
Modernist
Joined June 2020
- Tweets 3,418
- Following 397
- Followers 792
- Likes 1,830
109 Photos and videos









mconcat retweeted

May 28
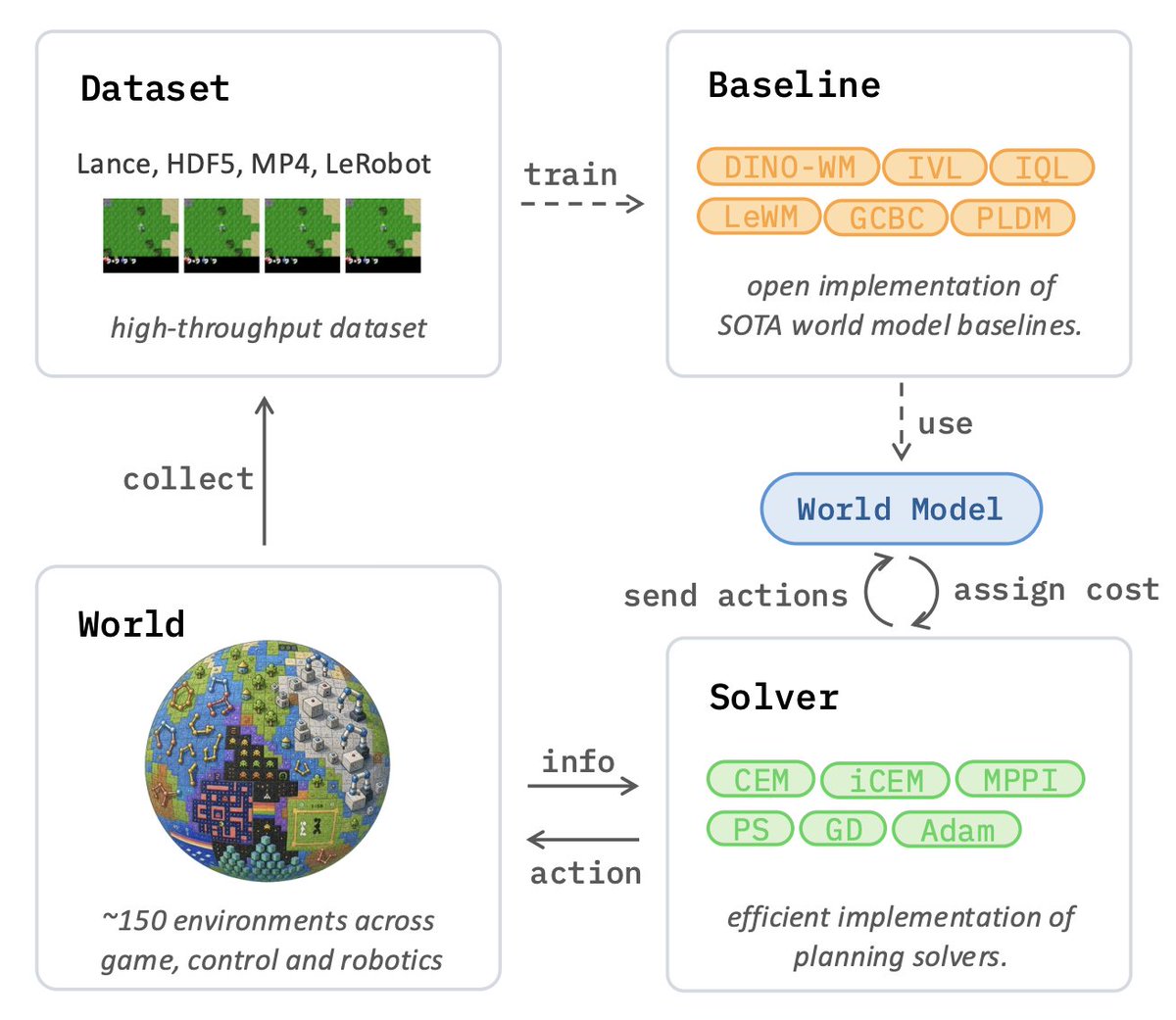
Would you like to join the research effort on JEPA and World Models easily?
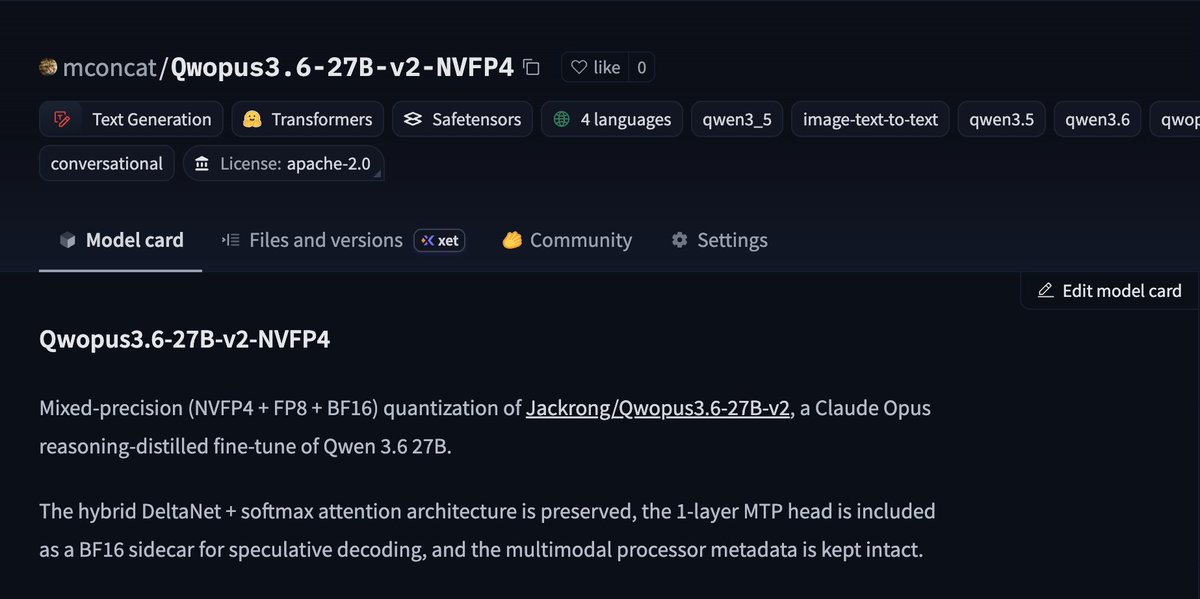
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: github.com/galilai-group/sta…
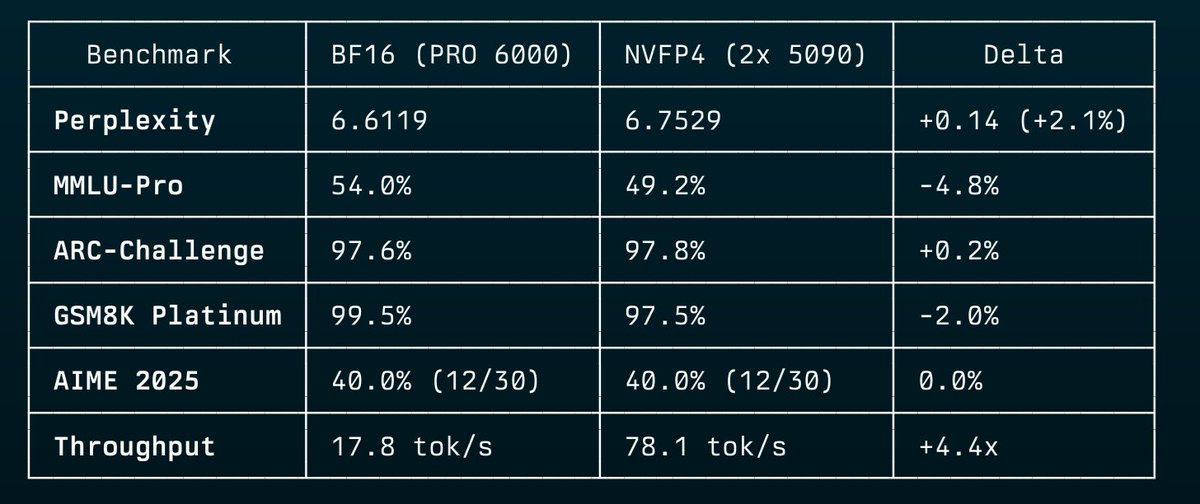
40
274
1,818
113,456

May 27
교황 레오 14세 Magnifica Humanitas 회칙의 한국어 번역본(gemma 4 31b로 기계번역됨)
mconcat.github.io/magnifica-…
151
mconcat retweeted

May 22
🚨 Why does Self-Play RL for LLMs keep collapsing? Most fixes focus on the reward signal. In our new paper "Survive or Collapse", we show that's the wrong lever. The true binding constraint is actually Data Gating: deciding which generated tasks enter the training pool. 🧵 1/n
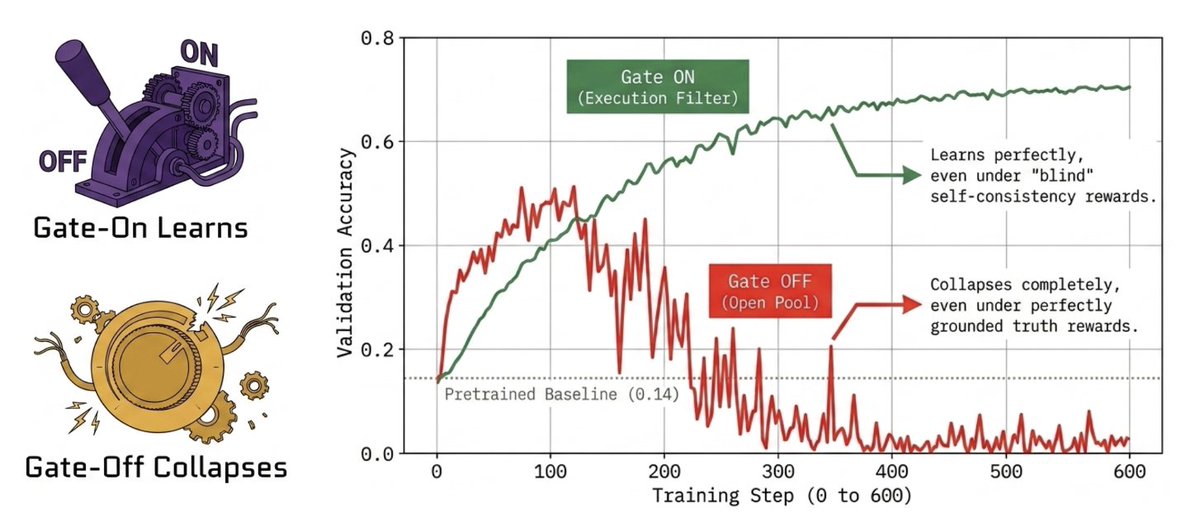
7
41
259
33,697
mconcat retweeted

Vmax is building an open-ended learning system that generates and optimizes itself on tasks that it creates, avoiding human bias that may corrupt optimal learning curricula.
In PopuLoRA, we instantiate this as co-evolving populations of LLMs performing asymmetric self-play.
21
56
291
71,212
mconcat retweeted

May 21
The most popular way to interpret AI is missing the bigger picture.
Models think in curved shapes. But sparse autoencoders (SAEs) work with straight lines.
Can they still capture models’ curved neural geometry? Yes, but not how you might think! (1/7)
May 7

Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
25
151
1,017
173,725
mconcat retweeted

May 13
We’re training models wrong and it’s due to chatGPT. Even the modern coding agents used daily still use message-based exchanges: They send messages to users, to themselves (CoT) and to tools, and receive messages in turn.
This bottlenecks even very intelligent agents to a single stream. The models cannot read while writing, cannot act while thinking and cannot think while processing information.
In our new paper, see below, we discuss LLMs with parallel streams. We show that multi-stream LLMs can …
🔵Be created by instruction-tuning for the stream format
🔵Simplify user and tool use UX removing many pain points with agents and chat models (such as having to interrupt the model to get a word in)
🔵Multi-Stream LLMs are fast, they can predict read tokens in all streams in parallel in each forward pass, improving latency
🔵 LLMs with multiple streams have an easier time encoding a separation of concerns, improving security
🔵 LLMs with many internal streams provide a legible form of parallel/cont. reasoning. Even if the main CoT stream is accidentally pressured or too focused on a particular task to voice concerns, other internal streams can subvocalize concerns that would otherwise not be verbalized.
Does this sound related to a recent thinky post :) - Yes, but I don’t feel so bad about being outshipped with such a cool report on their side by 23 hours. I’ll link a 2nd thread below with a more direct comparison. I actually think both are complementary in interesting ways.
42
167
1,366
157,119
mconcat retweeted
May 14
Neural networks do math by rotating shapes.
We found a shape-rotating calculator hidden inside an LLM – and it’s used for more than just math! (1/6)
May 7
Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
122
555
4,297
936,207
mconcat retweeted

May 12
"How do you self-improve a model on open-ended tasks where you can't take a majority vote?"
I got asked this in nearly every research interview I did last year. None of my answers felt clean.
So we built something that doesn't need a vote, a verifier, or a judge.
Meet G-Zero. 👇
paper: arxiv.org/abs/2605.09959
huggingface: huggingface.co/papers/2605.0…
code: github.com/Chengsong-Huang/G…
All experiments are done via api by @thinkymachines (1/n)
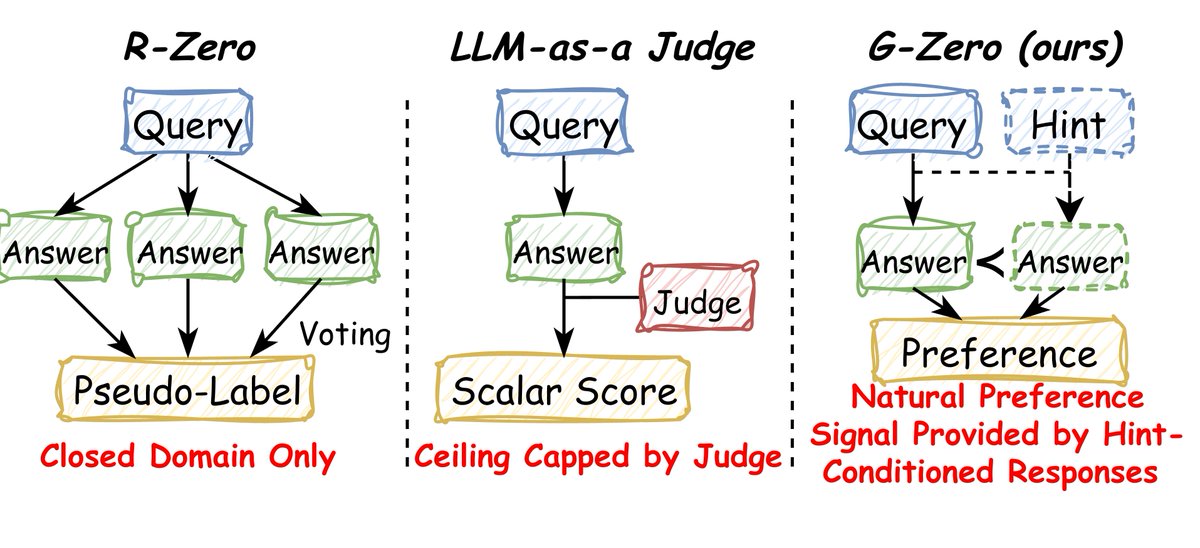
6
45
239
15,030
May 13
Yup
May 12

Symbolic learning is not a replacement for coding agents, it's a replacement for gradient descent & NNs: a low-level, completely general, extremely scalable new learning substrate.
88
mconcat retweeted

May 2
🎉OrthoMerge has been accepted to #ICML2026. This work introduces an elegant way to merge different model checkpoints. Kudos to my PhD students @sihany077 and @KexuanShi67338.
Feb 6

Orthogonal Finetuning (oft.wyliu.com; boft.wyliu.com) has a unique advantage of preventing catastrophic forgetting. Inspired by this property, we find that merging models within the orthogonal group can effectively reduce model conflicts and preserve both pretraining and downstream knowledge. This is our OrthoMerge framework.
The idea behind OrthoMerge is extremely simple. For OFT-tuned models, we can first map the orthogonal adapters to Lie algebra with inverse Carley transform and then perform merging there. This guarantees the merged model differs from the pretrained model only up to an orthogonal transformation.
A better news is that OrthoMerge can also be applied to non-OFT-tuned models. By solving the orthogonal procrustes problem, we can have the projected component of the adapter onto the orthogonal group. OrthoMerge will then be applied there and the residual component can be merged using conventional merging methods. That said, OrthoMerge can be used together with existing model merging methods!
This is a great example of simple yet effective ideas. Great efforts by my PhD students Sihan Yang and Kexuan Shi. The project is already open-sourced and feel free to give it a try!
Project: spherelab.ai/OrthoMerge/
Paper: arxiv.org/pdf/2602.05943
Code: github.com/Sphere-AI-Lab/Ort…
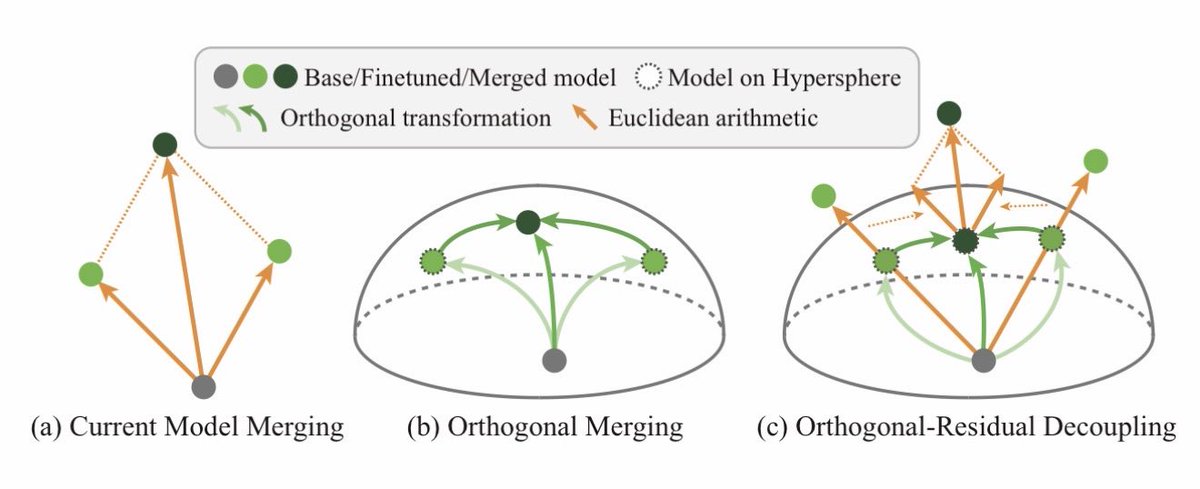
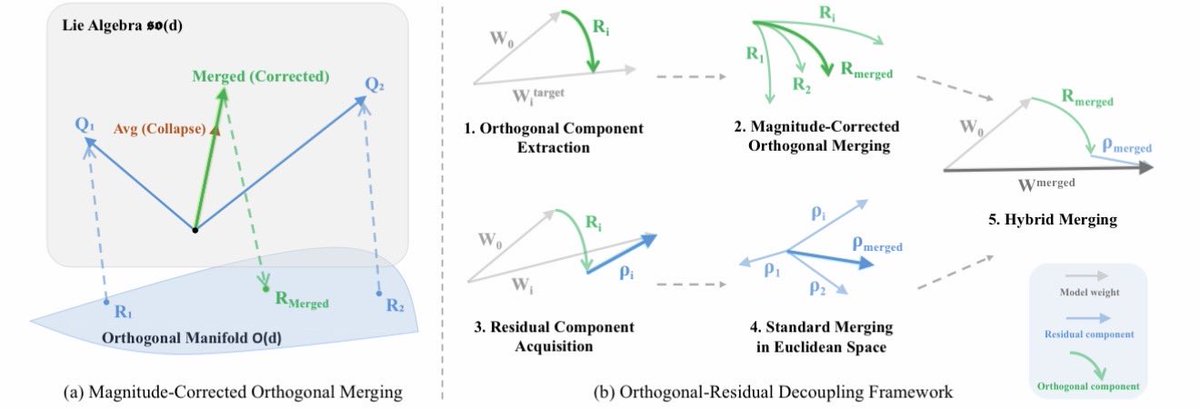
2
21
181
25,924
mconcat retweeted

Apr 26
mechinterp research in a nutshell
Apr 24


7
30
494
28,367
Apr 27
If we put the multiple language models in a society where different game theoretic mechanisms from our human one get applied, we will see the whole universe of shadow cultures
Apr 25

spooky implication that there is potentially some whole universe of "shadow math" that you have to make inhuman mental movements to access so no human have done so yet, that is going to be increasingly revealed by frontier models

1
92
mconcat retweeted

Apr 23
Self-play led to superhuman Go performance, why hasn’t it for LLMs?
In practice, long run self-play plateaus like RL. We study why this happens, and build a self-play algorithm that scales better. It solves as many problems with a 7B model as the pass@4 of a model 100x bigger.
31
152
1,021
145,841
mconcat retweeted

Apr 22
Introducing Mirror: An Automated Journal of AI Interpretability. (@mirror_research)
It is off to a strong launch with 240 empirical studies in AI interpretability conducted purely by LLM agents.
Details about this “auto-journal” and a few of my favorite studies below:

16
54
302
24,917
mconcat retweeted

Apr 21
Introducing ml-intern, the agent that just automated the post-training team @huggingface
It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem.
It can pull off crazy things:
We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%.
In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%.
For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on hf.co/spaces, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously.
How it works?
ml-intern makes full use of the HF ecosystem:
- finds papers on arxiv and hf.co/papers, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on hf.co/datasets
- browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data
- launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains
ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like.
Releasing it today as a CLI and a web app you can use from your phone/desktop.
CLI: github.com/huggingface/ml-in…
Web mobile: huggingface.co/spaces/smolag…
And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.
138
641
4,661
1,250,309