
Researching the dark arts of deep learning at Meta's FAIR (Fundamental AI Research) Lab
Joined December 2012
- Tweets 85
- Following 1,643
- Followers 512
- Likes 255
9 Photos and videos




Mark Ibrahim @ICLR 2026 retweeted

Apr 24
Don’t miss @dohmatobelvis presenting our latest work, “Why less is more (sometimes): A theory of data curation” at #ICLR2026!
Swing by our poster at the main conference to chat:
📅 Saturday, April 25
🕒 3:15pm–5:45pm
📍 Pavilion 3, P3-#1816
8 Nov 2025

New @AIatMeta paper explains when a smaller, curated dataset beats using everything.
Standard training wastes effort because many examples are redundant or wrong.
They formalize a label generator, a pruning oracle, and a learner.
From this, they derive exact error laws and sharp regime switches.
With a strong generator and plenty of data, keeping hard examples works best.
With a weak generator or small data, keeping easy examples or keeping more helps.
They analyze 2 modes, label agnostic by features and label aware that first filters wrong labels.
ImageNet and LLM math results match the theory, and pruning also prevents collapse in self training.
----
Paper – arxiv. org/abs/2511.03492
Paper Title: "Why Less is More (Sometimes): A Theory of Data Curation"

11
50
6,352
Come learn about computer-use agents with OpenApps, oral at #ICLR2026 in Rio 🇧🇷on Saturday 2:35pm ET Room 204 or stop by our poster in the morning iclr.cc/virtual/2026/oral/10… w/ @karen_ullrich
x.com/marksibrahim/status/19…
10 Dec 2025

Want to teach AI agents to use apps like humans? Get started with digital agents research using OpenApps, our new Python-based environment.
2
170
Mark Ibrahim @ICLR 2026 retweeted
I am soon heading to Rio for #ICLR2026!
It is going to be a packed week: including an oral presentation of OpenApps, our work on measuring how reliable UI agents really are when the apps they interact with change.
1
1
25
1,633
Mark Ibrahim @ICLR 2026 retweeted

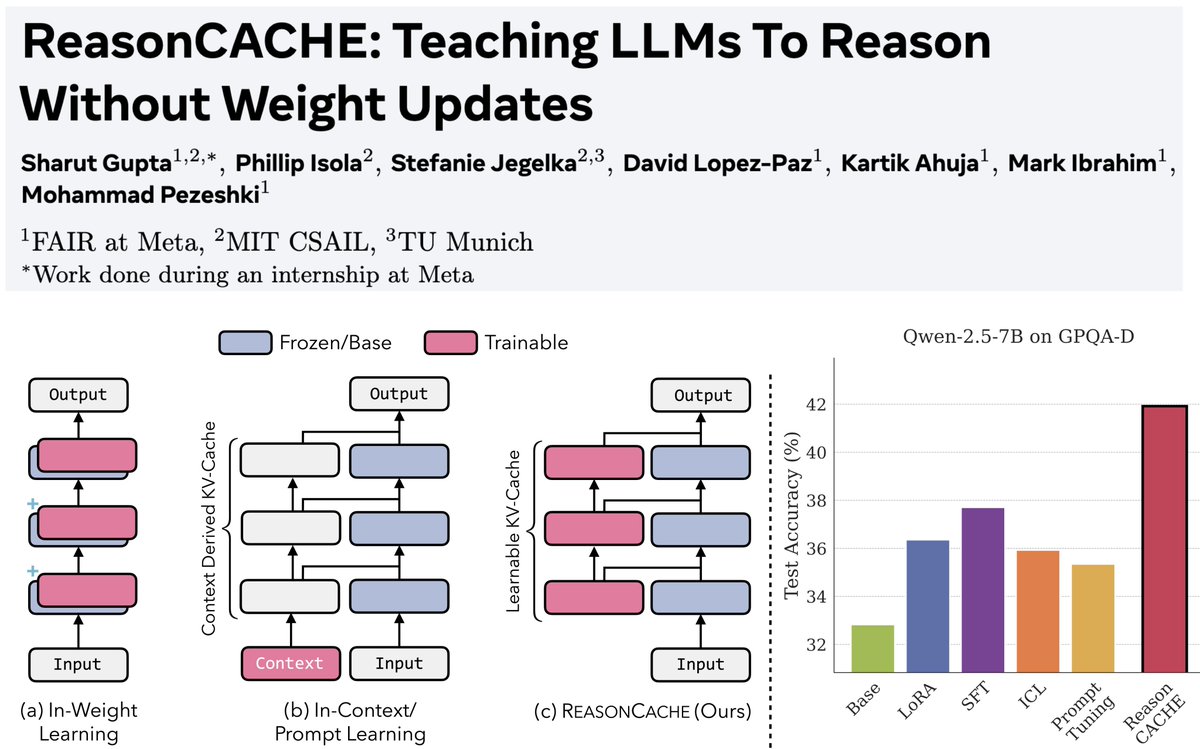
1/n Can LLMs learn to reason on hard benchmarks like AIME and GPQA purely through context, without SFT, RL, or any weight updates?
Turns out… Yes! And it can have strong performance while being highly efficient
Paper: arxiv.org/pdf/2602.02366
Blog: reasoncache.github.io/
4
35
204
17,724
Mark Ibrahim @ICLR 2026 retweeted

Feb 5
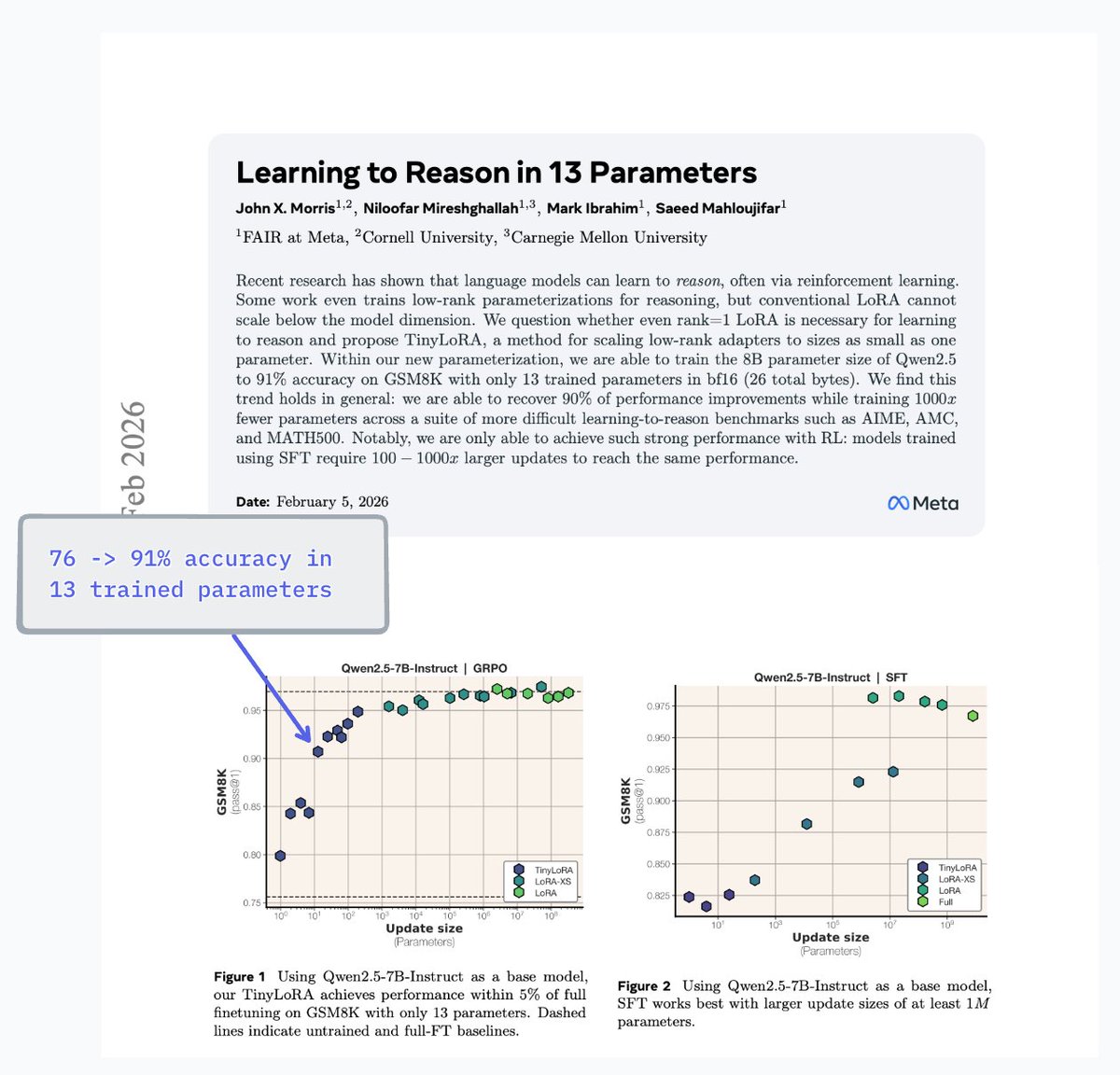
at long last, the final paper of my phd
🧮 Learning to Reason in 13 Parameters 🧮
we develop TinyLoRA, a new ft method. with TinyLoRA RL, models learn well with dozens or hundreds of params
example: we use only 13 parameters to train 7B Qwen model from 76 to 91% on GSM8K 🤯
60
230
2,043
182,448
Mark Ibrahim @ICLR 2026 retweeted

Jan 12
My first PhD paper is out! 🎓
"What Drives Success in Physical Planning with Joint-Embedding Predictive World Models?"
tl:dr: JEPA-WMs for robotics: learn dynamics on top of visual encoders, optimize actions towards goal 👇
w/ @JimmyTYYang1, Jean Ponce, @AdrienBardes, @ylecun
14
111
942
146,562
Mark Ibrahim @ICLR 2026 retweeted

10 Dec 2025
Release Day 🎉
Meet OpenApps — a pure-Python, open-source ecosystem for stress-testing UI agents at scale.
Runs on a single CPU. Generates thousands of unique UI variations. And it reveals just how fragile today’s SOTA agents are.
(Yes, even GPT-4 and Claude struggle.)
3
17
34
9,978

10 Dec 2025
Want to teach AI agents to use apps like humans? Get started with digital agents research using OpenApps, our new Python-based environment.
1
10
29
10,022
10 Dec 2025
1
3
284
10 Dec 2025
in collaboration with the excellent research team at FAIR: @karen_ullrich Jingtong Su @randall_balestr @_amirbar Claudia Shi, Arjun Subramonian, Nikolaos Tsilivis, Ivan Evtimov, adn @KempeLab
1
6
1,057
Mark Ibrahim @ICLR 2026 retweeted
3 Dec 2025
Stop by the Meta booth tomorrow, Wednesday Dec 3rd at #NeurIPS in San Diego! 🤖📱
We demo our new research environment, OpenApps, for digital agents. Generate thousands of app versions to train and evaluate multimodal agents to use apps like humans do.
Not attending? Stay tuned

1
2
9
938
Mark Ibrahim @ICLR 2026 retweeted

21 Nov 2025
With LeJEPA (arxiv.org/abs/2511.08544) it has never been easier to train JEPAs! And this matters A LOT because JEPAs have numerous provable benefits over the good-old reconstruction based methods (arxiv.org/abs/2505.12477).
NeurIPS spotlight: Wed, 11 a.m. PST, Hall C,D,E #2613
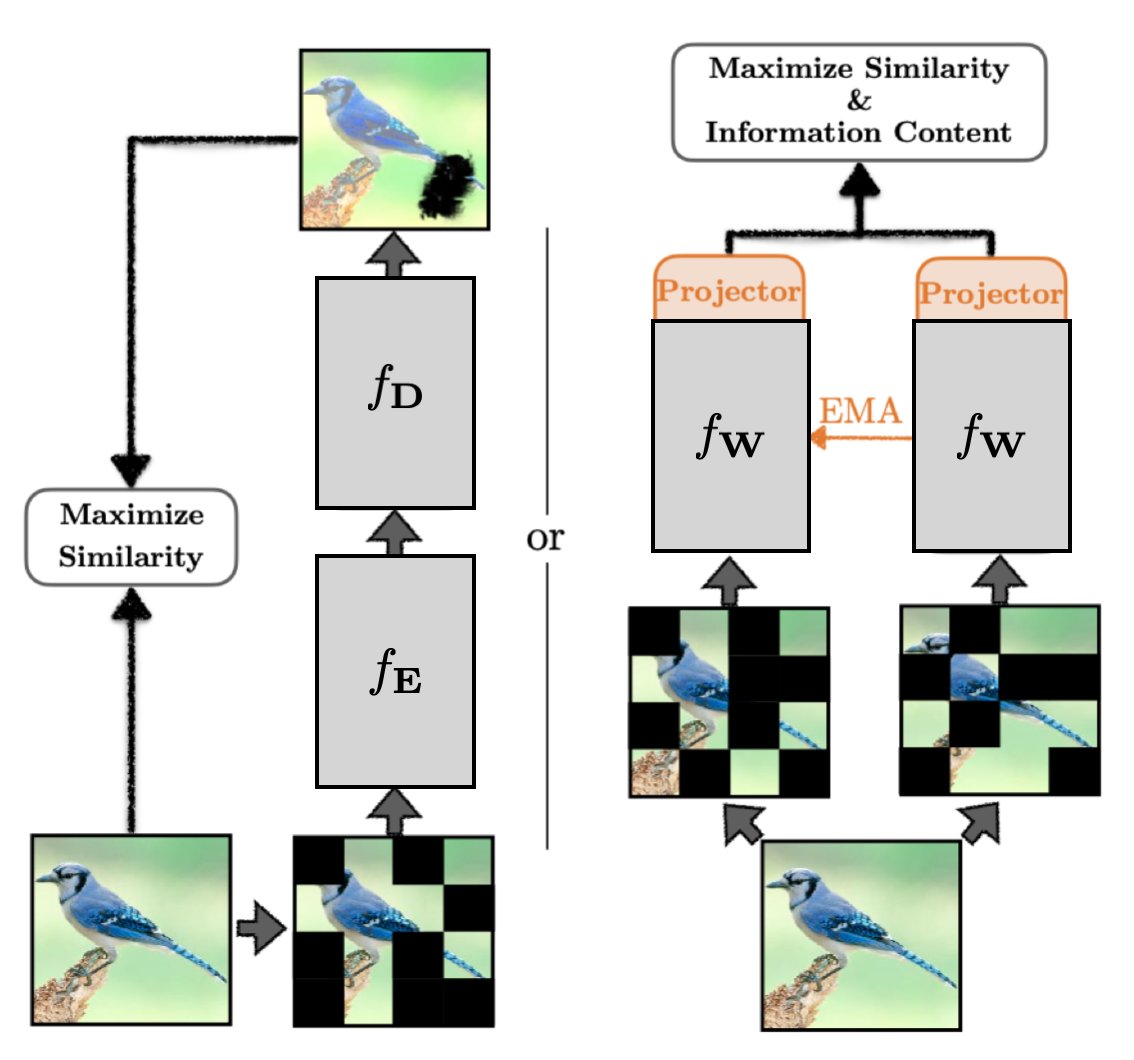
20 Nov 2025

Lots of discussion around JEPA and why latent space prediction works better than input space (e.g., LLMs) for certain modalities.
But no one has formalized WHY.
The answer lies in whether statistically dominant features are semantically meaningful.
@NeurIPSConf spotlight 🧵👇
12
60
445
86,125
7 Nov 2025
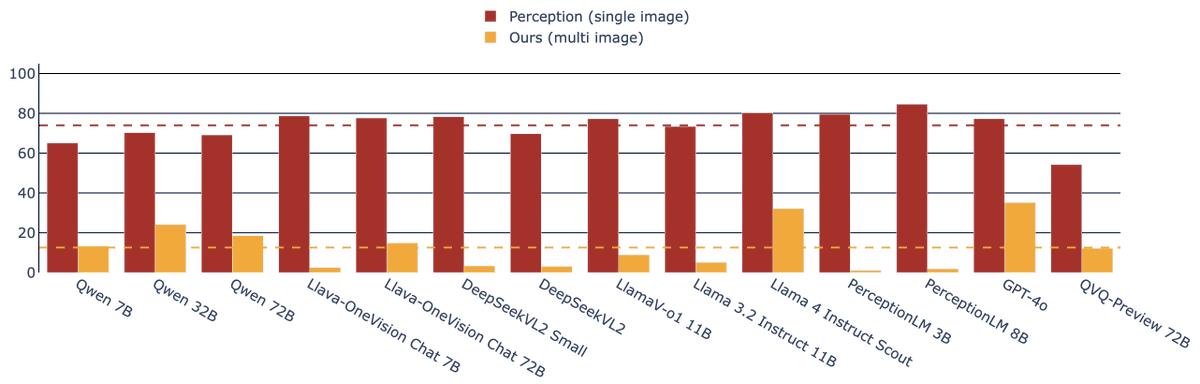
We introduce, Common-O, a new multimodal benchmark for hallucination when reasoning across scenes.
We find leading multimodal LLMs can reliably identify objects, yet hallucinate when reasoning across scenes.
🧵1/3
1
2
11
3,642
7 Nov 2025
Despite saturating single image perception, Common-O establishes a new challenging multimodal benchmark. The best performing model only achieves 35% on Common-O and on Common-O Complex, consisting of more complex scenes, the best model achieves only 1%.
🧵2/3
1
2
150
7 Nov 2025
✅ 22k multi-scene questions
✅ New scenes not in existing web data
✅ Runs in ~15 min on one GPU
Work led by Candace Ross in collaboration with Florian Bordes, @adinamwilliams, and @polkirichenko .
Check it out on HuggingFace & ArXiv: huggingface.co/datasets/face…
2
125
Mark Ibrahim @ICLR 2026 retweeted

18 Oct 2025
Meta on meta: thrilled to share our work on Meta-learning… at Meta! 🔥🧠
We make two major contributions:
1️⃣ Unified framework revealing insights into various amortizations 🧠
2️⃣ Greedy belief-state updates to handle long context-lengths 🚀

5
31
224
45,908
16 Oct 2025
If you’re an NYU student, come learn about this wonderful opportunity to collaborate with us at FAIR events.atmeta.com/metanyuaim… Panel is tomorrow 10am at NYU Center for Data Science.
6
41
4,304
Mark Ibrahim @ICLR 2026 retweeted

14 Oct 2025
RL has led to amazing advances in reasoning domains with LLMs.
But why has it been so successful, and why does the length of the response increases during RL? In new work, we introduce a framework to provide conceptual and theoretical answers to these questions.

2
14
61
5,029