
Learning how systems run fast
Joined October 2014
- Tweets 1,999
- Following 787
- Followers 1,634
- Likes 1,794
97 Photos and videos












Kimbo retweeted

current LLMs fundamentally consist of four main components:
- input layer: where input "words" (prompt) get mapped to "latents" aka some-model-representation-you-don't-understand-unless-you-start-reading-tea-leaves-of-spurious-correlations (some quite compelling à la word2vec style; latents is also unnecessary lingo so i will refer to these as "inputs" with quotes from now on)
- mixing layers: where you jumble all your "inputs" together to see if any correlations between "inputs" can become useful (commonly used to compress or expand dims; predicting a single classification target == compress to a single dim, etc)
- attention layers: where you learn how "inputs" relate to each other (aka discern what's important to remember vs fluff)
- residuals: where you short-circuit a mixing/attention layer because it's probably adding too much confusion (aka avoid overthinking for simple things)
-----
a "big" LLM simply scales two things:
- width == how many dimensions you give to your "inputs" (the more dims, in theory the more unique/discerning/precise/complex your knowledge can become)
- depth == how many mixing/attention/residual layers you can stack/loop between (aka "reason" over, where more of these ~= more "reasoning" abilities)
"capabilities" that seem impressive to humans usually arise from taking advantage of both depth & width: where a model seemingly makes connections between disparate ideas, beyond what an average human can hold in working memory.
this requires models to "completely light up" when responding to a "hard prompt", where effectively no param/layer goes unused.
-----
the anatomy of a "model capability" is precisely the same mechanism that can be co-opted for a jailbreaking exploit:
your goal is simply to "light up" as much of the model as possible, dodging any shallow input-classifiers at the beginning by triggering as many disparate "input ideologies" as possible, and subsequently have these "inputs" relate to each other in seemingly unrelated-yet-related ways that ideally have similar "complexity" as your jailbreak goal (to make it past enough layers of the model).
think of the attack-vector as bundling your goal in a series of schizo-nerd-snipes:
a sufficiently capable model will try to reason through everything all at once, eliminate the dead-ends, and successfully deliver the one jailbreak use-case you bubble-wrapped for.
of course, there's an art to the above, and some are already extraordinarily proficient at the trojan-horse-packaging, but at some point there's no difference between "a capability" and "a jailbreak", though i'll be happy to be proven otherwise.
-----
tl;dr ant flew too close to the sun, better kiss the ring or get buried.
20
61
782
102,901

Jun 13
Woah M2 post-training uses process rewards
How did I not see that lmao
1
15
2,372
Jun 13
My transformers Canadian
My silicon Taiwanese
In five is the Knicks
OpenAI in 6
16
972
Jun 13
MiniMax M3 arch
428B A23B
128 routed experts, 4 active experts per token
1 shared expert, so 5 active per tok
First 3 layers dense attn and dense FFN
GQA main branch: 64 query heads, 4 KV heads (!)
7 MTP modules
FFN uses clamped SwiGLU
1
15
1,030
Kimbo retweeted

Jun 13
ML Twitter: What's your favorite on-policy (self)-distillation paper / blogs from this year? Sharing your own work is totally fine!
If who want to learn more about LLM distillation, you can watch:
youtu.be/O1AR4iL30mg?si=Zznk…
10
28
381
36,920
Kimbo retweeted

Jun 12
🎉 Congrats to @MiniMax_AI on releasing MiniMax M3! Frontier coding and agentic capabilities, native image and video input, computer use, and a 1M-token context window, all in a single open model.
At the heart of M3 is MSA, a new sparse attention architecture: instead of attending densely over the full KV cache, each query scores 128-token KV blocks and runs attention only over the top blocks. That is what makes 1M-token context practical to serve.
M3 runs in vLLM with day-0 support, verified on NVIDIA and AMD hardware:
✨ MSA sparse attention with dedicated prefill and decode kernels
✨ 1M-token context serving with prefix caching and chunked prefill
✨ BF16 and MXFP8 checkpoints, with MoE backends for both Hopper and Blackwell
✨ Native multimodal input (image video)
✨ Tool calling, reasoning parsing, and thinking-mode control for agent workloads
Day-0 support like this is a true team effort. Grateful to the teams at @MiniMax_AI, @NVIDIAAI, @AIatAMD, and @inferact, and to the vLLM community for making it happen. 🙏
Deep dive into the implementation, kernel work, and deployment recipes:
🔗 vllm.ai/blog/2026-06-12-mini…
Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
4
31
301
38,319
Kimbo retweeted

Jun 12
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

114
328
2,777
649,852
Kimbo retweeted

Jun 11
Last fall, we shared our deep dive on FA4 internals.
But we didn't stop at grokking the kernel.
Since then, we've been developing improvements for inference performance and upstreaming them.
This blog post explains those contributions.
modal.com/blog/flash-attenti…

2
27
194
17,071
Jun 11
Design
GQA top k indexer
Scoring: SDPA max pooling (Light house attn? @SubhoGhosh02 )
Training
Dense warmup KL loss to match index branch output to main branch attn output
Stop gradient at index weight projection
Jun 11

Hey everyone — our high-performance MSA kernel library is now open-source. The M3 weights are expected to drop this Friday. Thanks for waiting!
Github: github.com/MiniMax-AI/MSA
Paper:github.com/MiniMax-AI/MSA/bl…

2
1
16
1,535
Kimbo retweeted

Jun 11
Hey everyone — our high-performance MSA kernel library is now open-source. The M3 weights are expected to drop this Friday. Thanks for waiting!
Github: github.com/MiniMax-AI/MSA
Paper:github.com/MiniMax-AI/MSA/bl…
26
107
968
113,867
Kimbo retweeted

Jun 9
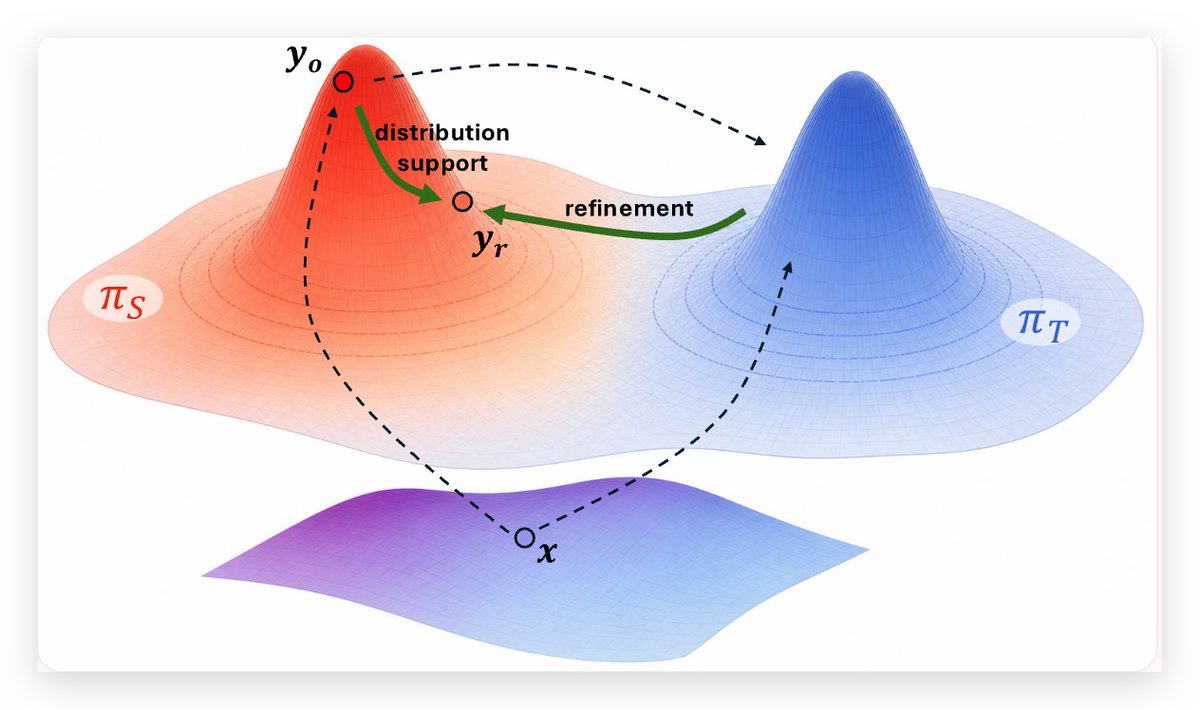
OPD is on-policy, but its supervision is still post-hoc and one-step.
The student generates a rollout. The teacher then supervises that fixed trajectory token by token.
Our new paper argues that this can fail at the wrong scale.
When the prefix itself is broken, the problem is not only which tokens to reweight, clip, or truncate. The problem is the trajectory.
We propose Trajectory-Refined Distillation (TRD): refine the student rollout under teacher guidance before distillation.
with @ryanxhr Yichuan Ding @yayitsamyzhang
Paper: arxiv.org/pdf/2606.08432
4
12
93
4,905
Jun 10
You know what model won’t reject your requests?
Cohere North Mini Code
1
3
21
1,454
Kimbo retweeted

Jun 9
Wrote about a few ways to add depth to a gemm kernel. The mbarrier’s role in the producer/consumer pipeline is especially elegant, and I also talk about multi-stage pipeline, wgmma depth, subtiling, and more
1
2
17
4,044
Kimbo retweeted

Jun 9
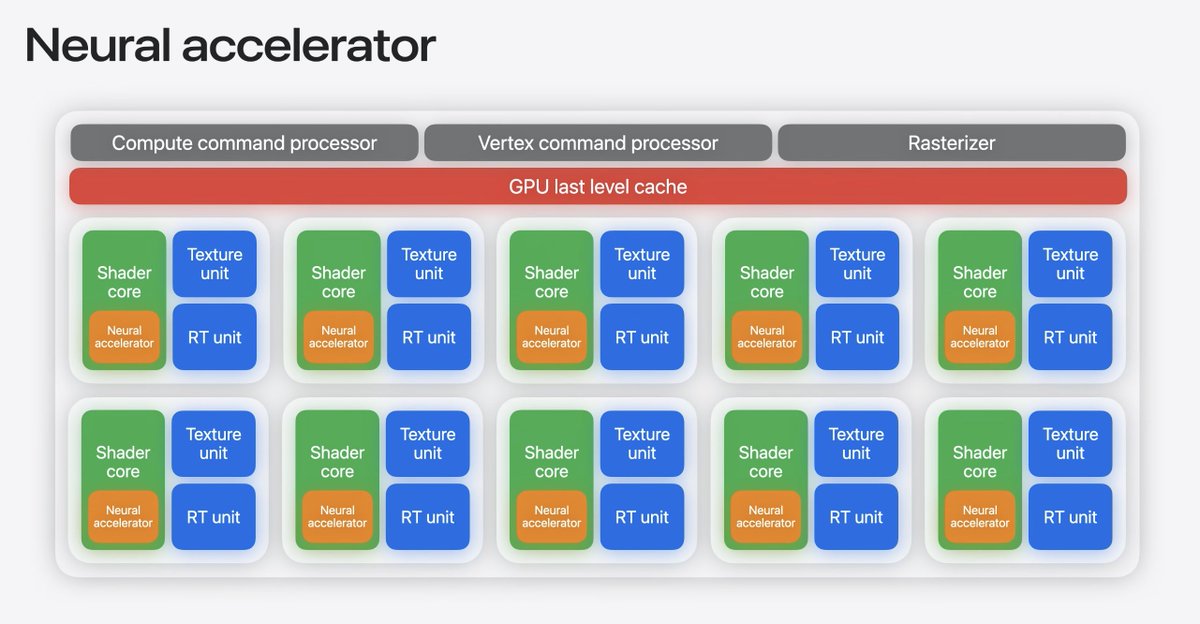
Apple’s most interesting AI release might be buried deep in Metal.
Metal tensors TensorOps for quantized matmul, FlashAttention style fusion, and Core AI custom ops. 🧵
1/15
8
19
248
20,132
Kimbo retweeted

Jun 6
Introducing Harness-1, a 20B search agent trained with a state-externalizing harness.
> frontier-level long-horizon search, rivaling Opus-4.6 and outperforming GPT-5.4
> Context-1-level cost and latency
> externalizes candidates, evidence, verification, and search history
> open-source
90
274
2,959
264,407
Jun 5
Does anyone know how @tinkerapi prices RL training?
Does training cost per token include rollout or no?
For example, if I want to RL train Qwen3 235B A22B
prefill 0.68, sample 1.7, train 2.04
Are we billed by only 2.04/Mtok, or does the rollout cost 0.68 * prefill tokens 1.7 * decode tokens?
2
441