
Streaming DB data to Apache Iceberg | @IITKGP
Joined July 2022
- Tweets 79
- Following 488
- Followers 66
- Likes 47
5 Photos and videos


Rohan Khameshra retweeted

15 Sep 2025
Data replication into @ApacheIceberg isn’t easy from CDC to schema changes, it can get tricky fast.
That’s why at OLake, we’re building not just the fastest replication framework for Iceberg, but also the resources to help you do it right.
Check out this thread 🧵

3
1
1
64
Rohan Khameshra retweeted
9 Sep 2025
In our recent session with Arsham (co-founder , greybeam), we dove deep into the evolving @ApacheIceberg catalog ecosystem.
One highlight: Apache Polaris
Here’s what it is — and why it matters 👇
#DataEngineeringStudy
1
3
6
91
Rohan Khameshra retweeted
4 Sep 2025
Today we’ll be diving into one of the most important concepts of the Iceberg ecosystem — Catalogs.
Expect deep dives into @apachepolaris , Lakekeeper, and AWS Glue, along with demos, why they matter, and how they fit into the bigger picture.
👉 Don’t miss out — Register now!
1
1
5
59
Rohan Khameshra retweeted
2 Sep 2025
Iceberg in production? Your catalog choice decides governance, cost, performance & interoperability.
Join Arsham Eslami (Greybeam) on Sept 4 for a deep dive on catalogs:
Raw Iceberg vs. catalog-backed
Live demos: Glue, Polaris, Lakekeeper
2025 updates: Polaris 1.0, Snowflake

1
1
2
64

28 Aug 2025
Are people here using or planning to use Iceberg V3?
We are planning to use Iceberg in production, just a quick questio before we start the development.
Has anybody done the deployment in production, if yes: What are problems you faced? Are the integrations enough to start?
3
5
71
Rohan Khameshra retweeted
26 Aug 2025
Kickoff session for @_olake week 🚀
Shivji Saurabh from @nutanix dive into:
- @ApacheIceberg table ops
- @ClickHouseDB best practices
- Performance tips
-Live demos Q&A
📅 Aug 28
Save your seat lu.ma/u425eixj
Make sure to keep an eye on the week!
2
3
8
123
26 Aug 2025
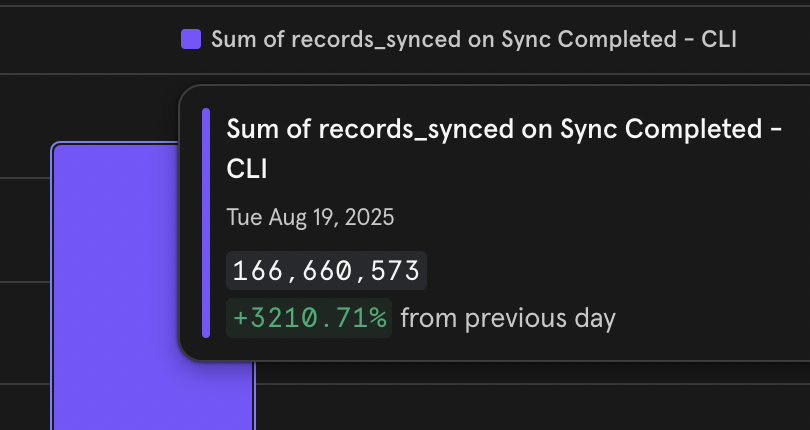
166M rows synched in a single day on a V0.1 version of an OSS, only means one thing @ApacheIceberg is here to stay and is the future of Open Data in the AI world.
24 Aug 2025

I am working on @_olake from last 7 months, and its users are already syncing millions of records to the data lake in iceberg format every day. #etl #iceberg #Growth #postgres #mysql #oracle #mongodb
3
34
Rohan Khameshra retweeted
25 Aug 2025
Optimizing Queries in Apache Iceberg
As data grows, queries slow down. Sorting helps, but not always with multi-column filters.
That’s where Z-ordering comes in it clusters data, reduces file scans, and speeds up queries.
The key is knowing when to apply it.
🧵 A thread




2
2
4
74
Rohan Khameshra retweeted
25 Aug 2025
At our @ApacheIceberg NYC Meetup, we discussed the problems teams face with traditional tools like @fivetran and @AirbyteHQ and why solving them is integral for companies scaling to PBs of data.
From pain points →to Iceberg’s capabilities →how OLake achieves them.
A thread🧵
2
1
6
119
Rohan Khameshra retweeted
21 Aug 2025
Hey devs, OLake Community Week is here!
Bringing together industry leaders, speakers and the community!
📅 Aug 28 – Clickhouse Iceberg session
🤝 Aug 29 – 8th Community Call
📅 Sep 4 – Current landscape & Future Catalog insights
📌 Register here👉 lu.ma/olake?k=c

1
2
66
Rohan Khameshra retweeted
21 Aug 2025
Watch @cto_datazip at the @ApacheIceberg NYC Meetup answer a key question:
👉 How does OLake handle write conflicts when multiple workers are running in parallel?
#OLake #ApacheIceberg #DataEngineering #ParallelProcessing
3
6
134
Rohan Khameshra retweeted

12 Aug 2025
The SC’s directive to remove all stray dogs from Delhi-NCR is a step back from decades of humane, science-backed policy.
These voiceless souls are not “problems” to be erased.
Shelters, sterilisation, vaccination & community care can keep streets safe - without cruelty.
Blanket removals are cruel, shortsighted, and strip us of compassion.
We can ensure public safety and animal welfare go hand in hand.
6,174
8,797
34,759
3,736,795
Rohan Khameshra retweeted

12 Aug 2025
Supreme Court bans them for biting, scaring, and threatening.
For a second, I thought we were discussing about some human beings. And aren’t they a bigger menace to society than these stray dogs?
306
297
1,406
71,470
Rohan Khameshra retweeted
11 Aug 2025
DoorDash saved millions switching to Iceberg format
25-49% storage reduction
40-70% compute cost savings
But Iceberg or delta lake what's right for your ML pipelines?
Our comparison breaks down when to choose what
olake.io/blog/apache-iceberg…

2
5
150
26 Jan 2025
Recently starting reading about @ApacheIceberg and #lakehouse. Will be writing about what I learn.
Do follow if you want to join for the ride.
2
57
30 Jan 2025
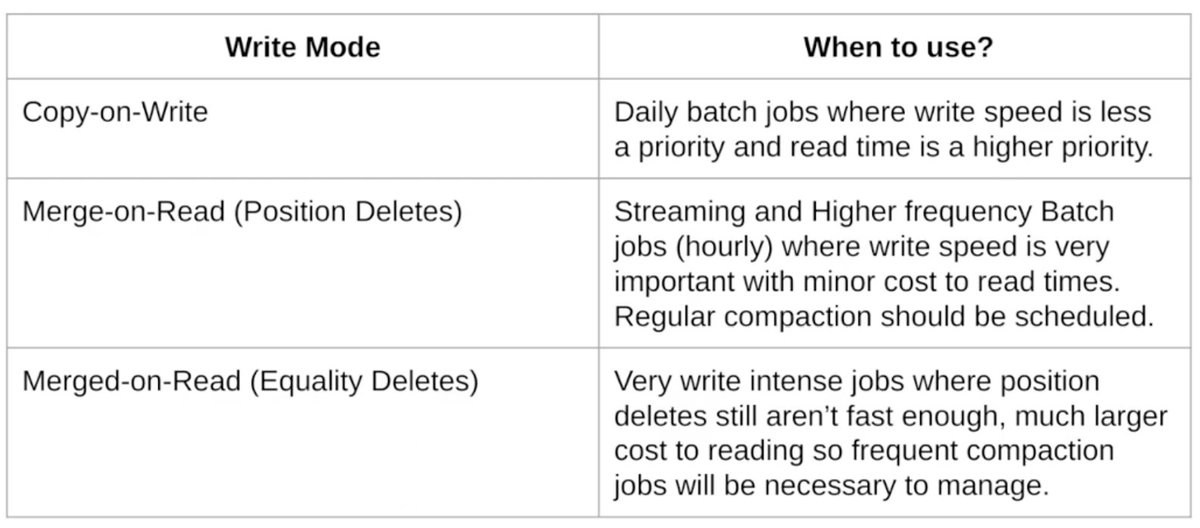
learnt about different methods of data changes
and my 2 cents are:
34
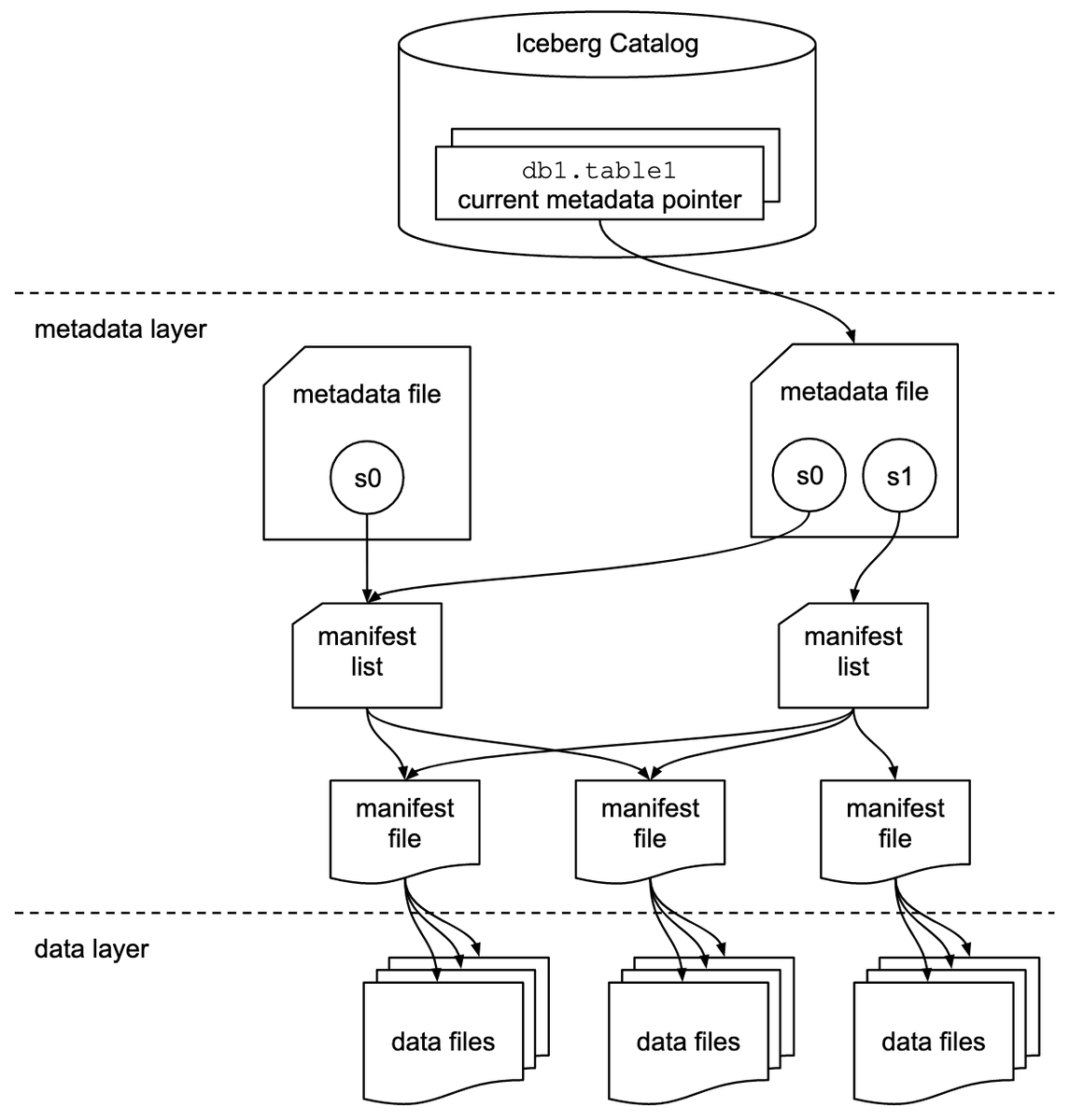
27 Jan 2025
Day 1: learnt about apache iceberg's architecture and how the metadata layer of metadata files, manifest list and manifest helps with ACID properties in data lake.
33
26 Jan 2025
Humans took thousands of years to reach where we are today, AI took just took couple years.
The rate of evolution is definitely exciting. Is 2025 the year where AI take over human for logical thinking in most domains?
25 Jan 2025

Goodbye ChatGPT
It’s only been 5 days since Deepseek R1 dropped, and the World is already blown away by its potential.
13 examples that will blow your mind (Don't miss the 5th one):

1
83
21 Jan 2025
Streaming DB data to @ApacheIceberg sounds easy, but it’s not. Why? 🧵
1/ Capturing changes without impacting DB performance is hard.
2/ Schema changes break pipelines.
3/ Latency makes real-time impossible.
4/ Scaling adds complexity.
How are you solving it today?
2
47
28 Nov 2024
Ohh shittt...and here I thought having more VCs is ecosystem getting mature
28 Nov 2024

No one wants to play a game with more referees than players.
53