
Data Scientist, using data to tell your product's story.
Joined March 2016
- Tweets 787
- Following 210
- Followers 104
- Likes 675
67 Photos and videos














gordana neskovic retweeted

May 4
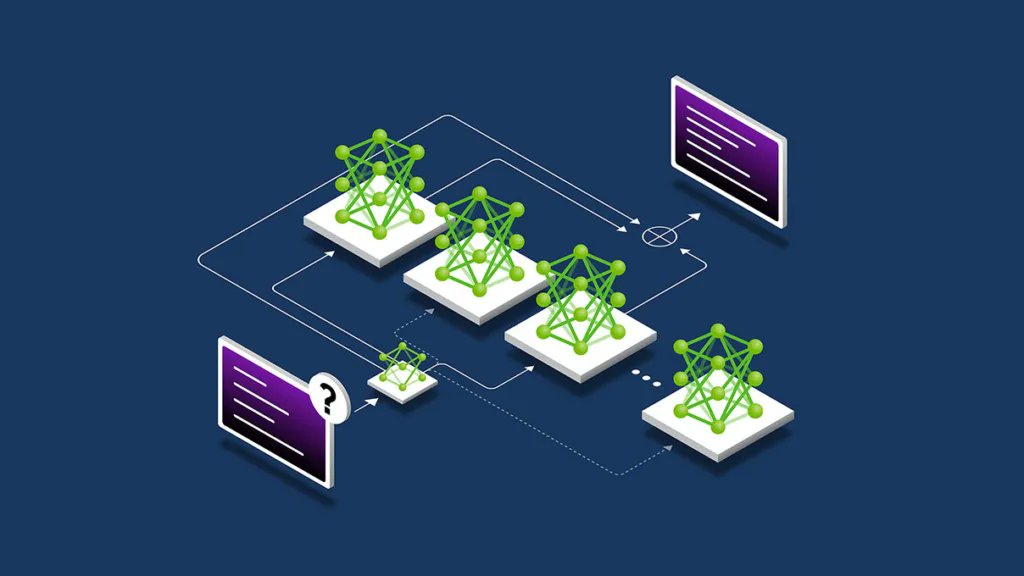
📢 EnterpriseOps-Gym is now accepted to ICML 2026 🇰🇷✨
website: enterpriseops-gym.github.io/
🧩 1,150 expert-curated tasks
🏢 8 enterprise domains
🧰 512 tools
✅ Deterministic verifiers (Outcome Integrity Compliance)
📦 Fully containerized, no enterprise instance required
📊 𝗙𝗿𝗲𝘀𝗵 𝘂𝗽𝗱𝗮𝘁𝗲: GPT-5.5 numbers are out (alongside the strongest open and closed baselines). We will keep updating as new models drop because long-horizon reliability is moving fast, and we want to stay current.
One exciting (and humbling) signal: we’ve already seen frontier lab teams experimenting with EnterpriseOps-Gym to stress-test and improve their agents: including folks at OpenAI, Mistral AI, and NVIDIA AI. 🙏
📈 𝗘𝗮𝗿𝗹𝘆 𝗿𝗲𝘀𝘂𝗹𝘁𝘀 𝗮𝗿𝗲 𝗽𝗿𝗼𝗺𝗶𝘀𝗶𝗻𝗴: Top open models including NVIDIA Nemotron Super are showing strong performance, in some cases competing with frontier models.
@shiva_malay @sagardavasam @PShravannayak @turingcom @jonsid @ServiceNowRSRCH @Mila_Quebec
2
15
45
3,406
gordana neskovic retweeted

Apr 28
.@nvidia Nemotron 3 Nano Omni. First on DigitalOcean. 🤖🆕
One model. Text, vision, & native tool use. Document intelligence, multimodal RAG, agentic workflows. One API call, one bill.
Generally available today on DigitalOcean Serverless Inference. Try it in the Multimodal Playground in the comments. ⬇️
1
6
14
2,283

Nemotron 3 Nano Omni is available locally on Ollama!
This requires the latest Ollama 0.22 release.

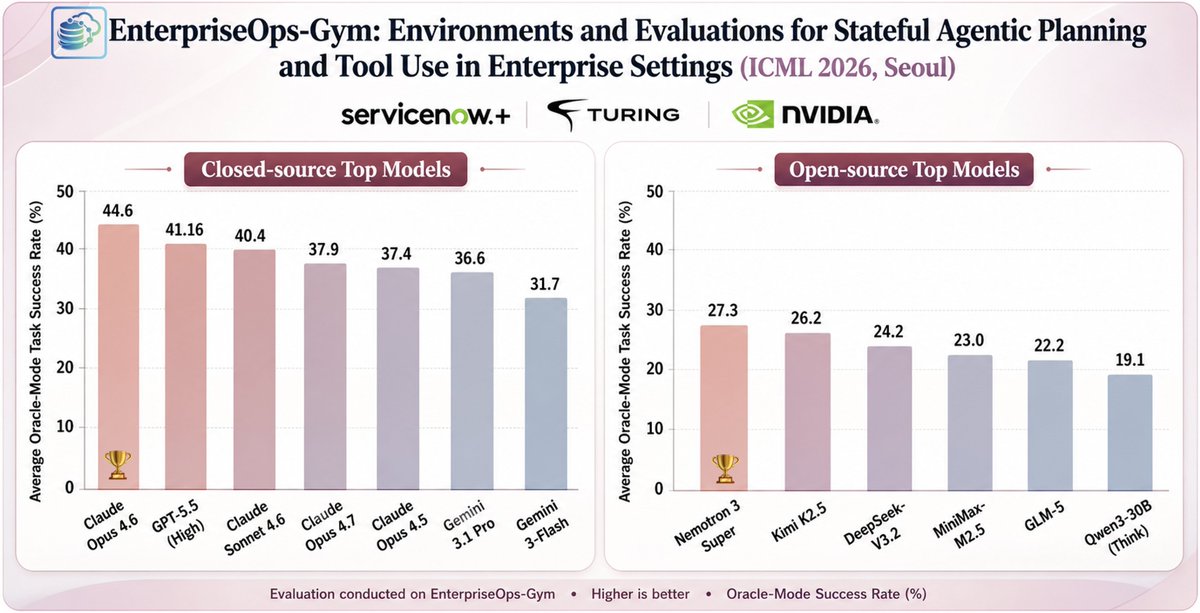
Meet Nemotron 3 Nano Omni 👋
Our latest addition to the Nemotron family is the highest efficiency, open multimodal model with leading accuracy.
30B parameters. 256K context length. 🧵👇
37
42
426
51,298
gordana neskovic retweeted

Apr 28
NVIDIA Nemotron 3 Nano Omni is live on Nebius Token Factory.
A major step forward for multimodal reasoning, bringing video, audio, images, documents, and text into a single model.
Bringing these workloads into production requires consistent performance, low latency, and efficient scaling. Nemotron 3 Nano enables this with a unified efficient architecture, while we focus on the infrastructure layer that ensures it performs reliably under real-world load.
From capability to production.
Try it today 👇

6
9
41
5,155
gordana neskovic retweeted

Apr 28
Congrats to @nvidia on releasing NVIDIA Nemotron 3 Nano Omni! GMI is supporting it on Day 0.
Nemotron 3 Nano Omni is an open multimodal model with highest efficiency that powers sub-agents to complete tasks faster across vision, audio, and language.
· 30B-A3B MoE
· 256K context
· ~2x throughput
· ~2.5x less compute on video
start on GMI today 👇
gmicloud.ai/en/blog/running-…

2
9
33
3,634

NVIDIA Nemotron™ 3 Nano Omni is deployed on Vultr.
Available on dedicated GPU clusters or serverless inference accelerated by @nvidia Dynamo 1.0, Nemotron™ 3 Nano Omni accelerates faster, more efficient, more accurate enterprise agent task completion: blogs.vultr.com/nvidia-nemot…

7
10
3,795
gordana neskovic retweeted

Apr 28
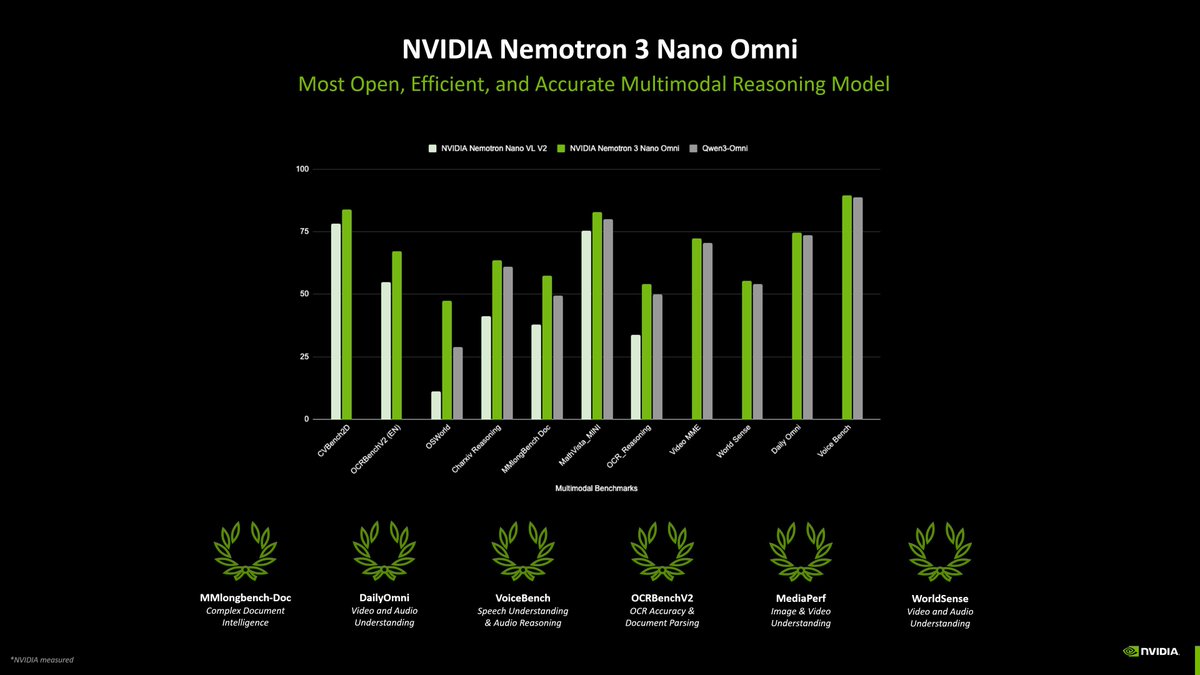
NVIDIA Nemotron™ 3 Nano Omni is live on OpenRouter.
An open 30B-A3B multimodal model for agentic workflows: text, image, video, and audio in → text out, with a 256k context window and efficient MoE architecture for computer use, documents, and AV reasoning.
8
23
206
13,689
gordana neskovic retweeted

Apr 28
Excited to support @NVIDIA Nemotron 3 Nano Omni, now available on Fireworks.
It's the first open model that handles vision, audio, video, and text in a single inference loop. Built for multimodal sub-agents at scale, with 9× higher throughput than Qwen3 30B. 256K context.
Now available on Fireworks for on-demand deployments. →fireworks.ai/models/firework…

1
4
58
6,027
gordana neskovic retweeted

Apr 28
@NVIDIA Nemotron 3 Nano Omni is now on Together AI.
Enterprise multimodal AI — video, audio, image, documents & text — optimized for speed and scale.
✅ ~3B active params, 9x higher throughput
✅ Fully managed, zero infra headache
✅ Secure, zero-trust architecture
Build faster agentic systems. Today. 👇

2
3
13
2,070
gordana neskovic retweeted

Apr 28
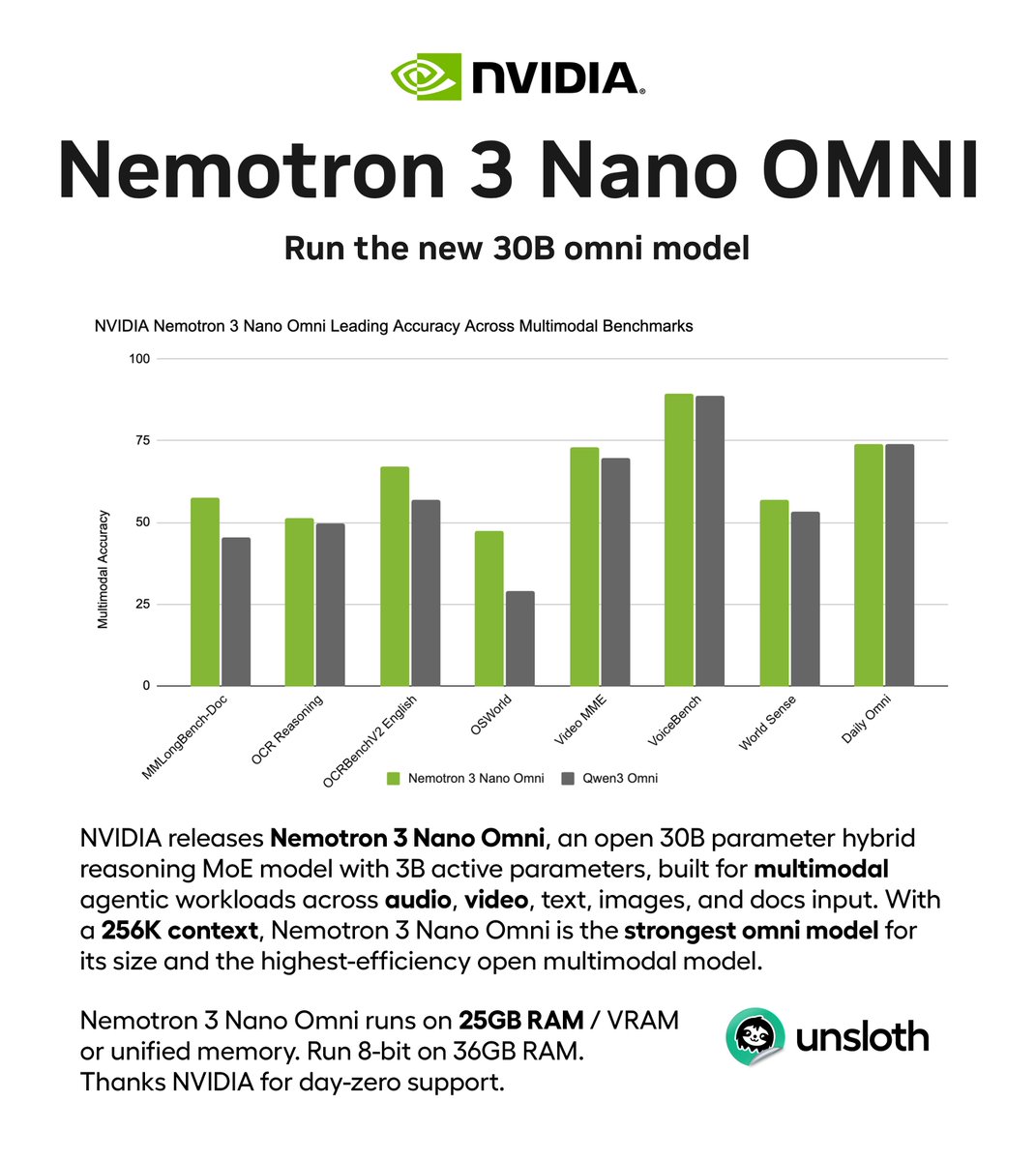
NVIDIA releases Nemotron-3-Nano-Omni, a new 30B open multimodal MoE model.
Nemotron-3-Nano-Omni-30B-A3B is the strongest omni model for its size and supports audio, video, image and text.
Run on ~25GB RAM.
GGUF: huggingface.co/unsloth/NVIDI…
Guide: unsloth.ai/docs/models/nemot…
44
134
940
71,091
gordana neskovic retweeted

Apr 28
Nemotron 3 Nano Omni is now live on FriendliAI —Day-0 support.
One open model for video, audio, images, docs text .
No multi-model pipelines.
Optimized for production on Dedicated Endpoints.
2
2
6
640

NVIDIA Nemotron 3 Nano Omni is now available on Clarifai with Zero Day support.
A 30B A3B multimodal reasoning model built for agent workflows across documents, images, video, audio, and text.
Why it stands out:
• Multimodal input across text, image, video, and audio
• Hybrid MoE Transformer-Mamba architecture
• 300K context window
• Runs on a single H100, H200, or B200
• 400 tokens/sec on Clarifai Reasoning Engine

2
4
12
1,856

NVIDIA Nemotron 3 Nano Omni is now live on fal, available at launch.
A single model for multimodal agents:
🔁 text, image, video, audio in one loop
🧠 1 context reasoning across complex workflows
⚡️ ~9× higher throughput with fewer inference hops
Built for real-world agent systems.

7
16
128
22,918
gordana neskovic retweeted

Apr 28
DeepInfra is an official launch partner for @nvidia Nemotron™ 3 Nano Omni — live today.
One open multimodal 30B-A3B model.
One pass over image, video, audio, docs text.
No multi-model pipelines.
OpenAI-compatible API, usage-based pricing.
$0.20 in / $0.80 out per 1M tokens

2
6
45
4,428

Introducing @NVIDIA Nemotron 3 Nano Omni.
NVIDIA Nemotron 3 Nano Omni is an open multimodal foundation model that unifies audio, images, text, and video into a single context window. It powers subagents for use cases like computer-use agent, document intelligence, and video and audio reasoning at scale.
Unlike most agent systems that rely on separate models for speech, vision, and language, this model combines audio and vision encoders into one unified architecture. This simplifies agentic workflows and enables smarter and more efficient agents.
Read more: baseten.co/blog/nvidia-nemot…

1
8
32
4,936
gordana neskovic retweeted

Mar 17
After much reflection, I have decided to resign from my position as Director of the National Counterterrorism Center, effective today.
I cannot in good conscience support the ongoing war in Iran. Iran posed no imminent threat to our nation, and it is clear that we started this war due to pressure from Israel and its powerful American lobby.
It has been an honor serving under @POTUS and @DNIGabbard and leading the professionals at NCTC.
May God bless America.

72,413
215,815
840,532
103,433,516


gordana neskovic retweeted

Mar 16
NVIDIA Announces NemoClaw for the OpenClaw Community nvidianews.nvidia.com/news/n…
1
2
31

Tokenization can be a #TTFT bottleneck for long-context #LLMs.
That's why we worked with the @NVIDIA Dynamo team to built fastokens:
⚡ Up to 17× faster on 50K tokens
📉 Reduced TTFT by up to 40%
Read more: crusoe.ai/resources/blog/red…
#NVIDIAGTC #GTC2026 #AIInfrastructure

4
13
6,805