
heheheheheheehehe
Joined August 2021
- Tweets 107
- Following 141
- Followers 67
- Likes 215
10 Photos and videos







Wrote an annotated Triton implementation of Flash Attention 2. (Links in reply)
This is based on the flash attention implementation by the Triton team. Changed it to support GQA and cleaned up a little bit.
Check it out to read the code for forward and backward passes along with the math and derivations. Hope this helps understand transformer attention and flash attention better.
There's about 60 more annotated deep learning paper implementations on this website.
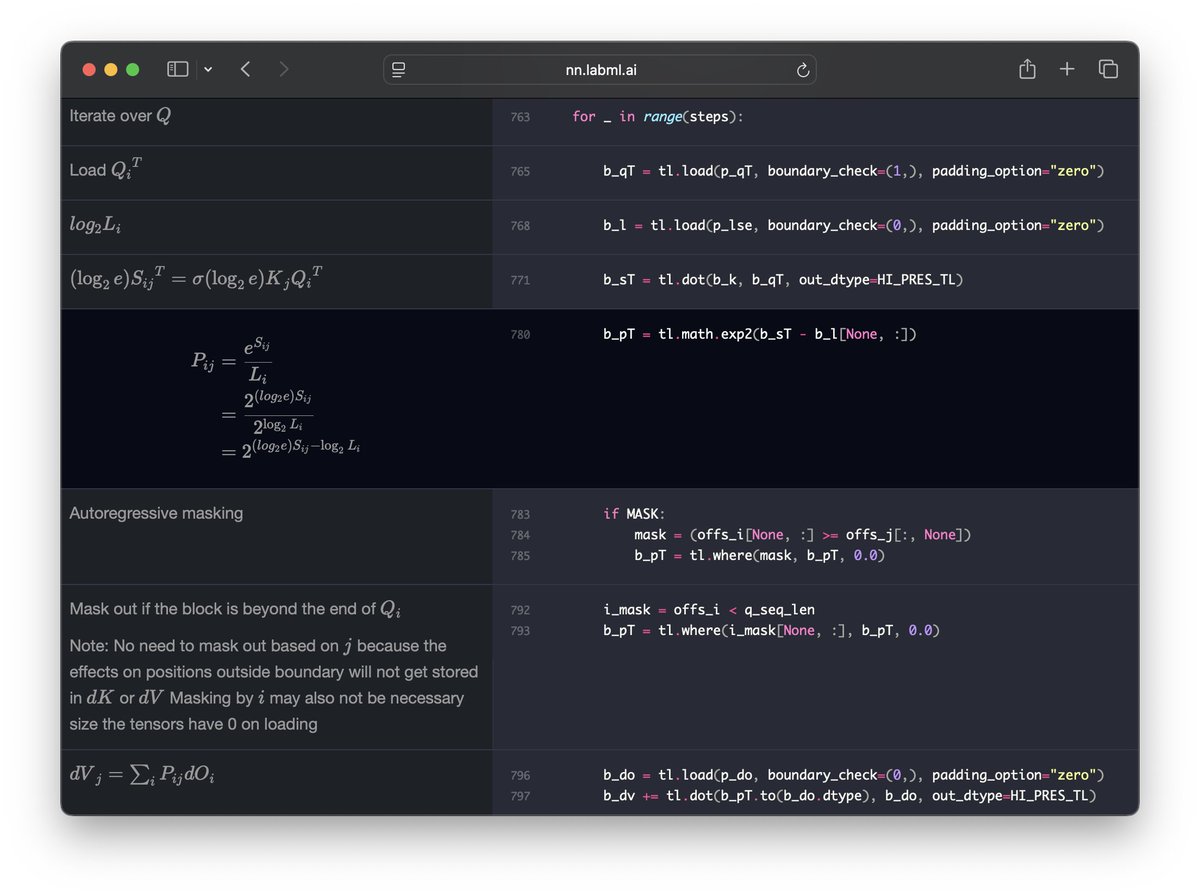
ALT The annotated code. Click on math symbols or identifiers to highlight them.
3
9
47
4,359

21 Jun 2025
Letting co-pilot comment on my pull request and then replying to those comments and resolving them makes me feel like a Schizophreniac . But honestly, some of the suggestions are legit useful, so I’m just gonna keep doing that.
49
hehehehe retweeted

6 Jun 2025
docker is supposed to solve the "works on my machine" problem
but often I find that it just adds another layer to the "works on my machine" problem esp if you use a mac
178
94
3,190
184,561
2 May 2025
I mean, it’s your app.

4
313
2 Mar 2025
Going to save this and reply to chat gpt posts on LinkedIn


89
hehehehe retweeted

25 Feb 2025
> I made <thing> from scratch in Python!
>look inside
>import <thing>


Works!
Made a WebSocket server from scratch in Python with Grok 3
Now need to make it work properly in the flight sim!

82
435
10,623
375,703


21 Dec 2024
I need to let a LLM "talk" to swift core data. Need a language both the DB and the LLM talks so the obvious solution is SQL. SQL won't work on a key value store though. I wonder how hard would it be to write a SQL like driver for core data.
#DoingdumbShitTillImNotDumbAnymore
1
64
21 Dec 2024
Being dumb off to a great start. Apparently there's a thing called Predicates on core data. Like a poor man's SQL. Entire chain of thought wasted 👍
40
hehehehe retweeted

20 Dec 2024
CS grads on suicide watch
60
217
3,825
326,824

hehehehe retweeted

20 Nov 2024
No it isn’t. That’s the whole point

245
593
21,026
2,005,206


5 Nov 2024
“Oh thanks. Didn’t notice that”


1
50
19 Oct 2024
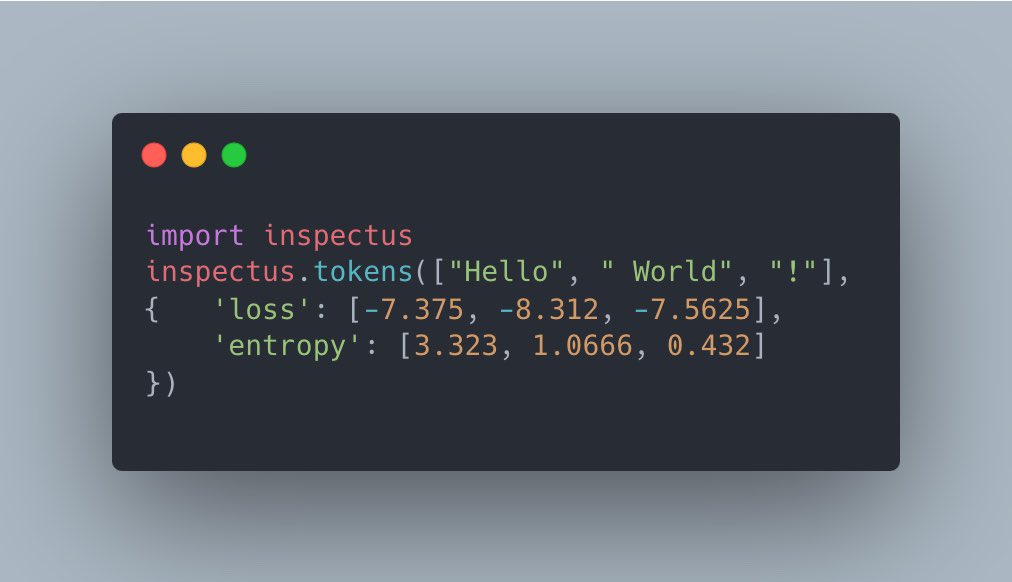
Now Our visualization library Inspectus can visualize values related to tokens in LLM outputs. This demo shows some outputs from using entropyx (by @_xjdr) on Llama 3. Had fun making this. (jk I didn’t)
🔗👇
1
1
6
1,745
19 Oct 2024
Pip package: pypi.org/project/inspectus/
Docs: labmlai.github.io/inspectus/
Github: github.com/labmlai/inspectus

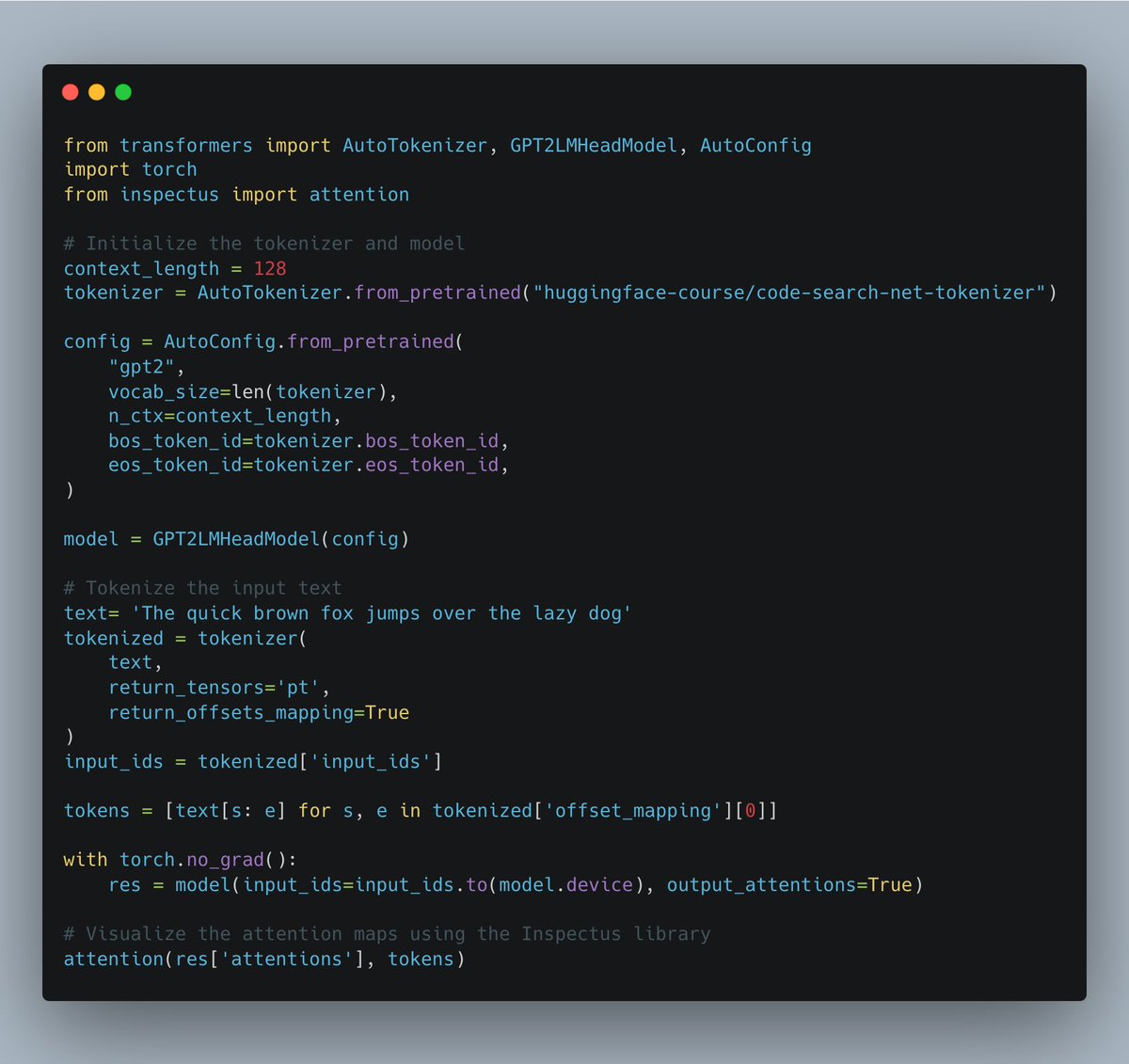
We’ve open-sourced our LLM attention visualization library. It generates interactive visualizations of attention matrices with just a few lines of Python code in notebooks.
@luck_not_shit cleaned up and polished the existing code to make it open source.
112