
30 Photos and videos













Pinned Tweet

May 26
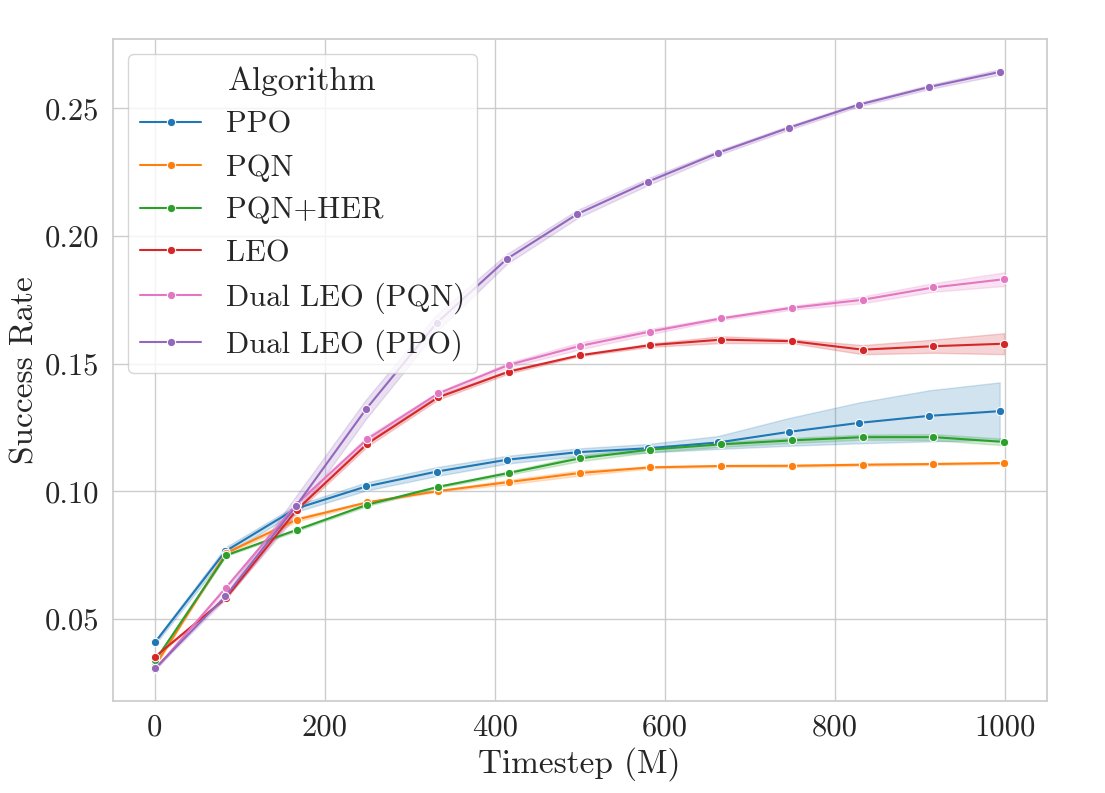
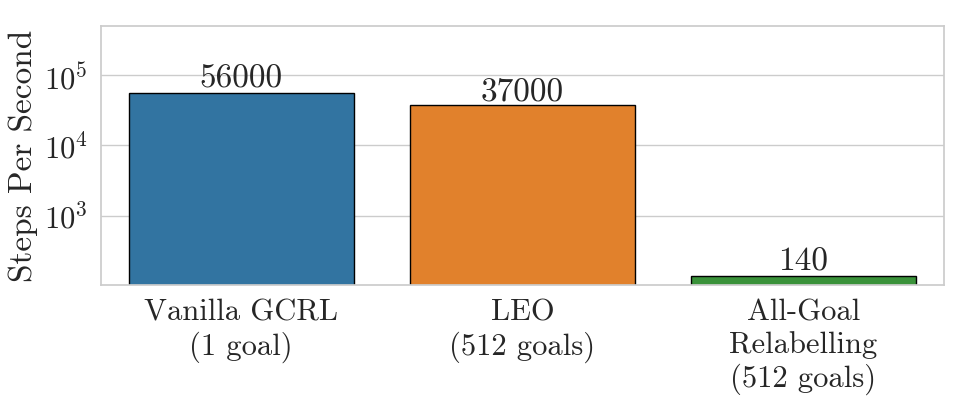
Hindsight Experience Replay has become the ubiquitous method for goal-conditioned reinforcement learning, but leaves open the question of which goal to relabel with.
In this work, accepted at ICML, we propose instead simply Learning Everything All at Once (LEO).
1/
4
31
211
25,193
Michael Matthews retweeted

Mean Field Games provide a framework for modelling large populations.
ICML26 Spotlight: Introducing Recurrent Structural Policy Gradient for partially observable MFGs with common noise, benefitting from faster convergence than model-free RL, but remaining tractable, unlike DP.

1
22
93
22,137
May 26
Hindsight Experience Replay has become the ubiquitous method for goal-conditioned reinforcement learning, but leaves open the question of which goal to relabel with.
In this work, accepted at ICML, we propose instead simply Learning Everything All at Once (LEO).
1/
4
31
211
25,193
May 26
While the focus of our work is on finite goal sets, we also adapt LEO for continuous goal sets through goal quantisation, achieving competitive results with Hindsight Experience Replay in continuous control tasks.
8/
1
8
754
May 26
Work done at @FLAIR_ox with @JacksonMattT, @mcbeukman, Thomas Foster, @_aletcher, Scott Fujimoto, @cedcolas and @j_foerst.
Blog post: mtmatthews.com/blog/leo/
GitHub: github.com/MichaelTMatthews/…
Paper: arxiv.org/abs/2605.23551
end/
14
788
Michael Matthews retweeted

Happy to share that SOL has been accepted as spotlight to ICML :) come hear about SOL in Seoul!
1 Oct 2025

Introducing Scalable Option Learning (SOL☀️), a blazingly fast hierarchical RL algorithm that makes progress on long-horizon tasks and demonstrates positive scaling trends on the largely unsolved NetHack benchmark, when trained for 30 billion samples. Details, paper and code in >
1
2
32
3,232
Michael Matthews retweeted

Apr 16
RL researchers when they try to think of a name for their new algorithm:
Apr 16

what the procurement team at AllBirds, Inc. sees when they try to pay server OEMs with a $50M Convertible Financing Facility Agreement
11
26
267
33,550
Apr 17
Very well deserved! Can't wait to see what you work on there :)

Excited to announce I’ll be joining @EugeneVinitsky at @nyutandon this autumn for a PhD!
I will be working on the intersection of game theory, reinforcement learning, and autonomous vehicles.
Thanks to everyone who helped me get to this point, especially from @FLAIR_Ox :)
1
6
612
Michael Matthews retweeted

Mar 31
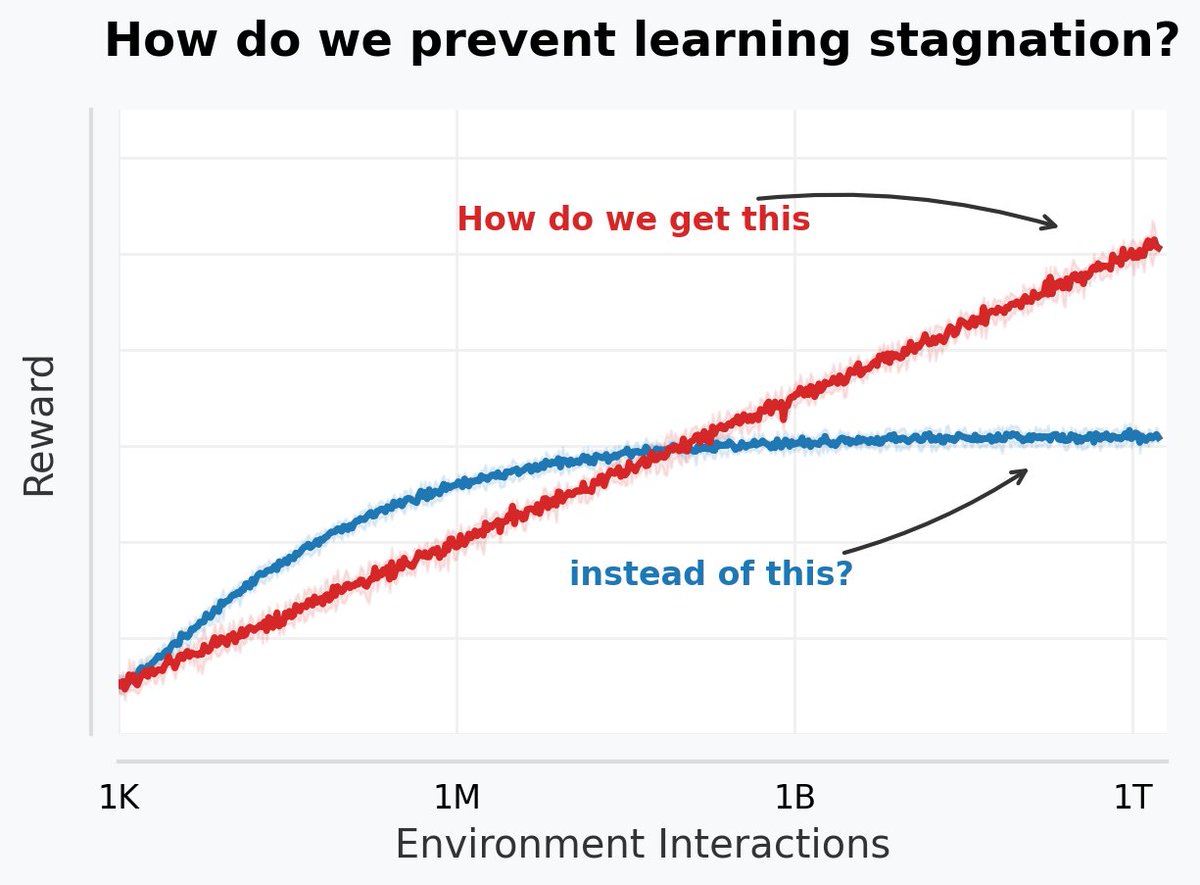
1/ As compute continues to grow and simulators continue to improve, it is becoming feasible to train RL agents for billions or trillions of timesteps. However, this is only useful if agents can continue learning over such long training horizons, which is far from given 👇
6
46
355
99,153
Michael Matthews retweeted

Mar 25
"The only unsaturated agentic intelligence benchmark in the world"
Excuse me? @NetHack_LE is unsaturated since 2020.

Announcing ARC-AGI-3
The only unsaturated agentic intelligence benchmark in the world
Humans score 100%, AI <1%
This human-AI gap demonstrates we do not yet have AGI
Most benchmarks test what models already know, ARC-AGI-3 tests how they learn
13
27
223
51,366
Michael Matthews retweeted

Feb 26
📢Current world models aren't really modeling the world; they're modeling one agent's view of it. Partial observations ≠ world state.
Future world models will be independent of any one agent's perspective. You will be able to “drop in” any number of agents at any point in time, and a persistent world state will evolve with their interactions. Imagine a neural MMORPG server. 🧵[1/10]
13
85
614
126,218
Michael Matthews retweeted

22 Apr 2025
Why did only humans invent graphical systems like writing? 🧠✍️
In our new paper at @cogsci_soc, we explore how agents learn to communicate using a model of pictographic signification similar to human proto-writing. 🧵👇
25
180
1,151
155,300
Michael Matthews retweeted

1 Dec 2025
🪩 So excited to reveal DiscoBench: An Open-Ended Benchmark for Algorithm Discovery! 🪩
It addresses the key issues of current evals with its broad task coverage, modular file system, meta-train/meta-test split and emphasis on open-ended tasks! 🧵
1
24
109
30,638
Michael Matthews retweeted

18 Nov 2025
My Oxford lab (@FLAIR_Ox ) is hiring Phd students! If you are thinking of doing a Phd in blue-sky and -sort of crazy ambitious- ML and have a technically strong background and love to work with others, please consider all options for joining us:
1) Direct entry - deadline is the 1st of Dec AOE (ox.ac.uk/admissions/graduate…)
2) AIMS CDT (ox.ac.uk/admissions/graduate…) deadline on 27th of Jan 2026 AOE
3) EIT CDT (ox.ac.uk/admissions/graduate…) deadline on the 7th of Jan 2026 AOE
Student funding is a real constraint / concern in the UK (especially for overseas students) and by applying for these three programs you can maximize your chances of ending up in a very very special place.
3
30
160
14,227
22 Oct 2025
Interning with Mikael has been one of the best experiences of my PhD - would highly recommend this opportunity to anyone!
21 Oct 2025
I'm looking for a PhD intern for next year, co-advised with Scott Fujimoto, for a project developing sample-efficient RL algorithms for long-horizon decision-making. If you've worked on off-policy/MBRL, hierarchical RL, embodied AI, we'd love to hear from you! Contact below.
11
3,125