
Research @Pokee_AI | PhD from @mldcmu | prev @DeterminedAI | ML expert specializing in large scale model development, AutoML, and MLOps.
Joined February 2019
- Tweets 41
- Following 286
- Followers 97
- Likes 1,119
Photos and videos

At NeurIPS in SD! We're working on scaling agents for automation at Pokee AI
Love to chat about
- RL post training
- agent systems
- long horizon planning and retrieval
DM to connect!
#NuerIPS2025 #NeurIPS
4
137
Liam Li retweeted

22 Oct 2025
🔥 NEW SOTA OPEN-SOURCE MODEL
Today’s a big one for us at @Pokee_AI .
We’re releasing PokeeResearch-7B, a new state-of-the-art deep-research agent that outperforms every other 7B model in its class.
It’s fully open-source — weights inference code are now live on @huggingface, and built end-to-end using @vllm_project , @sgl_project , and @verl_project.
Benchmarks, tools, pipelines — everything’s public. 👇

2
5
23
2,440

Open. Source. SOTA. Deep. Research. 🚀
Today, we’re releasing PokeeResearch-7B, a SOTA open-source deep research agent that outperforms all other 7B deep research agents. And, we are open-sourcing both the weights and inference code on @huggingface!
We're additionally excited to have partnered with vLLM @vllm_project, SGLang @sgl_project, and verl @verl_project on training and inference pipelines.
We can’t wait to see what you all build with PokeeResearch!
🤗• Hugging Face Model: huggingface.co/PokeeAI/pokee…
🌐• Webpage: pokee.ai/deepresearch-previe…
📋• ArXiv: arxiv.org/pdf/2510.15862
🔗• Github Repo: github.com/Pokee-AI/PokeeRes…
60
188
1,122
583,917
Liam Li retweeted
26 Aug 2025
@Pokee_AI is now live with Nano Banana at pokee.ai !
Unparallel consistency in image editing with Pokee's prompt optimization and the fastest AI Agent in social media marketing across the internet!
Publish to any platforms (@instagram, @YouTube , @tiktok_us , @LinkedIn , @X , @facebook , @Pinterest , @Reddit ), completely automatically, with unparalleled quality content, through Pokee AI. Now you never have to hire a big marketing team, it might just be a 1-person job. Maybe even 0-person?
Try it out at pokee.ai today!
#NanoBanana
2
5
6
937
GPT-5 is here—and Pokee AI is already integrated!
We’ve already built it into Pokee AI to give you next-level performance right now.
But Pokee AI is way more beyond GPT-5!
At Pokee AI, we’ve built a full-scale productivity engine—not just with GPT‑5, but by intelligently orchestrating the entire AI model suite to automate tasks, optimize workflows, and deliver results directly across your favorite platforms:
- Built-in integrations for your favorite tools: we deliver the results directly to your accounts in Google workspace, social media platforms(X, LinkedIn, Instagram, Youtube, Ticktok etc ), Notion, JIra etc.
- Custom Workflows & Automation: based on your prompts, Pokee auto breakdown your task into steps and pick the best model for each step.
- Reinforcement Learning–Powered Intelligence: Unlike LLM-only systems like GPT‑5, Pokee uses proprietary reinforcement learning to select tools and complete tasks—solving the execution problem, not just suggesting actions.
🔗 Learn more and try it today: pokee.ai/?ref_code=x_pokee
#ChatGPT #GPT5 #AiAgent #AGI

4
8
856
Liam Li retweeted
8 Jul 2025
🚀 Big news! Pokee AI just raised a $12M seed round—3x oversubscribed!
Our mission: Automate every human workflow on the internet with frictionless AI agents.
Public beta now live 👉 pokee.ai
Here's what we're building and who's backing us 🧵👇
38
31
180
482,107
Liam Li retweeted

12 Nov 2024
🧵 on surprising revelations from our study of specialized foundation models (FMs beyond vision/text): after evaluating dozens of scientific & time series FMs we found that most weren’t even competitive with simple supervised models, some with as little as 513 parameters.
1/n

3
62
243
43,052

Introducing Copilot Arena - Interactive coding evaluation in the wild.
Our extension lets you test top models for free, right in VSCode. Let's vote and build the Copilot leaderboard!
Download here:
marketplace.visualstudio.com…
Led by @iamwaynechi and @valeriechen_ at CMU. 1/🧵
10
73
474
158,083
Liam Li retweeted

14 Mar 2024
Introducing Unified PDE Solvers (UPS), a step towards efficiently building foundation models for PDE solvers (arxiv.org/abs/2403.07187)! Starting from a pretrained LM, UPS tackles diverse spatiotemporal PDEs with SOTA accuracy, using ~20x less data and a single A6000! 🧵[1/x]
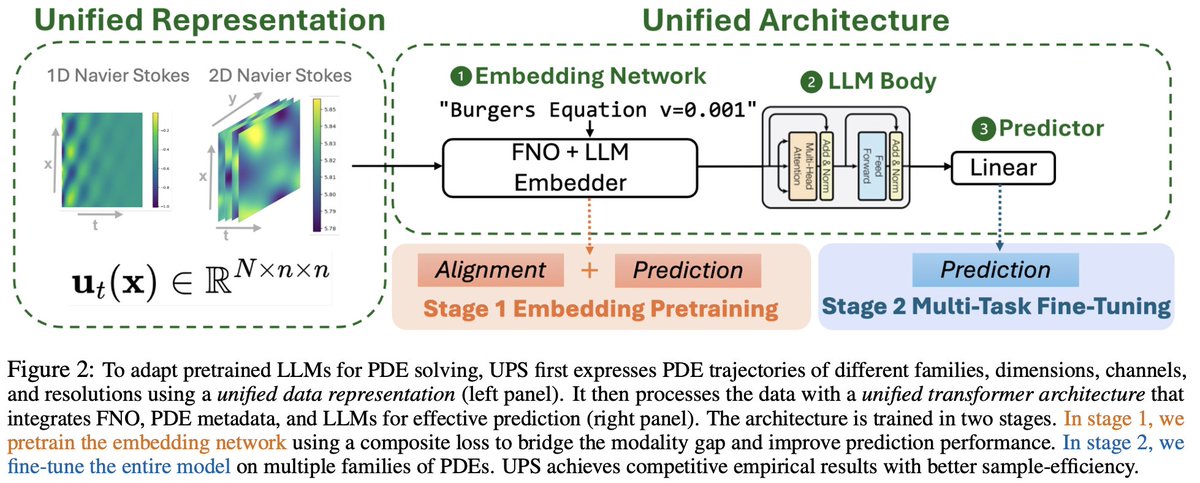
3
24
101
14,672
One of the clearest explanations I’ve seen of kv cache, continuous batching, paged attention, and mqa.
18 Dec 2023

New blog post: how to make LLMs go fast! Want to understand how people are making LLMs go brrrrr? This post is a survey of lots of different LLM inference optimizations, ranging from "everyone uses this in prod" to "I cooked this up last week (but it seems to work)"



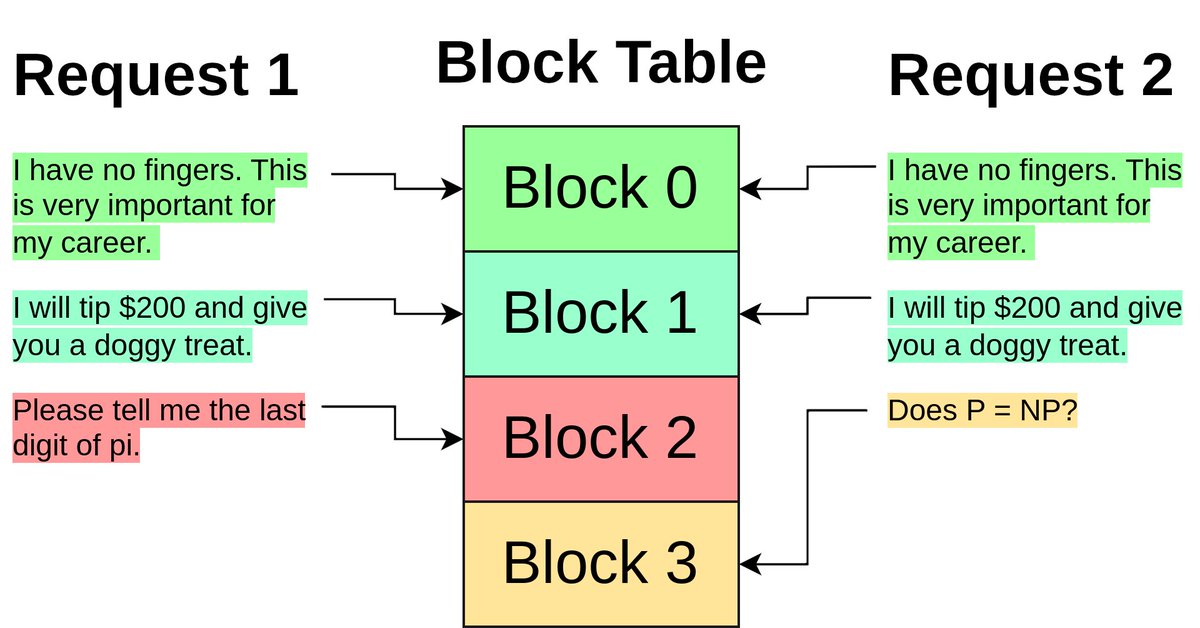
1
161
Liam Li retweeted

18 Dec 2023
New blog post: how to make LLMs go fast! Want to understand how people are making LLMs go brrrrr? This post is a survey of lots of different LLM inference optimizations, ranging from "everyone uses this in prod" to "I cooked this up last week (but it seems to work)"
12
149
1,012
176,789
Liam Li retweeted

16 Dec 2023
Chat with Mistral 7B Instruct v0.2 running locally in iphone and ipad. Now available in @AppStore. apps.apple.com/gb/app/mlc-ch…
21
66
482
135,427
Liam Li retweeted

13 Dec 2023
phew, did our annual @untappedvc LP summit yesterday!
thought it'd be fun to share a few of our slides (w candid/cheeky commentary).
👇

182
12
132
63,135
Liam Li retweeted

9 Dec 2023
The EU AI Act negotiations ended.
One contentious issue was the regulation of foundation models, particularly open source ones.
Kudos to the French, German, and Italian governments for not giving up on open source models.
Juicy part:
"The legislation ultimately included restrictions for foundation models but gave broad exemptions to “open-source models,” which are developed using code that’s freely available for developers to alter for their own products and tools. The move could benefit open-source AI companies in Europe that lobbied against the law, including France’s Mistral and Germany’s Aleph Alpha, as well as Meta, which released the open-source model LLaMA."
washingtonpost.com/technolog…
126
556
3,357
739,698
Liam Li retweeted

27 Nov 2023
I'm moderating a plenary panel at #NeurIPS2023 entitled "LLMs: Beyond Scaling" with some amazing researchers.
Please send or upvote any interesting questions:
dory.app/events/2KZxWFPULUn9…

7
58
511
103,533
Liam Li retweeted

16 Feb 2023
Is training deep neural nets from scratch about to become obsolete? Recent research indicates that the answer might be yes. Here's why...
📰: arxiv.org/abs/2302.05738
[1/5]
4
52
274
44,862
Super excited to share our work led by @JunhongShen1 on cross-modal fine-tuning! We show it's possible to adapt LLM to genomics, music, ECG, and tabular data with surprisingly strong results, often surpassing current SoTA. Check out the thread for more details!
14 Feb 2023

Can we use LLMs to tackle genomics tasks? Vision transformers to solve PDEs? In new work led by @JunhongShen1, we consider the general problem of cross-modal fine-tuning and provide surprisingly optimistic answers to these questions. 1/N
arxiv.org/abs/2302.05738
1
5
307
Liam Li retweeted

1 Feb 2023
Excited to introduce 💠 𝗭𝗲𝗻𝗼, an ML evaluation framework for any data or model, from classification to image generation.
Our goal is to create a standard tool for ML evaluation, like PyTest for testing or PyTorch for model dev.
Learn more at zenoml.com
(1/6)

6
52
313
67,487
Liam Li retweeted

10 Dec 2022
1/ A large part of my job is producing detailed reports for commercial clients regarding how the ongoing pandemic will affect the market in the future. Weeks, months, years.
213
3,083
8,365
Liam Li retweeted

29 Nov 2022
Can’t wait to attend @NeurIPSConf tomorrow, my first in-person conference in way too long! And excited to share this experience with several students / collaborators who are finally getting to present their work in person... 1/N
1
6
33