
Chief Scientist | Committer of vLLM / LMCache / Production Stack
Joined January 2022
- Tweets 109
- Following 59
- Followers 221
- Likes 233
12 Photos and videos










May 1
Goblin is lowkey invading open-source projects lol.
May 1

GOBLIN MODE: ON
, ,
/(.-" "-.)\
|\ \/ \/ /|
| \ / =. .= \ / |
\( \ o\/o / ) /
\_, '-/ \-' ,_/
/ \__/ \
\ \__/\__/ /
___\ \| -- |/ /___
/` \ / `\
/ '----' \
[!] Goblin breach detected // LMCache docs
> Click to make them go away ▓▒░
docs.lmcache.ai/
1
141
Apr 29
massage and then cut, cruel
Apr 29

Cutting a sweet mango with machine
Community note
All mango varieties contain a large central seed or pit, which is absent in this video. mango.org/mango-facts en.wikipedia.org/wiki/Mango a-z-animals.com/blog/truth-or-…
51
Apr 23
So glad to see our project --- LMCache --- is included in the discussion!

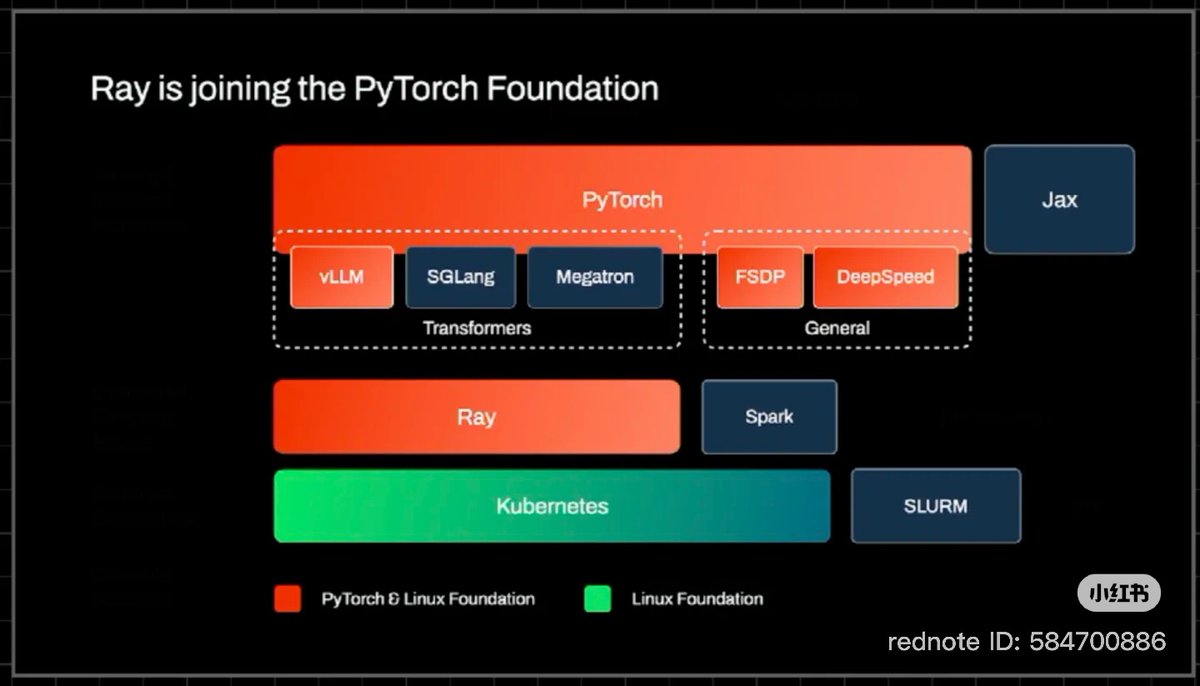
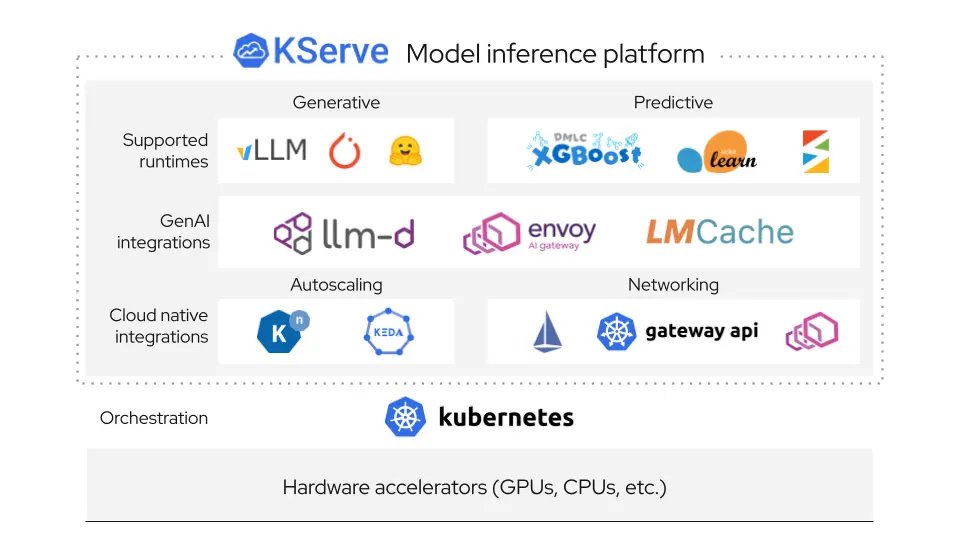
llm-d published a new post on KServe llm-d vLLM for production LLM inference on Kubernetes.
Authors from @RedHat and Tesla describe how the stack addressed routing, customization, and day-2 operational challenges, citing 3x higher output tokens/s and 2x lower TTFT in one deployment after enabling prefix-cache aware routing.
By Yuan Tang, Scott Cabrinha, Robert Shaw, and Sai Krishna
@CloudNativeFdn
🔗 @_llm_d_ llm-d.ai/blog/production-gra…
#vLLM #KServe #Kubernetes #LLMOps #OpenSource
6
778
Apr 23
Free yes, only in April no
Apr 9

Try the top models for free in April
1
66
Apr 23
Key trick: don't use existing interactions directly ---- try to generate "lessons" from previous interactions instead.
Apr 21
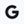
ReasoningBank, a novel agent memory framework, enables LLM agents to continuously learn from both successful & failed experiences. Our evaluation shows that it enhances agent effectiveness, boosting success rates and efficiency. Learn more: goo.gle/4dWrPGb
ALT Workflow of ReasoningBank integrated with an agent during test time.
2
116
Apr 22
LLM providers start to take control...
Apr 22

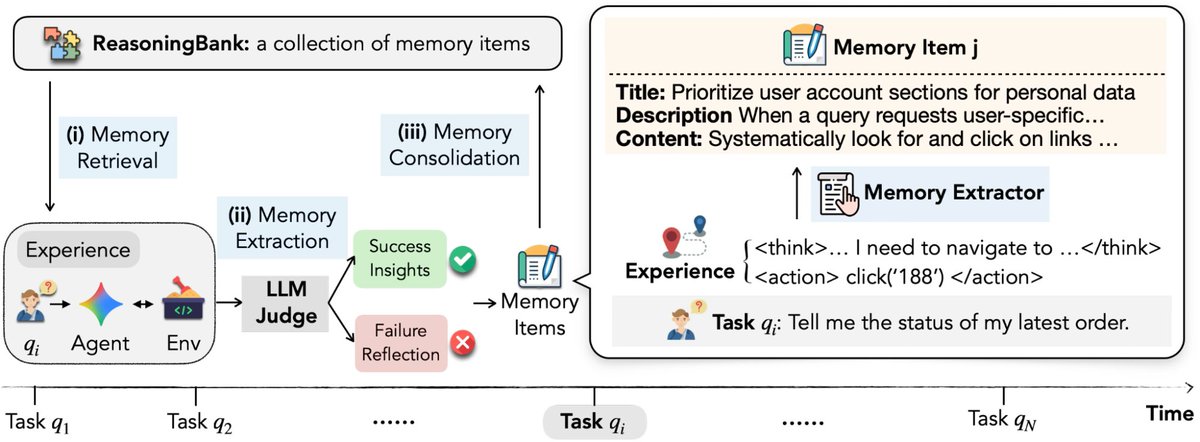
A company with 60 accounts just had its entire AI infrastructure taken offline by their provider.
No reason given, all that was provided was an appeal path as a Google Form.
This is not a one-off, we have mapped the pattern across every major closed-weight provider and what enterprise teams can do about it.
📖 Read the full blog: tensormesh.ai/blog-posts/ent…
🚀 Try Tensormesh with $100 in free GPU Credits: app.tensormesh.ai/login?logg…
1
119
Apr 17
My time being spent:
before using claude code --> write code
after using claude code --> read code, understand and find potential issues
My mental effort is not getting much lighter lol.
4
191
Apr 16
I want stardew valley on my IDE 😝
Apr 15

Someone built a transparent Mario game that runs OVER IDE so can play while waiting for Copilot to write code.
1
76
Apr 16
Heard that Qwen close-sourced their best model 😈
Apr 16

⚡ Meet Qwen3.6-35B-A3B:Now Open-Source!🚀🚀
A sparse MoE model, 35B total params, 3B active. Apache 2.0 license.
🔥 Agentic coding on par with models 10x its active size
📷 Strong multimodal perception and reasoning ability
🧠 Multimodal thinking non-thinking modes
Efficient. Powerful. Versatile. Try it now👇
Blog:qwen.ai/blog?id=qwen3.6-35b-…
Qwen Studio:chat.qwen.ai
HuggingFace:huggingface.co/Qwen/Qwen3.6-…
ModelScope:modelscope.cn/models/Qwen/Qw…
API(‘Qwen3.6-Flash’ on Model Studio):Coming soon~ Stay tuned

127
Apr 14
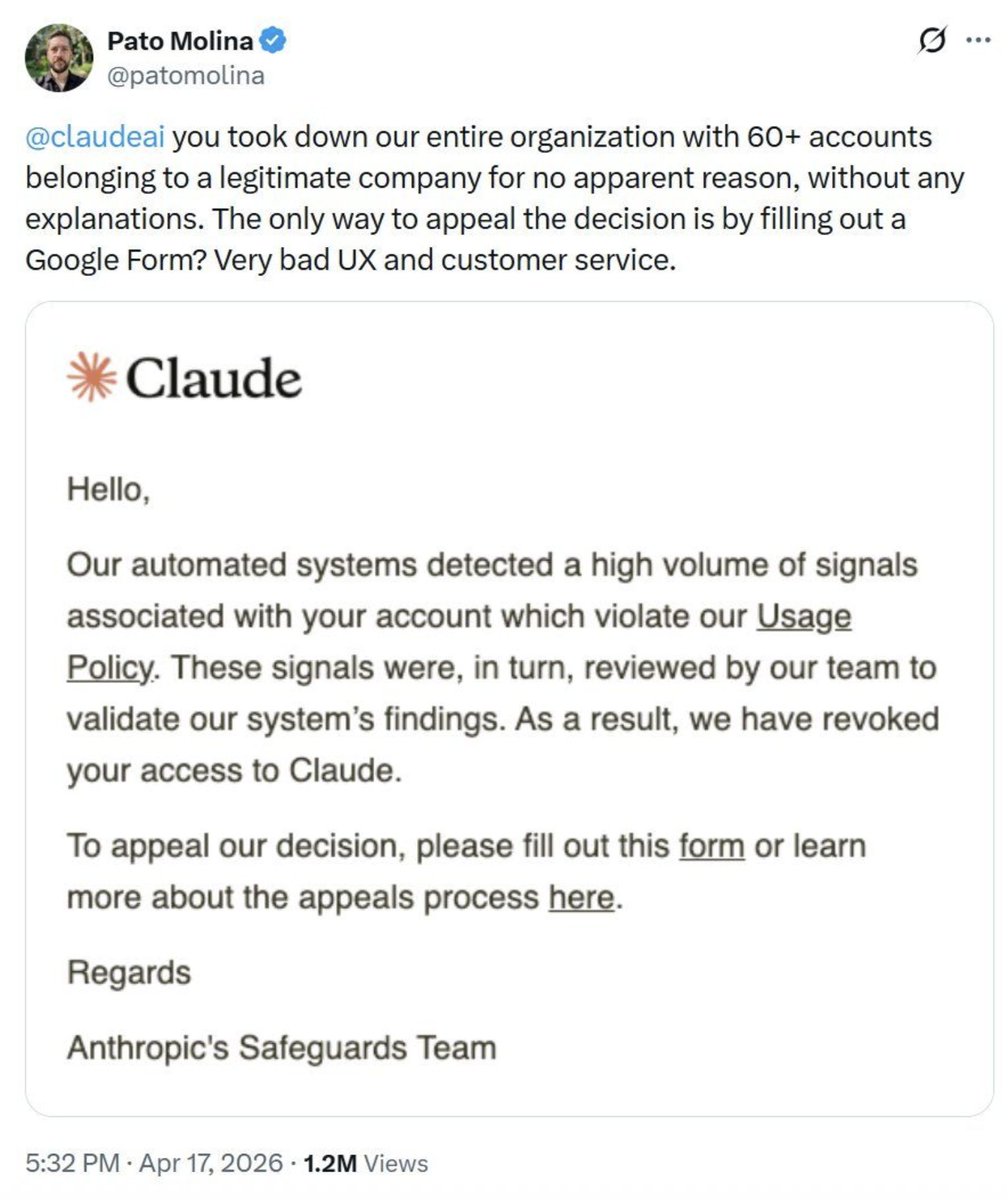
LLM for reranking helps you push Terminal Bench Sota by so much!
Apr 13

Turns out we can get SOTA on agentic benchmarks with a simple test-time method!
Excited to introduce LLM-as-a-Verifier.
Test-time scaling is effective, but picking the "winner" among many candidates is the bottleneck. We introduce a way to extract a cleaner signal from the model:
1️⃣ Ask the LLM to rank results on a scale of 1-k
2️⃣ Use the log-probs of those rank tokens to calculate an expected score
You can get a verification score in a single sampling pass per candidate pair.
Blog: llm-as-a-verifier.notion.sit…
Code: llm-as-a-verifier.github.io
Led by @jackyk02 and in collaboration with a great team: @shululi256, @pranav_atreya, @liu_yuejiang, @drmapavone, @istoica05
1
13
3,227
Apr 14
Latest models use efficient attentions like Mamba or sliding window. This gives huge potential in KV cache offloading layer --- LMCache needs to catch up.
Apr 14
GPU memory alone won’t carry the next generation of LLM serving.
At #RaySummit, our Chief Scientist @this_will_echo shared how #LMCache offloads KV Cache across CPU RAM, local disk, Redis, and S3, while enabling cache reuse beyond basic prefix caching.
Watch the full talk on YouTube:
👉🏻youtube.com/watch?v=aVpkkVp-…
#RaySummit #LMCache #Tensormesh #KVCache
2
154
Apr 13
Lol benchmaxxing, sooo true
Apr 12

we need agent evals that are really consistent with real world usages. otherwise people are optimizing foundation models for the wrong direction. the problem of targeting is even bigger than benchmaxxing.
2
587
Apr 11
Two years ago, we just have 2 NVIDIA A40.
Two years later, our project is mentioned in Jensen Huang's GTC talk.
Hope is the first-order weapon for human to fight for the future.
Mar 18

Some former colleagues from @lmcache shared this photo from the GTC Keynote. I am honestly surprised how fast the team has been growing. (We were a research lab on 2 A40 GPUs in 2023!)
btw I think they are hiring LLM hackers (or product hackers I am not sure 🤪, you should just check with @JunchenJiang @ChengYihuaA)
#GTC #LLM #Inference #Nvidia #LMCache #KVCache

3
5
1,136
Kuntai Du retweeted

Mar 31
Why not store KV cache permanently?
In case you missed it, #IBM recently posted two blogs for 𝗹𝗹𝗺-𝗱 𝗞𝟴𝗦 𝗟𝗠𝗖𝗮𝗰𝗵𝗲-based KV storage. Thrilled to keep building together.
Avoiding recomputation is the goal, but it’s still rare to see KV cache treated as shared, persistent infrastructure in real production deployments.
Excited to see LMCache be part of this with IBM, a long-time collaborator of the LMCache community. Thrilled to keep building together.
These two posts are a great look at what that can actually look like in practice:
1. Rethinking LLM Inference Economics with llm-d, LMCache, and IBM Storage Scale
community.ibm.com/community/…
2. Deploying Distributed LLM Inference Service with IBM Storage Scale for KV Cache Offloading
community.ibm.com/community/…
Great read for anyone interested in fast yet cheap LLM inference.
#LMCache #vLLM #Kubernetes #K8s #KVCache
2
8
296
Mar 25
Physical LLM is on the way lol
Mar 25
"𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 𝗰𝗼𝗻𝘁𝗲𝘅𝘁 𝗶𝘀 𝘁𝗵𝗲 𝗻𝗲𝘄 𝗯𝗼𝘁𝘁𝗹𝗲𝗻𝗲𝗰𝗸" — Kevin Deierling, SVP Networking #NVIDIA
At his #GTC talk last week, he highlighted 𝗖𝗠𝗫 and 𝗖𝗮𝗰𝗵𝗲𝗕𝗹𝗲𝗻𝗱 from 𝗟𝗠𝗖𝗮𝗰𝗵𝗲 (@tensormesh) were part of the new KV Cache memory stack for agents, and recognized @tensormesh among the 𝗖𝗠𝗫 𝘀𝘁𝗼𝗿𝗮𝗴𝗲 𝗽𝗮𝗿𝘁𝗻𝗲𝗿𝘀.
As the stack evolves, @tensormesh keeps building for what's next.
▶️ session Replay:
tinyurl.com/GTC-talk


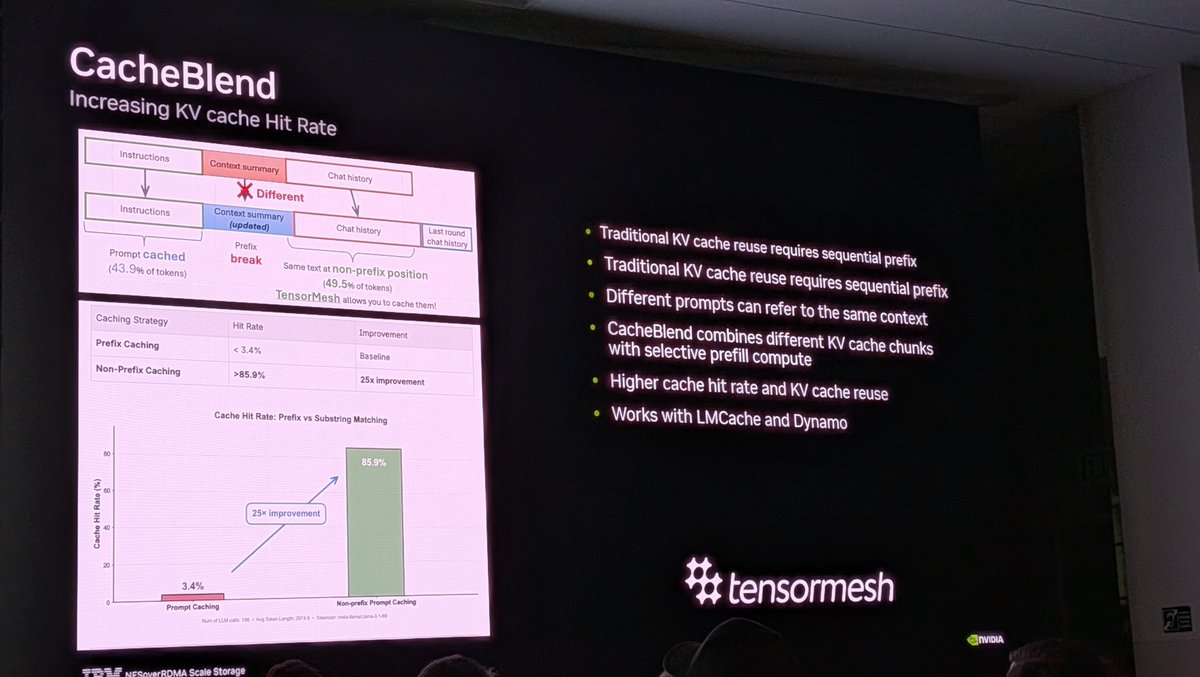
1
124
Kuntai Du retweeted

Mar 17
🔴 Live from #GTC2026
On the floor with our Chief Scientist @this_will_echo and CTO #Yihua Chang — #KVCache is the hottest topic of the day. Even Jensen opened with it.
🎙️They covered topics like:
#CacheBlend, @lmcache 0.4.0. and the super cool collab with @nvidia around a bot called #reachy using LMCache under the hood for 20x speedup
#GTC2026 #KVCache #LMCache #TensorMesh
3
14
462
Jan 14
By offloading KV caches to SSD, we managed to reduce the time-to-first-token for @gmi_cloud without ANY extra infra cost!
Jan 2

Happy 2026 🥂
First post of the year: a technical benchmark.
In a joint study with @tensormesh , we achieved:
- 4× TTFT improvement
- Prefix cache hit rate >50%
Using SSD-augmented KVCache on realistic multi-turn LLM traffic.
Full write-up on GMI Cloud: gmicloud.ai/blog/gmi-cloud-a…
2
382
Kuntai Du retweeted

10 Dec 2025
🚀 LMCache has officially been out for 1.5 years now!
Within its success, LMCache has become the default KV-cache library for open-source LLM inference (CPU offload, P2P sharing, multi-backend storage, vLLM/SGLang integration, and more).
As a PyTorch Foundation Ecosystem project, LMCache is now used by enterprise leaders across the industry (GKE, AWS, Nvidia's Dynamo, llm-d…).
🤔What’s the secret to our product??
🔎 Come see yourself: arxiv.org/pdf/2510.09665
♥️ A huge thank you to our contributors and community, you’ve influenced what makes LMCache today. (@lmcache)
#KVCache #LMCache #LLM #vLLM

5
2
16
1,644
18 Nov 2025
Github is not acting normal...
Our LMCache logo suddenly disappeared today, we didn't make any change. And we cannot even clone the repo using ssh.
Github bad bad.
208