
Not on this hellsite anymore. Find me @ kelwebbdavies on bsky.
Joined May 2007
- Tweets 8,846
- Following 570
- Followers 420
- Likes 34,013
808 Photos and videos















Pinned Tweet

27 Feb 2024
The first part of this webinar I did last week will be relevant to anyone who teaches in HE - it addresses the linguistic accessibility that GenAI enables if it's used for language adjustment, and that students should be allowed to use it that way.
27 Feb 2024

If you missed it last week, you can now watch the recording of @kel_webb's talk on Digital realities and #translanguaging in #EAP!
@baleap #TELL #tleap #DigitalEducation #Baleap
🎥youtu.be/-600GB8w-WQ?si=hWG_…
1
4
15
3,420
7 Nov 2024
Downloaded my archive and deleted the app and I’ll just be on the 🔵 place from now on. Byyeee 👋🏻
5
190
Kelly Webb-Davies retweeted

4 Nov 2024
It’s really difficult to overstate how many pedagogical problems that seem impossible to solve are actually just a function of classes being too big.
20
235
2,075
125,793
3 Nov 2024
The kids do NOT speak “broken” English or struggle to translate thought to language. It’s that these tools are trained primarily on standard, prestige varieties of language so that is how they function best. The tools are biased against linguistic diversity because society is.
1 Nov 2024

One the saddest realizations for me when we were scaling the @midjourney server at @discord in ‘22 was seeing millions of US gen z kids struggle to prompt
They literally don’t have the words. Broken english. Pidgin lingo. Translating thought to language is insanely hard for them
1
1
7
372
3 Nov 2024
We could help kids, and all people who speak stigmatised varieties of languages, by designing the tools to function equally in the full diversity of Englishes. Instead of making ppl conform to the standard, make tools accessible for diverse populations. x.com/AnjneyMidha/status/185…
1 Nov 2024
Gen z is visual. @DavidSHolz quickly realized that and used AI to solve the problem by shipping /describe (image -> prompt)
So that story has a happy ending. But the underlying issue is one of education
If natural language is the UI for AI, the kids need a lot more help
96
Kelly Webb-Davies retweeted

1 Nov 2024
All my posts on the 5 trends will appear on my newsletter AI in Academic Practice: linkedin.com/newsletters/ai-….
2
2
401
Kelly Webb-Davies retweeted
1 Nov 2024
🚀 What are the 5 trends shaping AI today? For my November writing project, I will publish a deep dive into every one of these each week leading up to the 2nd anniversary of ChatGPT:
1️⃣ Multimodality
2️⃣ Interfaces & UX
3️⃣ Long Context Windows
4️⃣ Small Local Models
5️⃣ Agents

1
2
7
1,005
Kelly Webb-Davies retweeted

So sorry to hear this. What a horror story!
As I said to the parliamentary inquiry (on Hansard!) if we rolled this out across Australian higher ed we would expect 60k false positives per semester.
1
2
9
419
26 Oct 2024
Guides like this only address using GenAI to generate content and ideas, but ignore ways of using it for language adjustment - which maintains human thought, creativity, ideas, has basically little to no risk of hallucination, bias and plagiarism, and enhances accessibility.
24 Oct 2024

"there's something especially pernicious about text generators in academia, where writing is not merely an output but a means of thinking, crediting, arguing, structuring thoughts. Hollowing out these skills carries foundational risks" @DingemanseMark tinyurl.com/44samxwe
2
168
Kelly Webb-Davies retweeted
25 Oct 2024
What is the present and future of academic writing in the age of Large Language Models?
I put together some questions to guide our collective reflection. Comments, suggestions, criticisms welcome. 🔗👇
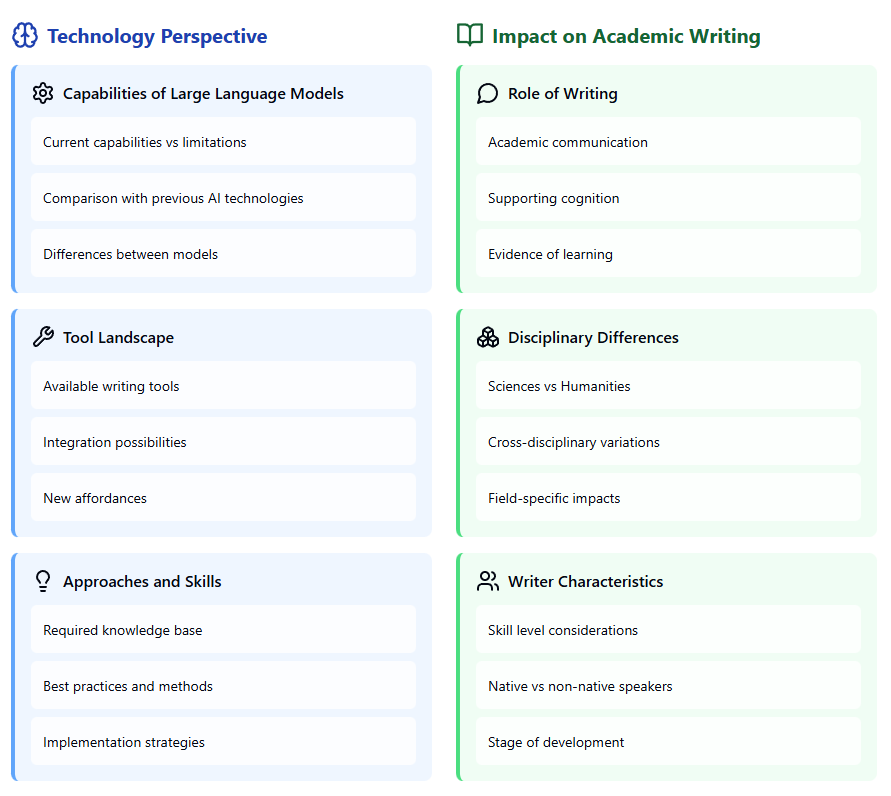
1
5
10
813
Kelly Webb-Davies retweeted

24 Oct 2024
“English is important, but perfect English is not”: The disjuncture between the IELTS and language experiences from the perspectives of international students in Australia - Liu - International Journal of Applied Linguistics - Wiley Online Library onlinelibrary.wiley.com/doi/…
6
17
1,281
25 Oct 2024
This is such wonderful work! There’s increasingly fewer excuses for not being linguistically inclusive in academia, with the current state and rapid developments in language tech.
25 Oct 2024

30% of non-native English speakers often decide not to attend an international conference due to #languagebarriers. @ICCB2025 we are seriously trying to reduce language barriers as much as possible. See our initiatives here: conbio.org/mini-sites/iccb-2…
Our initiatives include:
1
79
23 Oct 2024
Oh this is brilliant. I feel like I’ve been waiting 18 months for something like this!
22 Oct 2024

When ChatGPT came out, many people deemed it a perfect plagiarism tool. The truth is more surprising. nyer.cm/UwR9R7P
1
107
Kelly Webb-Davies retweeted
22 Oct 2024
Universities: Why do our kids use AI to write their assignments 😭 😭 😭 don’t they know writing is important?
Also Universities: What if we made writing instructors into a permanent underclass of peasants that we work to the bone for as little money as possible?
37
891
6,666
312,849
Kelly Webb-Davies retweeted

22 Oct 2024
I know this is meant to be a cuddly story but for those Windrush victims I’ve been speaking to recently who are aging and worrying about dying without their status being sorted, this for them I’m sure will be a slap in the face
22 Oct 2024

Paddington Bear given official UK passport by Home Office theguardian.com/film/2024/oc…
79
835
3,807
162,178
Kelly Webb-Davies retweeted

22 Oct 2024
This whimsy is just nauseating in the context of how the @ukhomeoffice treats actual flesh and blood human beings.
22 Oct 2024

Paddington Bear given UK passport by Home Office dlvr.it/TFbSx2
27
1,596
10,658
475,916
20 Oct 2024
Dominik here with what maybe be a long tweet, but the nuance and POV that is so often missing from AI in edu conversations 👏🏻
20 Oct 2024

Big question about LLMs and learning (with a very long and imperfect answer):
⁉️ How do we use LLMs to learn something we don't know much about? ⁉️
Often, people say you should only use Large Language Models if you know enough to evaluate the output. But that's too limiting and assumes perfect transmission with reliable output.
Here's a much longer than anybody wants exposition of what I think is involved. (Note, this genuinely started as 280 character tweet. Once I gave up on that, I gave up on any semblance of brevity.)
Status quo: How we learn from unreliable sources
People learn wrong things from reliable textbooks or tutors, all the time. And in reality the learning inputs are a mixture of reliable but variably comprehensible input, variably reliable prior understanding, and variably reliable feedback from other sources.
Some examples of unreliable inputs into learning:
- prior knowledge and learning that is either insufficient for comprehension of the input or in conflict with it
- a tutor answering a question wrongly (this happens a lot more than we assume in our models)
- a tutor answering a different question because they did not understand the query (this happens all the time!),
- a peer who shared imperfect understanding of the problem (it is rarely just the one learner with the source of information)
- a socially validated but unreliable or misleading source, for instance, peer reviewed research is completely unreliable as a source of basic information and many textbooks are out of date or present biased information or pass on myths prevalent in the discipline or simplify for pedagogic reasons (which may be inappropriate for the need of the learner who is using them),
- commonly held misconceptions that are passed through the media, common discourse or even practitioners (e.g. many doctors still prescribe antibiotics for viral infections)
Yet, it is possible to learn from this mixture of inputs, because learning is a process and there are many opportunities to learn and unlearn over time as we receive feedback. And as we know, just purely from the progress of knowledge, much of what we learn in textbooks is wrong simply because of new discoveries.
Also, much of the accuracy actual information we learn is irrelevant outside very narrow contexts (e.g. historical facts). Most people who would make fun of creationists do not really understand how evolution through natural selection works or what the roles of genes are. If you interrogate their understanding it becomes clear that they have most a Lamarckian notion of the origin of species with a lot of Huxleyan teleology thrown in. Yet, this does not make any difference.
What kind of input into learning do LLMs provide
The popular pedagogical discourse falls into two frames:
1. LLMs are amazing because they can explain hard concepts in a way that the learner can probe
2. LLMs are dangerous because they may be either subtly wrong or completely hallucinate facts, so that somebody who has no prior understanding will be easily misled
The problem is that both of those framings are accurate. But they can apply to human tutors, as well, or as I suggested to printed validated sources.
But even though on the higher level, LLMs are not that different from other inputs into learning, here, as everywhere they are weird. They have a strange mixture of vast knowledge and misconception. They have unexpected blind spots.
They are deeply conceptual but flawed factually. My quip here is: "ChatGPT is not Wikipedia, but it can help you understand Wikipedia."
So, it is legitimate to approach LLMs with a lot of caution as an input into learning. But the answer is not to exclude them nor to focus only on the imperfections. We need to reconceptualise learning to take into account both framings and the actual state of the status quo.
How do we reconceptualise learning in a world with LLMs?
First, we need to start with the acknowledgement that LLMs with all their strengths and imperfections have already become part of the mix of inputs into learning. And their role will only increase.
Second, we need to fully recognize that the current inputs into learning are a mixture of reliable and unreliable and comprehensible and incomprehensible. And one input can be all of them at the same time for different learners (e.g. a textbook may be actively misleading for the purpose of comprehension, or a paper may be actively incomprehensible for the purpose of maintaining accuracy).
Third, we also need to be more purposeful in distinguishing where reliability is important. For example, if I am a researcher in chemistry working on an experiment and need to look up the exact atomic number of an element, I require perfect accuracy. As do I when I am a student studying for an exam. But if I am learner trying to understand the concept of atomic numbers, the accuracy of the numbers is less important and I can always learn the correct number later.
We already have a perfect model for this in Wikipedia. We are perfectly happy to use it for random facts that don't matter (who was in what movie, when a something happened, what's the definition of a concept), yet we would not (should not) rely on that information if perfect accuracy were necessary - we would instead look up the sources or find alternative sources.
Fourth, we need to pay much more attention to the process of learning. I am very sceptical of simplifying this into "we just need to teach students how to learn" - know how to learn needs to emerge along the process of learning something - pure cognition without knowledge is no good. But I would suggest that we need to incorporate reflection on the learning process more deeply into learning. This does not have a history of success.
Partly, this requires undermining the role of the tutor as an arbiter of reliability and, partly, this is not the exciting part. My analogy is some piano tutorials on YouTube that always combine this is what you need to learn with this is how you practice it.
The problem is that most current tutors are selected for their role because they figured out ways of learning and practicing their subject implicitly and their reflections on the nature of their knowledge / skill or the process it took to acquire it are profoundly unreliable. And even worse, the process they could use for learning/practice is very idiosyncratic to their type - somebody good enough to become a tutor without explicit instruction.
And the other problem is that in our conception of learning, we don't have a positive framing of an imperfectly reliable sources - we only think of it as a bad thing that needs to be eliminated (rather than an inevitability, that needs to be recognised). Although we do have many framings that recognise the reality.
And the final obstacte that stands in our way is that we don't actually have (yet) a reliable set of techniques that will work for a variety of learners using LLMs across a variety of subjects.
2
84
20 Oct 2024
Not all GenAI use is cheating. Many uses increase accessibility and equity. Banning it completely just maintains the status quo which disadvantages many stigmatised groups it could help and I’m not interested in that.
2
6
350
20 Oct 2024
The more I think about it, the more mad I get that the “GenAI = cheating” POV comes from a place of privilege. You find writing helps you think? Great, but not everyone has that brain. For a lot of people writing is a block to thinking.
1
1
55
20 Oct 2024
Don’t need assistance to write in formal English? Fortunate for those born into a social context that means you didn’t have to spend 10,000s of extra hours learning it on top of your own language so you could express your ideas in a way that society codes as educated and worthy.
33