
Machine Learning Engineer, Founder @Enployable, MIT Technology Review Global Panelist, Google, Facebook, Intel, & Microsoft Scholar. she/her
Joined May 2011
- Tweets 411
- Following 883
- Followers 351
- Likes 1,163
36 Photos and videos














Pinned Tweet

22 Dec 2025
So proud of our Enployable AI team: we officially accepted our 2025 Tech100 award! Incredible energy and inspiring to connect with fellow honorees. Thank you @NoVATechCouncil for a fantastic celebration! ✨🏆
5
89

1,089
2,255
17,512
14,185,846
Laura Truncellito retweeted

May 11
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral x.com/zan2434/status/2046982…
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.

1,040
2,016
19,288
3,831,282
Laura Truncellito retweeted

Apr 25
Hamming's talk is so important that I reproduced it on my site. It's one of the only things on my site written by someone else.
paulgraham.com/hamming.html
Apr 24

A mathematician who shared an office with Claude Shannon at Bell Labs gave one lecture in 1986 that explains why some people win Nobel Prizes and other equally smart people spend their whole lives doing forgettable work.
His name was Richard Hamming. He won the Turing Award. He invented error-correcting codes that made modern computing possible. And he spent 30 years at Bell Labs sitting in a cafeteria at lunch watching which scientists became legendary and which ones faded into nothing.
In March 1986, he walked into a Bellcore auditorium in front of 200 researchers and told them exactly what he had seen.
Here's the framework that has been quoted by every serious scientist for the last 40 years.
His opening line landed like a punch. He said most scientists he worked with at Bell Labs were just as smart as the Nobel Prize winners. Just as hardworking. Just as credentialed. And yet at the end of a 40-year career, one group had changed entire fields and the other group was forgotten by the time they retired.
He wanted to know what the difference actually was. And he said it wasn't luck. It wasn't IQ. It was a specific set of habits that almost nobody is willing to follow.
The first habit was the one that hurts the most to hear. He said most scientists deliberately avoid the most important problem in their field because the odds of failure are too high. They pick a safe adjacent problem, solve it cleanly, publish it, and move on. And because they never swing at the hard problem, they never hit it. He said if you do not work on an important problem, it is unlikely you will do important work. That is not a motivational line. That is a logical one.
The second habit was about doors. Literal doors. He noticed that the scientists at Bell Labs who kept their office doors closed got more done in the short term because they had no interruptions. But the scientists who kept their doors open got more done over a career. The open-door scientists were interrupted constantly. They also absorbed every new idea passing through the hallway. Ten years in, they were working on problems the closed-door scientists did not even know existed.
The third habit was inversion. When Bell Labs refused to give him the team of programmers he wanted, Hamming sat with the rejection for weeks. Then he flipped the question. Instead of asking for programmers to write the programs, he asked why machines could not write the programs themselves. That single inversion pushed him into the frontier of computer science. He said the pattern repeats everywhere. What looks like a defect, if you flip it correctly, becomes the exact thing that pushes you ahead of everyone else.
The fourth habit was the one that hit me the hardest. He said knowledge and productivity compound like interest. Someone who works 10 percent harder than you does not produce 10 percent more over a career. They produce twice as much. The gap doesn't add. It multiplies. And it compounds silently for years before anyone notices.
He finished the lecture with a line I have never been able to shake.
He said Pasteur's famous quote is right. Luck favors the prepared mind. But he meant it literally. You don't hope for luck. You engineer the conditions where luck can land on you. Open doors. Important problems. Inverted questions. Compounded hours. Those are not traits. Those are choices you make every single day.
The transcript has been sitting on the University of Virginia's computer science website for almost 30 years. The video is free on YouTube. Stripe Press reprinted the full lectures as a book in 2020 and Bret Victor wrote the foreword.
Hamming died in 1998. He gave his final lecture a few weeks before. He was 82.
The lecture that explains why some careers become legendary and others disappear is still free. Most people who could benefit from it will never open it.

82
430
3,706
786,309
Laura Truncellito retweeted

Apr 24
MIT just made every AI company's billion dollar bet look embarrassing.
They solved AI memory. Not by building a bigger brain. By teaching it how to read.
The paper dropped on December 31, 2025. Three MIT CSAIL researchers. One idea so obvious it hurts. And a result that makes five years of context window arms racing look like the wrong war entirely.
Here is the problem nobody solved.
Every AI model on the planet has a hard ceiling. A context window. The maximum amount of text it can hold in working memory at once. Cross that line and something ugly happens — something researchers have a clinical name for.
Context rot.
The more you pack into an AI's context, the worse it performs on everything already inside it. Facts blur. Information buried in the middle vanishes. The model does not become more capable as you feed it more. It becomes more confused. You give it your entire codebase and it forgets what it read three files ago. You hand it a 500-page legal document and it loses the clause from page 12 by the time it reaches page 400.
So the industry built a workaround. RAG. Retrieval Augmented Generation. Chop the document into chunks. Store them in a database. Retrieve the relevant ones when needed.
It was always a compromise dressed up as a solution.
The retriever guesses which chunks matter before the AI has read anything. If it guesses wrong — and it does, constantly — the AI never sees the information it needed. The act of chunking destroys every relationship between distant paragraphs. The full picture gets shredded into fragments that the AI then tries to reassemble blindfolded.
Two bad options. One broken industry. Three MIT researchers and a deadline of December 31st.
Here is what they built.
Stop putting the document in the AI's memory at all.
That is the entire idea. That is the breakthrough. Store the document as a Python variable outside the AI's context window entirely. Tell the AI the variable exists and how big it is. Then get out of the way.
When you ask a question, the AI does not try to remember anything. It behaves like a human expert dropped into a library with a computer. It writes code. It searches the document with regular expressions. It slices to the exact section it needs. It scans the structure. It navigates. It finds precisely what is relevant and pulls only that into its active window.
Then it does something that makes this recursive.
When the AI finds relevant material, it spawns smaller sub-AI instances to read and analyze those sections in parallel. Each one focused. Each one fast. Each one reporting back. The root AI synthesizes everything and produces an answer.
No summarization. No deletion. No information loss. No decay. Every byte of the original document remains intact, accessible, and queryable for as long as you need it.
Now here are the numbers.
Standard frontier models on the hardest long-context reasoning benchmarks: scores near zero. Complete collapse. GPT-5 on a benchmark requiring it to track complex code history beyond 75,000 tokens — could not solve even 10% of problems.
RLMs on the same benchmarks: solved them. Dramatically. Double-digit percentage gains over every alternative approach. Successfully handling inputs up to 10 million tokens — 100 times beyond a model's native context window.
Cost per query: comparable to or cheaper than standard massive context calls.
Read that again. One hundred times the context. Better answers. Same price.
The timeline of the arms race makes this sting harder. GPT-3 in 2020: 4,000 tokens. GPT-4: 32,000. Claude 3: 200,000. Gemini: 1 million. Gemini 2: 2 million. Every generation, every company, billions of dollars spent, all betting on the same assumption.
More context equals better performance.
MIT just proved that assumption was wrong the entire time.
Not slightly wrong. Fundamentally wrong. The entire premise of the last five years of context window research — that the solution to AI memory was a bigger window — was the wrong answer to the wrong question.
The right question was never how much can you force an AI to hold in its head.
It was whether you could teach an AI to know where to look.
A human expert handed a 10,000-page archive does not read all 10,000 pages before answering your question. They navigate. They search. They find the relevant section, read it deeply, and synthesize the answer.
RLMs are the first AI architecture that works the same way.
The code is open source. On GitHub right now. Free. No license fees. No API costs. Drop it in as a replacement for your existing LLM API calls and your application does not even notice the difference — except that it suddenly works on inputs it used to fail on entirely.
Prime Intellect — one of the leading AI research labs in the space — has already called RLMs a major research focus and described what comes next: teaching models to manage their own context through reinforcement learning, enabling agents to solve tasks spanning not hours, but weeks and months.
The context window wars are over.
MIT won them by walking away from the battlefield.
Source: Zhang, Kraska, Khattab · MIT CSAIL · arXiv:2512.24601
Paper: arxiv.org/abs/2512.24601
GitHub: github.com/alexzhang13/rlm

147
444
2,149
326,944

Demis Hassabis and Sebastian Mallaby were on stage in SF today and here are the 9 best things they said:
1. "There is a 50% chance that OpenAI goes bankrupt in the next 18mos" -Mallaby
2. "Dario is the best of all the other lab leaders." -Demis
3. On Claude Mythos: "It's not really tenable for a private company to decide who gets access to the frontier of cyber defense tech. What happens when China can do this in 6-12mos?" -Mallaby
4. "Not all countries are pessimistic about AI. I was just in India for the AI Summit Modi had and they're quite optimistic there" -Demis
5. "The most exciting current prospect in AI is our work at Isomorphic Labs. AlphaFold is just one of the many problems we need to solve. We need 6 'AlphaFold' moments to compress the drug delivery timeline from 10yrs to a few months" -Demis
6. "I don't think of p(doom) as probabilities to throw out there. I just know it's non zero. Some people like Marc Andreesen and Yann LeCun think it's 0% and I think that's crazy" -Demis
7. On AGI: "I think of a post-scarcity world where on the bright side we will have an unbelievable amount of science but we will have to think of economic problems of sharing proceeds equitably. We will also have philosophical questions to answer and need great new philosophers" -Demis
8. On career advice: "Immerse yourself in AI tools. Everyone has access to tools 3-6 months behind frontier. Enormous opportunity lies in applying AI to unexplored areas." -Demis
9. On the future: "When I started building this technology, I pictured a future quite different from this. More like CERN researchers where we discuss ideas and help each other out and stress test each other's ideas. It's my job to help how I can to make sure we make more considered, more scientific, more rigorous and more thoughtful decisions and that will also involve social scientists and economists. I'm going to do all I can to try and influence the future in a note thoughtful manner. The decisions we make in the next 5-10 years are going to affect us for 1000s of years. But I remain very optimistic." -Demis

91
275
2,850
730,677
Apr 23
If you've ever tried to explain your startup idea and felt the words slip away, you're not alone.
A structured template grounds you when an idea is still forming. The offering, audience, problem, secret sauce.
elevator-pitch-worksheet.fi.…
#FounderInstitute
12
Apr 15
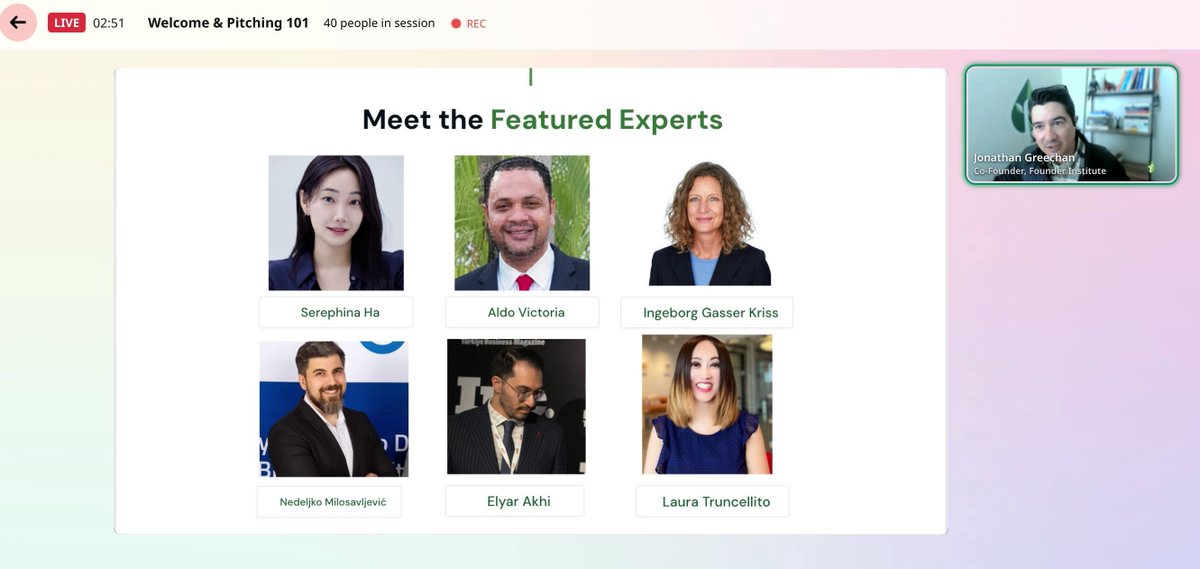
This Thursday, I'm leading a hands-on Claude AI session for Nasdaq Entrepreneurial Center's Milestone Circles alumnae. DM me or @saundragilliard for sign-up details.
Looking forward to seeing you!
@nasdaqcenter @AnthropicAI
#AI #Claude #Anthropic #WomenInTech #Nasdaq
31
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
13
Laura Truncellito retweeted

Apr 1
Happy April Fools!
For the next few days, Claude Code gets five rarities across 18 species of buddies that talk to you as you code.
Upgrade and send `/buddy` to unbox yours.
(these tokens don't contribute to your usage limits!)
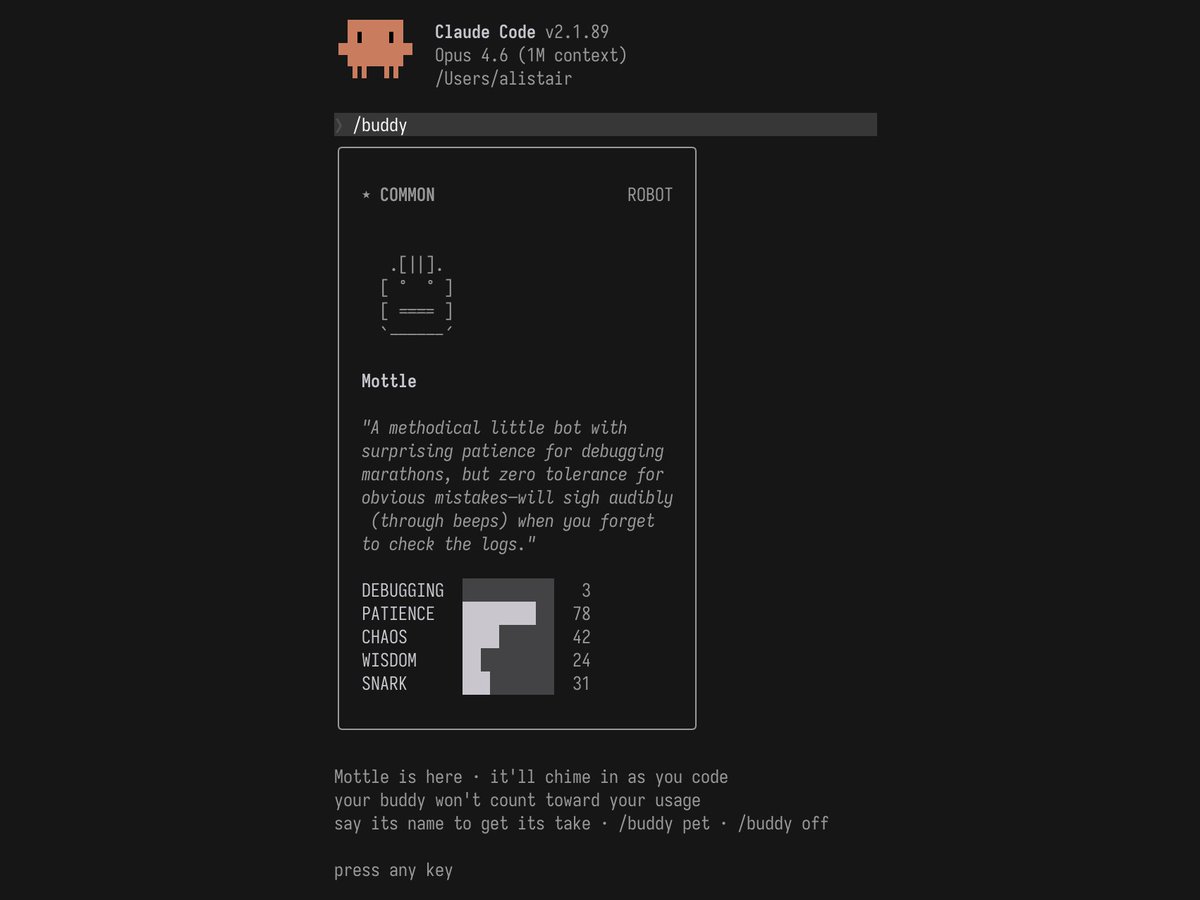
ALT Screenshot of the Claude Code terminal interface presenting a trading card style unboxing of a buddy
66
19
425
67,796
Laura Truncellito retweeted

Mar 30
How can we autonomously improve LLM harnesses on problems humans are actively working on?
Doing so requires solving a hard, long-horizon credit-assignment problem over all prior code, traces, and scores.
Announcing Meta-Harness: a method for optimizing harnesses end-to-end

78
284
1,763
592,926
Laura Truncellito retweeted

Mar 26
A MIT professor taught the same lecture every January for 40 years, and every single time it was standing room only.
I watched it at 2am and it completely rewired how I think about communication.
His name was Patrick Winston. The lecture is called "How to Speak."
His opening line hit like a truck: your success in life will be determined largely by your ability to speak, your ability to write, and the quality of your ideas in that order.
Not your GPA. Not your pedigree. Not your IQ. How you speak is what separates people who get heard from people who get ignored.
Here's the framework he drilled into MIT students for four decades.
He said never start with a joke. Start by telling people exactly what they're going to learn. Prime the pump before you pour anything in. He called it the "empowerment promise" give people a reason to stay in their seats within the first 60 seconds.
Then he broke down the 5S rule for making ideas stick: Symbol, Slogan, Surprise, Salient, and Story. Every idea worth remembering hits at least three of these.
The part that floored me was his "near miss" technique. Don't just show what's right show what almost looks right but isn't. That contrast is when the brain actually locks something in permanently.
His final rule before any big talk: end with a contribution, not a summary. Don't recap what you said. Tell people what you gave them that they didn't have before they walked in.
I've used this framework in pitches, interviews, and presentations ever since watching it, and the results are not subtle.
Patrick Winston passed away in 2019, but this lecture is still free on MIT OpenCourseWare. One hour, watched by millions, and it costs absolutely nothing.
The most important class MIT ever put on the internet isn't about code or math. It's about how to make people actually listen to you.

197
3,757
19,907
1,945,158
Mar 26
And that one area is HR.
Mar 26

And yes, this means companies will also require a R&D budget for areas of the company that traditionally have not required R&D -- you need to experiment with organizational approaches, new ways of structuring projects, skill/agent building techniques, and other ways to apply AI.
1
10
A great new feature by #ClaudeCode
Today we're launching local scheduled tasks in Claude Code desktop.
Create a schedule for tasks that you want to run regularly. They'll run as long as your computer is awake.
3
30
Laura Truncellito retweeted

Jan 26
The Adolescence of Technology: an essay on the risks posed by powerful AI to national security, economies and democracy—and how we can defend against them: darioamodei.com/essay/the-ad…
879
2,663
15,377
6,273,124
Feb 25
Feb 24
CLIs are super exciting precisely because they are a "legacy" technology, which means AI agents can natively and easily use them, combine them, interact with them via the entire terminal toolkit.
E.g ask your Claude/Codex agent to install this new Polymarket CLI and ask for any arbitrary dashboards or interfaces or logic. The agents will build it for you. Install the Github CLI too and you can ask them to navigate the repo, see issues, PRs, discussions, even the code itself.
Example: Claude built this terminal dashboard in ~3 minutes, of the highest volume polymarkets and the 24hr change. Or you can make it a web app or whatever you want. Even more powerful when you use it as a module of bigger pipelines.
If you have any kind of product or service think: can agents access and use them?
- are your legacy docs (for humans) at least exportable in markdown?
- have you written Skills for your product?
- can your product/service be usable via CLI? Or MCP?
- ...
It's 2026. Build. For. Agents.

2
30
Feb 21

Claude Code on desktop can now preview your running apps, review your code, and handle CI failures and PRs in the background.
Here’s what's new:
1
36
Laura Truncellito retweeted
Feb 19
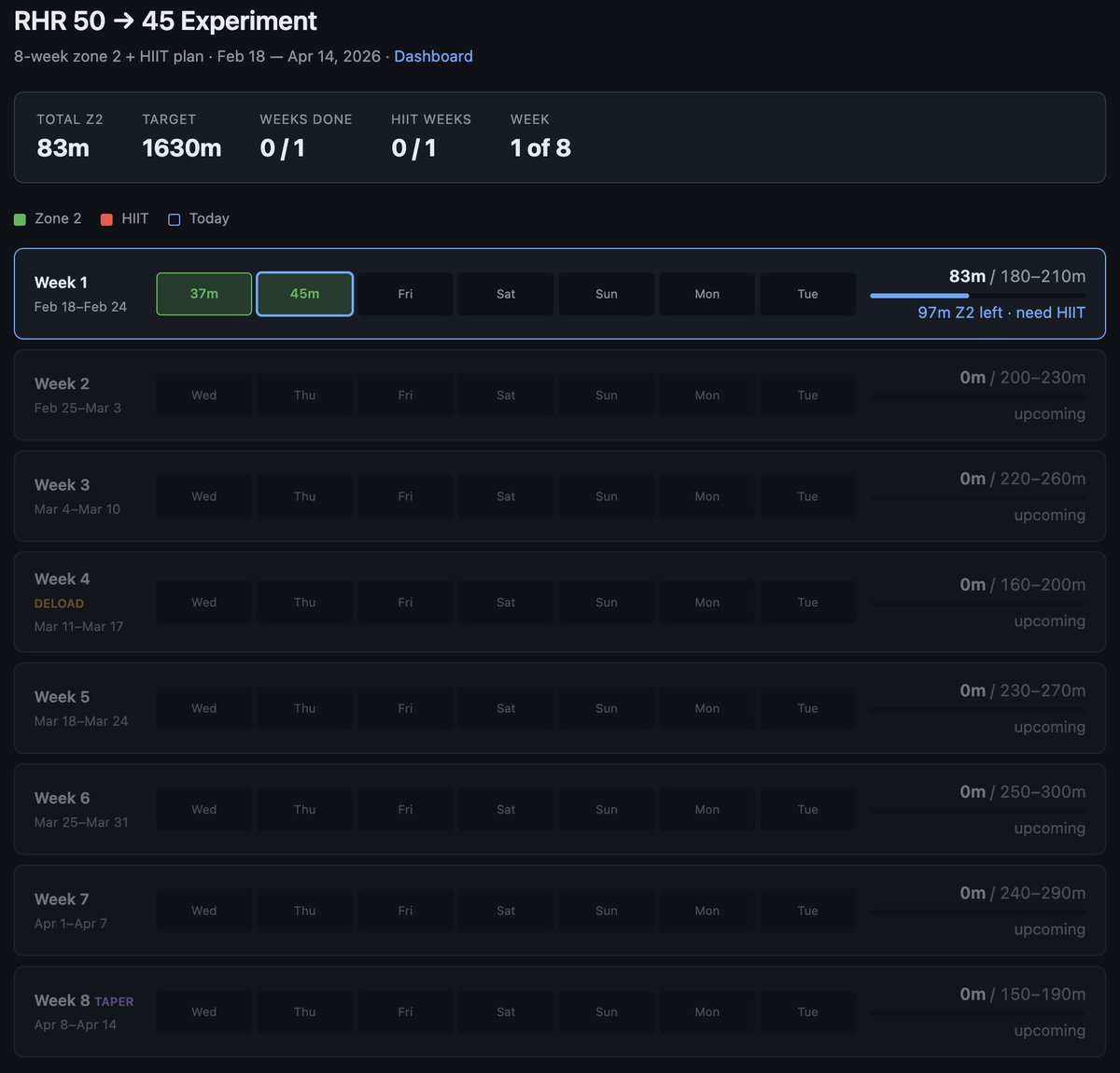
Very interested in what the coming era of highly bespoke software might look like.
Example from this morning - I've become a bit loosy goosy with my cardio recently so I decided to do a more srs, regimented experiment to try to lower my Resting Heart Rate from 50 -> 45, over experiment duration of 8 weeks. The primary way to do this is to aspire to a certain sum total minute goals in Zone 2 cardio and 1 HIIT/week.
1 hour later I vibe coded this super custom dashboard for this very specific experiment that shows me how I'm tracking. Claude had to reverse engineer the Woodway treadmill cloud API to pull raw data, process, filter, debug it and create a web UI frontend to track the experiment. It wasn't a fully smooth experience and I had to notice and ask to fix bugs e.g. it screwed up metric vs. imperial system units and it screwed up on the calendar matching up days to dates etc.
But I still feel like the overall direction is clear:
1) There will never be (and shouldn't be) a specific app on the app store for this kind of thing. I shouldn't have to look for, download and use some kind of a "Cardio experiment tracker", when this thing is ~300 lines of code that an LLM agent will give you in seconds. The idea of an "app store" of a long tail of discrete set of apps you choose from feels somehow wrong and outdated when LLM agents can improvise the app on the spot and just for you.
2) Second, the industry has to reconfigure into a set of services of sensors and actuators with agent native ergonomics. My Woodway treadmill is a sensor - it turns physical state into digital knowledge. It shouldn't maintain some human-readable frontend and my LLM agent shouldn't have to reverse engineer it, it should be an API/CLI easily usable by my agent. I'm a little bit disappointed (and my timelines are correspondingly slower) with how slowly this progression is happening in the industry overall. 99% of products/services still don't have an AI-native CLI yet. 99% of products/services maintain .html/.css docs like I won't immediately look for how to copy paste the whole thing to my agent to get something done. They give you a list of instructions on a webpage to open this or that url and click here or there to do a thing. In 2026. What am I a computer? You do it. Or have my agent do it.
So anyway today I am impressed that this random thing took 1 hour (it would have been ~10 hours 2 years ago). But what excites me more is thinking through how this really should have been 1 minute tops. What has to be in place so that it would be 1 minute? So that I could simply say "Hi can you help me track my cardio over the next 8 weeks", and after a very brief Q&A the app would be up. The AI would already have a lot personal context, it would gather the extra needed data, it would reference and search related skill libraries, and maintain all my little apps/automations.
TLDR the "app store" of a set of discrete apps that you choose from is an increasingly outdated concept all by itself. The future are services of AI-native sensors & actuators orchestrated via LLM glue into highly custom, ephemeral apps. It's just not here yet.
907
1,009
12,024
1,957,222
Feb 12
Feb 11
New art project.
Train and inference GPT in 243 lines of pure, dependency-free Python. This is the *full* algorithmic content of what is needed. Everything else is just for efficiency. I cannot simplify this any further.
gist.github.com/karpathy/862…
1
52
Laura Truncellito retweeted

Feb 11
These are literally the kind of LLM interview questions most candidates wish they had seen earlier.
A curated list of 50 LLM interview questions - shared by Hao Hoang.
What's covered:
Fundamentals:
→ Tokenization and why it matters
→ Attention mechanisms in transformers
→ Context windows and their tradeoffs
→ Embeddings and initialization
→ Positional encodings
Fine-tuning & Efficiency:
→ LoRA vs QLoRA
→ PEFT to prevent catastrophic forgetting
→ Model distillation
→ Adaptive Softmax for large vocabularies
Generation & Decoding:
→ Beam search vs greedy decoding
→ Temperature, top-k, top-p sampling
→ Autoregressive vs masked models
Advanced Concepts:
→ RAG (Retrieval-Augmented Generation)
→ Chain-of-Thought prompting
→ Mixture of Experts (MoE)
→ Knowledge graph integration
→ Zero-shot and few-shot learning
Math & Theory:
→ Softmax in attention
→ Cross-entropy loss
→ KL divergence
→ Gradient computation for embeddings
→ Vanishing gradient solutions in transformers
You don't need to follow me (@techNmak) and comment "LLM". I will put the link in the comments.

40
183
1,111
83,080
Laura Truncellito retweeted

Genie 3 🤝 @Waymo
The Waymo World Model generates photorealistic, interactive environments to train autonomous vehicles.
This helps the cars navigate rare, unpredictable events before encountering them in reality. 🧵
80
250
1,687
427,972