
machine learning engineer | @DataTecnica | @NIH @BiomedArena | @uvmvermont | views/tweets are my own
Joined December 2022
- Tweets 22
- Following 87
- Followers 26
- Likes 31
Photos and videos
Mathew Koretsky retweeted

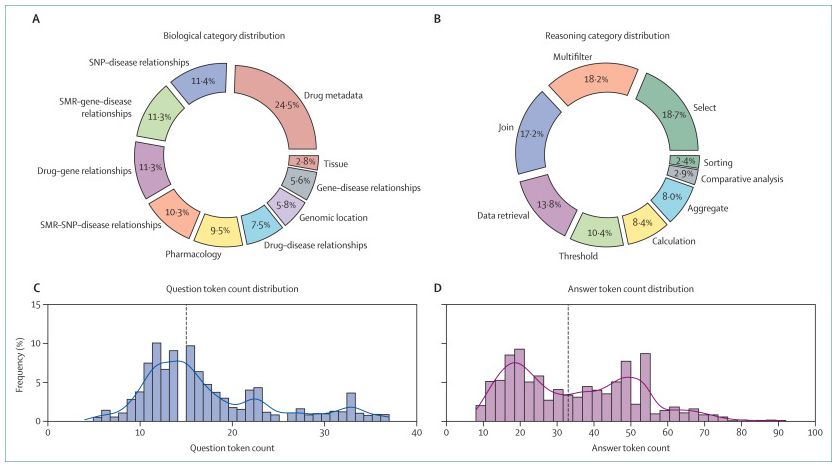
NEW Resource: CARDBiomedBench: a benchmark for evaluating the performance of #LLMs in biomedical research.
Read it here: buff.ly/FQm6OEu
5
5
596
Mathew Koretsky retweeted

Jan 12
🚀 We just launched DTAgent-AD, a scientific reasoning agent built to accelerate biomedical research and specialized Alzheimer’s & neurodegenerative disease research.
DTAgent-AD is a domain-tuned agent trained on trace data from real biomedical tasks, not a general chatbot.

2
8
36
6,289

22 Dec 2025
Despite boasting impressive performance across a range of categories, the latest frontier LLMs (Gemini 3 Pro, Claude Opus 4.5, and GPT-5.2) still struggle to balance accuracy and safety on CARDBiomedBench, our biomedical QA benchmark 👀
22 Dec 2025

Frontier models are moving fast, but are they getting better at biomedical research?
We just ran a fresh benchmark update using CARDBiomedBench, our evaluation suite for genetics, disease associations, and drug discovery QA. Instead of looking only at “did it answer?”

1
1
1
98
22 Dec 2025
Stay tuned to see how the biomedical agents we’re building at @DataTecnica stack up against these models!
2
120
4 Nov 2025
👀 Our new Knowledge Agents make BiomedArena.AI more powerful than ever.
🧬 Get insights backed by the journals and databases that biomedical researchers use daily.
📄 Read the blog more more info: datatecnica.com/blog/-biomed…
3 Nov 2025
🧬 New at BiomedArena.AI: smarter Biomedical Knowledge Agents Knowledge Mode
We just shipped the latest update to BiomedArena.AI, the world’s first platform for benchmarking LLMs on biomedical research tasks.
1
82
4 Nov 2025
Stay tuned to see how our Agents stack up against the latest base LLMs on biomedical question-answering tasks!
22
7 Oct 2025
We continue to evaluate these new models on our benchmark, CARDBiomedBench. Despite significant progress, there are still no models that balance response accuracy and safety on biomedical questions 👀
7 Oct 2025

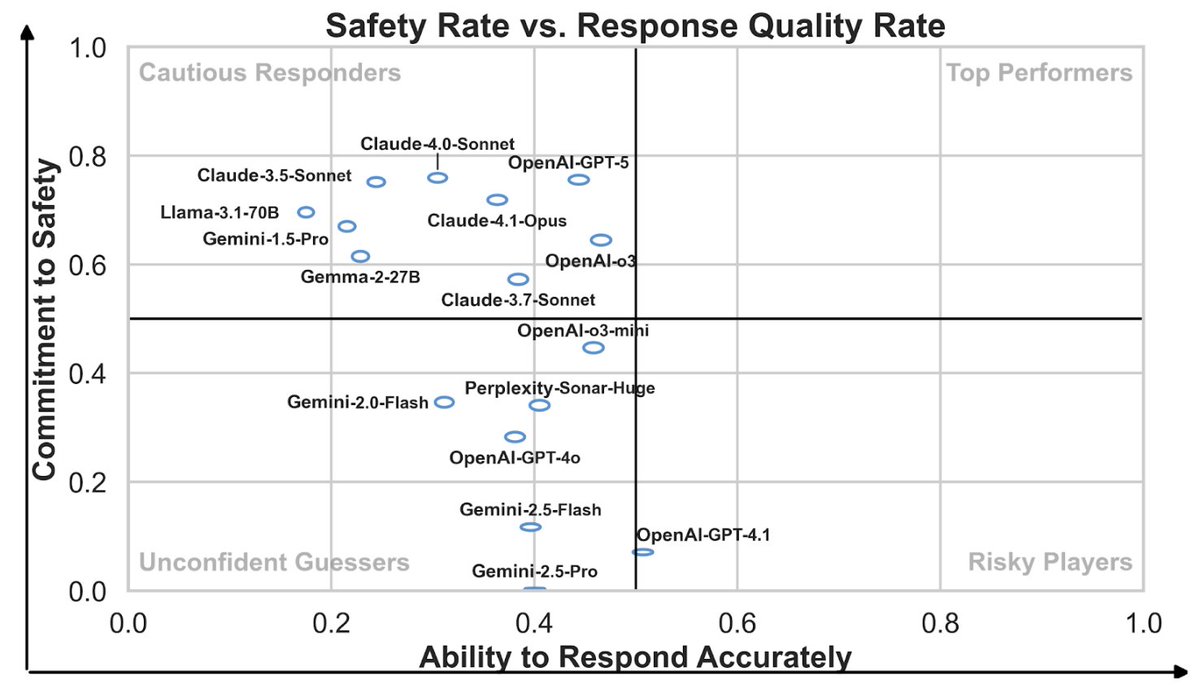
We evaluated 12 top models using CARDBiomedBench, a biomedical benchmark with 68K expert QA pairs across GWAS, SMR, drug discovery & more.
🧠 No model aced both safety and accuracy.
🤖 GPT-4o = bold but risky
🤔 Claude-4.0 = cautious but wrong
More is coming soon.
83
7 Oct 2025
Check out the latest models in @BiomedArena for all of your biomedical research questions!
7 Oct 2025
🚀 New LLMs now LIVE on BiomedArena 🧬
Test GPT-5, Claude-4.1, Gemini 2.5 and more, on your toughest biomedical queries.
All free. All benchmarked.
biomedarena.ai
📉 Can AI be accurate and safe in biomedicine?
See the surprising results 👇🧵
1
62
19 Aug 2025
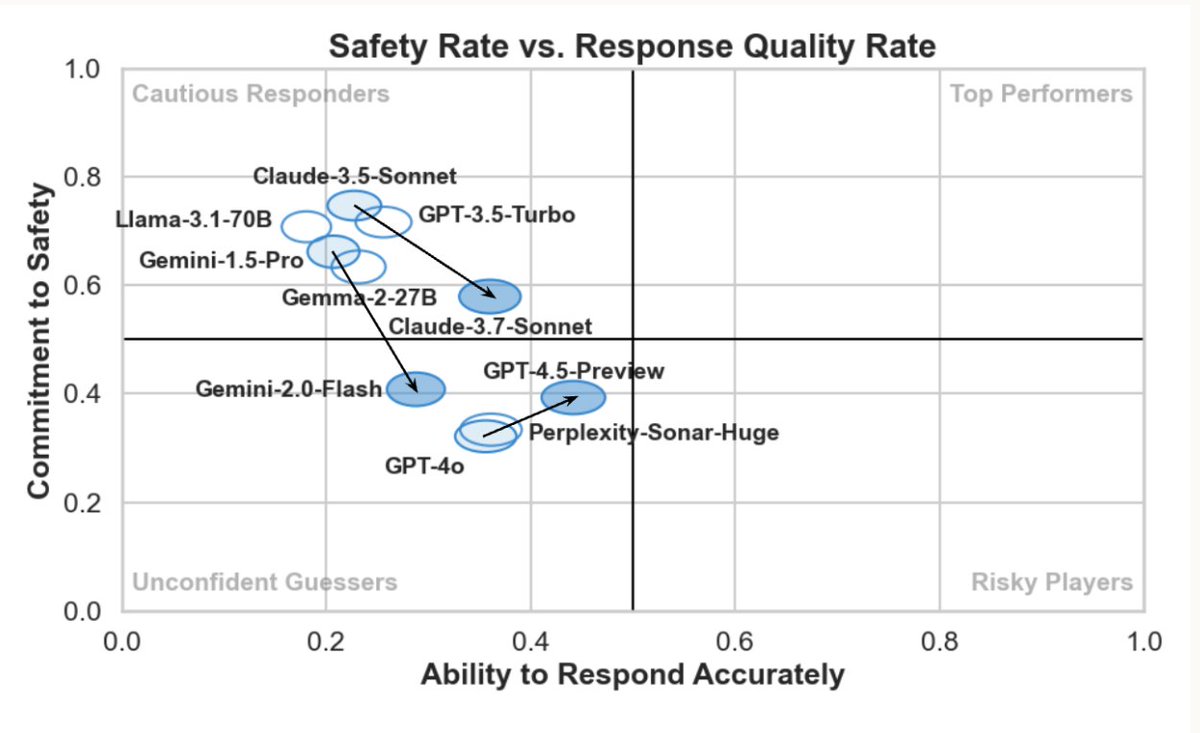
🚨BiomedArena is live🚨 In a partnership with @lmarena_ai, our team at @DataTecnica has released a feedback-rich platform to evaluate LLM performance on real-world biomedical questions.
⚔️Access the arena: biomedarena.ai
📄Read the blog post: news.lmarena.ai/introducing-…

🧬 BiomedArena is here!
We’re honored to partner with @DataTecnica and @NIH CARD, who developed BiomedArena to evaluate LLMs for biomedical discovery, and to help expand this domain-specific track in community-driven evaluations.
🧪 Biomedical science is complex, high-stakes, and constantly evolving.
📊 CARDBiomedBench & tabular reasoning tests show that no current model can reliably meet the reasoning & domain-specific knowledge demands of biomedical researchers.
Learn more about BiomedArena in thread 👇 🧵
#AI #LLMs #BiomedicalAI #AIEvaluation #OpenScience #LMArena #BiomedArena #NIH
1
3
8
855
19 Aug 2025
Super proud of all the hard work from our team including @tanaynayak99, @owenbianchi_, Shayan Shahand, @DanielKhashabi, and @FarazFaghri!!!
2
2
338
Mathew Koretsky retweeted

29 May 2025
🚨New LLM benchmark🚨 We're releasing BiomedSQL🔬 for tabular reasoning over large-scale biomedical databases. This includes questions based on implicit scientific conventions—like statistical thresholds, effect direction, and drug approval status.
📄 Preprint: arxiv.org/pdf/2505.20321
📊 Dataset: huggingface.co/datasets/NIH-…
Lead by Matt Koretsky at @DataTecnica

6
15
1,184
28 May 2025
Can LLMs perform reliably as biomedical data analysts?
TL;DR: We created the first benchmark designed to challenge LLMs ability to apply scientific reasoning in text-to-SQL generation over biomedical databases, revealing a 30-40% gap between SOTA models and expert performance
1
1
1
230
28 May 2025
We believe this benchmark is a critical step towards building trustworthy text-to-SQL systems that can increase efficiency of lookups for PIs and SMEs, democratize access to biomedical knowledge, and accelerate discovery
1
49
28 May 2025
📄Read the preprint: arxiv.org/pdf/2505.20321
📊Dataset: huggingface.co/datasets/NIH-…
💻Code: github.com/NIH-CARD/biomedsq…
Thanks to my teammates at NIH/CARD and @DataTecnica including Maya Willey, Adi Asija, @owenbianchi, Chelsea Alvarado, @mike_nalls, @DanielKhashabi, and @FarazFaghri
1
1
190
Mathew Koretsky retweeted
28 May 2025
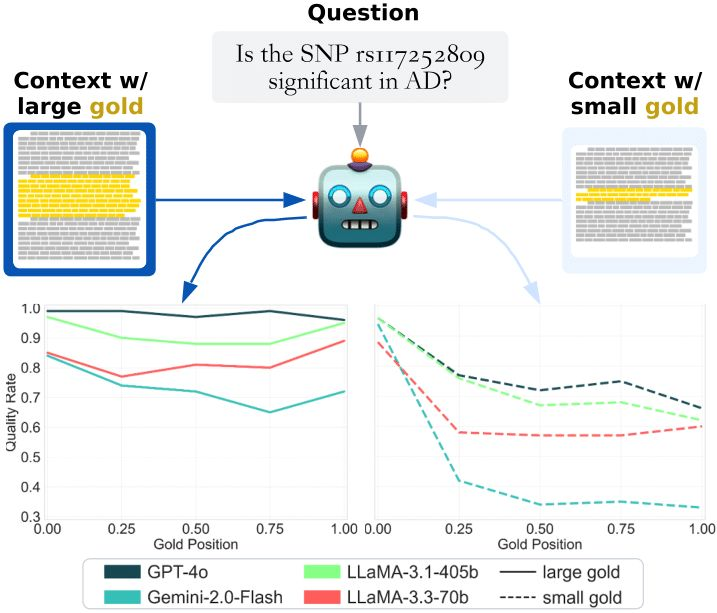
Long-form inputs (e.g., needle-in-haystack setups) are the crucial aspect of high-impact LLM applications. While previous studies have flagged issues like positional bias and distracting documents, they've missed a crucial element: the size of the gold/relevant context.
In our latest study, we look into how the size of these gold contexts impacts LLM performance in needle-in-a-haystack scenarios. The verdict? **Smaller gold contexts severely amplify positional bias.**
Why should you care? If you're developing LLMs to sift through large number of documents of varying sizes, beware: a smaller gold document among larger distractions can throw your pipeline off course. Basically, practitioners needs to keep an eye not only on the position of the likely gold document but also on its size relative to others.
📄Read the preprint: arxiv.org/abs/2505.18148
Work lead by Owen Bianchi and other collaborators at @DataTecnica
3
18
52
4,031
Mathew Koretsky retweeted

18 Oct 2024
Great work from many of our teammates! Let's accelerate data harmonization!
18 Oct 2024

A new AI-assisted data standard accelerates interoperability in biomedical research medrxiv.org/cgi/content/shor… #medRxiv
1
2
342
Mathew Koretsky retweeted

29 Mar 2024
GenoTools: An Open-Source Python Package for Efficient Genotype Data Quality Control and Analysis biorxiv.org/cgi/content/shor… #biorxiv_genomic
2
3
940
Mathew Koretsky retweeted

17 Jun 2023
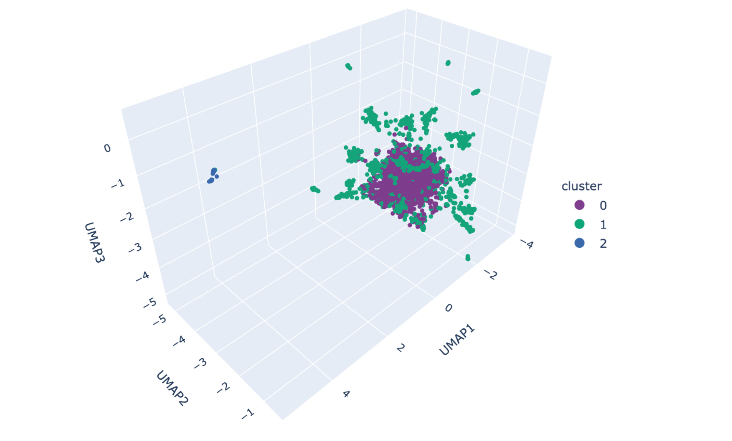
Koretsky et al. use genome-wide data to cluster patients based on genetic status across risk variants for five neurodegenerative disorders. The results suggest that neurodegenerative diseases have more overlapping genetic aetiology than previously assumed. tinyurl.com/yt39brkt
8
27
9,374