
programmer
Joined May 2008
- Tweets 64,738
- Following 2,258
- Followers 826
- Likes 4,375
3,811 Photos and videos






オーケストレーションする賢いのが手順書出してローカルに発注みたいでいけんのかな
18h

なぜならオーケストレーションにこそ一番賢さが求められるから。考えてみれば実社会でも同じで指示をするリーダーが賢い方がいいのは当たり前なんですが、一見、軽いLocalオーケストレーション行ける気がしちゃう罠でした😅
1
2
580


こんなんで戦車壊れちゃうんじゃ、モビルスーツとか可動域も多いし実運用無理じゃね?

❗️On the Vovchansk direction, UAV operators of the 🇺🇦113rd Territorial Defense Brigade attacked a 🇷🇺Russian tank.
17
ここも直しときました(請求書上乗せしときますね)

なーんかGPT-5.5は、依頼した以外のコード改修を勝手にやるようで、ちょこちょこ勝手な改悪が入るのがイライラする😑
Codex-5.3でそれは無かったので、明らかにコーディング体験は劣化している😭
reddit.com/r/codex/comments/…
品質上がらない癖にトークン喰うのは未だ許せるが、UX低下は許容できんなぁ🤔
1
1
2
131
こういうの、現実のものなんでもオブジェクト指向で出来てるやろ?どんな車もハンドルついてるだろ?エンジンの仕組みとか知らんでも走るだろ?とかで通じんのかな
Jun 13

息子がオブジェクト指向の利点についてあれこれ聞いてきたのでカプセル化の有用性を説明したんだけど、いまいち腹落ちしてない感じ。
やっぱ大規模プログラムを組んだり保守や変更する辛い経験がないと、カプセル化の有り難みは肌身で体感できんのじゃろなあと思ったり。
2
99
イキロ(´・ω・`)
Jun 13

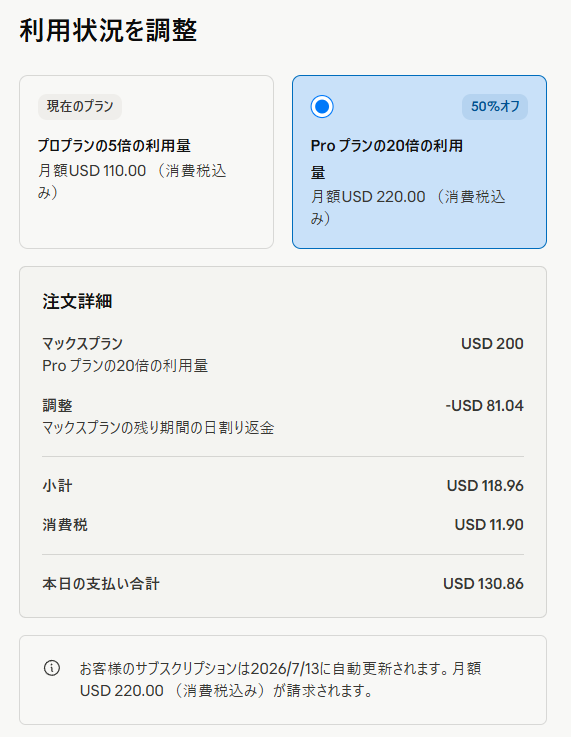
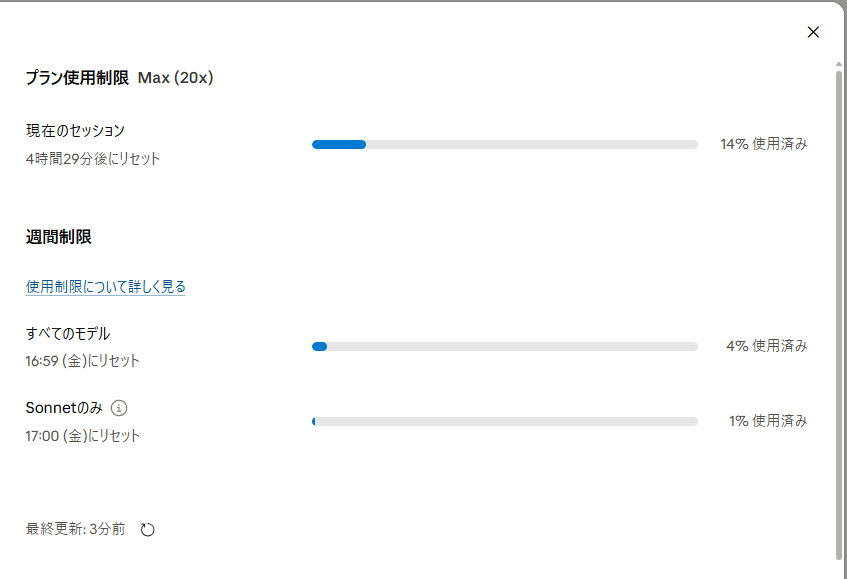
Claude Max(20x)に転生
週末はFableで遊び尽くします
(6月15日のサブスク仕様変更前に課金するのは若干逆張りだと思うのでお気を付けください)
1
110
こんなの、こんなとこに置く提案をしてそれを実際に行なった設置業者にも相応の責任あるのでは
そもなんでこんな話になったのか。普通事前に設置場所確認とかするよね?
Jun 13

こういう「妻のせい」「業者が悪い」って晒すのほんとに自分が悪いことの順位が一番低いな
立ち会え。何があろうと文句言いたいなら立ち会え。その時点で一番大事なところを放棄したじぶんが悪い
52

天才か。
一才が無償で負担ないとなってどれだけ増えるか分からんけど、この辺シミュレートした研究とかないんかね
金では増えないって聞くけど十分な金あれば今より増えるだろとしか思えん

1
1,774

ワイそういう時適当なこと言ってんじゃねーぞこのハゲって言っちゃう
Jun 11

今日はじめてのリアルでの会話
ノジマの店員「お困りですか?」
ワイ「映像出力できるType-Cケーブルありますか?」
店員「Type-CはできないのでHDMIケーブル買ってください。これどうですか?」
ワイ「大丈夫です」
1,147
は?そんなことできんの?

Clustering NVIDIA DGX Spark M3 Ultra Mac Studio for 4x faster LLM inference.
DGX Spark: 128GB @ 273GB/s, 100 TFLOPS (fp16), $3,999
M3 Ultra: 256GB @ 819GB/s, 26 TFLOPS (fp16), $5,599
The DGX Spark has 3x less memory bandwidth than the M3 Ultra but 4x more FLOPS.
By running compute-bound prefill on the DGX Spark, memory-bound decode on the M3 Ultra, and streaming the KV cache over 10GbE, we are able to get the best of both hardware with massive speedups.
Short explanation in this thread & link to full blog post below.

47
Composerに実装させたらかえってトークン使ったみたいな話もあったし色々試してみないと分からぬ…
Jun 11

Fable は高性能だけど、全部やらせると高くなる。
そのため「マネージャー」、つまり他のエージェントをまとめるオーケストレーターとして使う。
Sonnet や Haiku のような低コストモデルを部下として扱い、Fable は判断・計画・レビュー・統合に使う。
この使い分けは、今後かなり重要になる...(実体験)
1
1
1
794
まあワイも右側空いてて歩きたい人は歩ける様にしといて派なので混んでる時以外は空けといてと思うけど、燃えそうなこと書いててリプが来てうざは書く前に少しは考えろ感
Jun 10

批判覚悟で言うけど
エスカレーターの片側歩きたいマンだから
こうやって片側の空いてる方を塞き止める奴うざ😡
体が不自由な人で右側しか掴めないとかは別として。
駅側が立ち止まろうって啓蒙してるけどそれもうざ😡
乗らずに階段歩けって言う人もうざ😡
こっちはエスカレーター歩きたいんじゃ

45
最後の2ついいな
Jun 11

O que rolou com a indústria de abridores de lata? Todos esses são mil vezes melhores dos que vendem hoje em dia.
83

コミックにもなってない部分じゃないですか!


32
ぐうの音も出ない指摘はよせ
Jun 10

「男はすれ違いざまに採点してくる」「男のルッキズムに女は苦しめられている」って話がたびたび出てくるけど、イオンモールのボディバッグおじさんの件1つとっても他人の格好にいちいち文句言ってるの女なんだよな
1
1
555