
Xoogler, Rubyist, SQLitist
Joined May 2008
- Tweets 3,326
- Following 460
- Followers 828
- Likes 2,908
90 Photos and videos








30 Dec 2025
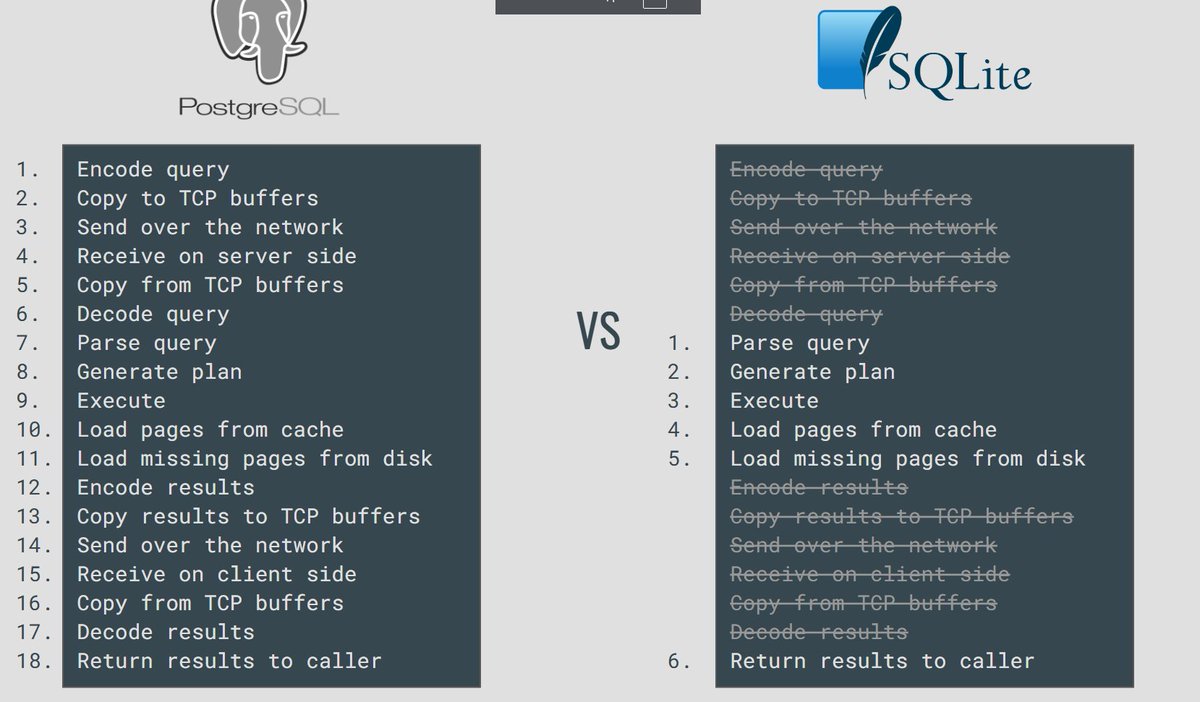
If you are building a really high performance data ingestion pipeline, what matters most is how many pages you are touching per tx and in which cache level (L1, L2, L3) would they fit.
WAL helps, but it will largely depend on how many records are written per page in a single tx
3
131
4 Nov 2025
user1: why is this slow?
rails dev investigates: oh, it’s N 1 AR queries.
user2: why is this slow?
C dev investigates: oh, it’s N 1 malloc().
the similarity is uncanny.
1
3
146
4 Nov 2025
Don't do expensive stuff in a loop
Prepare all you need first then iterate and do whatever
114
23 Oct 2025
Spent a little time optimizing a hot route on a Ruby Roda SQLite JSON API app
15 db queries: 1 refactored, 3 new indexes & all now use prepared statements
DB time was ~5ms per req, now ~500us per req
Most of the req time was in DB, reqs now are under 1 ms
Roda SQLite FTW!
1
8
284
10 Oct 2025
Great news all over, the war in Gaza seems to be over and better judgement about app server is coming into the Ruby community. Falcon improves on execution context memory overhead than any threaded/forked solution which is one of the big bottlenecks we deal with in Ruby land
9 Oct 2025

Falcon is now serving most of Shopify storefront traffic: web and API. It's solid, delivered big wins already, and unlocks a huge swath of new storefront optimizations we'll be trickling out over time.
Performance is an evergreen quest at Shopify. 🏃♀️🏃♂️ 💨
5
631
11 Aug 2025
Even though they try to justify their crimes, they know they are the monsters and they and their accomplices* are OK with it.
* By active support or mere silence
11 Aug 2025

Here is why starving children is fine, here is why targeting journalists is fine, here is why destroying hospitals is fine, here is why destroying every house in Gaza is fine, here is why shooting people in line for food is fine. Do you hear yourselves? Are you fucking serious?
242
16 Jul 2025
I believe the only chance Americans can get the Epstein truth out (and withstand the assured political avalanche) is to vote someone unrelated to both parties (and whoever is blackmailing them) to office. And that is not guaranteed, but any other way guarantees nothing happens
192
15 Jul 2025
When building really high perf data pipelines you can hit a wall when you try to insert or update many related tables
The overheads from binding (mostly similar) data to each statement and calling them becomes a good chunk of your overhead
1/3
1
1
175
15 Jul 2025
A more efficient way is to create a view that represents your variable set. Then create an INSTEAD OF trigger on the view to fan the data out to the target tables.
By inserting into the view, you bind the data once and visit the DB once, and all your inserts take one trip.
2/3
1
2
105
15 Jul 2025
Needless to say, don't do this for your blog or CMS app! I am talking in the context of really high performance data pipelines with huge volumes of data ingestion.
For all other use cases, optimize for readability & maintainability!
3/3
1
1
95
3 Jun 2025
The observability ecosystem is going through a J2EE, CORBA and XML phase right now. Here's hope it finds its RoR moment!
2
8
1,235
16 May 2025
Working with the Ruby C APIs, even though the documentation is really lacking, is still a lot easier and more straightforward than the Python C APIs.
Ruby's principle of least surprise extends, somewhat, to their C API too
1
6
240
16 May 2025
TinyBits 0.6.0 is released, better memory management, smaller multi-object buffers and a more robust dictionary support
With external dictionaries, a schema-less encoder like TinyBits can match (and sometimes exceed) the compactness of Protocol Buffers encoded output
3
4
26
1,441
16 May 2025
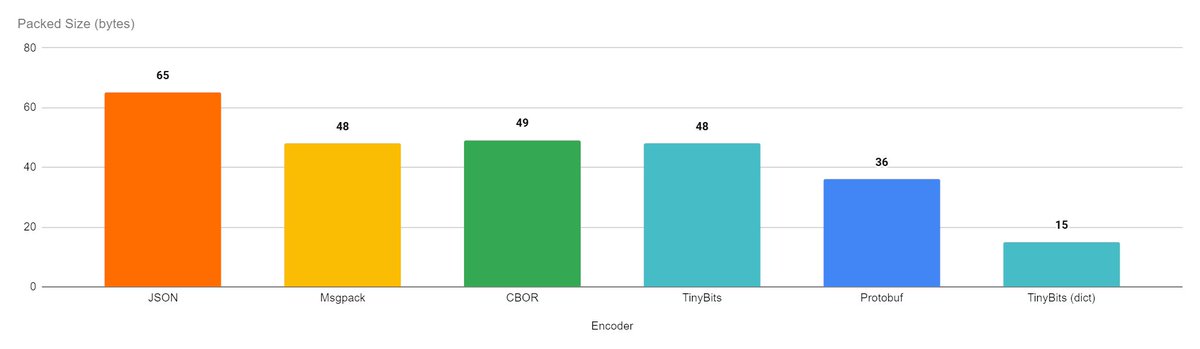
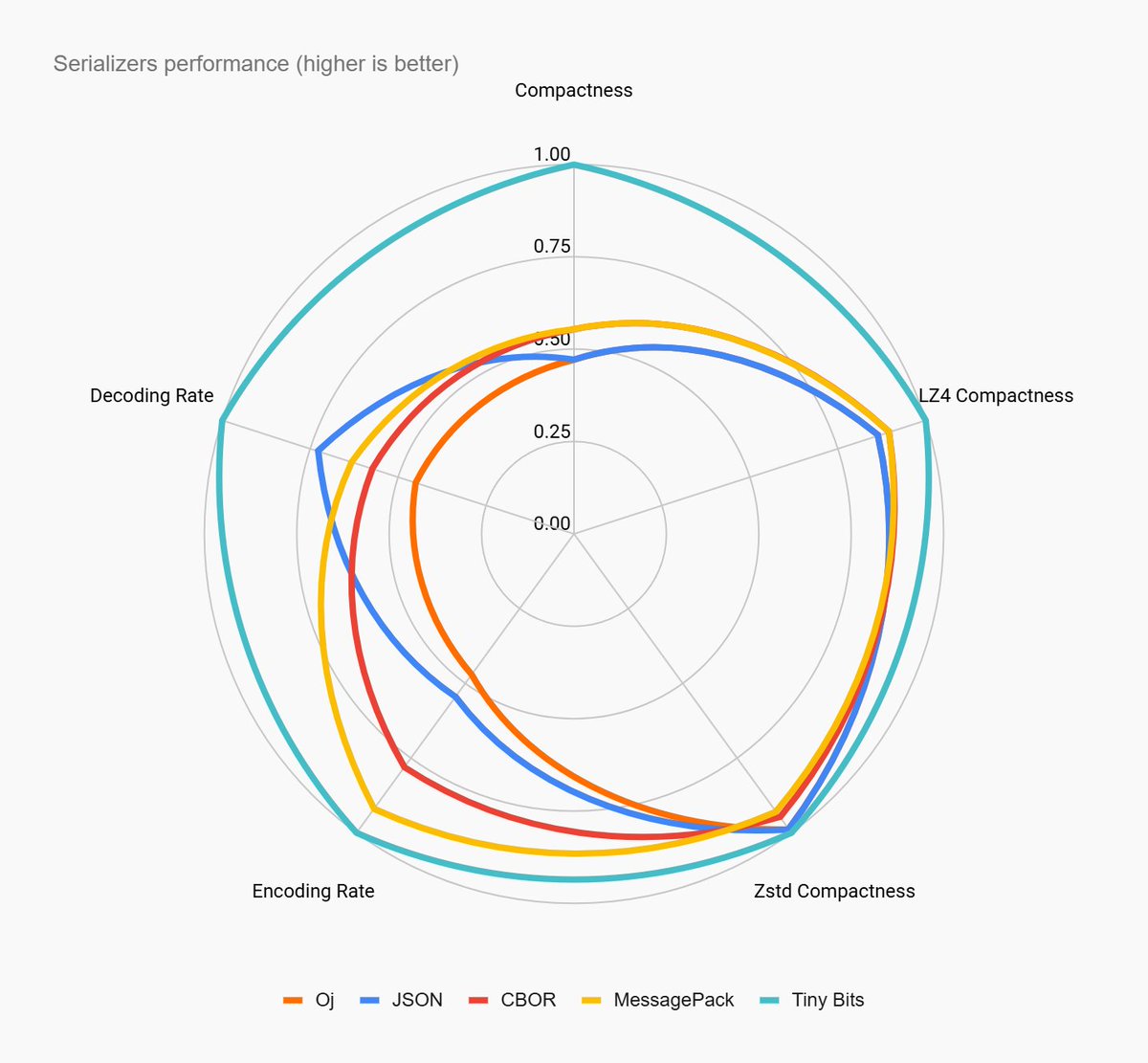
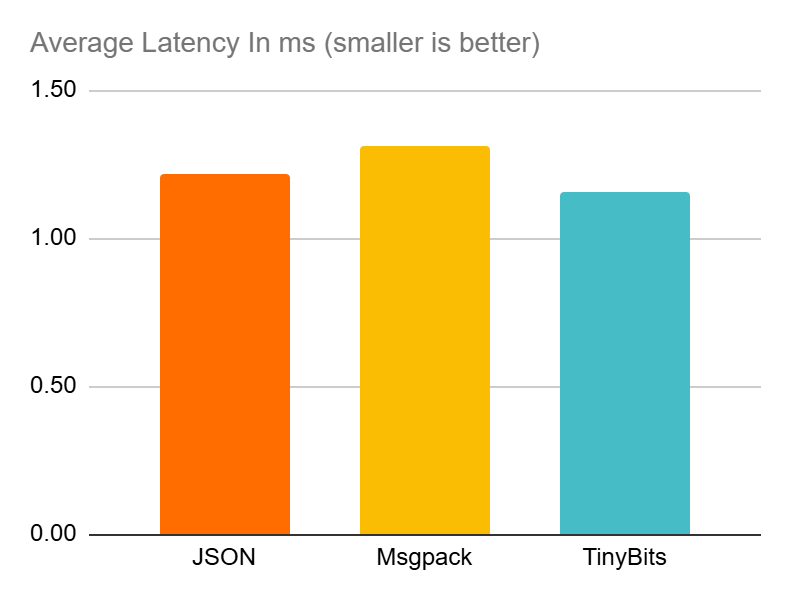
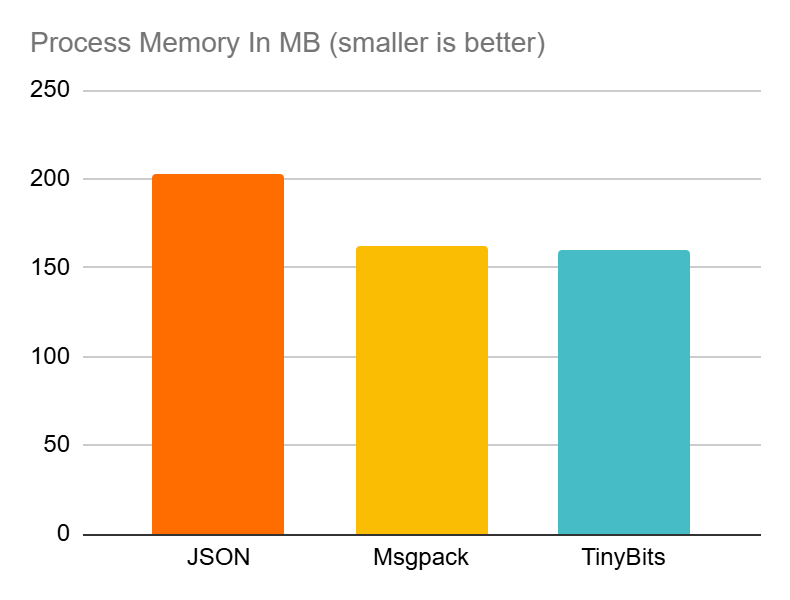
I also discuss a real world use case where TinyBits is used to encode and transmit instrumentation data from a Ruby app. And I compare it to both JSON and Msgpack
Beating them both by varying degrees in all tested metrics, payload size, process memory & performance overhead
1
5
224
16 May 2025
I explain more about the new features and its benefits on my blog
oldmoe.blog/2025/05/16/tinyb…
6
116
oldmoe مُحَمَّد retweeted

13 May 2025
Read the full newsletter for free at newsletter.shortruby.com/p/e… and please do share it online and with your friends or colleagues.
3
8
639
9 May 2025
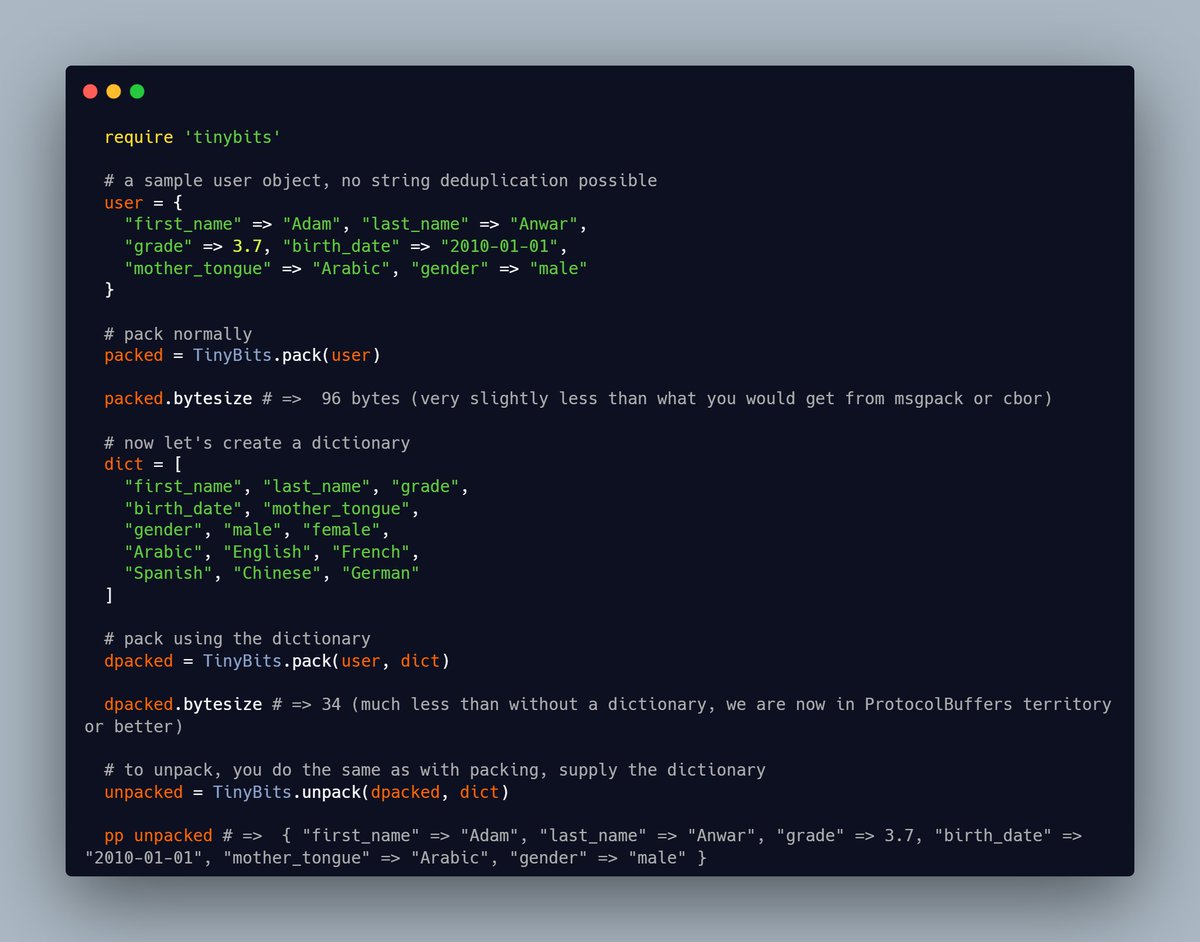
TinyBits is getting a new interesting feature, you can now (using the repo's head) supply the pack/unpack method with an external dictionary.
For shorter messages with no duplicate strings this can lead to a dramatic size reduction, from 96 to 34 bytes in the example below
1
3
148
9 May 2025
This getting too close now to ProtocolBuffers, and other schema-full encoders size efficiency, while being 10x simpler to use. In some case it will be event more efficient since you can add common strings to the dictionary, not just hash keys
1
104