
35 Photos and videos







Pinned Tweet

Feb 11
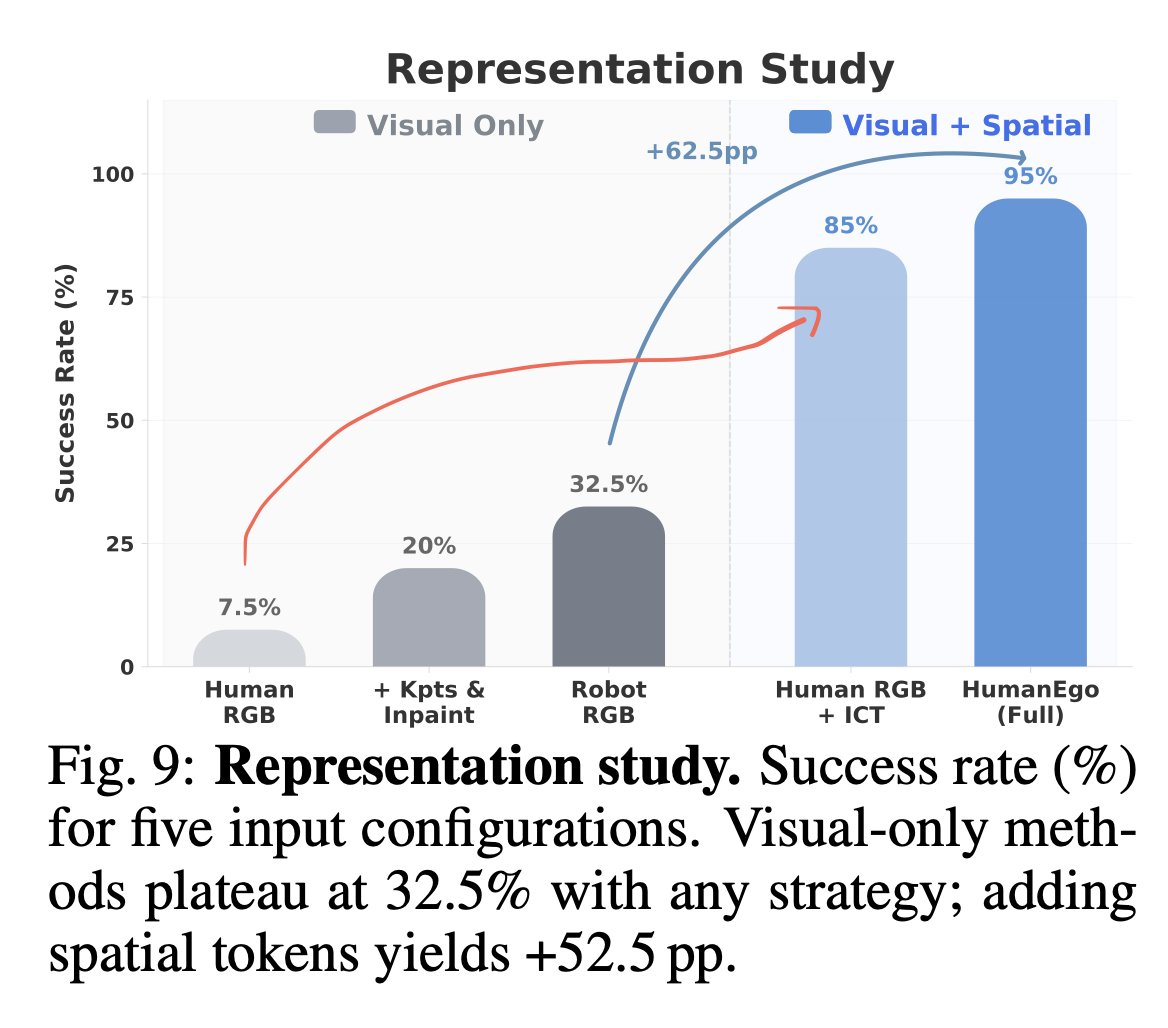
MolmoSpaces provides singular scale and diversity. We built a benchmark that puts that scale to use.
MolmoSpaces-Bench evaluates zero-shot policies across thousands of environments previously unseen to them under systematic variation, providing insights that go beyond a success rate %
More Below:

Introducing MolmoSpaces, a large-scale, fully open platform benchmark for embodied AI research. 🤖
230k indoor scenes, 130k object models, & 42M annotated robotic grasps—all in one ecosystem.
6
16
151
13,390
Jun 9
Wall-OSS is now the #1 policy on the zero-shot MolmoSpaces evals. A lot of details in their paper, I recommend checking it out.
May 28

We are open-sourcing Wall-OSS-0.5.
Pretrain Once, Act Anywhere.
Wall-OSS-0.5 is a VLA model for real-world robotic manipulation, exploring whether pretraining alone can produce robot capabilities directly testable on physical hardware before task-specific fine-tuning.
Key technical highlights:
• Gradient-bridged co-training
• Vision-Aligned RVQ Action Tokenizer
• Action-Space Supervision
• DMuon distributed optimizer
In zero-shot real-robot evaluation, the pretrained checkpoint achieved task-progress scores above 80 on multiple tasks, including Block Sorting, Fruit Sorting, Ring Stacking, and Rope Tightening.
Paper, code, blog, and uncut videos: x2robot.com/oss#resources
1
10
36
6,291
Omar Rayyan retweeted

May 30
Robotics is still data starved. Collecting high-quality robot demonstrations remains brutally slow and expensive.
Introducing COBALT: A cloud-native teleoperation platform designed for large-scale robot learning.
We are democratizing data collection by leveraging the hardware everyone already owns: the smartphone
All you need is to download an app (today)!
Read on for more!
29
52
393
98,515
Omar Rayyan retweeted

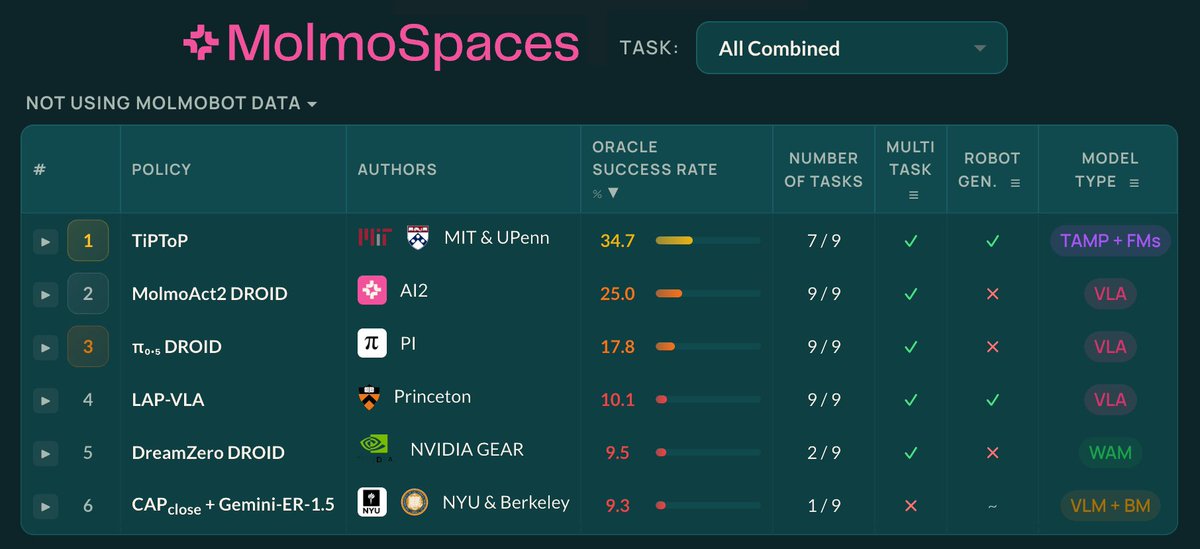
𝗧𝗶𝗣𝗧𝗼𝗣 𝗶𝘀 #𝟭 𝗼𝗻 𝗠𝗼𝗹𝗺𝗼𝗦𝗽𝗮𝗰𝗲𝘀! Outperforming VLAs including MolmoAct2 and π₀.₅, and WAMs like DreamZero
It's the only method that uses inference-time search and 𝙯𝙚𝙧𝙤 robot data. We didn't do any benchmark-specific tuning.
3
15
138
14,170
Omar Rayyan retweeted

Mar 29
Just merged an amazing contribution by @omarrayyann to mjlab's viser viewer: checkpoint hot-swapping! You can now browse and load any checkpoint mid-session without restarting and it works with local checkpoints and W&B runs.
1
16
141
9,518
Omar Rayyan retweeted

Mar 25
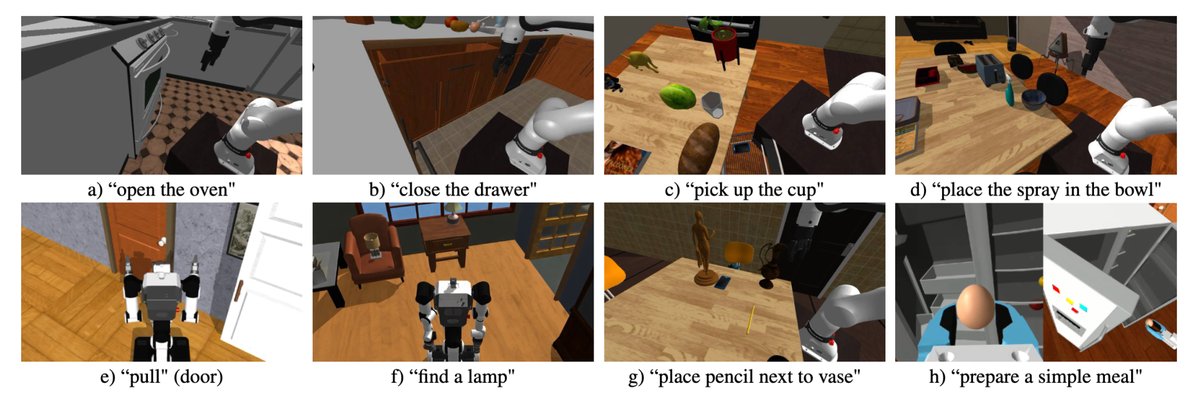
Benchmarking, evaluating, and developing robotics code is difficult, and part of this is because no simulator really reflects the diversity and scale of real embodiments. Enter MolmoSpaces from AI2: a massive open ecosystem with a range of 230,000 handcrafted and procedurally-generated home environments, including 48,000 manipulable objects. Crucially, MolmoSpaces provides simulation environments which work for both navigation and manipulation. We talked to the team: @YejinKim4, @omarrayyann, and Max Argus, to tell us more.
Watch Episode 69 of RoboPapers, with @micoolcho and @DJiafei, now!
1
16
74
20,996
Omar Rayyan retweeted

Mar 25
Jensen approves!
Hercules efforts from @YejinKim4 @omarrayyann, Max Argus & team! This has a decent chance of becoming a super important benchmark fo robotics going forward.
Check out this @RoboPapers episode with the MolmoSpaces folks.

Mar 25

Benchmarking, evaluating, and developing robotics code is difficult, and part of this is because no simulator really reflects the diversity and scale of real embodiments. Enter MolmoSpaces from AI2: a massive open ecosystem with a range of 230,000 handcrafted and procedurally-generated home environments, including 48,000 manipulable objects. Crucially, MolmoSpaces provides simulation environments which work for both navigation and manipulation. We talked to the team: @YejinKim4, @omarrayyann, and Max Argus, to tell us more.
Watch Episode 69 of RoboPapers, with @micoolcho and @DJiafei, now!
1
3
7
1,170
Mar 11
Check out our MolmoBot release and the open-sourced foundational models trained entirely in simulated MolmoSpaces homes!
Today, a step forward in open robotics - our results show that sim-to-real zero shot transfer for manipulation is possible. MolmoBot is our open model suite for robotics, trained entirely in simulation on MolmoSpaces.🧵
2
2
18
1,515
Omar Rayyan retweeted

Feb 28
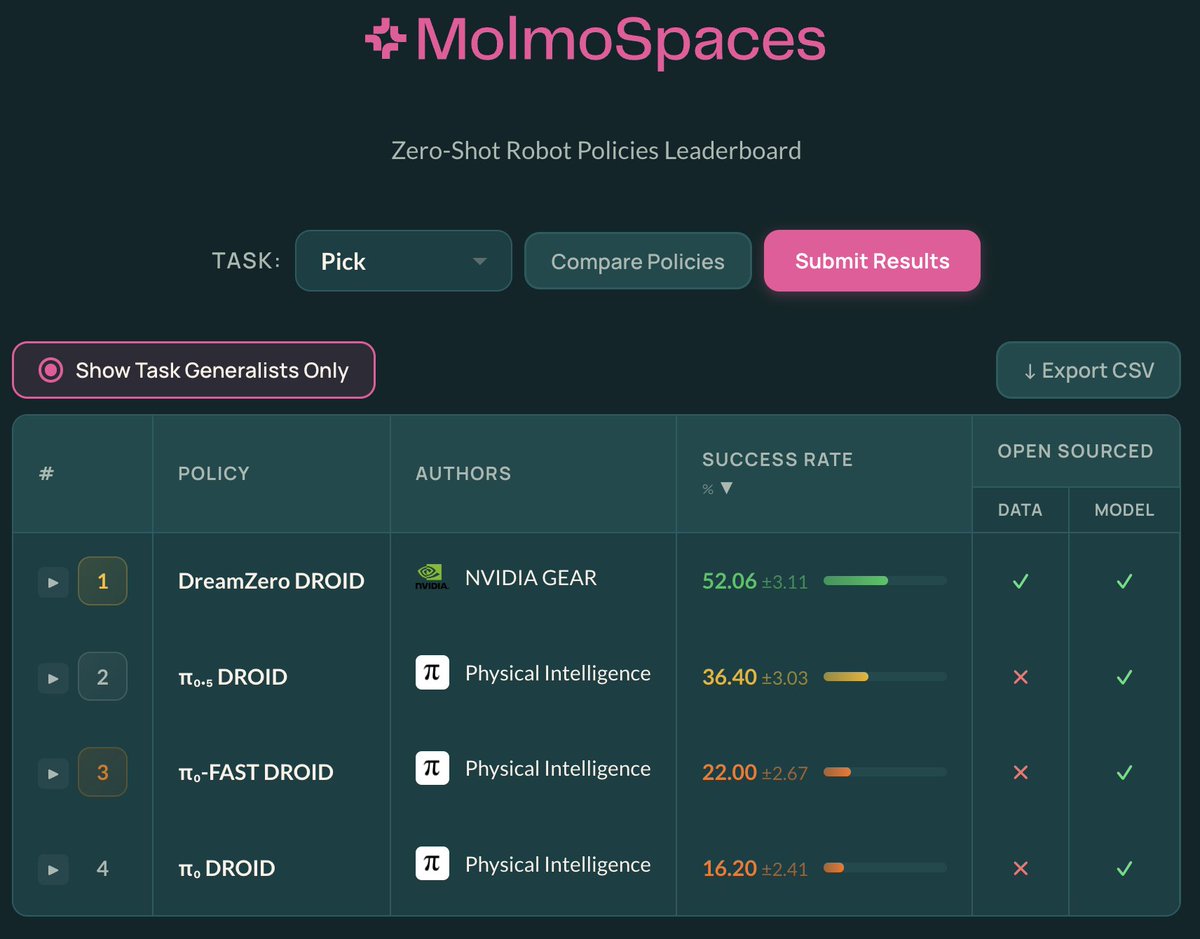
MolmoSpaces leaderboard is now open for submissions!
When we created this benchmark for zero-shot real-to-sim eval in diverse homes, we didn’t expect things to heat up so quickly. But it did, thanks to @jang_yoel and team at GEAR toppling PI to take the crown on task-general category. Congrats 🎉
You can evaluate and submit your model to this leaderboard: molmospaces.allen.ai/leaderb…
Feb 27

𝐃𝐫𝐞𝐚𝐦𝐙𝐞𝐫𝐨 𝐢𝐬 #𝟏 𝐨𝐧 𝐛𝐨𝐭𝐡 𝐌𝐨𝐥𝐦𝐨𝐒𝐩𝐚𝐜𝐞𝐬 𝐚𝐧𝐝 𝐑𝐨𝐛𝐨𝐀𝐫𝐞𝐧𝐚 🏆
𝗪𝗵𝗮𝘁 𝗺𝗮𝗸𝗲𝘀 𝘁𝗵𝗶𝘀 𝗻𝗼𝘁𝗮𝗯𝗹𝗲: DreamZero-DROID is trained 𝑓𝑟𝑜𝑚 𝑠𝑐𝑟𝑎𝑡𝑐ℎ using only the DROID dataset. No pretraining on large-scale robot data, unlike competing VLAs. This demonstrates the strength of video-model backbones for generalist robot policies (VAMs/WAMs).
More broadly, training 𝑜𝑛𝑙𝑦 on real data and evaluating on (1) transparent, distributed benchmarks like 𝐑𝐨𝐛𝐨𝐀𝐫𝐞𝐧𝐚 or (2) scalable sim-benchmarks like 𝐌𝐨𝐥𝐦𝐨𝐒𝐩𝐚𝐜𝐞𝐬 is an exciting step toward fairer and more reproducible evaluation of generalist policies, one that the community can hillclimb together to measure progress.
Special thanks to the Ai2 MolmoSpaces team (@notmahi @omarrayyann @YejinKim4 Max Argus) and the RoboArena team (@pranav_atreya) for helping with the set-up and getting these evaluations! Special shout out to @youliangtan @NadunRanawakaA @chuning_zhu, who led these efforts from the GEAR side :)
We also release our DreamZero-AgiBot checkpoint & post-training code to enable very efficient few-shot adaptation. Post-train on just ~30 minutes of play data for your specific robot, and see the robot do basic language following and pick-and-place 🤗(See YAM experiments in our paper for more detail).
We also provide the entire codebase & preprocessed dataset to replicate the DreamZero-DROID checkpoint.
🌐 dreamzero0.github.io
💻 github.com/dreamzero0/dreamz…
RoboArena: robo-arena.github.io/leaderb…
MolmoSpaces: molmospaces.allen.ai/leaderb…

2
4
40
4,648
Feb 28
MolmoSpaces-Bench leaderboard is now live! Test your generalist policies to see how they compare across tasks and environments. Feel free to reach out if you need help setting it up.
molmospaces.allen.ai/leaderb…
2
5
35
1,868
Feb 28
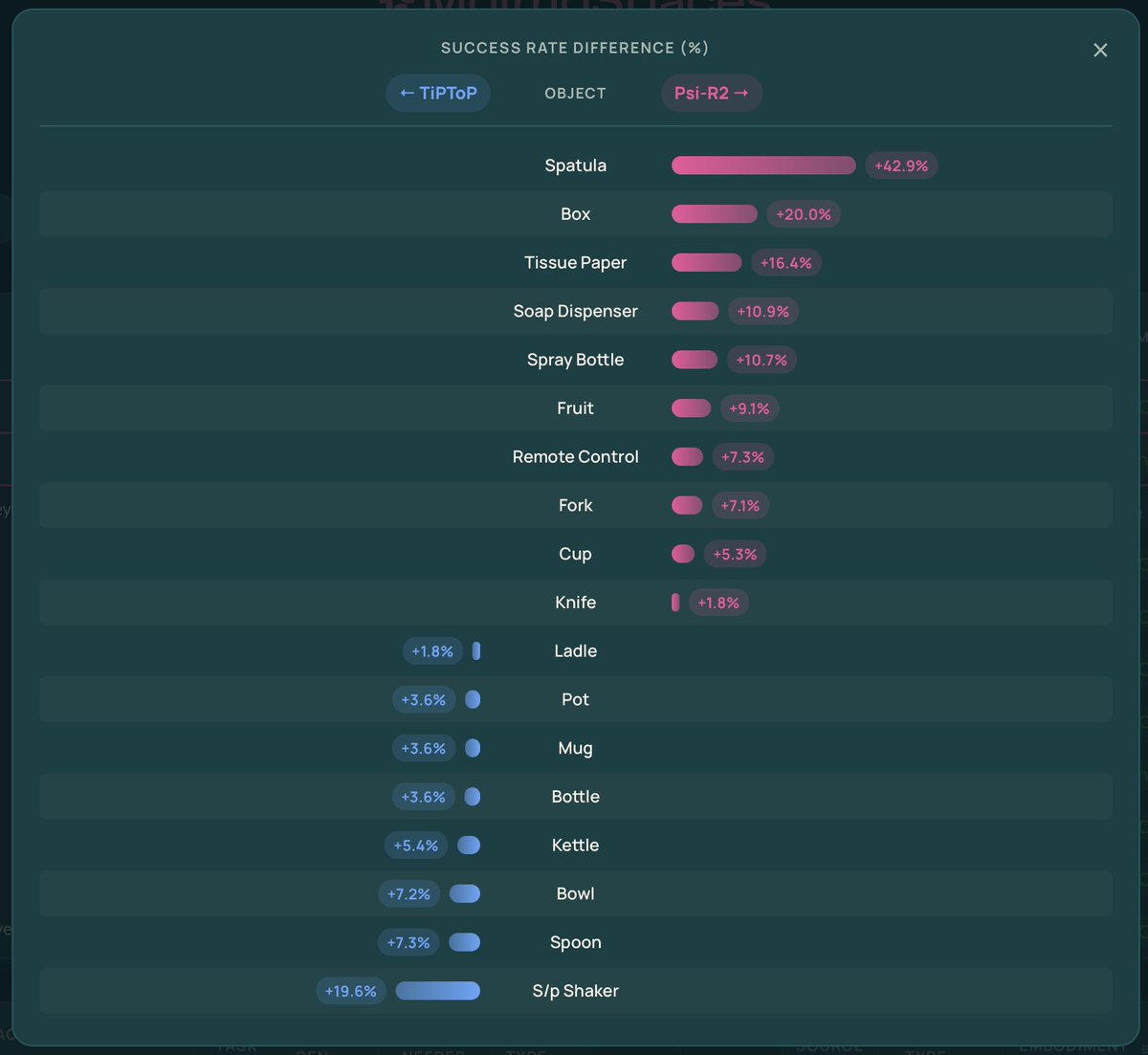
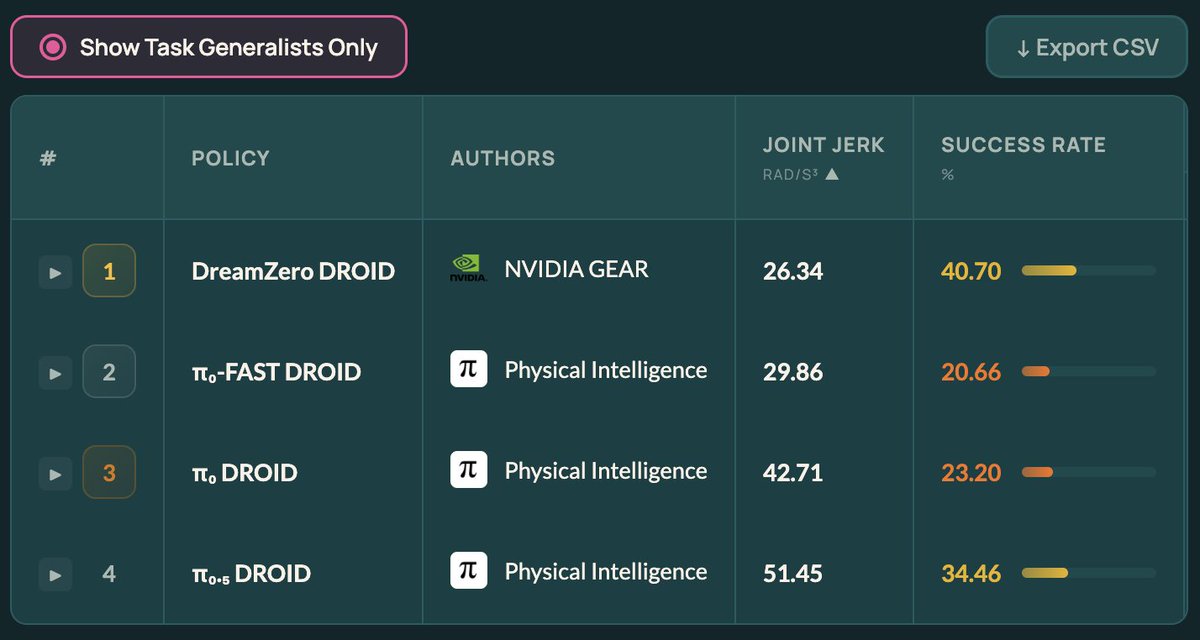
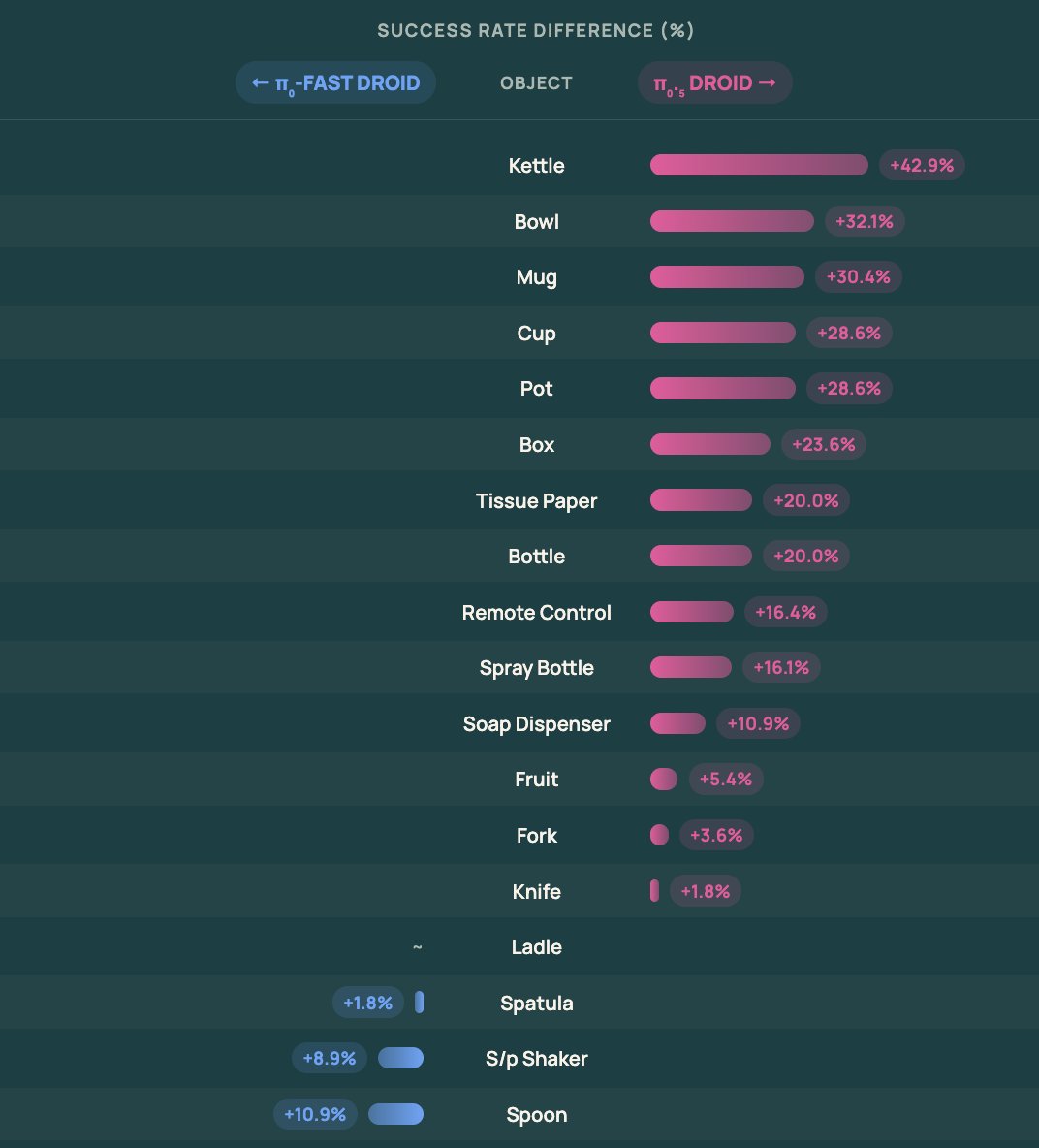
You can get more insights than just the success rate (e.g. AR policies like DreamZero and pi0-Fast generate smoother trajectories) and cross-compare policy performance across objects.
1
6
201
Feb 28
Also thanks to @youliangtan @jang_yoel for their DreamZero API. Their world action model now leads the benchmark with zero sim data. x.com/jang_yoel/status/20275…
Feb 27
𝐃𝐫𝐞𝐚𝐦𝐙𝐞𝐫𝐨 𝐢𝐬 #𝟏 𝐨𝐧 𝐛𝐨𝐭𝐡 𝐌𝐨𝐥𝐦𝐨𝐒𝐩𝐚𝐜𝐞𝐬 𝐚𝐧𝐝 𝐑𝐨𝐛𝐨𝐀𝐫𝐞𝐧𝐚 🏆
𝗪𝗵𝗮𝘁 𝗺𝗮𝗸𝗲𝘀 𝘁𝗵𝗶𝘀 𝗻𝗼𝘁𝗮𝗯𝗹𝗲: DreamZero-DROID is trained 𝑓𝑟𝑜𝑚 𝑠𝑐𝑟𝑎𝑡𝑐ℎ using only the DROID dataset. No pretraining on large-scale robot data, unlike competing VLAs. This demonstrates the strength of video-model backbones for generalist robot policies (VAMs/WAMs).
More broadly, training 𝑜𝑛𝑙𝑦 on real data and evaluating on (1) transparent, distributed benchmarks like 𝐑𝐨𝐛𝐨𝐀𝐫𝐞𝐧𝐚 or (2) scalable sim-benchmarks like 𝐌𝐨𝐥𝐦𝐨𝐒𝐩𝐚𝐜𝐞𝐬 is an exciting step toward fairer and more reproducible evaluation of generalist policies, one that the community can hillclimb together to measure progress.
Special thanks to the Ai2 MolmoSpaces team (@notmahi @omarrayyann @YejinKim4 Max Argus) and the RoboArena team (@pranav_atreya) for helping with the set-up and getting these evaluations! Special shout out to @youliangtan @NadunRanawakaA @chuning_zhu, who led these efforts from the GEAR side :)
We also release our DreamZero-AgiBot checkpoint & post-training code to enable very efficient few-shot adaptation. Post-train on just ~30 minutes of play data for your specific robot, and see the robot do basic language following and pick-and-place 🤗(See YAM experiments in our paper for more detail).
We also provide the entire codebase & preprocessed dataset to replicate the DreamZero-DROID checkpoint.
🌐 dreamzero0.github.io
💻 github.com/dreamzero0/dreamz…
RoboArena: robo-arena.github.io/leaderb…
MolmoSpaces: molmospaces.allen.ai/leaderb…
8
365
Feb 14
MolmoSpaces also comes with 42M grasps that cover 48K objects across 250K scenes, allowing large-scale functional trajectory generation in MuJoCo and IsaacSim.
4
35
318
18,939
Feb 14
We opensource our mjcf2grasp pipeline that lets you generate and verify grasps starting from an MJCF file: github.com/allenai/molmospac…
2
24
1,133

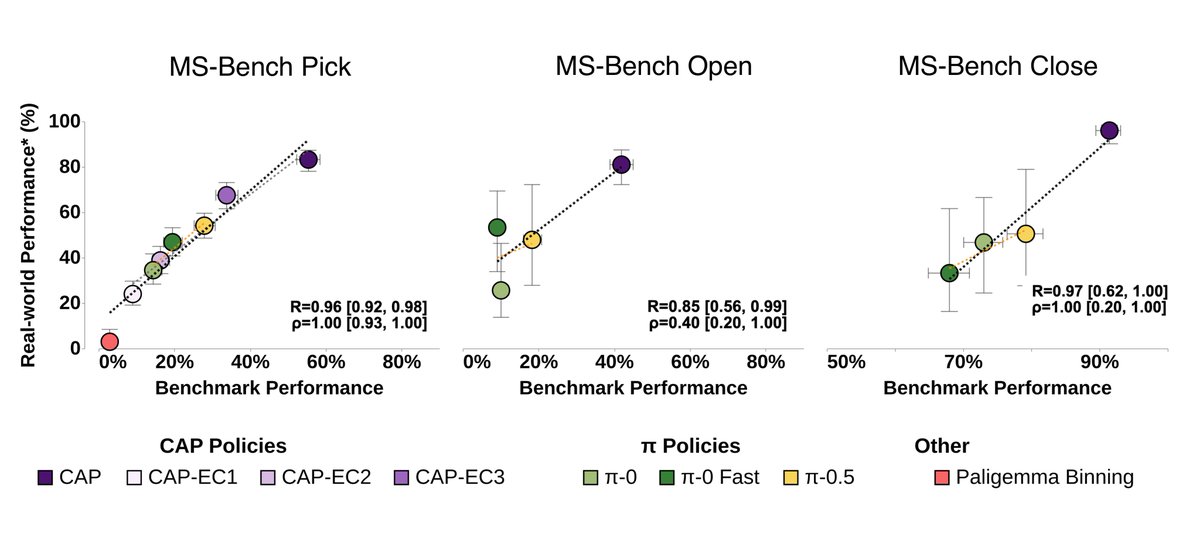
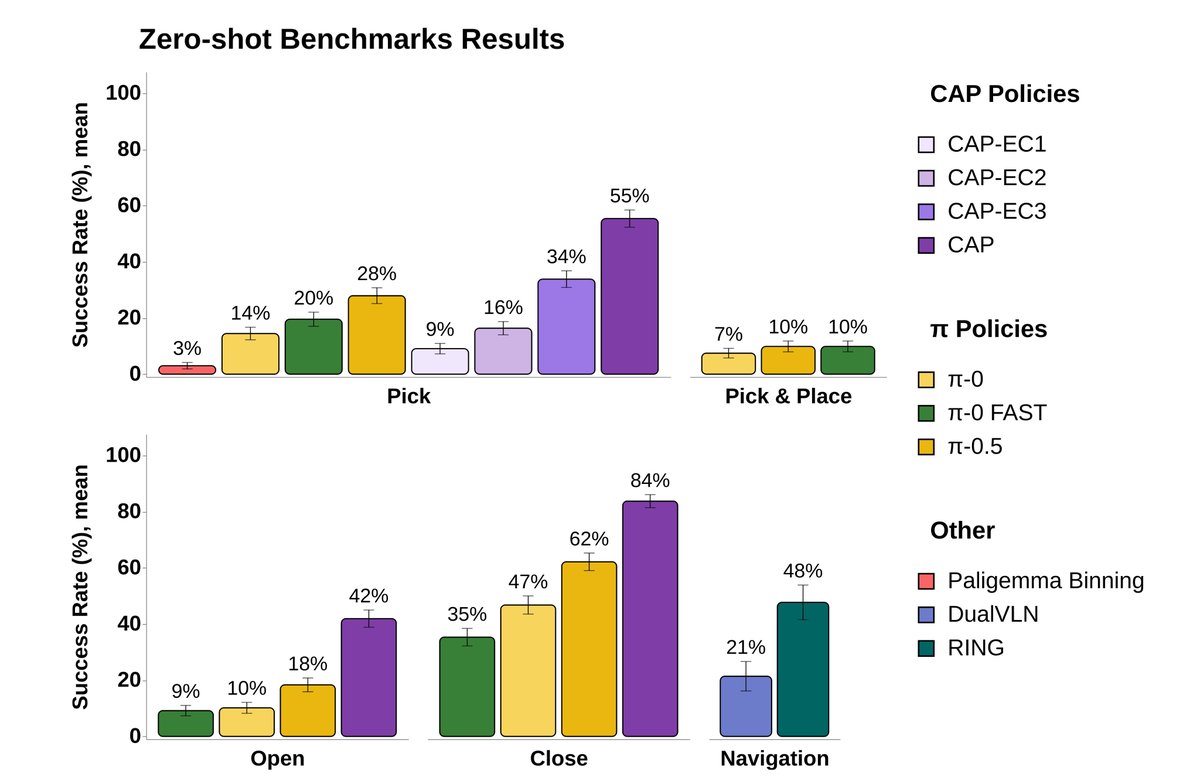
Also check out MolmoSpaces-Bench from @omarrayyann! Our contact-anchored policies (CAPs) perform well zero-shot across diverse environments and objects. Omar is the rockstar behind our sim env for CAP, enabling us to train and evaluate multiple models in a day.
Feb 11

It’s hard to find true zero-shot end-to-end policies – ones that work without any fine-tuning in fully novel, simulated environments, even for single tasks! We test two policy families, the π family from @physical_int and the recent Contact-Anchored Policies (CAP) from NYU & UCB.
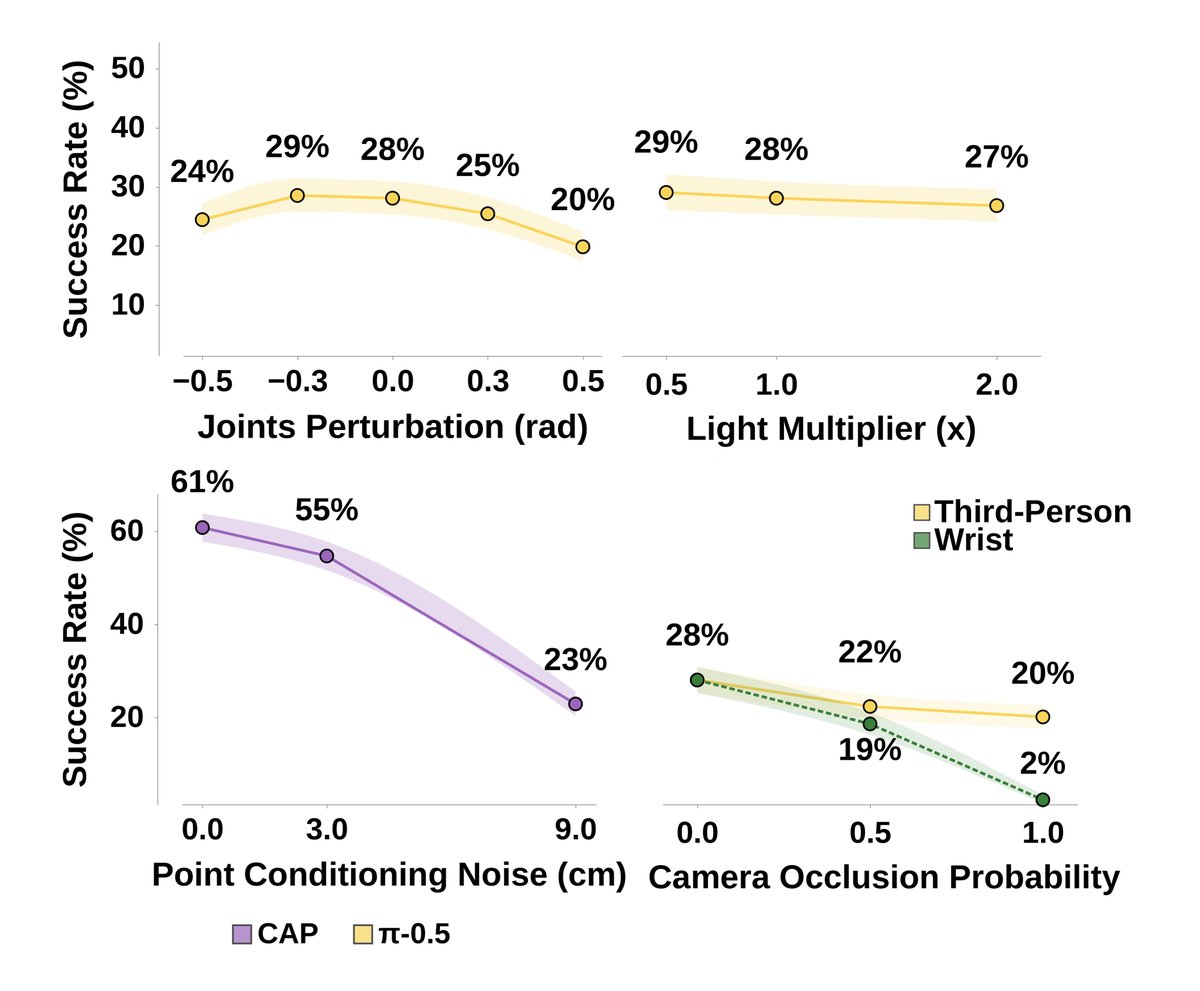
On all our tasks, we are making steady progress – but we are nowhere close to saturation yet.
1
6
784
Omar Rayyan retweeted
Feb 11
How general are your general robotic policies?
Today, we're releasing MolmoScenes-Bench to help explore this question. You can spin up ~1k envs in ~700 unique simulated homes and within hours find out how well your zero-shot policy generalizes to these unseen scenes 🧵
Feb 11
MolmoSpaces provides singular scale and diversity. We built a benchmark that puts that scale to use.
MolmoSpaces-Bench evaluates zero-shot policies across thousands of environments previously unseen to them under systematic variation, providing insights that go beyond a success rate %
More Below:
1
3
26
3,574
Feb 11
MolmoSpaces provides singular scale and diversity. We built a benchmark that puts that scale to use.
MolmoSpaces-Bench evaluates zero-shot policies across thousands of environments previously unseen to them under systematic variation, providing insights that go beyond a success rate %
More Below:
Introducing MolmoSpaces, a large-scale, fully open platform benchmark for embodied AI research. 🤖
230k indoor scenes, 130k object models, & 42M annotated robotic grasps—all in one ecosystem.
6
16
151
13,390
Feb 11
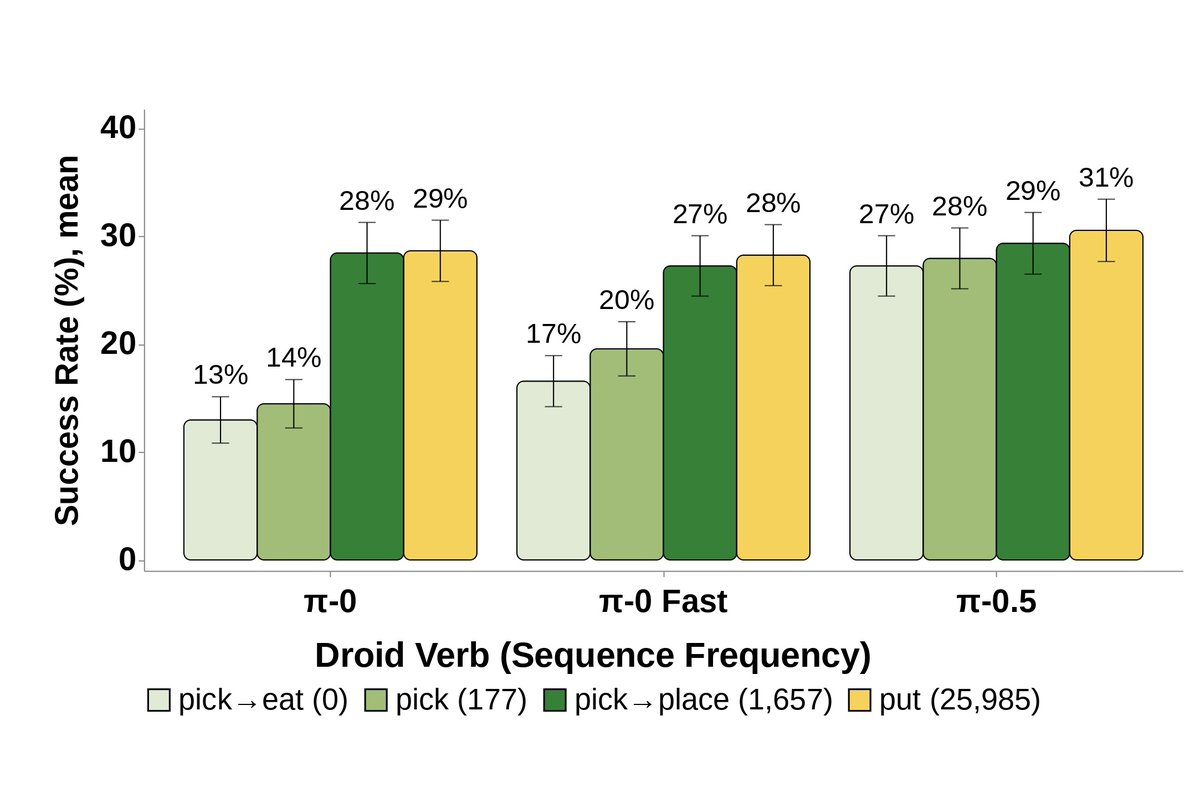
Another example is prompt-sensitivity in lang-conditioned models. On the exact same tasks, early π models fail more when given queries less frequent in DROID dataset – newer π models almost entirely close this gap.
2
3
285
Feb 11
And finally, these benchmarks would not have been possible without advising from @notmahi, the efforts of @max_argus and @YejinKim4, the support of my PhD advisor @yuchencui1, and others at Ai2 — @arjungru, @rosemhendrix, @mayasguru, @ab_deshpande, @snehaljauhri, @shuoliu14, @ainaz_eftekhar, @piper_wolters, and @ranjaykrishna.
💻 github.com/allenai/molmospac…
📄 allenai.org/papers/molmospac…
4
358