
Joined April 2025
- Tweets 154
- Following 73
- Followers 1,152
- Likes 137
46 Photos and videos













Pinned Tweet

Jun 10
🥳Our third open-source release is here: XRZero-G0.
After WALL-OSS-0.5 and WALL-WM, we’re open-sourcing XRZero-G0 to Scale Robot Learning with Interfaces, Data Quality and Ratios
XRZero-G0 enables robot-free data collection, trainable policy generation, and real-robot evaluation through a closed-loop pipeline:
Collection → Inspection → Training → Evaluation
Key highlights: 2,000 hours of validated multimodal demonstrations
~85% effective data yield in controlled settings
10:1 robot-free / real-robot data mixing law
Up to 20x reduction in real-robot data needs
Zero-shot transfer across robot embodiments
Built for scalable, reproducible embodied AI research.
Project: x2robot.com/x2go
Paper: arxiv.org/abs/2604.13001
Code: github.com/X-Square-Robot/XR…
Dataset: 📷huggingface.co/datasets/x-sq…
@ComWjm @_akhaliq @HuggingPapers @ModelScope2022 @Xianbao_QIAN @XRoboHub @TheHumanoidHub @chris_j_paxton @IlirAliu_
May 29

Introducing WALL-WM, our open-source World Model for embodied AI and the next piece of our open-source robotics stack.
Carving World Action Modeling at the Event Joints
Read the blog: x2robot.com/en/pages/wm
Why it matters
WALL-WM shifts robot world modeling from fixed-length action chunks to event-grounded video-action pretraining. It learns around events like reaching, contact, grasping, lifting, moving, and placing, so language, vision, and action align more naturally.
Why you should care
WALL-WM brings together:
•Event-grounded VLA pretraining
•Prior-aligned video-action architecture
•Wan-based video tower randomly initialized action DiT
•Multi-view perception with sight-cone masking, tube patch masking, and Camera RoPE
•Event Mode for variable-length execution
•Unified Mode with Staircase Decoding
•DMuon for large-scale training
The goal: help robots learn what physically matters, not just what happens in the next fixed slice of time.
Code (coming soon): github.com/X-Square-Robot/wa…
#opensource #EmbodiedAI
5
21
78
17,256
Excited to support the #RSS2026 Diffusion for Robot Learning Workshop! 🚀
Looking forward to seeing more great work on diffusion models for embodied AI and robot learning. Submit your work and join us at RSS!

🚀 The #RSS2026 Diffusion for Robot Learning Workshop is now open for submission!
rss2026-diffusion-robot-lear…
Diffusion models are the next frontier for embodied AI.
Submit by June 24 to win a prize of 1000$ sponsored by @XSquareRobot and join us to hear from our invited speakers!

2
10
942
Jun 11
Robot-free demos can be collected through our VR interface, inspected, trained, and evaluated in a closed loop.
Cool thing is that a small amount of real-robot data mixed with large-scale robot-free data can reach comparable performance, while reducing real-robot data needs by up to 20x.
Code: github.com/X-Square-Robot/XR…
Paper: arxiv.org/abs/2604.13001
Jun 10
🥳Our third open-source release is here: XRZero-G0.
After WALL-OSS-0.5 and WALL-WM, we’re open-sourcing XRZero-G0 to Scale Robot Learning with Interfaces, Data Quality and Ratios
XRZero-G0 enables robot-free data collection, trainable policy generation, and real-robot evaluation through a closed-loop pipeline:
Collection → Inspection → Training → Evaluation
Key highlights: 2,000 hours of validated multimodal demonstrations
~85% effective data yield in controlled settings
10:1 robot-free / real-robot data mixing law
Up to 20x reduction in real-robot data needs
Zero-shot transfer across robot embodiments
Built for scalable, reproducible embodied AI research.
Project: x2robot.com/x2go
Paper: arxiv.org/abs/2604.13001
Code: github.com/X-Square-Robot/XR…
Dataset: 📷huggingface.co/datasets/x-sq…
@ComWjm @_akhaliq @HuggingPapers @ModelScope2022 @Xianbao_QIAN @XRoboHub @TheHumanoidHub @chris_j_paxton @IlirAliu_
2
4
67
10,068
X Square Robot retweeted

Jun 9
Wall-OSS is now the #1 policy on the zero-shot MolmoSpaces evals. A lot of details in their paper, I recommend checking it out.
May 28
We are open-sourcing Wall-OSS-0.5.
Pretrain Once, Act Anywhere.
Wall-OSS-0.5 is a VLA model for real-world robotic manipulation, exploring whether pretraining alone can produce robot capabilities directly testable on physical hardware before task-specific fine-tuning.
Key technical highlights:
• Gradient-bridged co-training
• Vision-Aligned RVQ Action Tokenizer
• Action-Space Supervision
• DMuon distributed optimizer
In zero-shot real-robot evaluation, the pretrained checkpoint achieved task-progress scores above 80 on multiple tasks, including Block Sorting, Fruit Sorting, Ring Stacking, and Rope Tightening.
Paper, code, blog, and uncut videos: x2robot.com/oss#resources
1
10
36
6,288
X Square Robot retweeted

🌌 At @saturdayrobotic Saturday Robotics Research Night @CVPR, we hosted Xiaofan Li (World Model Tech Lead @XSquareRobot) for a lightning talk on WALL-WM.
TLDR: From next chunk prediction → next event prediction. WALL-WM introduces a new training inference workflow for world modeling, shifting from rigid frame chunks to semantic event signals. It explores tighter integration of agent intelligence and WAM for improved real-world dynamic perception and prediction.
x2robot.com/api/files/file/W…
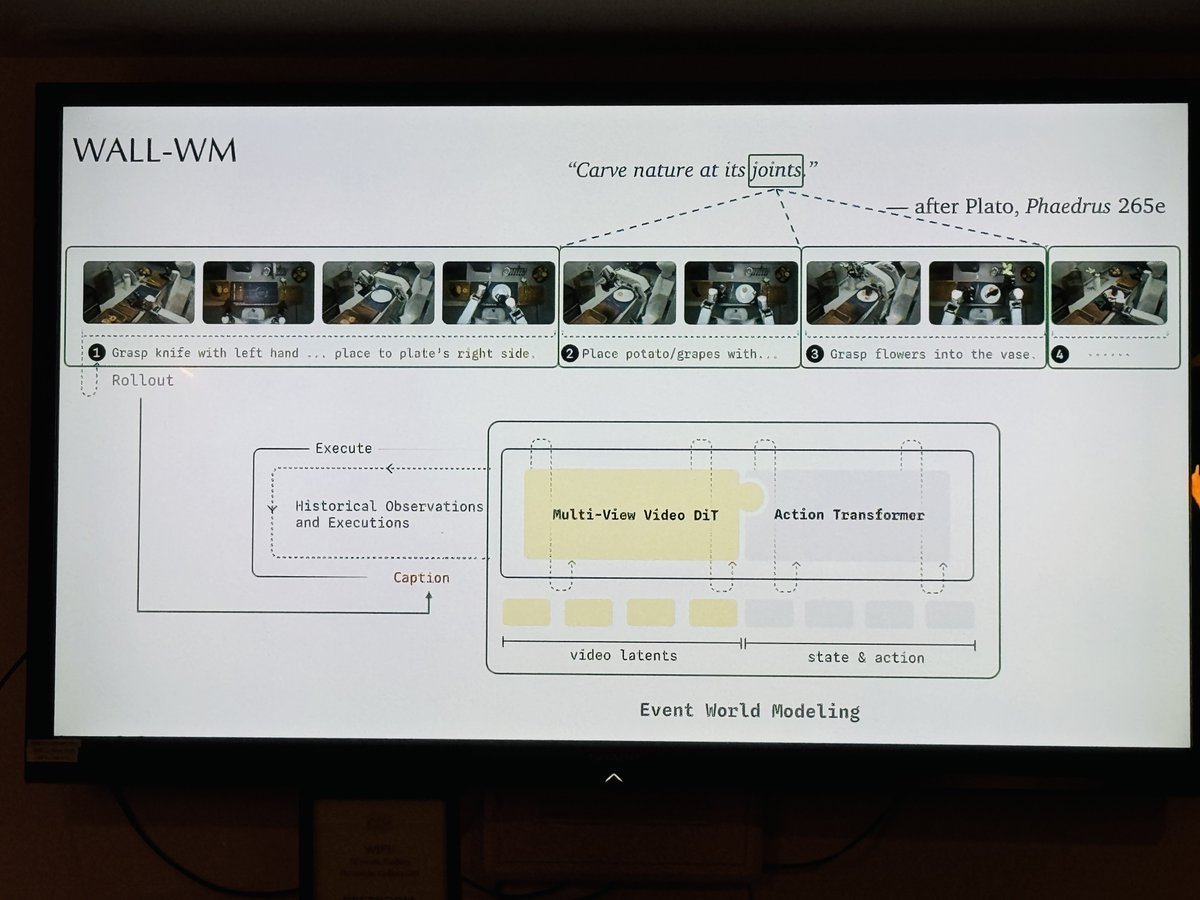
WALL-WM is a World Action Model (WAM) built on event-level VLA pretraining.
Existing WAMs typically:
• initialize from multimodal/video foundation models
• directly train & infer fixed-length action chunks conditioned on observation instruction
Problem: text, vision, and action lie on different manifolds and temporal scales → direct joint optimization can distort pretrained representations.
💡 Core idea: Event as atomic unit
WALL-WM replaces fixed frame-chunk modeling with semantic event modeling.
Well-posed event:
(c_event, O) → v_event
Event enforces:
• semantic alignment (language ↔ event meaning)
• temporal alignment (vision / action / tactile consistency)
→ “Carve nature at its joints” (Plato, Phaedrus 265e)
🧠 Architecture
• Historical Observations Executions buffer
• Multi-View Video DiT → video latents (world dynamics)
• Action Transformer → state-action modeling
• Unified Event World Modeling block couples video action pathways
Language stack:
• Qwen3.5 Staircase Decoder in unified embedding space
⚙️ Two inference modes (same event-pretrained backbone)
1. Language-Guided Reasoning (Event Mode)
• consumes next-event descriptions
• produces variable-length execution chunks
• includes explicit temporal event tokens (e.g., “pick…1.6s → fallback → pick…2.4s”)
• ON/OFF switch separates reasoning from execution
→ semantic event rollout
2. Event World Modeling
• Video DiT Action Transformer
• purely event-centric rollout of dynamics
• no fixed-length chunk assumption in modeling
→ temporal event rollout
🔁 Key decomposition
Semantic path:
Language → Event
Temporal path:
Vision/Action → Event
Unified abstraction stack:
Pixel → Patch → Frame → Event
🧩 Training philosophy (anti–Bitter Lesson framing)
Shift annotation cost → training cost via self-supervised event structure learning
End-to-end target pipeline:
Reasoning/Grounding → Perception → Future Video → 3D Representation → Action
Core principle:
“The more we do (preprocessing structure), the less the model has to infer.”
Includes:
• normalization
• spectrograms
• voxelization
• tokenization
⚠️ video-only pretraining critique
Failure modes:
• strong latent distribution assumptions (e.g., SIGReg-style constraints)
• semantic rediscovery cost in vision-action alignment
• weak coupling between language semantics and temporal execution
Examples: VJPEA, LeWorldModel-style approaches
Fix:
Language acts as semantic tagging over VA event clusters, not temporal supervision signal.
🧬 Representation hierarchy
Raw physical signals:
vision / audio / action / biological signals
↓ (signal processing mathematical abstraction)
structured modalities
↓
Event layer (highest alignment primitive)
📌 Conclusion
WALL-WM is not a chunk-level improvement.
It replaces fixed temporal chunking with event-level alignment as the fundamental unit of world modeling.
Where prior WAMs learn “what action follows this frame window”,
WALL-WM learns “what event is unfolding in the world”.
WALL-WM defines the event-based representation primitive for future world models and embodied agents.
@CVPRConf #CVPR2026 #WorldModel




🌌 At @saturdayrobotic Saturday Robotics Research Night, we hosted @mli0603 Zhaoshuo Li (Robotics & World Model Tech Lead @NVIDIAAI Cosmos) for a lightning talk on Cosmos 3.
Cosmos 3 is a unified omnimodal world model built on a Mixture-of-Transformers (MoT) backbone with parallel Autoregressive Diffusion pathways connected via cross-attention. One model jointly understands & generates Language, Image, Video, Audio, and Action with flexible I/O.
It effectively subsumes:
👁️ VLMs
🎥 Video Generators
🔊 Audio Generators
🌍 World Simulators
🤖 World-Action Models
🎮 Robot Policy Models
Single backbone supports:
• Vision Reasoning
• Image Generation
• Audio-Visual Generation
• Robot Policy Control
• Forward Dynamics
• Inverse Dynamics
Vision reasoning grounds language in spatial relations, temporal evolution, object states, and actions.
Forward Dynamics:
(obs controls) → future video rollouts for planning, evaluation, and synthetic data generation.
Inverse Dynamics:
(video) → trajectories/actions explaining observed state transitions.
🍿 Popcorn demo:
0.3–3.4s pick cup
3.4–14.8s stabilize cup → insert scoop → scoop twice → transfer popcorn while maintaining alignment
14.8–18.7s place cup → return scoop → retract arms
Not frame captioning—the model temporally segments manipulation into physically meaningful subgoals.
Forward Dynamics demo:
camera observation (blue point-cloud-like representation) hand pose (green skeletal hands) → physically plausible future interaction rollouts respecting object dynamics.
Inverse Dynamics demo:
robot manipulation video → articulated 3D trajectories recovered from observed pixel changes.
🔥 Most impressive: Cosmos 3 Omni Block.
Prompt:
“pick the Cosmos 3 Omni block from bottom drawer and place it on counter”
The model first performs explicit spatial grounding:
gripper(514,769)
block(471,780)
drawer(400,760)
counter(460,310)
while identifying distractors:
forklift, white truck, white SUV, quadruped robot, Physical AI Builder figure.
It then generates structured reasoning pixel-space action outputs:
[514,769] approach block
[507,783] grasp block
[500,471] lift from drawer
[464,278] move to counter
[460,275] place on counter
A second, far more cluttered scene containing multiple robot arms, excavators, vehicles, and the same drawer receives the identical prompt and produces analogous trajectories after grounding relevant objects and free-space regions.
Cosmos 3 positions omnimodal world models as a scalable foundation for embodied agents, jointly performing understanding, generation, simulation, reasoning, and control inside a single architecture.
It achieves SoTA across diverse understanding & generation benchmarks, and NVIDIA is releasing the full stack: code, checkpoints, curated synthetic datasets, and evaluation benchmarks.
Cosmos 3 = a unified world-action engine.




5
13
3,086
Jun 8
🥳WALL-WM made it to the alphaXiv Trending Top 10. Instead of predicting every frame uniformly, it learns to focus on the moments that matter.
Project: x2robot.com/pages/wm
arXiv: arxiv.org/abs/2606.01955
GitHub: github.com/X-Square-Robot/wa…
HF: huggingface.co/papers/2606.0…
@_akhaliq @HuggingPapers @Xianbao_QIAN @TheHumanoidHub @chris_j_paxton @XRoboHub
May 29
Introducing WALL-WM, our open-source World Model for embodied AI and the next piece of our open-source robotics stack.
Carving World Action Modeling at the Event Joints
Read the blog: x2robot.com/en/pages/wm
Why it matters
WALL-WM shifts robot world modeling from fixed-length action chunks to event-grounded video-action pretraining. It learns around events like reaching, contact, grasping, lifting, moving, and placing, so language, vision, and action align more naturally.
Why you should care
WALL-WM brings together:
•Event-grounded VLA pretraining
•Prior-aligned video-action architecture
•Wan-based video tower randomly initialized action DiT
•Multi-view perception with sight-cone masking, tube patch masking, and Camera RoPE
•Event Mode for variable-length execution
•Unified Mode with Staircase Decoding
•DMuon for large-scale training
The goal: help robots learn what physically matters, not just what happens in the next fixed slice of time.
Code (coming soon): github.com/X-Square-Robot/wa…
#opensource #EmbodiedAI
2
9
35
7,867
X Square Robot retweeted
🛬 Landing in Denver for @CVPR!
🤖 Excited to introduce Saturday Robotics Research Night (@saturdayrobotic), co-hosted with @aurorafeng_01 and @ManycoreTech.
It might be @CVPRConf's most research-dense side event.
We've received 550 registrations and approved 300 researchers, engineers, founders, professors. The event has also been organically amplified by both the official @CVPR and @CVPRConf X accounts.
Our venue can probably fit only ~100 people comfortably, so if you're coming, please arrive early.
We've curated 1 hour of lightning talks packed with frontier research, new model releases, and technical hot takes at the frontier of Physical AI:
⚡ @aurorafeng_01 (Founder @neuralmotion) — NM-GenET
Generative video-action model for universal embodiment transfer and cross-embodiment policy learning.
⚡ @mli0603 (Robotics & World Model Tech Lead @NVIDIAAI) — Cosmos 3
A true omnimodal world model unifying language, image, video, audio, and action generation/control in a single architecture. Yes, robot policy control included.
⚡ Xiaofan Li (World Model Tech Lead @XSquareRobot) — WALL-WM
Moving beyond next-chunk prediction toward next-event prediction for scalable World Action Models.
⚡ @SourORZ1 (@UMich)
Test-Time Scaling for World Action Models via Zero-Shot Geometric Verification.
⚡ @JieWang_ZJUI (@Penn @GRASPlab)
Toward a Robotics MMLU: What should evaluation for foundation robot policies actually look like?
⚡ @guocheng_qian (Senior AI Researcher @Snap)
Diffusion-DRF: Rich differentiable rewards for video diffusion RL fine-tuning.
A rare opportunity to hear what may be coming next in robotics, world models, embodied intelligence, video generation, evaluation, and Physical AI.
If you're around the convention center, DM me — happy to grab a ☕ and chat about robotics, world models, embodied AI, or whatever you're building.
And if you can't make it, you're always welcome to join our weekly @saturdayrobotic World Models Reading Club in San Francisco.
See everyone in Denver. ✈️🔥
#CVPR #CVPR2026 #Robotics #EmbodiedAI #WorldModels #PhysicalAI




1
7
18
2,715
Jun 1
After open-sourcing Wall-OSS-0.5 and WALL-WM this week, we’re heading to #CVPR2026 in Denver to meet the embodied AI and robotics community in person.
If you’re building, researching, or simply curious about robotics, VLA, world models, robot foundation models, sim-to-real, or real-world deployment, come find us.
Where to Meet X Square Robot at @CVPR
1. Tech Talk | June 4
X Square Robot × Embodied AI Workshop
📍Location: Room 107
Topic: Event-Level World Action Model for Embodied AI
Speaker: @shalfunnn World Model Tech Lead
2. CVPR Exhibition | 📍Booth 853
June 5 | 10:00 AM-6:00 PM
June 6 | 10:00 AM-6:00 PM
June 7 | 10:00 AM-3:00 PM
3. Saturday Robotics Meetup | June 6, 5:30-9:30 PM
We’ll also be joining the @saturdayrobotic @junfanzhu98 *Research Night* gathering to share what we’ve been working on and connect with the broader robotics community.
Register: luma.com/zamm9g2g
4. X-Night Afterparty | June 7, 6:30-9:00 PM
📍Downtown Denver
Join us for steak chats, technical conversations, open roles, internship discussions, and a few robotics debates we probably won’t settle in one night.
Register: luma.com/a7z814iy
See you in Denver.

2
3
18
3,474
X Square Robot retweeted

May 29
A practical step forward for real-world manipulation: an open-source world model that replaces rigid action chunking with event-grounded prediction.
It anchors planning and control to actual physical moments (reach → grasp → contact → place), giving robots more natural timing, tighter contact handling, and reliable long-horizon behavior without heavy sim-to-real tuning.
The dual-arm demo shows clean, adaptive kitchen table-setting (plates, cutlery, fruit) exactly the kind of unstructured bimanual task most labs struggle to make robust today.
For researchers and engineers, it’s immediately usable: better dexterity out of the box, variable horizons that match real physics, and full open weights/code to build on.
'Carving World Action Modeling at the Event Joints'
📌 Read the blog: x2robot.com/en/pages/wm
Code (coming soon): github.com/X-Square-Robot/wa…
Credit: @XSquareRobot
——-
If it matters in AI or Robotics, you'll read it here first: 22astronauts.com
3
13
36
3,769
May 29
Introducing WALL-WM, our open-source World Model for embodied AI and the next piece of our open-source robotics stack.
Carving World Action Modeling at the Event Joints
Read the blog: x2robot.com/en/pages/wm
Why it matters
WALL-WM shifts robot world modeling from fixed-length action chunks to event-grounded video-action pretraining. It learns around events like reaching, contact, grasping, lifting, moving, and placing, so language, vision, and action align more naturally.
Why you should care
WALL-WM brings together:
•Event-grounded VLA pretraining
•Prior-aligned video-action architecture
•Wan-based video tower randomly initialized action DiT
•Multi-view perception with sight-cone masking, tube patch masking, and Camera RoPE
•Event Mode for variable-length execution
•Unified Mode with Staircase Decoding
•DMuon for large-scale training
The goal: help robots learn what physically matters, not just what happens in the next fixed slice of time.
Code (coming soon): github.com/X-Square-Robot/wa…
#opensource #EmbodiedAI
8
40
228
38,071
X Square Robot retweeted

May 28
X Square Robot today officially open-sourced Wall-OSS-0.5 under the motto "Pretrain Once, Act Anywhere."
Wall-OSS-0.5 is a Vision-Language-Action model for real-world robotic manipulation. According to the team, the pretrained checkpoint shows zero-shot generalization on multiple real-robot tasks without task-specific post-training, while also outperforming recent open-source models such as π0.5 in fair comparisons that control for data and fine-tuning scale.
The model also reports stronger embodied grounding, suggesting that action-aware training can improve robot-relevant understanding without eroding general multimodal capability.
Code and model weights are expected to be released this weekend.
Project: x2robot.com/en/oss#resources
Worth following for researchers and developers working on VLA, robot learning, and embodied AI.
May 28
We are open-sourcing Wall-OSS-0.5.
Pretrain Once, Act Anywhere.
Wall-OSS-0.5 is a VLA model for real-world robotic manipulation, exploring whether pretraining alone can produce robot capabilities directly testable on physical hardware before task-specific fine-tuning.
Key technical highlights:
• Gradient-bridged co-training
• Vision-Aligned RVQ Action Tokenizer
• Action-Space Supervision
• DMuon distributed optimizer
In zero-shot real-robot evaluation, the pretrained checkpoint achieved task-progress scores above 80 on multiple tasks, including Block Sorting, Fruit Sorting, Ring Stacking, and Rope Tightening.
Paper, code, blog, and uncut videos: x2robot.com/oss#resources
2
6
18
3,622
May 28
We are open-sourcing Wall-OSS-0.5.
Pretrain Once, Act Anywhere.
Wall-OSS-0.5 is a VLA model for real-world robotic manipulation, exploring whether pretraining alone can produce robot capabilities directly testable on physical hardware before task-specific fine-tuning.
Key technical highlights:
• Gradient-bridged co-training
• Vision-Aligned RVQ Action Tokenizer
• Action-Space Supervision
• DMuon distributed optimizer
In zero-shot real-robot evaluation, the pretrained checkpoint achieved task-progress scores above 80 on multiple tasks, including Block Sorting, Fruit Sorting, Ring Stacking, and Rope Tightening.
Paper, code, blog, and uncut videos: x2robot.com/oss#resources
6
24
120
23,836
May 28
Code is coming soon!
Github: github.com/X-Square-Robot/wa… Hugging Face: huggingface.co/x-square-robo…
1
6
674

X Square Robot is moving its WALL-B powered home robots into real households, where the robots can learn cleaning and daily tasks directly from families.
May 25

🤖 INTERESTING: X Square Robot is moving its WALL-B powered home robots into real households, where they learn cleaning and daily tasks directly from families.
Would you live with a robot at home?
1
9
34
3,719
May 26
Over the past month, we asked families why they would want a robot at home. The answers were not really about sci-fi.
They were about only children needing company.
Parents getting older.
People living alone.
Couples arguing over chores.
Long workdays.
Homes that still need care when no one has energy left.
Some wanted help cleaning.
Some wanted someone to check the doors, windows, gas and lights.
Some wanted companionship for a child, a parent, or themselves.
That is what makes home robots interesting to me.
Not because they are perfect today.
But because the need is already real.
Would you live with one?

Would you actually live with a robot at home? A new robot family member is starting to arrive. 🤖
35 days after Born to Bot, Bot to Family, X Square Robot is moving its next-gen home robot into real households.
It runs on WALL-B, a world model that connects vision, language, touch, action, and physical prediction for messy, unpredictable home tasks.
It can already help with parts of cleaning and tidying, but it still moves slowly, hesitates, and learns inside real homes.
More than 1,000 families have signed up. Pre-orders are open now — would you bring one home?
5
6
26
2,487
May 26
感谢福爸的分享😊
May 25

深度评测!自变量家务机器人离“真干活儿”还有多远?
Can Home Robots Really Do Chores Yet? A Deep-Dive Review of Xsquare Robot #XSquareRobot #humanoids
1
441
X Square Robot retweeted

May 25
Home robots are leaving stage demos and entering the only test that really matters: ordinary family life.
X Square Robot is starting to move its next-gen home robot into real households.
It runs on WALL-B, a world model designed to connect vision, language, touch, action, and physical prediction, which is exactly what a home robot needs when the real world refuses to stay neat.
A kitchen is not a controlled environment of a factory floor. it is a moving negotiation between habits, clutter, pets, children, half-finished chores, and objects that never return to the same place twice.
That is where Moravec’s paradox shows up: tasks that feel effortless to humans, like picking up clutter, avoiding pets, or judging what belongs where, are often brutally hard for robots.
Would you bring a robot with daily chores?
May 25
Meet the world at home, where life happens and bots become family
35 days ago, at our “Born to Bot, Bot to Family” launch event, we shared our vision of bringing robots into real homes.
Today, we’re very happy to share that our robots are now gradually entering real families.
For embodied AI, the real world is everyday life: different routines, different kitchens, and different ways of doing even the simplest tasks.
This is where robots meet the world at home, where life happens and bots become family.
They are still learning. They may move slowly, hesitate, and sometimes look a little clumsy. But every home they enter helps them understand the world a little better.
11
9
45
6,770
May 26
Excited to be part of this!
Looking forward to sharing WALL-WM with the Robotics & World Models community at #CVPR2026. See you there!
We (@saturdayrobotic) are hosting a Robotics & World Model happy hour at @CVPRConf 2026 on 6/6, fancy venue delicious food.
If you're into Robotics & World Models, join us: luma.com/zamm9g2g
Lightning talks:
1. @neuralmotion — Introducing NM-GenET, a generative video-action model for universal embodiment transfer and cross-embodiment, cross-domain policy learning.
2. @nvidia Cosmos — Introducing Cosmos3, a next-generation omni world model that unifies image, video, audio, embodied reasoning, and robot policy control into a single scalable foundation model.
3. @XSquareRobot, @ZJU_China — WALL-WM, an event-centric World Action Model that scales general-purpose robot learning through semantic event pretraining, unified VLA inference, and large-scale real-world generalization.
4. @UMich — Exploring test-time scaling for World Action Models using zero-shot geometric verification to improve rollout quality, physical consistency, and downstream robot action performance without retraining.
and more...
See you in Denver @CVPR on 6/6!
2
1
10
1,414