
Principal Engineer, Founder @AICTechPro | Obsessed with local AI & MLX on Apple Silicon.
Joined May 2009
- Tweets 213
- Following 352
- Followers 270
- Likes 360
19 Photos and videos














Jun 11
#WWDC26 was the biggest local AI release Apple has ever shipped. I build local AI on macOS with MLX, so I went through the sessions, the docs, and the GitHub repos. Here's what actually changed.
The context: Apple already had the pieces. The Foundation Models framework arrived last year with an on-device model. MLX, Apple's open source machine learning framework, has powered local models on Macs since late 2023, and its biggest performance advances quietly shipped months before the keynote.
What's new is that Apple connected everything.
The Foundation Models framework now accepts any model, not just Apple's. One protocol, one session API, and the model behind it becomes a swappable choice: Apple's on-device model, a bigger Apple model running on Private Cloud Compute, open source models via MLX, or your own custom weights through Core AI, a brand new framework for running your own models on device with a ready catalog that includes Qwen and Mistral.
The framework also went agentic. Dynamic Profiles lets one session switch models, tools, and instructions on the fly. Models can now see images, read text and barcodes through the camera, and search your Mac with Spotlight for fully local retrieval. A new command line tool brings all of it to scripts.
And Apple put real weight behind open source. The Core AI model implementation is already on GitHub, and a new Apache licensed utilities package adds agent skills, conversation memory management, and a bridge that lets any local model server plug into Apple's API. Even the developer tools caught up, with new Instruments profiling for on-device models and Xcode connecting directly to a local MLX server.
Add it up and there are more ways to run a local model on a Mac than ever: Apple's own, open source models, custom weights, a local server, even a cluster of Macs working as one. No cloud account required for any of it.
Local AI on Apple platforms is now a platform strategy, not a side project.
5
5
59
5,306
Jun 10
Built a playground app to show what Apple announced at #WWDC26: the Foundation Models framework driving an open-source MLX model (Qwen3.5-4B via MLXLanguageModel) and Apple's on-device model through the same LanguageModelSession. One picker switch, downstream untouched. Live TTFT / tok/s / token counts from the framework's Usage API. MLX via AFM, huge for local AI on Apple platforms.
Test rig: M3 Ultra (32 cores), 512 GB, macOS 27.0 (26A5353q).
5
3
16
3,101
Jun 10
1
130
Malek Ould-Oulhadj retweeted

Jun 10
Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
168
808
5,018
917,188
Jun 9
Our quick-invoke feature looks a bit like the new Siri AI on macOS 27. 😄 Months in the making, and near launch. Good timing!
Ask it anything and it acts across Calendar, Files, Photos, Music, web, and smart home, all on your Mac. Fully local, running Qwen and Gemma models.
Great minds think alike. 🤝
Bravo, Apple 👏 for all the announcements and the leap forward with Siri AI. #WWDC26
4
350
Malek Ould-Oulhadj retweeted
Jun 3
When you consider how the brain generates thoughts and predicts what comes next, then draw the analogy to generative AI and next-token prediction, thinking starts to look less like magic and more like a very powerful process running on billions of neurons. So is AI consciousness really that different from human consciousness? Maybe the gap is just sensory; there are channels of human perception that AI does not have access to yet, and perhaps those cover the parts of consciousness we still do not fully understand.
2
1
6
278
May 31
"Design is not just what it looks like and feels like. Design is how it works." — Steve Jobs. For years, the gap between a great idea and a shipped product was engineering capacity. You could see the vision clearly in your head and still spend months, or never get there at all, because building it required a team you didn't have.
That gap is closing fast. AI coding agents are turning product thinkers into builders. Not by writing snippets you paste into a file, but by operating at the level that actually matters: architecture. You describe the system, the constraints, the way it should work, and the agent reasons through the structure with you. This is architectural coding. You stay focused on how it works while the agent handles much of how it gets built.
What excites me most is who this unlocks. The people with the sharpest sense of how a product should feel and behave were often the furthest from the code. Now they're the closest. The bottleneck was never their imagination. It was access.
We're about to see a wave of dream projects come to life. Things that lived in notebooks and half-finished prototypes for years. Things that one person could never build alone, and now can.
If you've been sitting on an idea, this is the moment to build it.
What have you been waiting to make?
3
71
Apr 30
This is a huge contribution to interpretability research. Thanks @Alibaba_Qwen 🙏
Apr 30

Today we’re releasing Qwen-Scope 🔭, an open suite of sparse autoencoders for the Qwen model family. It turns SAE features into practical tools:
🎯 Inference — Steer model outputs by directly manipulating internal features, no prompt engineering needed
📂 Data — Classify & synthesize targeted data with minimal seed examples, boosting long-tail capabilities
🏋️ Training — Trace code-switching & repetitive generation back to their source, fix them at the root
📊 Evaluation — Analyze feature activation patterns to select smarter benchmarks and cut redundancy
We hope the community uses Qwen-Scope to uncover new mechanisms inside Qwen models and build applications beyond what we explored.Excited to see what you build! 🚀
🔗🔗
Blog: qwen.ai/blog?id=qwen-scope
HuggingFace: huggingface.co/collections/Q…
ModelScope: modelscope.cn/collections/Qw…
Technical Report: qianwen-res.oss-accelerate.a…

1
1
2
377
Apr 27
Capital can buy AI talent. It can't buy what makes that talent creative. A thread on what frontier labs keep missing 👇

2
68
Apr 3
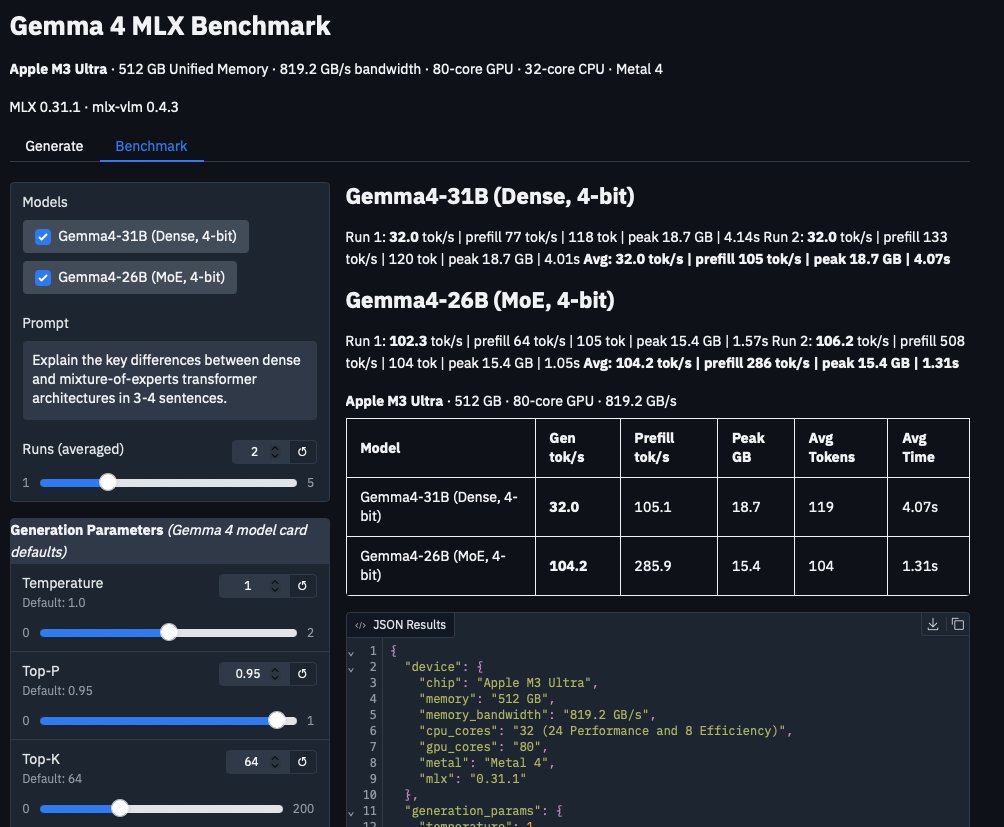
Gemma 4 MLX benchmarks on M3 Ultra, fully local.
26B MoE: 104 tok/s, 3.3x faster than the 31B dense (32 tok/s) 286 vs 105 tok/s prefill. 3 GB less memory.
Outstanding work by @GoogleDeepMind on Gemma 4. The MoE architecture is genuinely impressive, quality and efficiency at this level running fully on-device. Thanks to @Prince_Canuma for the MLX conversions.
Benchmarked here with Python mlx-vlm. We're also building a macOS app powered by MLX Swift with agentic tool calling, currently in development. More tests soon.
1
2
165
Malek Ould-Oulhadj retweeted

Hybrid AI is the way to go! 🤷🏻♂️
I've been running LLMs locally on Apple Silicon for over two years now. In @CoreViewHQ, in my investment company and for my family usage.
Inference, classification, clustering, fine-tuning, agentic coding, chat all on Mac Studios that sit on my desk.
No cloud dependency. No data leaving the building. Total privacy. 💪
With M5 Ultra pushing unified memory further, the gap between "local" and "data center" will be even lower. Most companies don't need a GPU cluster. They need a Mac Studio and the right stack of software to make the magic happen.
Apple's AI play isn't Siri. It's Apple Silicon. Are you ready? 🚀

7
8
138
7,519
Mar 26
There is a lot of LLM intelligence spent adapting traditional tools to the AI era, developing apps overnight by frontier labs to kill competition, and chasing money-making trends. Instead, this intelligence should be fulfilling its long-promised potential for humanity: health and wellbeing research, learning how to evolve in harmony together, and focusing on breakthroughs with what we’ve already achieved rather than trying to kill others’ creativity and coexistence.
1
69
Mar 25
Google's TurboQuant is a genuine breakthrough for local AI. Here's what it actually does and doesn't do, since there's been some confusion.
When an LLM processes your conversation, it stores keys and values for every token it's seen. That's called the KV cache, and it grows fast. Long conversations eat memory quickly, slow down, and eventually hit a wall.
TurboQuant shrinks that KV cache from 16 bits down to about 3 bits per value with minimal to zero quality loss. No retraining. No new model files. Just smarter compression at inference time. The paper demonstrates a 6x reduction in KV cache memory.
What it does:
→ 6x smaller KV cache memory footprint
→ Significantly longer conversations before running out of memory
→ Works with your existing models, nothing to re-download
What it doesn't do:
→ Make models smaller to download or load. A 32GB model still needs 32GB.
The real story: if you run models locally, your biggest constraint after loading the model is how much context you can fit before memory runs out. TurboQuant pushes that limit way back.
Credit to Google for publishing this openly instead of keeping it internal. This benefits everyone running local AI.
1
1
97
Mar 24
We've been building a native MLX macOS app that runs large language models entirely on your Mac. No cloud. No API keys. No subscriptions. Fully private and secure.
Think Qwen 3.5 models running locally, optimized for full agentic workflows with tool integration: Calendar, Reminders, Files, Music, Web Search, Home automation, and more.
Built for Apple Silicon. LLMs run fully on-device with Swift MLX.
Multiple ways to interact with your local model: the Mac app directly, a paired iPhone remote app, or server APIs for custom integrations.
We're getting close to our first release on the Mac App Store and looking for beta testers.
Drop a reply or DM if you want early access.
1
1
2
213
Feb 20
Instantaneous AI at 17K tokens/sec per user. When hardware and software hug each other, it’s a huge breakthrough.
Feb 19

24 dedicated people.
$30M spent on development.
Extreme specialization, speed, and power efficiency.
Today we launch Taalas’ first product. Check it out:
Details: taalas.com/the-path-to-ubiqu…
Demo chatbot: chatjimmy.ai
API: taalas.com/api-request-form/
3
369
Feb 12
Two Mac Studios just landed. M3 Ultra. 512GB unified memory per machine. The AI lab is getting serious. Running the biggest models locally. No cloud, no compromise. Developing in MLX, built for Apple Silicon from the ground up. Shoutout to @awnihannun @ActuallyIsaak and the MLX community for building an incredible foundation. We'll be building on it.
56
21
489
58,851