
Building @visionagents_ai • @GoogleDevExpert Dart & Flutter • @FlutterComm 💙 • Formula 1 fanatic 🏎 • Striving for excellence 💫
Joined October 2014
- Tweets 14,790
- Following 743
- Followers 8,132
- Likes 59,093
1,461 Photos and videos








Friends, I am happy to share that I am now a @GoogleDevExpert for Flutter 🎉.
THANK YOU to everyone who supported me over the years. You all are amazing 💙.
It is even more special since I am now the first GDE not only for my country but also the Caribbean 🎉
99
39
656
🍿
Jun 13

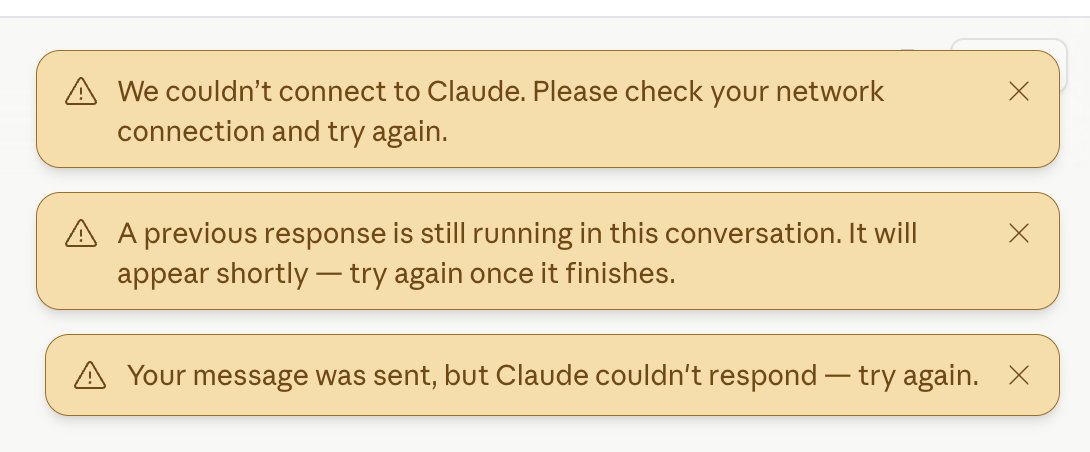
I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
2
2
537
With the World Cup starting this week, I thought it would be the perfect time to revisit our AI Football commentator and look at how things have changed with the new model releases over the last 6 months. It’s no Thierry Henry, but models are getting better and faster at video understanding. Everything here is running in real-time, the annotations are coming from @roboflow RF-DETR nano running locally, responsible for detecting players ball, a processor specifically handling the match state and keeping track/understanding of possession, shirt colours, visible jersey numbers, pressure, and field position (backed by Gemini 3.5 Flash) and the commentator itself using OpenAI realtime.
@OpenAI Realtime receives the annotated video stream at 3 FPS and generates the spoken broadcast-style commentary. Detection events from RF-DETR trigger short prompts, and a debounce plus speaking guard keeps the agent from interrupting itself.
The important design choice is that the realtime model is not doing everything alone. Roboflow gives it visual structure, Gemini helps maintain continuity, and OpenAI Realtime handles the fast spoken delivery. The result is a smoother demo: users see the actual overlays, while the commentator can reference grounded details like “green number 6” or “white number 11” instead of giving generic sports commentary.
I’m excited about models like the recent Interaction model from @thinkymachines, capable of full-duplex understanding. Perhaps in another 6 months it’ll be worth coming back to this and comparing today’s models with tomorrow's :)
Github: github.com/GetStream/Vision-…
Example: github.com/GetStream/Vision-…
2
4
277
Nash 🥇💙 retweeted

Jun 10
Fable is a good model. As with all new models, it is simultaneously excellent and entirely unremarkable (relative to other models). It is slow and expensive, and the "loops are all you need" discourse they are pushing is obvious in the context of someone using Fable-class models
What I've found so far is that for broad scope design (code architecture) tasks, Fable is unremarkable. Or, not better enough to justify its cost and speed.
But in highly targeted goal-oriented loops, it is another beast entirely. It is very slow but produces very good results.
I let it churn on optimizing a SwiftUI-layout resolver in Go I wrote and it was able to bring it down to an order of magnitude I could not reach myself (micro => nanosecond scale). But it took 2 hours and $40 to do it and I had to claw back some changes it overfit to Apple Silicon. Still, very worth it.
In comparison, for "implement this feature/change" iterative work, I ran head-to-head Fable vs GPT5.5 vs. GLM-5.1. They all produced equally acceptable final results, but GPT5/GLM did it in a couple minutes and Fable was churning away for 40 minutes. And GLM cost me less than a dollar, GPT5.5 ~$1.50, and Fable cost $9.
You can see that in this context, interactively working with an agent is nonsense. Its too slow. You need to write loops to keep the agent working and you probably want to highly parallelize the work being done. As with all things, I think a balance makes sense...
My sense is that I'd reserve Fable for targeted, surgical analysis and work. Not for daily driving everyday tasks.
I'm going to keep spending a shitload of money (relatively) and maining Fable for the rest of the week to continue to judge, will report if anything changes. I'll continue to head-to-head as well.
101
195
3,599
271,270
Nash 🥇💙 retweeted

Hola, Bonjour, Hello Gemini 3.5 Live Translate 👋
This new model brings speech-to-speech in 70 languages, auto-detection, native audio that holds onto tone and pacing, and continuous translation instead of turn-by-turn.
Check out the docs below to get started 👇
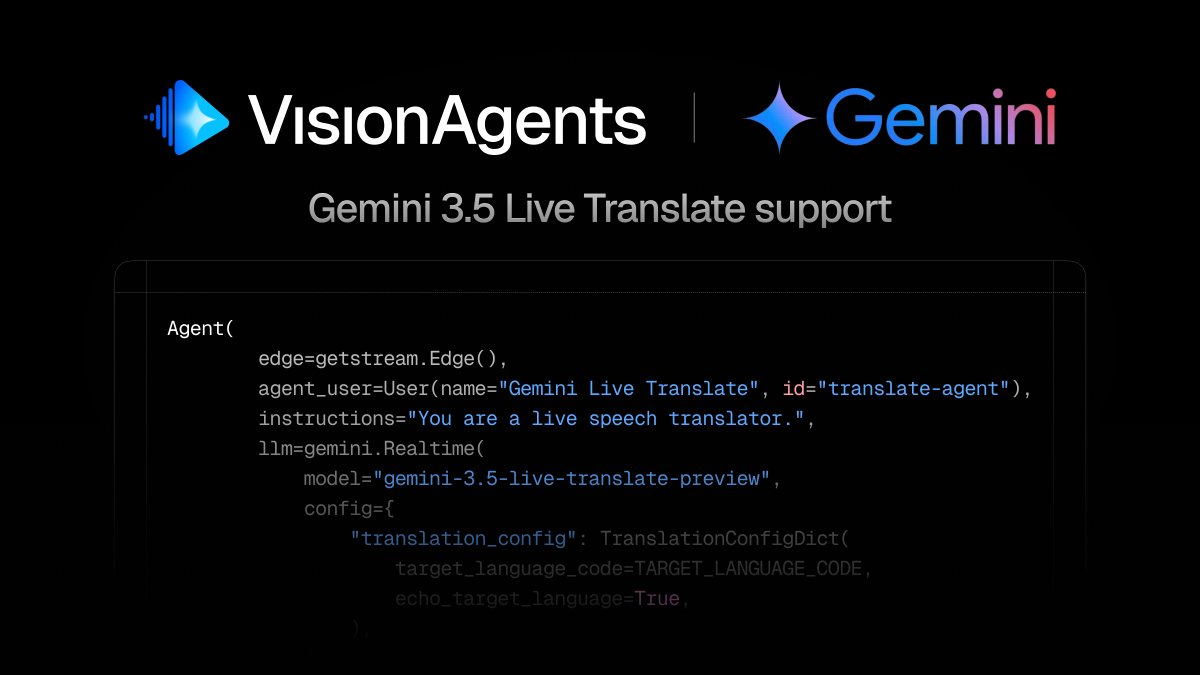

Gemini 3.5 Live Translate is now available in public preview on the Gemini API and Google AI Studio. 💬
This model translates speech as it streams, giving developers a blazing-fast, low-latency engine to build some seriously cool audio apps. See it in action 👇
3
4
15
1,948
Nash 🥇💙 retweeted

Good take
My guess is
- demand for intelligence is near infinite
- but 80% of workloads will be running on 99% cheaper models within 12-18 months
- 20% of workloads will still run on latest gen models where IQ maxing is important (scientific breakthroughs, higher level ochestrator agents?)
- rough analogy might be what % of macbooks or gaming PCs sold have the maxed out specs for CPU/GPU, prices are falling much faster than Moore's law here though
- this leads me to think the limiting factor will be energy and compute, not better models
At Coinbase we're working hard on routing prompts to cheaper models where appropriate, and in some cases have been able to keep costs roughly flat, while token usage continues to grow exponentially.
Jun 2

The most basic way AI could blow up imo. I'm not saying it does but this is the most obvious way I can see it happening
- Per seat subscriptions are massively subsidized. The flat fee was priced way below what heavy usage actually costs
- For real business use you have to move to the API anyway. Data protections, work integrations and compliance officer approval
- On the API you pay metered rates, and businesses are burning credits way faster than the per seat pricing ever led them to expect
- This is everywhere right now. Internally for us, Codex users, Uber torching its entire 2026 AI budget in 4 months, the Microsoft comments. Just go try an API
I shared more on this here: x.com/Shaughnessy119/status/…
- And I don't think most businesses have the money to keep paying increasing API rates without a real change to how they operate (caps needed)
- Because they have a cheap alternative. They can reach open source models through any aggregator (OpenRouter, Venice, Baseten, Together) and still get strong privacy. Venice private data centers, or E2EE/TEE serving GLM 5.1.
More on open source inference provider raises here: x.com/Shaughnessy119/status/…
- And the discount is enormous. DeepSeek V4 codes within a hair of Opus on SWE bench at roughly 1/30th the price, and the cheapest open models run closer to 1/100th
- Chinese labs open source frontier grade models. The model is the single biggest cost an inference provider has, and they get it for free
- This idea dies if China goes closed source. That is actually bullish web2 AI labs, because if everyone is closed you pay up for the best intelligence. China goes closed source if they are tired of giving away an asset and they want the revenue and data flow to train new models
- Is this showing up in web2 AI lab revenue yet? No. Revenue is off the charts. Anthropic went from 9B to 47B run rate in five months
- So go forward, what happens?
- I think revenue slowly starts leaking to the open source inference providers (see Venice usage, OpenRouter's $113M raise, Baseten is raising at $11B or triple its valuation in three months, on revenue that went from $200M to $600M annualized in a single quarter)
- It doesnt move overnight, but it caps the labs ability to raise prices, and margins are already deeply negative. OpenAI is reportedly running near negative 122%
- With margins that bad there is no cash flow, so the labs are fully dependent on outside capital to buy GPUs, train models, and keep subsidizing usage (I.e. see Google tapping $80b equity sale, granted 30b for employee RSU taxes. Clearly they think Equity is overvalued or you wouldn't sell it)
- The break comes when that capital stops. Pricing is capped so margins cant improve, and the moment investors lose conviction on payback, the whole flow reverses
- Why would they lose conviction on payback? Back to the start - the inability to improve margins or get businesses to pay more
- This is also limiting, if we start making new drugs with AI or create entirely new businesses, you better believe people will pay up to the max for AI usage
473
616
6,615
2,800,966
Nash 🥇💙 retweeted

Jun 6
Quite a week for open-source AI. Especially American open-source. Nemotron 3 Ultra is the most important release in quite some time. And some really cool RL and fine-tuning work from Harvey.
Jun 5

Before the week ends, let's acknowledge one of the most INSANE week ever for open AI, with 25 notable open-weight drops across every modality:
🧠 LLMs
→ NVIDIA Nemotron 3 Ultra: 550B hybrid Mamba-MoE, only 55B active, 1M context, MMLU 89.1. NVFP4 variant claims ~5x throughput on Blackwell. First openly-weighted 550B hybrid Mamba-Transformer, closing the gap with frontier closed models.
→ Google Gemma 4 12B: fully open dense any-to-any (text/image/audio/video), 256k context, encoder-free, 140 languages, AIME 2026 at 77.5. Shipped with a 23-checkpoint QAT wave (mobile ONNX MLX). Most deployable model of the week.
→ StepFun Step-3.7-Flash: 198B sparse MoE VLM, ~11B active, SWE-Bench PRO 56.3. Apache 2.0.
→ Liquid AI LFM2.5-8B-A1B: edge MoE, just 1.5B active, 128k ctx, MATH500 88.8, MLX-ready. Best on-device option this week.
→ JetBrains Mellum2-12B-A2.5B-Thinking: their first open MoE, near-Qwen3-14B coding at 2.5B active. Apache 2.0.
🎨 Image gen (the surprise of the week)
→ Ideogram 4: their FIRST-EVER open weights. 9.3B flow-matching DiT trained from scratch. #2 overall behind GPT Image 2, top open-weight model on Design Arena LMArena. Strongest open checkpoint for text-rich images, full stop. It has taste. Still can't believe this is open weights.
🔊 Audio & Speech (a breakout week for open TTS, 4 labs shipped)
→ Boson Higgs Audio v3 4B: 102 languages, 21 emotions, singing/whispering/shouting, sub-second TTFA.
→ RedNote dots.tts: the only fully continuous (no codec) open TTS pipeline, Apache 2.0.
→ Google Magenta RealTime 2: real-time music gen, <200ms latency, text audio MIDI. multimodalart ported it to PyTorch within hours with live ZeroGPU demos.
→ NVIDIA Nemotron-3.5 ASR: 600M streaming, 17x more concurrent streams vs Parakeet RNNT 1.1B.
👁️ Vision & VLMs
→ PaddleOCR-VL-1.6: SOTA document parsing at 1B params, Apache 2.0.
→ Baidu NAVA: 6.3B joint audio-video gen, best-in-class A/V sync, Apache 2.0.
🎬 Video, 3D & World Models
→ NVIDIA Cosmos3-Super: 64B omnimodal world model coupling action trajectories with video audio gen, for Physical AI.
→ JD JoyAI-Echo: up to 5-min multi-shot text-to-video on LTX-2.3.
→ ByteDance Bernini-R VAST TripoSplat (single-image-to-3D Gaussian splats, MIT).
47
69
842
721,143
What a sentence
Jun 5

The Spain national football team has arrived in downtown Chattanooga for the FIFA World Cup
306

Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
199
462
3,481
1,241,012
Nash 🥇💙 retweeted

Jun 1
Congrats to @MiniMax_AI on the M3 launch — and great to see @visionagents_ai ship day-zero integration, with Tencent RTC recommended in the docs as the edge transport for the lowest end-to-end latency across China & Asia.
M3 for intelligence. Vision Agents for the agent loop. Tencent RTC for real-time transport.

Congrats to the @MiniMax_AI team on the release of M3!
👉 A frontier-class open-weight model
👉 1M context window
👉 Native multimodality (image & video)
2
3
400
Nash 🥇💙 retweeted

let's gooo 🔥 M3 @visionagents_ai for real-time voice & video
go build something hype!
Congrats to the @MiniMax_AI team on the release of M3!
👉 A frontier-class open-weight model
👉 1M context window
👉 Native multimodality (image & video)
7
7
81
419,417
Awesome to see the open models continuing to improve at a rapid pace. It really does feel like the gap between open and closed models is starting to narrow. Congrats on the release, @MiniMax_AI!
Congrats to the @MiniMax_AI team on the release of M3!
👉 A frontier-class open-weight model
👉 1M context window
👉 Native multimodality (image & video)
3
185
Nash 🥇💙 retweeted
Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

560
1,154
10,971
4,944,396
