
Graduate Student at @Mila_Quebec and Student Researcher at @GoogleResearch. Previously interned at @Meta @Apple @MorganStanley @NVIDIAAI and @YorkUniversity
- Tweets 350
- Following 921
- Followers 1,057
- Likes 272
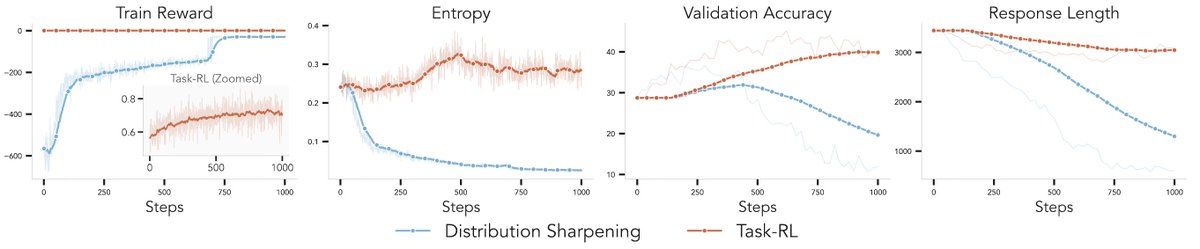
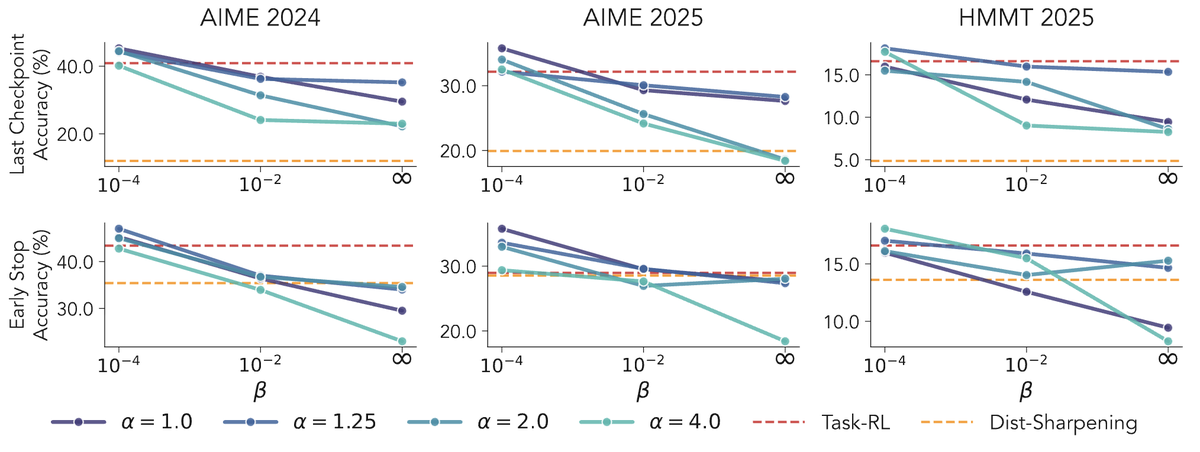
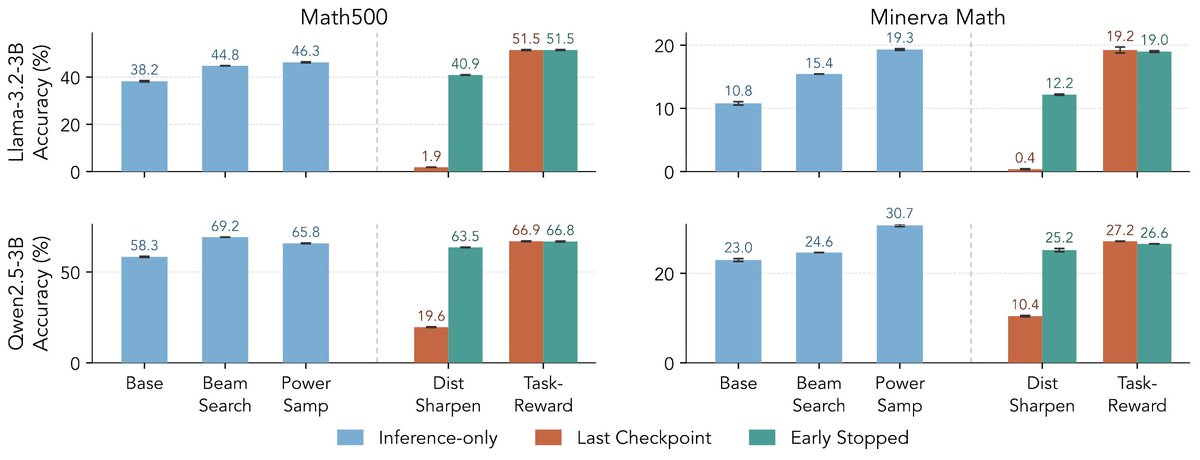
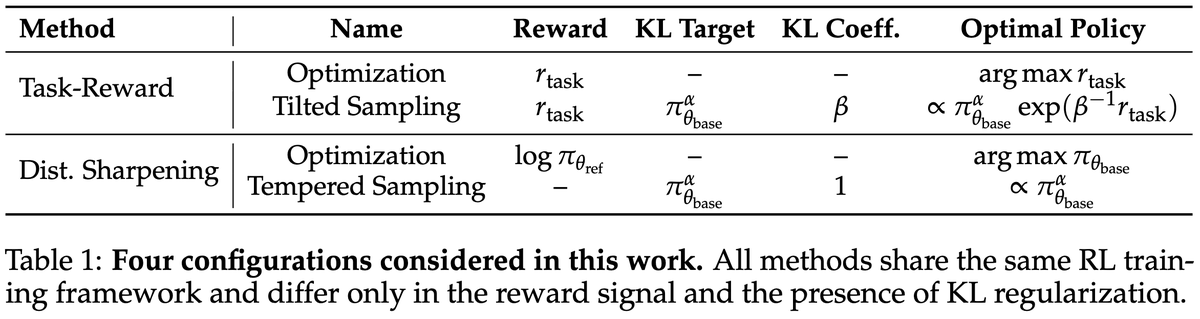
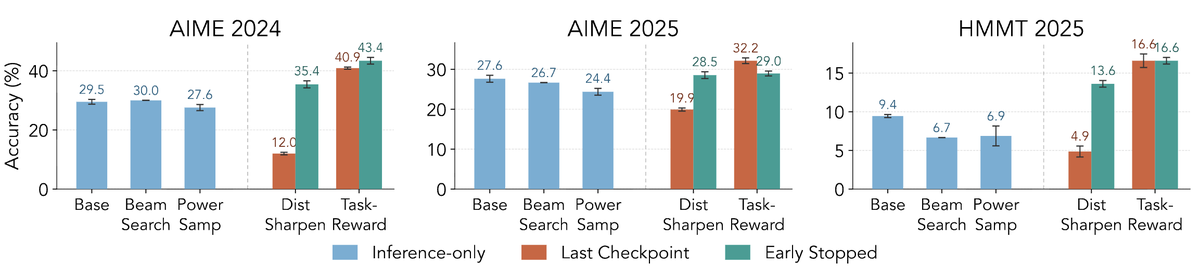
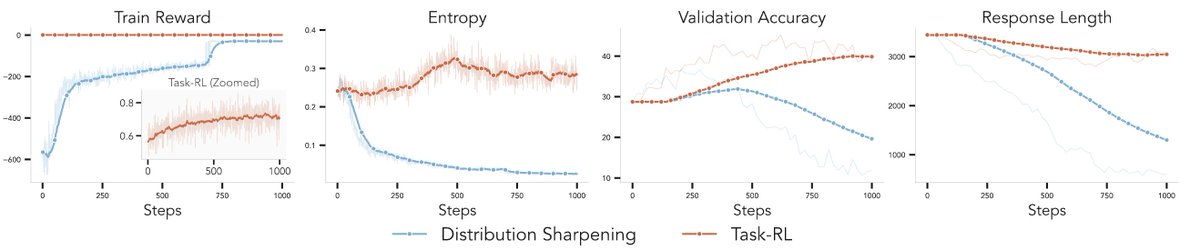
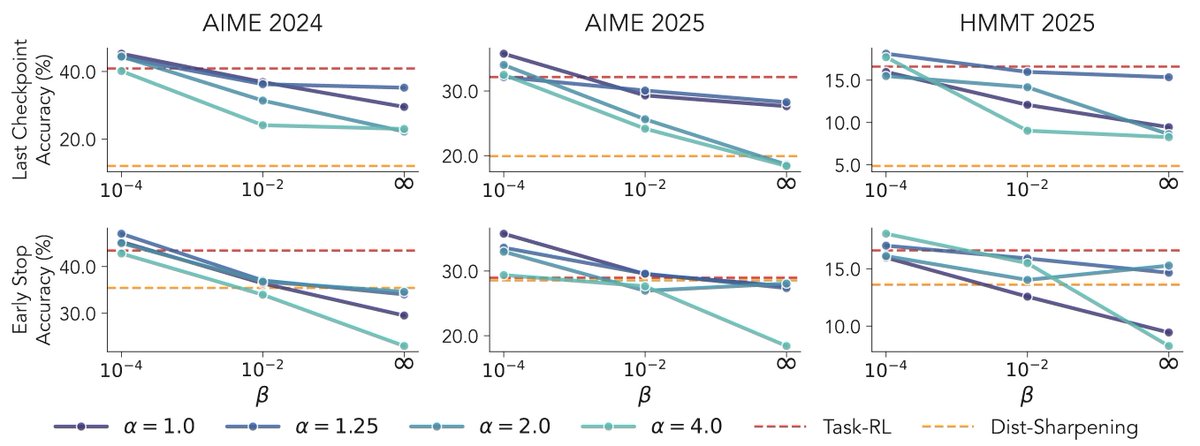

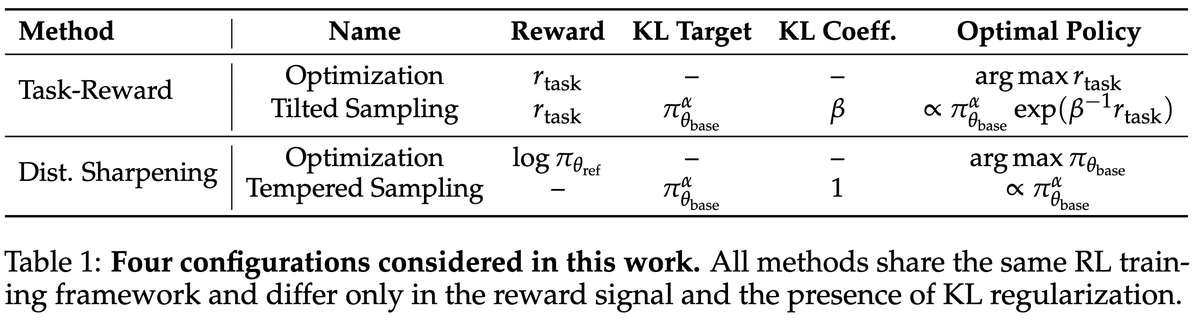
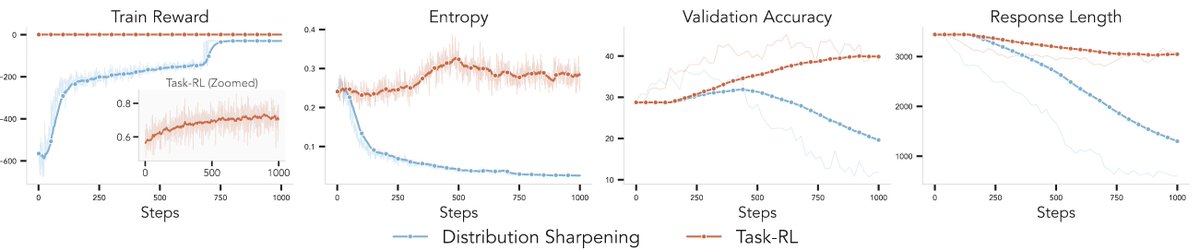
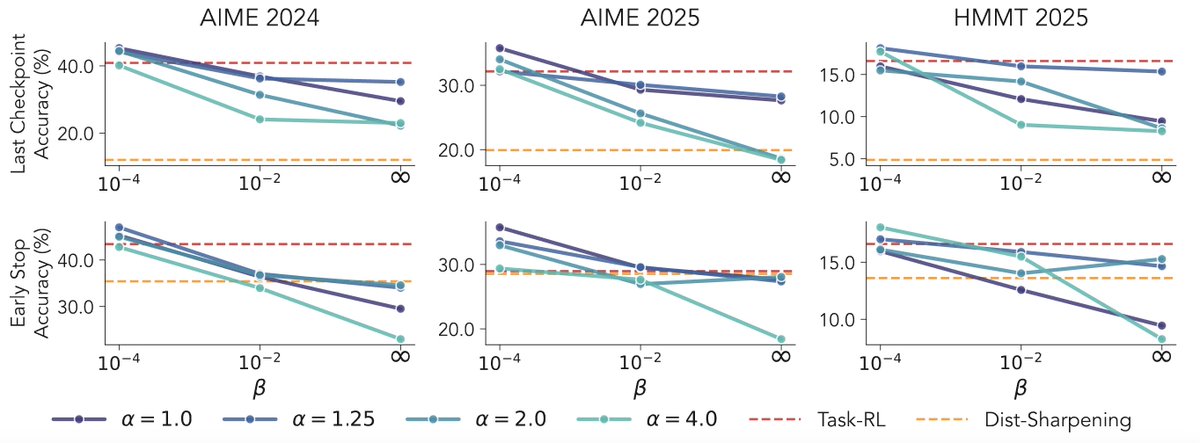
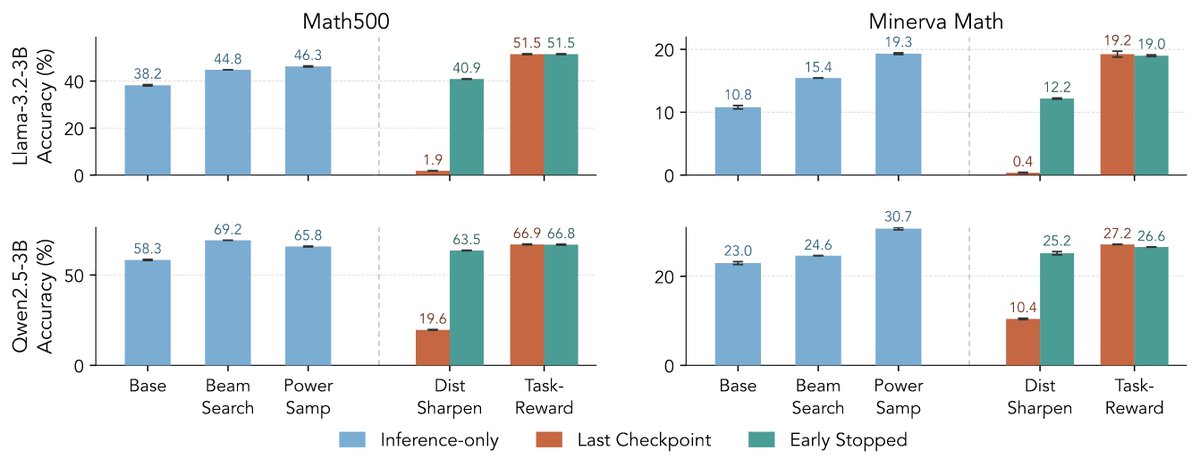
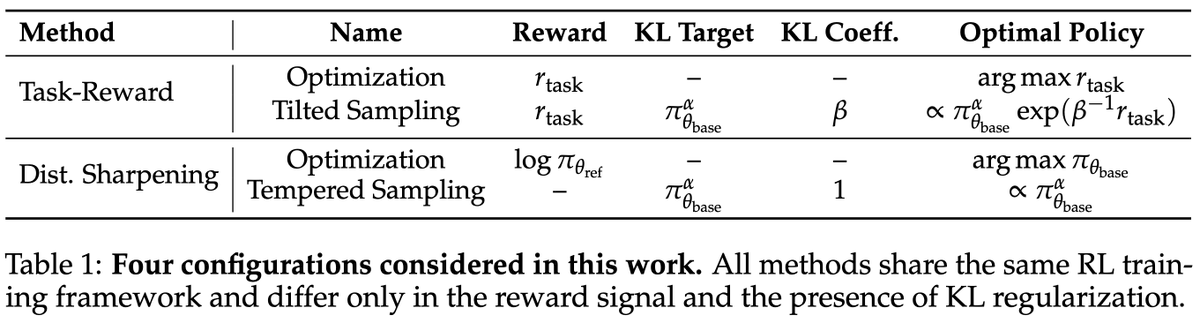

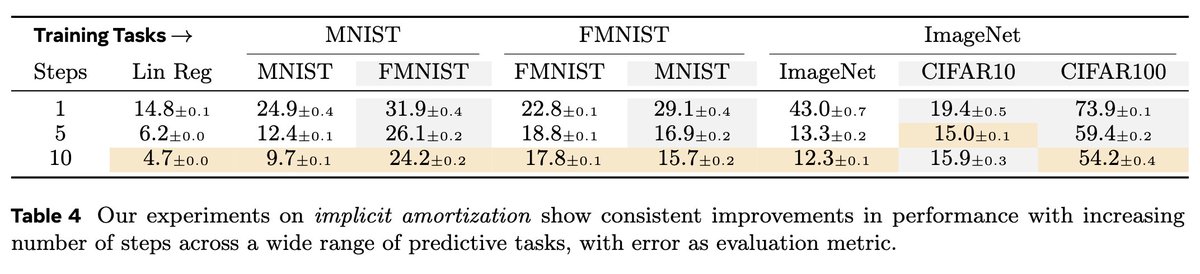
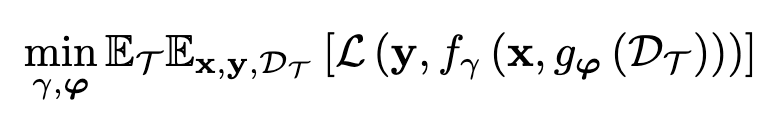




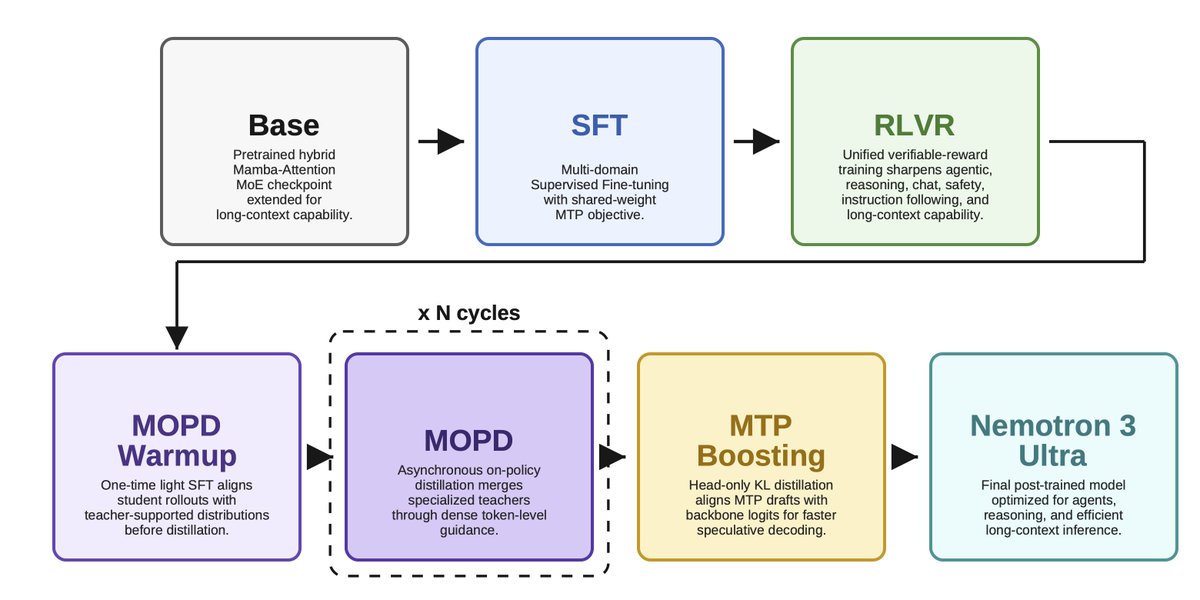
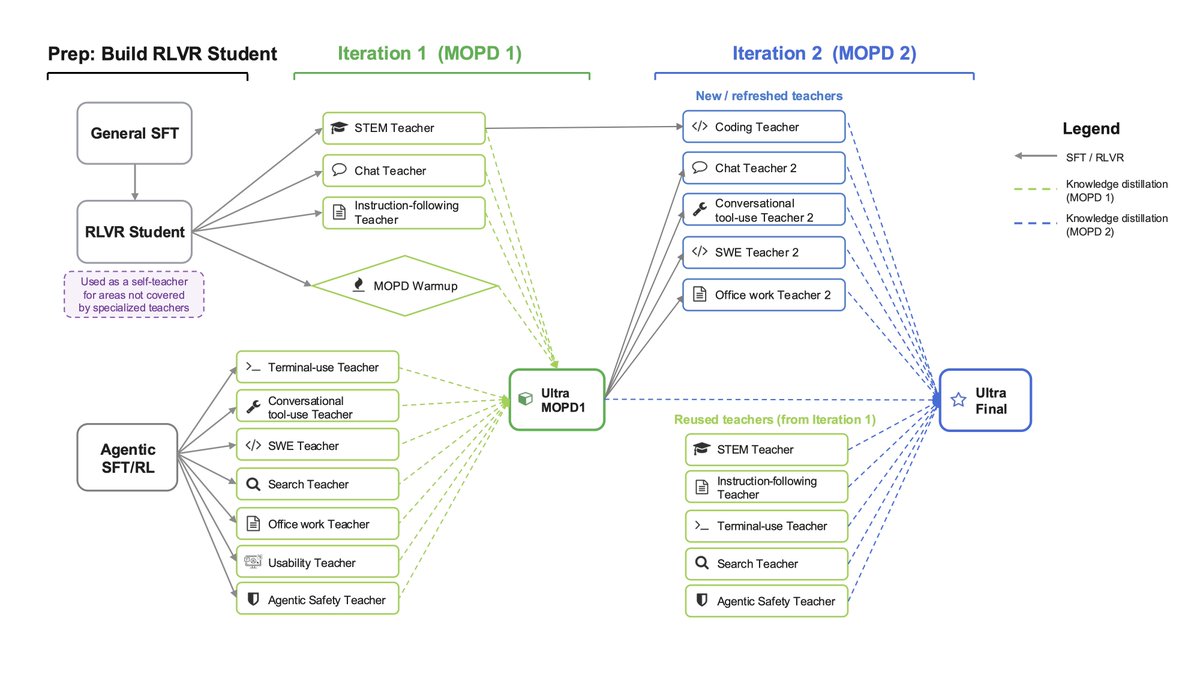


ALT Modern language models operate within finite context windows, yet many real-world tasks require models to absorb, retain, and act on information that far exceeds any single prompt. This workshop addresses the full spectrum of context management: fitting more into the window, maintaining state across interactions, and transferring knowledge into parameters. We frame this around the trade-off between context-time memory (information supplied at inference) and weight-time memory (information absorbed into parameters). Our goal is to build a shared vocabulary across subcommunities that rarely meet in one venue: long-context modeling, retrieval-augmented systems, continual learning, knowledge distillation, and LLM agents.



