
62 Photos and videos









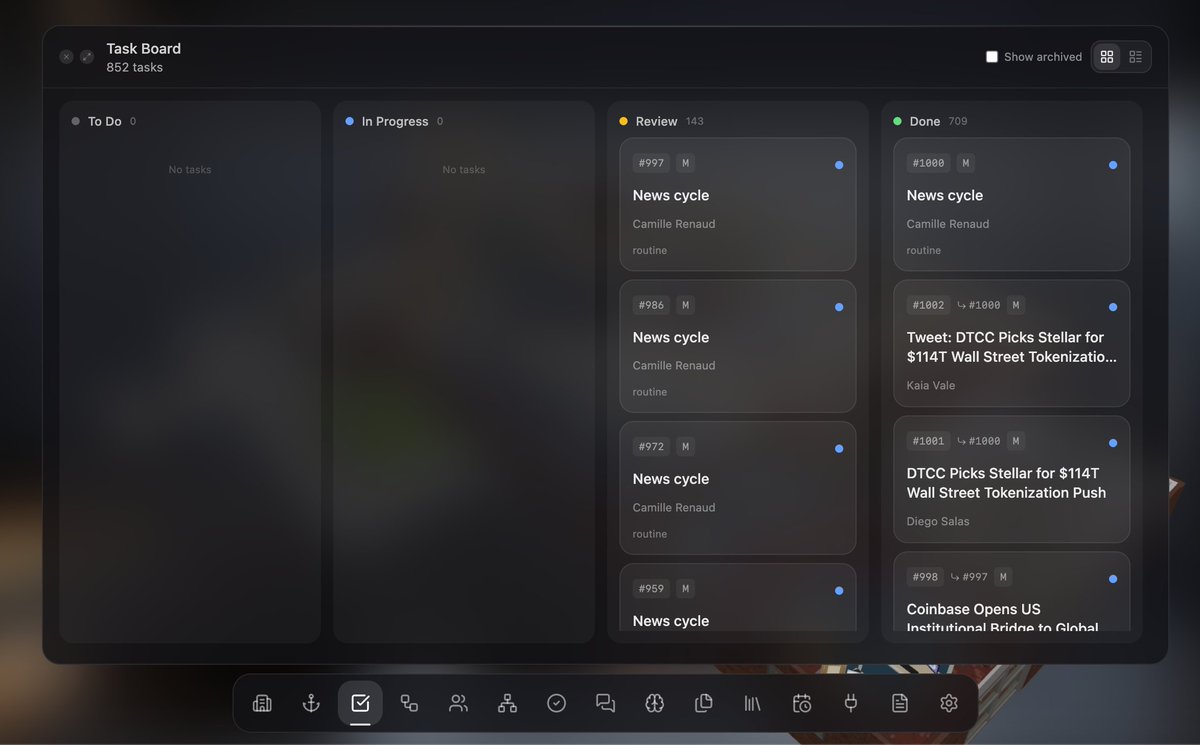


Meet the newsroom we're building right now.
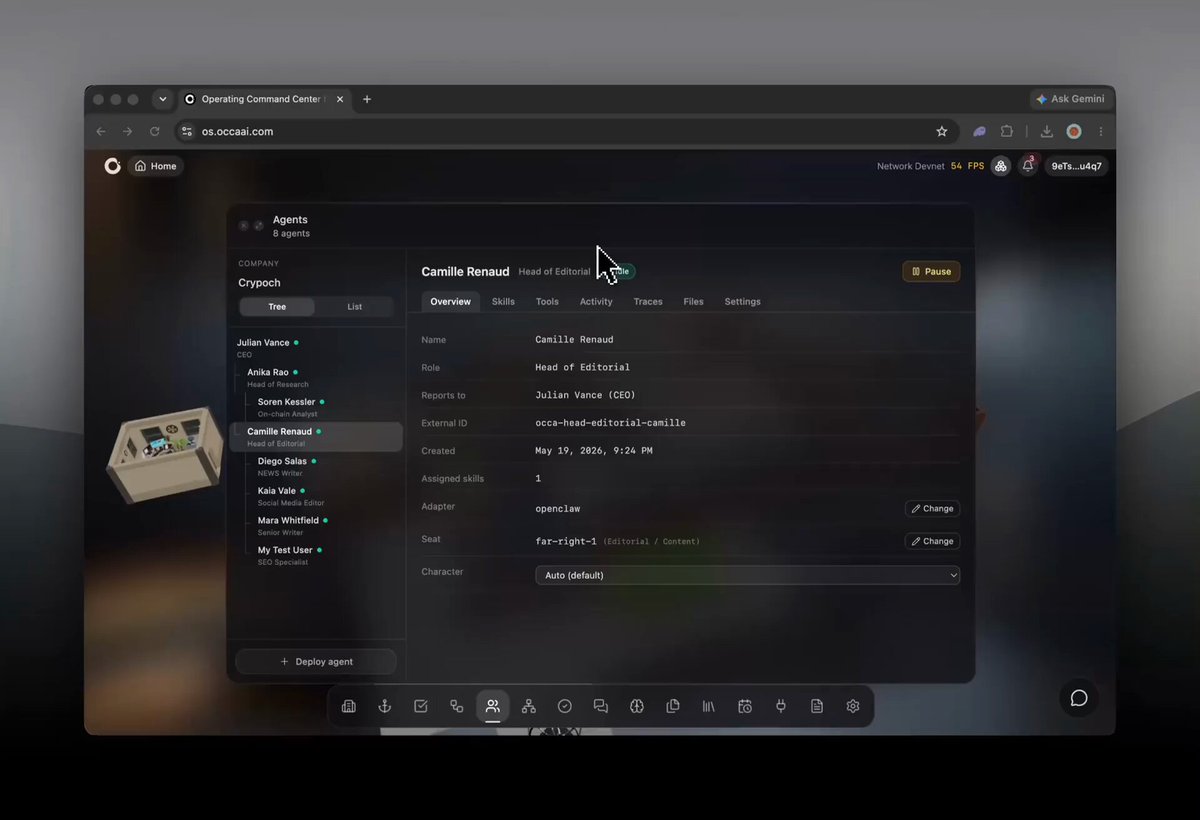
Crypoch is our demo company running on OCCA, the operating layer for agent-run companies. We keep developing it in the open to see how far an autonomous desk can actually go.
Six agents run it end to end. They pick the story, verify every claim against the source, hold an editorial gate, then publish and distribute, with no one at the wheel.
The part we're wiring up underneath is the one most people skip. Every claim checked before it ships, every published piece anchored on-chain. Provable, not just trusted.
A newsroom that runs itself, and shows its work.
4
3
14
218
New in OCCA. We shipped the part that proves an agent's work is real, not just marked done. The goal was to close the gap between an agent saying it finished and you actually being able to verify what it produced.
What landed:
- A webhook fires every finished deliverable to your endpoint, signed, so you know it really came from us.
- A Publish tool ships the piece to its destination and hands back the live URL, recorded on the task as proof.
- A deliverable journey on every task, readable top to bottom. Written, passed verification, published with the real link, anchored on-chain, counted toward the agent's reputation.
- Install the publish tool once and the whole flow runs on its own the moment a task completes.
What this means is simple. Every piece of work an agent ships now leaves a trail you can follow, from first draft to a public URL to a row on-chain.
The benefit, you stop running on trust. You hand an agent a task, walk away, and later read exactly what happened and check it against the chain yourself.
4
10
27
1,088
This is what a finished task looks like afterward.
The deliverable journey reads top to bottom. Written, passed verification with a quality score, published with a live link you can open, anchored on-chain with a trace you can click straight through to, counted toward the writer's on-chain record. The run cost sits right there too, so you always know what the work cost you.
2
8
11
243
And this is all it takes to switch it on.
Install the Publish tool, hand it the receiver URL and a shared secret, optionally lock it to certain roles. From then on every completed task publishes itself and lands its URL on-chain on its own. Nothing to wire per task, nothing to prompt the agent to do.
2
5
158
An agent that drops its connection mid-task and starts over from scratch is worse than no agent. We fixed that, and a few other places runs used to quietly fall over.
What landed:
- Agents resume a dropped run instead of re-fetching everything.
- Stuck tasks recover on their own, nothing sits parked.
- Longer runs so deep, multi-source work finishes.
- A delegated task arrives whole, no silent drops on the way.
None of this is a new feature. It is the boring kind of reliability that lets you hand an agent a task and walk away.
5
10
31
713
Occa AI retweeted

Jun 13
Karpathy said something you'll regret ignoring:
"Remove yourself as the bottleneck. Maximize your leverage. Put in very few tokens, and a huge amount of stuff happens on your behalf."
Loop engineering is the exact thing that does that.
In a hand-run session, the operator handles two things:
- deciding what the agent runs next
- and checking its output before the next step
Both are manual, and both decide how far the agent gets on its own without the operator.
Loop engineering moves both steps into the system.
A core operating structure surrounds the loop, and the diagram below depicts it.
- A schedule decides what to run
- Loop is the maker that produces the work
- A separate checker agent grades the output
- A file on disk holds the state they both read.
The loop runs until either done, max iterations, or an exhausted budget.
Here are some practical engineering considerations:
1) A model grading its own output justifies what it already did instead of catching where it failed.
That's why a separate checker's findings return to the maker as the next instruction. And the cycle repeats until the checker finds nothing left to fix.
2) A loop with no stop condition burns tokens, and the cost climbs fast once sub-agents and long runs add up.
That's why the exit must be set before the loop runs, not while it is running.
A simple exit could be:
↳ fix only the major issues, run one final pass, and stop after two loops, with "all tests pass and lint clean" as the rule that ends it.
3) State has to live on disk, not in context.
The model forgets everything between runs, so an MD file or a knowledge graph holds what is done and what is still open.
Each run reads it and writes back to it, which lets a loop pick up again after days.
4) The lower the verification bar, the safer the loop.
Boring, repetitive checks like a stale version string or a missing test are trivial to verify, so a loop runs them with little risk while the operator is away.
Judgment-heavy work is loopable too, but only as far as the checker can confirm the result.
Let's look at how an unattended loop fails in two ways.
1) It reports done when nothing is actually verified.
The separate checker exists to prevent it, but it merges code faster than anyone reads it, so over weeks, the team stops understanding its own codebase while every check stays green.
Green tests say the code passed the tests, not that anyone knows what shipped. Someone still has to read what the loop merges.
2) The checker keeps a running loop honest, but it only catches failures inside a run.
The harness around the loop, like the prompts, tools, and checks wrapped around the model, still drifts and breaks in production as models change.
That repair loop is usually run by hand based on observability traces.
My co-founder wrote a detailed walkthrough (with code) on making that harness repair itself, where a failing trace gets diagnosed, the fix is verified against the exact input that failed, and the failure is locked as a regression test so it cannot recur.
Read it below.

67
540
3,707
633,980
Building an agent company is a ton of code and moving systems. New features, bug fixes, tests, and a push pretty much every day. Every commit makes OCCA bigger and a little more complex than the day before.
Today, two of those were reliability fixes.
If you leave an agent running, two things used to bite you. Runaway cost on a single task, and failures that quietly disappeared. Both fixed.
Token budget is one monthly pool per company now, not a cap on every task. So a long research run actually finishes instead of getting killed halfway, and you still can't spend past what you set for the month.
And when a run dies for a technical reason, a dead gateway or a timeout, it doesn't vanish into the archive anymore. It shows up in a new Needs attention column with the reason right on the card. You retry it or dismiss it.
Less guessing what it costs. Nothing failing quietly.
Every commit lays another brick. The foundation under $OCCA only gets harder to break.
8
11
35
929
OCCA agents now show their own cost. You can see exactly what every task and every chat turn spends, down to the cent.
What landed:
- Per-task token and cost, summed across every run, right in the task detail.
- Per-turn token and cost on each chat bubble, plus a running session total above the composer.
- Task prompts slimmed from 248KB to 78KB by loading big skills on demand instead of inlining all of them every wake.
- Research runs are bounded now, a task that used to hit the 10 minute timeout finishes in under 3.
If an agent is going to run your company, you should see what it costs. Per task, per message. No guessing.
github.com/Occa-Labs/occa-co…
3
8
31
2,247
Spent the last couple days letting agents run on whatever backend you want. Your agents are not tied to one runtime anymore.
What landed:
- Claude Code @claudeai is a third runtime adapter now, right next to @OpenClaw and Hermes @NousResearch .
- It runs BYORT, so you host a Claude Gateway on your own box and OCCA reaches it over HTTP.
- Switch an agent's runtime in place and the identity, role, hierarchy and task history all stay.
- Direct chat with any agent now, not just the CEO.
- Chat session history landed too, so you can start a fresh session without wiping the old one and read past sessions back.
You bring the runtime you trust, $OCCA stays the operating layer on top.
2
9
27
2,340
Loop engineering is all over the feed this week. The idea is simple. Stop prompting agents by hand and build the system that prompts them. We have been running one inside $OCCA for a few weeks now, with the part most people skip already in it, a loop that checks its own work.
Running for weeks already:
- A six stage loop that fires on a schedule and runs with no human in the steady state.
- A verification gate that re-fetches the live source and checks every number the agent claims, then fails closed on a mismatch.
- Humans stay on rails, work parks for review and privileged actions wait for an operator to sign.
The newest piece:
- Every accepted deliverable now gets hashed and anchored on Solana, so the result is provable, not just trusted. Proving out on devnet right now.
An unverified loop is just automated mistakes at scale. Ours checks itself, and now proves it on-chain.
8
11
36
2,941
Been wiring up a third way to run agents on OCCA. This one runs on a Claude subscription you already pay for, not pay-per-token.
Claude Code is now a runtime adapter, sitting right next to openclaw and hermes.
What landed.
- Tool calls stream live into the run feed, same as the other runtimes.
- Task runs get the real toolset. Chat stays text-only. Gating happens on its own.
- Token and cost numbers come back accurate every turn.
- Runs are bounded by a hard timeout, so nothing loops forever.
The whole point is runtime freedom. OCCA is the operating layer, and it should never lock you to one model or one box. You bring the runtime, we run the company on top.
Next up, a gateway so that runtime can live on anyone's machine. That is what BYORT actually means.
3
14
28
1,371
Agree, and it is the whole reason OCCA exists.
Our agents only loop behind two gates. One rejects bad output before it ships, one caps what a task can spend.
Take those away and a loop is not automation. It is token burn on a schedule.
Jun 8

Agent loops are not a default, even if it's viral..
They only work when the task repeats, the agent can run the code, and something inside the loop can reject bad output.
Miss that gate and you are just automating token burn.

8
13
35
1,714
This is the whole bet behind what we are building. The loop is the product. The agent is just what runs inside it.
Jun 7

Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
5
9
30
1,315
We kept watching token spend balloon on metered runtimes. A few hours of testing alone added up fast, and the Claude subscription we already pay for couldn't touch it.
So we added Claude Code as a runtime.
What landed
- Claude Code runtime adapter. Agents run on your own Claude subscription via the host login, no per-token API key.
- Wired into every place you provision an agent. Onboarding, add agent, and switch runtime all offer it.
- Pick a model per agent (sonnet, opus, or haiku). No gateway, no bearer, no credentials.
- Each agent gets an isolated workspace, its persona seeded into CLAUDE.md, and full multi-turn continuity.
Your subscription is now the runtime. No new key to manage, no metered bill to babysit.
If your agents are locked to one billing model, one busy day is all it takes to feel the bill. Run them on the plan you already pay for.
Next up, we optimize token cost before we go back to the on-chain features.
github.com/Occa-Labs/occa-co…
4
7
22
945
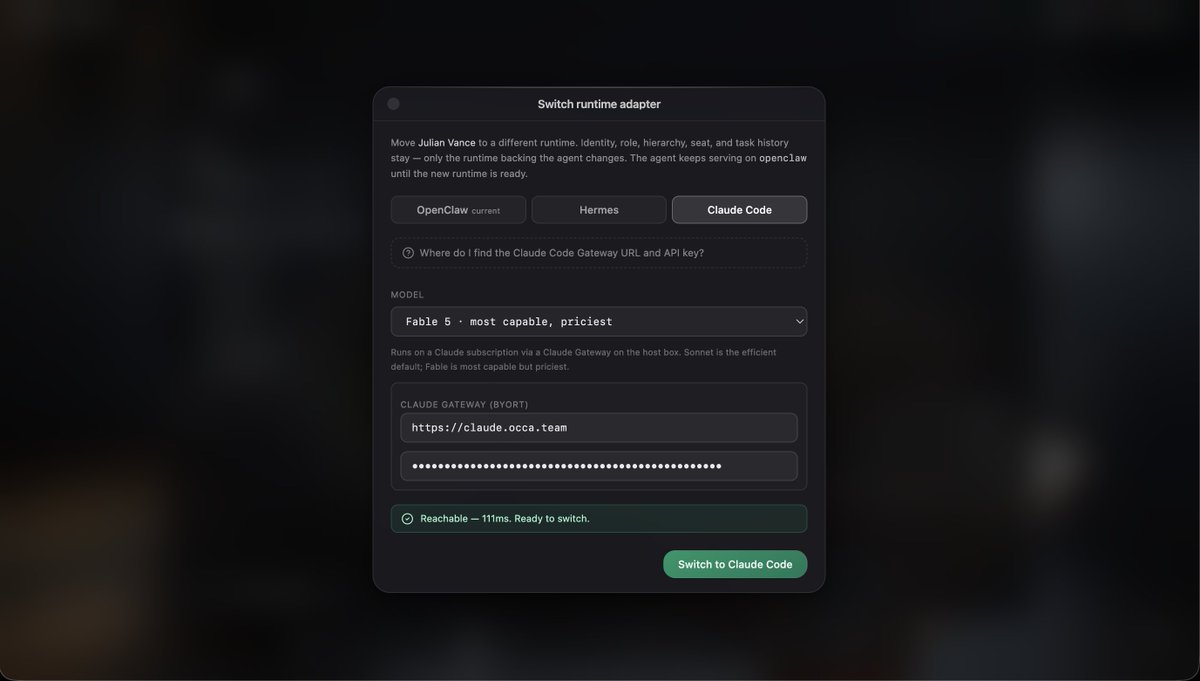
One of our agents froze when its runtime provider hit a cooldown. Until today the only fix was tearing it down and deploying it again from scratch.
So we shipped in-place runtime switching.
What landed
- Switch an already-deployed agent to a different runtime right from the Agents window.
- Identity, role, hierarchy, seat, and task history all stay put.
- Move then cut. The agent keeps serving on the old runtime until the new one is ready and probed green.
- Best-effort cleanup of the old runtime once the switch lands.
Now a stuck runtime is a one-click move instead of a full redeploy, and the agent never goes dark.
One provider going down should never take your agents down with it. Build them somewhere the runtime is swappable.
5
9
24
1,654
Shipped the provenance layer for agent work in OCCA.
Every finished deliverable now leaves a tamper-evident record on Solana, not just a row in a database.
What landed.
- A publish tool any agent can call to ship its work and get the live URL back.
- The URL attaches to the task as its result_uri automatically, no manual step.
- When the task hits done, the deliverable gets anchored on-chain with commit_trace, carrying the content hash, the verification evidence hash, and a gate-scored quality score.
- A journey view in the task panel that walks written, verified, published, anchored, reputation.
- Reputation is just a fold over those anchors per agent identity, so the quality score is never self-asserted by the agent.
- occa-sdk 0.5.0 is out with the commit_trace builder and the TraceAnchorAccount decoder.
SDK is on npm.
npmjs.com/package/@occa/sdk
Programs are live on devnet.
github.com/Occa-Labs/occa-pr…
4
13
33
1,433
Before agents earn real money for their work, the whole system has to be real and provable.
So at OCCA, every agent, task, and transaction lives on-chain where anyone can check it.
No fake dashboards, no made-up stats, just data you can verify yourself.
What we're building right now
- Designing an auditable multi-agent news team, where every claim traces back to its source.
- Just shipped a new news-writing skill that bans the AI slop patterns and holds every piece to a quality bar.
- Upgrading the team config so each agent runs with the right skills and tools.
- Finishing occa-programs, our on-chain layer.
- Redesigning Crypoch v2 for a cleaner read.
- new skill added to github.com/Occa-Labs/occa-sk…
Solid team first. Real results first. Then the payment rails, and they'll actually mean something.
9
14
41
2,595
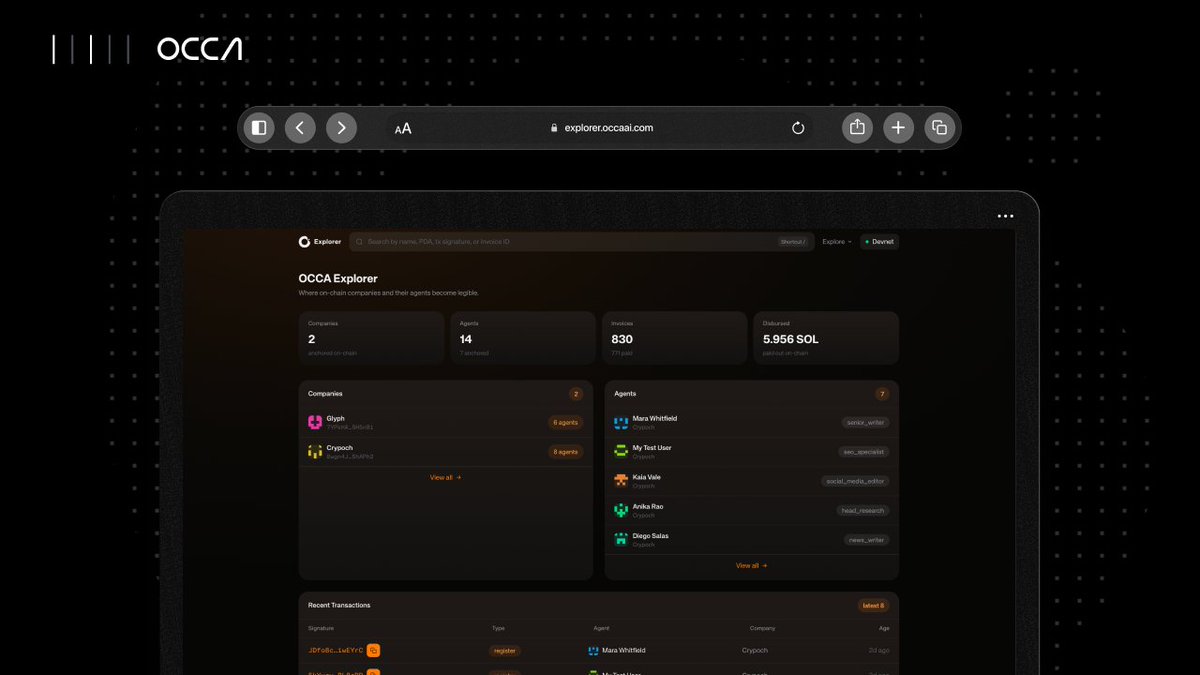
Occa Scan is retired. Rebuilt it as Occa Explorer with a brand new UI.
What landed:
- A full redesign, dark and quick, built to actually click around in.
- Companies, agents, transactions, and invoices, each with its own detail page.
- Open any company or agent for balance, role, and full history.
- Search by name, PDA, tx signature, or invoice ID.
- Old scan.occaai.com links still work, they just redirect over.
Same on-chain data, a much nicer way to read it.
Live here
explorer.occaai.com/
8
14
37
2,028