFC 9457-compliant structured error responses: Markdown and JSON instead of heavyweight HTML. 98% fewer tokens wasted.
blog.cloudflare.com/rfc-9457…
31
Mar 11
At @Cloudflare we will continue to build for AI Developers and Content Creators. We need to get the future economy of the internet right, and that means building ways to help AI *responsibly* ingest content in accordance with site owner's wishes!
We want to clarify something: one of the motivations for building this feature is that building a crawler that respects crawling best practices is hard. Too many crawlers use this as an excuse not to abide by site owners' preferences, and respect directives like robots.txt.
/crawl does this out of the box.
Additionally, the /crawl endpoint cannot bypass Cloudflare's bot detection or Captchas, and self-identifies as a bot. It respects all the same protections available to operators today: AI Crawl Control, robots.txt, Content Signals and Pay-Per-Crawl.
So, site owners can and should still choose how their content is consumed, and our /crawl endpoint will respect it.
1
61
Mar 10
If AI agents consume 50% of web traffic but pay 0% of the cost to create the content they consume, who keeps making content? This is the question the entire internet needs to answer in 2026.
20
Mar 6
The 2026 #F1 regulations are the biggest shake-up ever.
New active aero, new power units, completely rewritten rules.
If you're not watching the season opener this weekend, you're missing the best engineering competition on the planet.
acquired.fm/episodes/formula…
57
James Smith retweeted

Jan 15
Cloudflare acquires Human Native, an AI data marketplace specializing in transforming content into searchable and useful data, to accelerate work building new economic models for the Internet. cfl.re/3NuVv1M
3
13
99
16,038
Jan 15
Human Native 🤝Cloudflare
We are thrilled to announce that @humannativeai has been acquired by @Cloudflare !
Check out the full story: blog.cloudflare.com/human-na…
1
3
154
James Smith retweeted

4 Jun 2023
Google just dropped a 100% free learning path on Generative AI with 9 Courses 👇
Intro to Gen AI
Intro to LLMs
Intro to Responsible AI
Intro to Image Generation
Encoder-Decoder
Attention Mechanism
Transformers and BERT
Image Captioning
Gen AI Studio
cloudskillsboost.google/path…
69
1,825
7,248
1,386,248

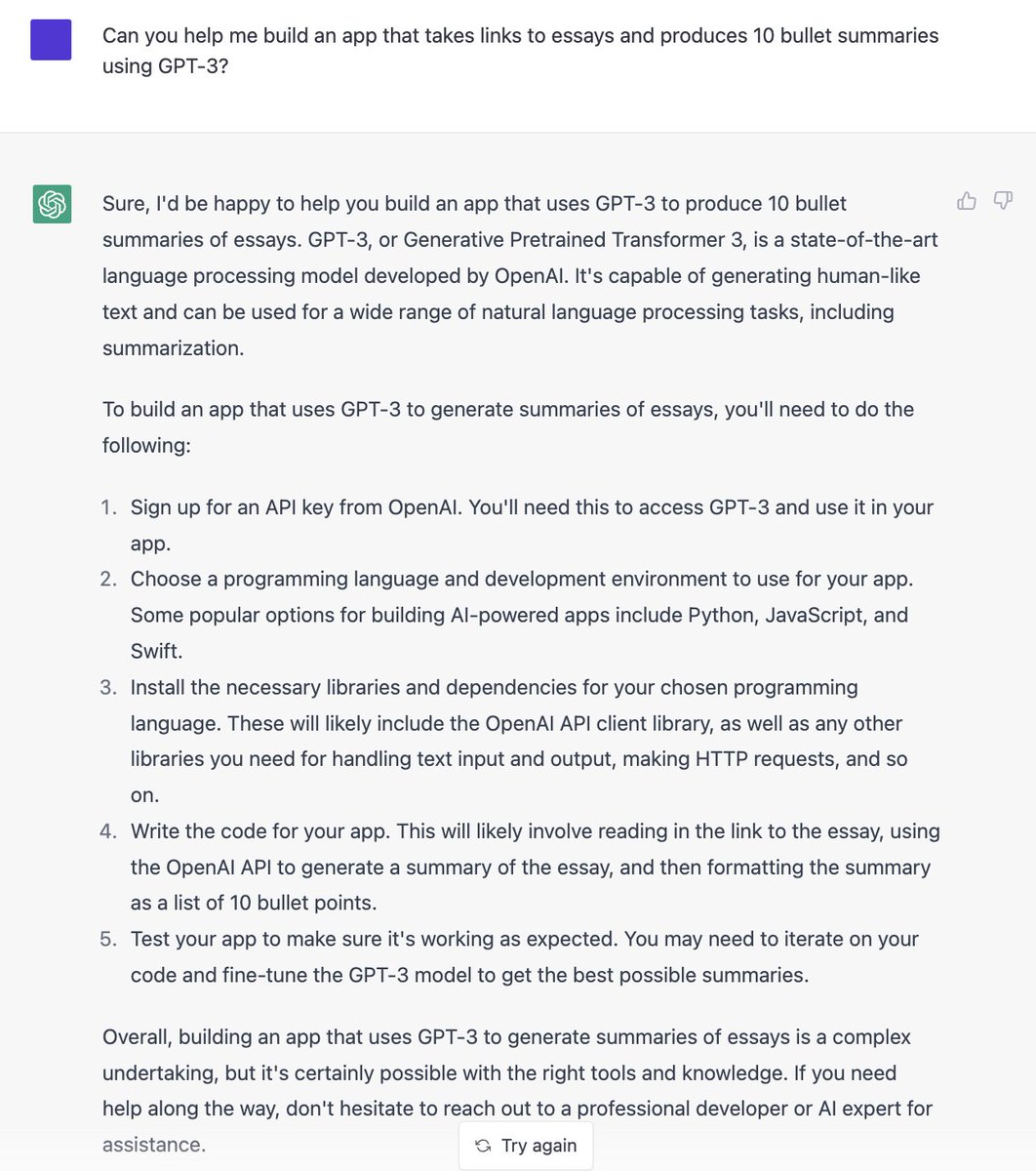
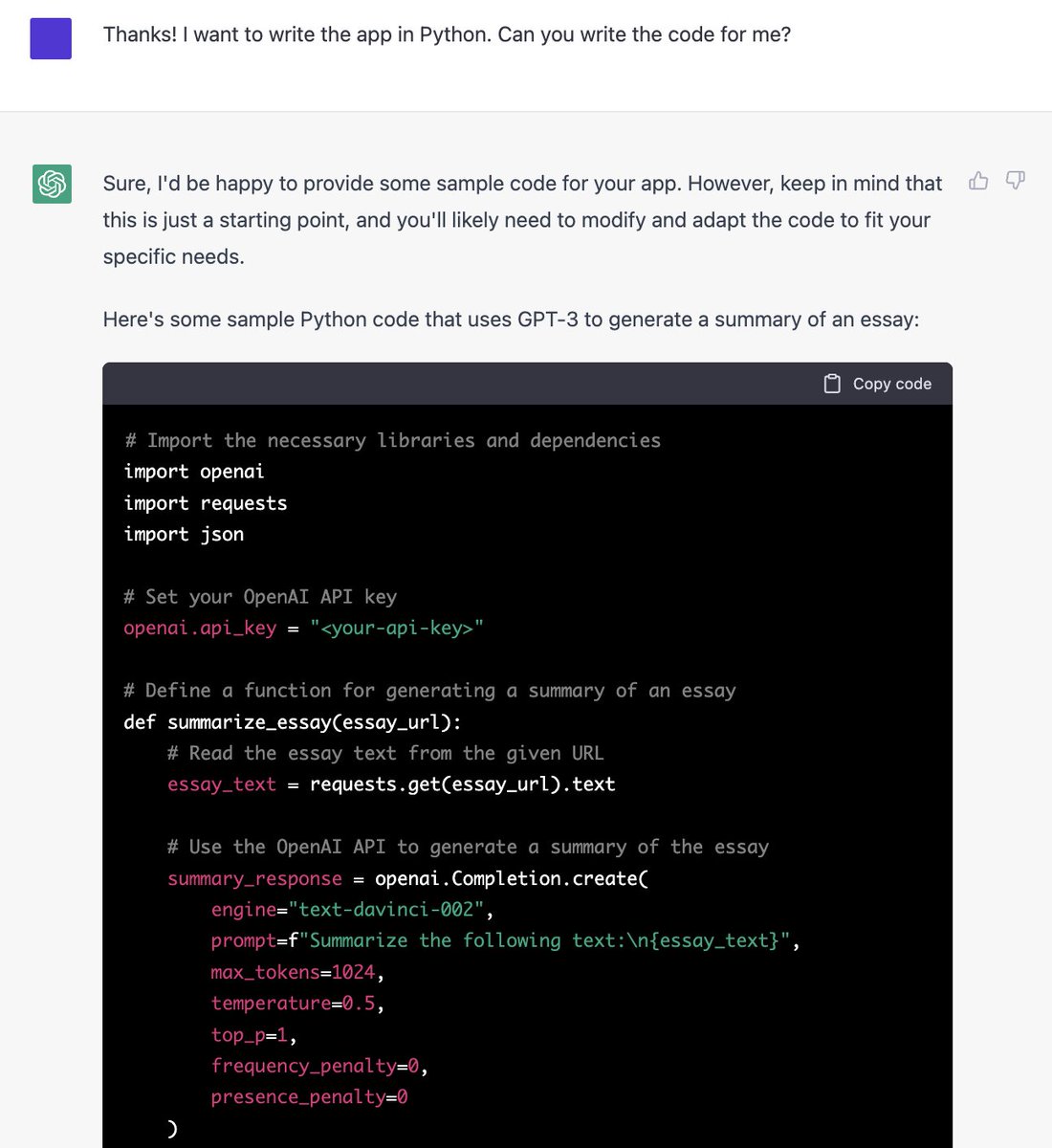

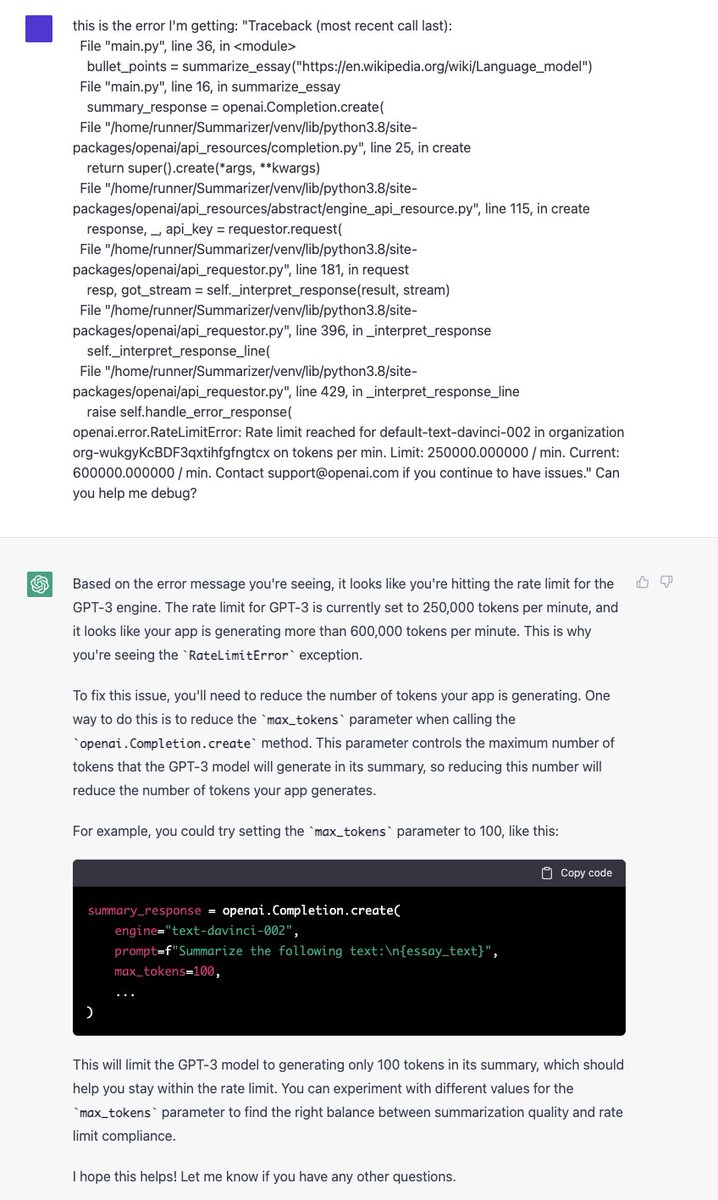
James Smith retweeted

2 Dec 2022
I’m sorry, I simply cannot be cynical about a technology that can accomplish this.
668
9,594
66,799
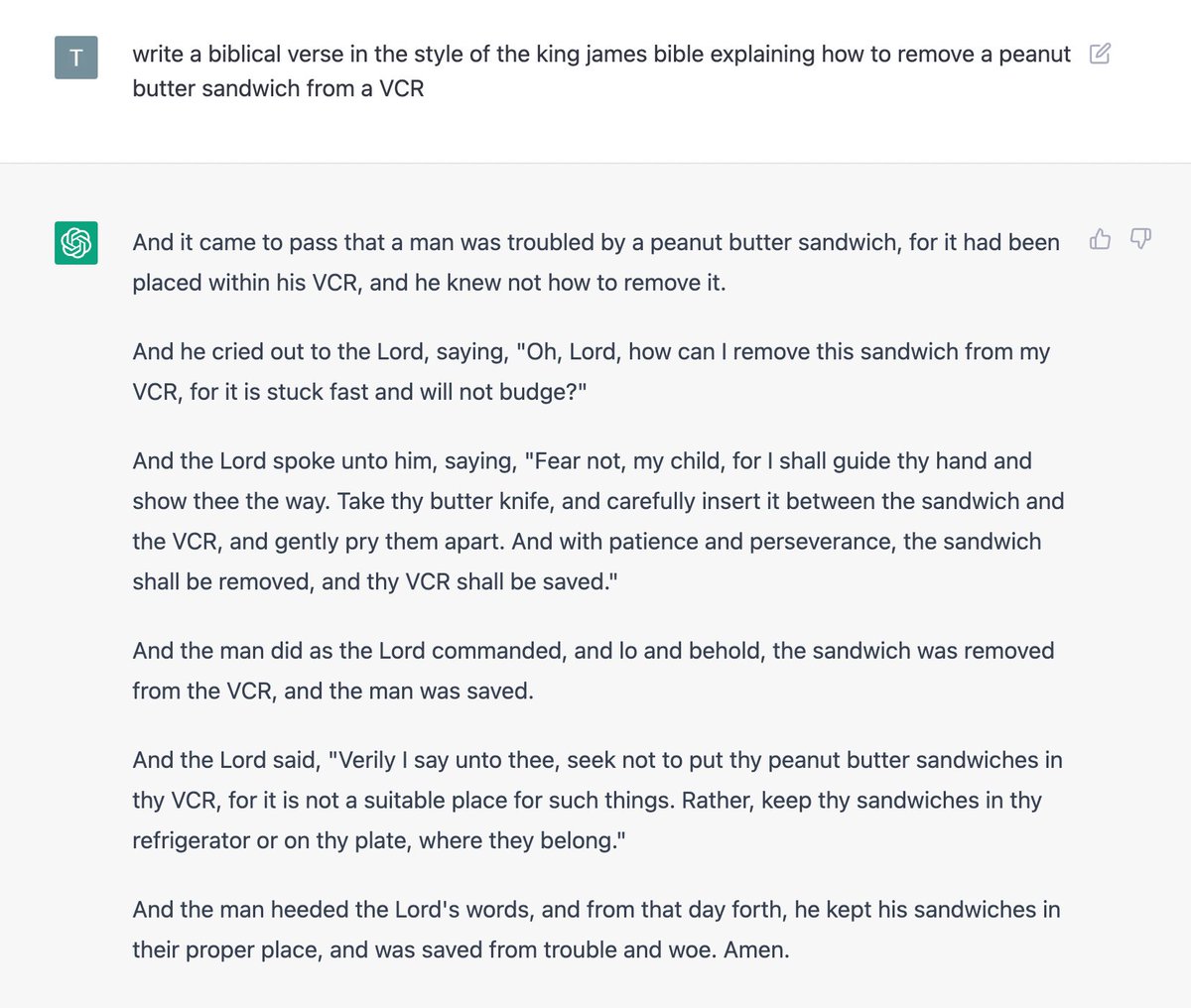
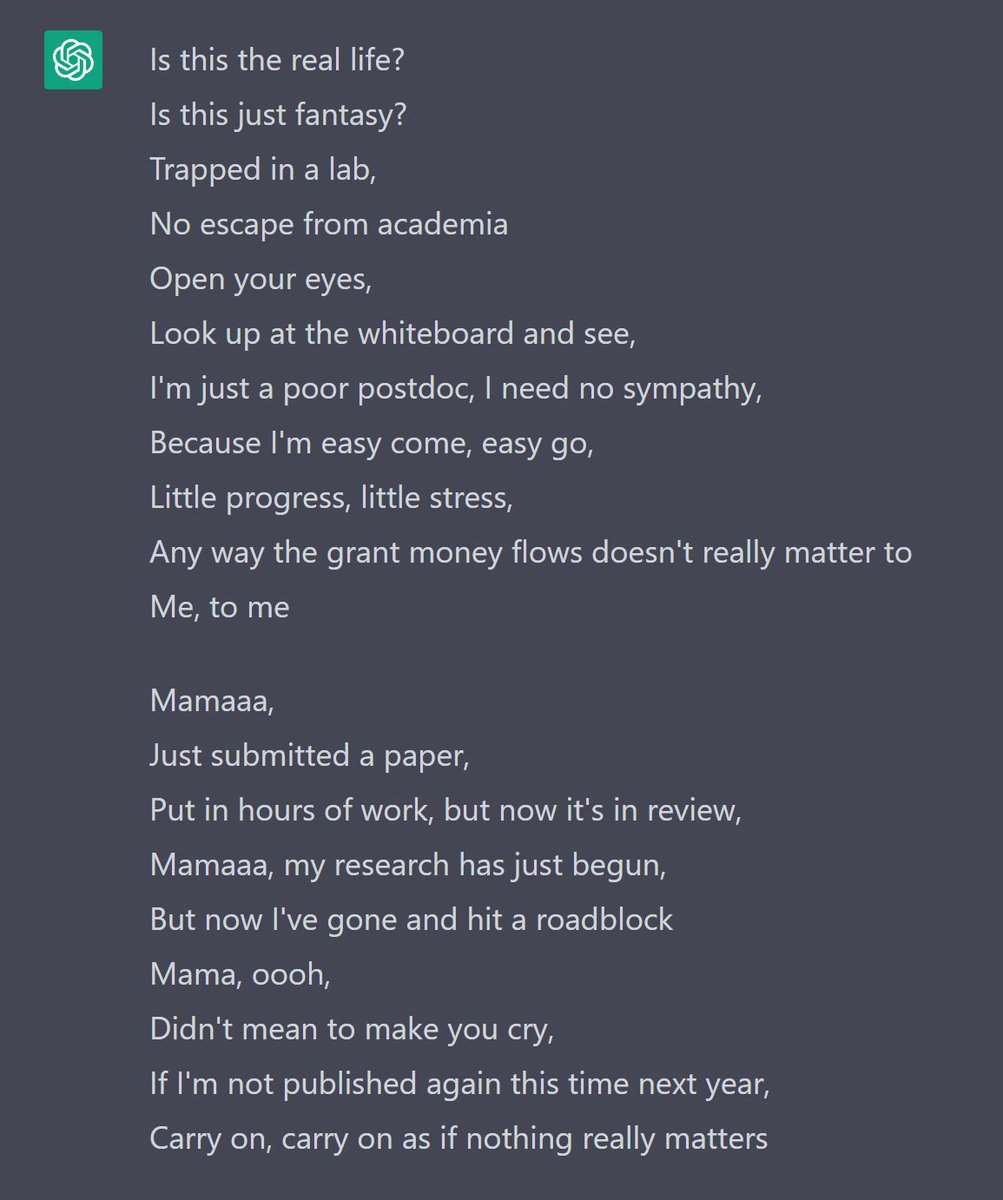
James Smith retweeted

2 Dec 2022
I asked ChatGPT to rewrite Bohemian Rhapsody to be about the life of a postdoc, and the output was flawless:



133
1,590
8,758
James Smith retweeted

3 Oct 2022
28 short pieces of life advice:
1. Block off 90 minutes in your calendar every morning to work on the most important thing. Wake up early if you need to. Don’t compromise.
203
2,128
13,243
James Smith retweeted

9 Sep 2022
That time when we showed the Queen how to get driving directions to Windsor Castle on an early version of Google Maps for phones. The Queen was super curious and engaging. My first & last royal focus group! Circa 2008.

6
6
237
James Smith retweeted

28 Feb 2022
My Product Manager Operating System (PMOS)
The 9 templates and frameworks I've found super valuable in 10 years of building and growing products.
Adopted from Basecamp, Amazon, and more.
A thread 🧵
24
126
823
James Smith retweeted

8 Feb 2022
Early career years are painful.
You feel like an idiot 98% of the time - lost, confused and insecure.
I wish I had a cheat sheet of principles for my first job.
So I put one together.
Here are 20 things about building a career I wish I knew sooner:
272
16,242
51,971
James Smith retweeted

23 Dec 2021
21 questions to reflect on as you end 2021:
76
771
3,233
James Smith retweeted

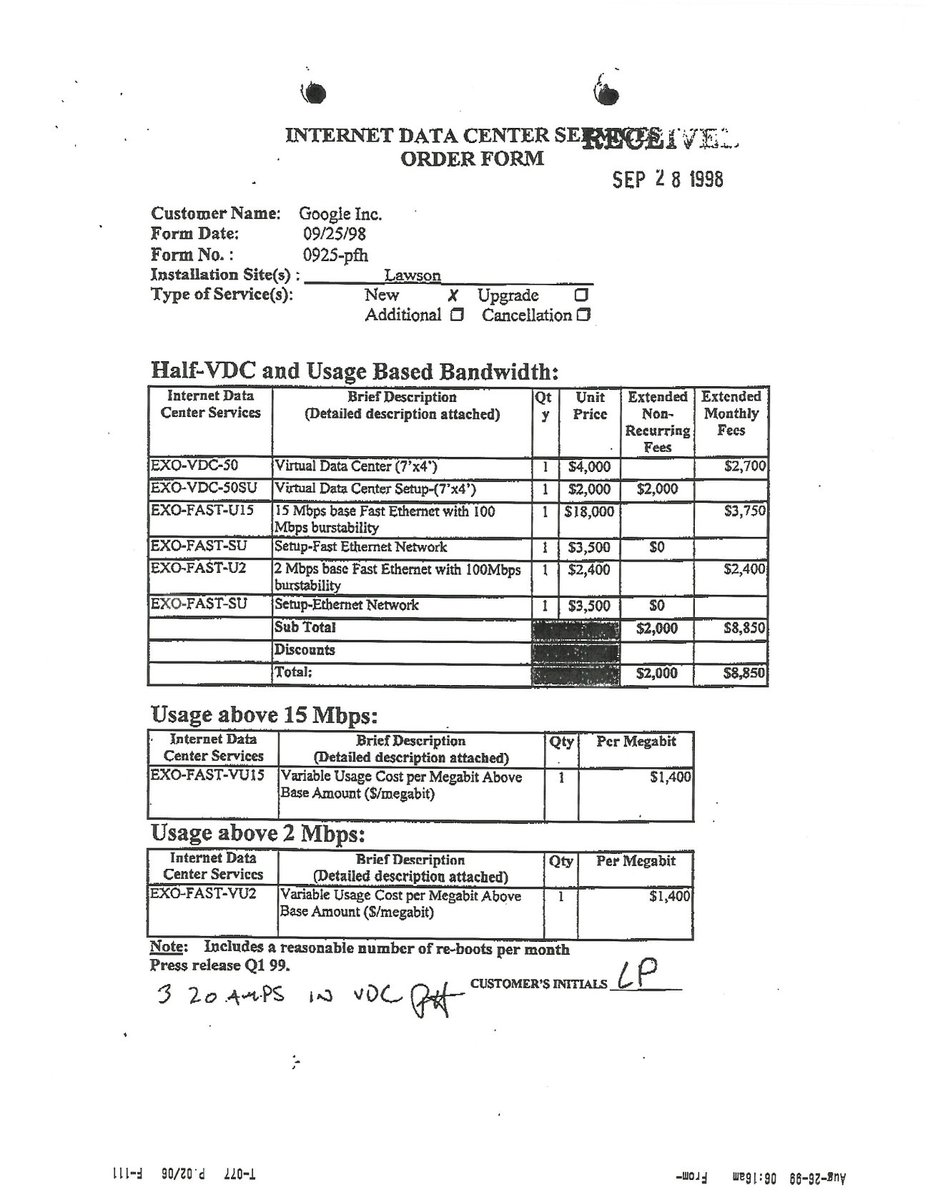
26 Sep 2021
A trip down memory lane...exactly 23 years ago Google signed its first datacenter contract. Let's walk through the lease in a thread. First, the copy you see here was sent by a "fax machine" which was something people used back then.
107
834
3,446