
Joined July 2013
- Tweets 573
- Following 277
- Followers 176
- Likes 10,971
38 Photos and videos





oriol retweeted

Jun 7
15 Policy Optimization and Preference Optimization techniques important in 2026
▪️ GRPO
▪️ DPO
▪️ REINFORCE
▪️ DAPO (Dynamic sAmpling)
▪️ Dr. GRPO
▪️ GSPO (Group Sequence)
▪️ DHPO (Dynamic Hybrid)
▪️ EP-GRPO (Entropy-Progress Aligned)
▪️ TR-GRPO (Token-Regulated)
▪️ DPPO (Dynamic Pruning)
▪️ ARPO (Agentic Reinforced)
▪️ VPO (Vector PO)
▪️ InSPO (Intrinsic Self-reflective Preference Optimization)
▪️ TI-DPO (Token-Importance Guided DPO)
▪️ RAPPO (Reliable Alignment for Preference PO)
Save this list as a quick reference for the most relevant policy optimization methods in 2026: turingpost.com/p/reasoning-r…
14
71
358
19,804

Jun 1
@Inforenfe No está el AVANT de Lleida 07:05 h - Barcelona 08:11 h del dia 9 de Julio? Normalmente está
1
89
Jun 1
@Renfe No hi ha el AVANT de Lleida 07:05 h - Barcelona 08:11 h pel dia 9 de Juliol? Normalment hi és
1
80
oriol retweeted

May 28
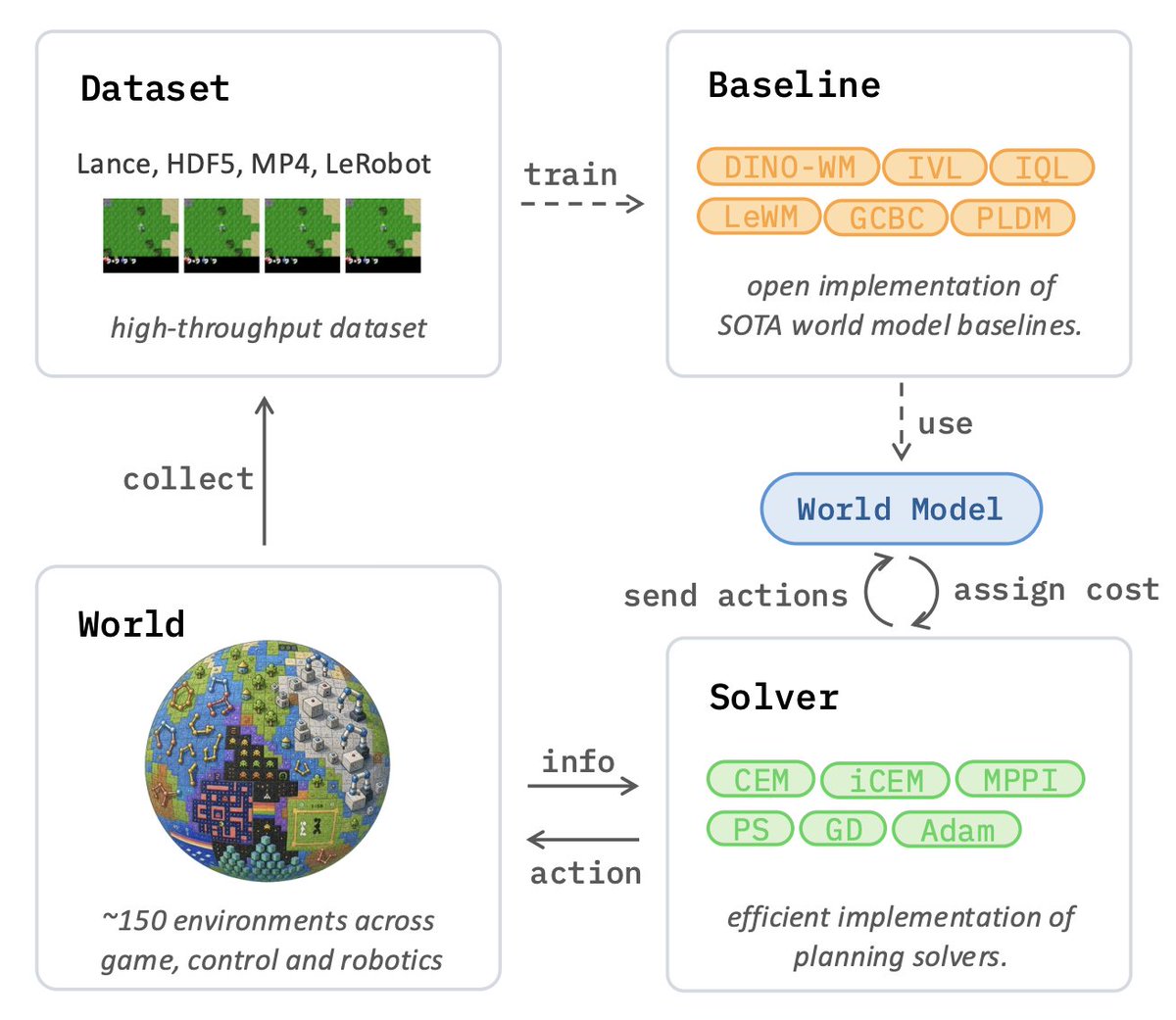
Would you like to join the research effort on JEPA and World Models easily?
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: github.com/galilai-group/sta…
40
273
1,816
113,364
oriol retweeted

May 25
Fita espectacular pel català! A part del text de la Viquipèdia, sabíeu que l'historial d'edicions de Viquipèdia té un valor també molt important per entrenar IAs? Per exemple, es fan corpus de correcció gramatical com WikEd Error a partir de l'historial d'edicions. Tot s'aprofita
May 25

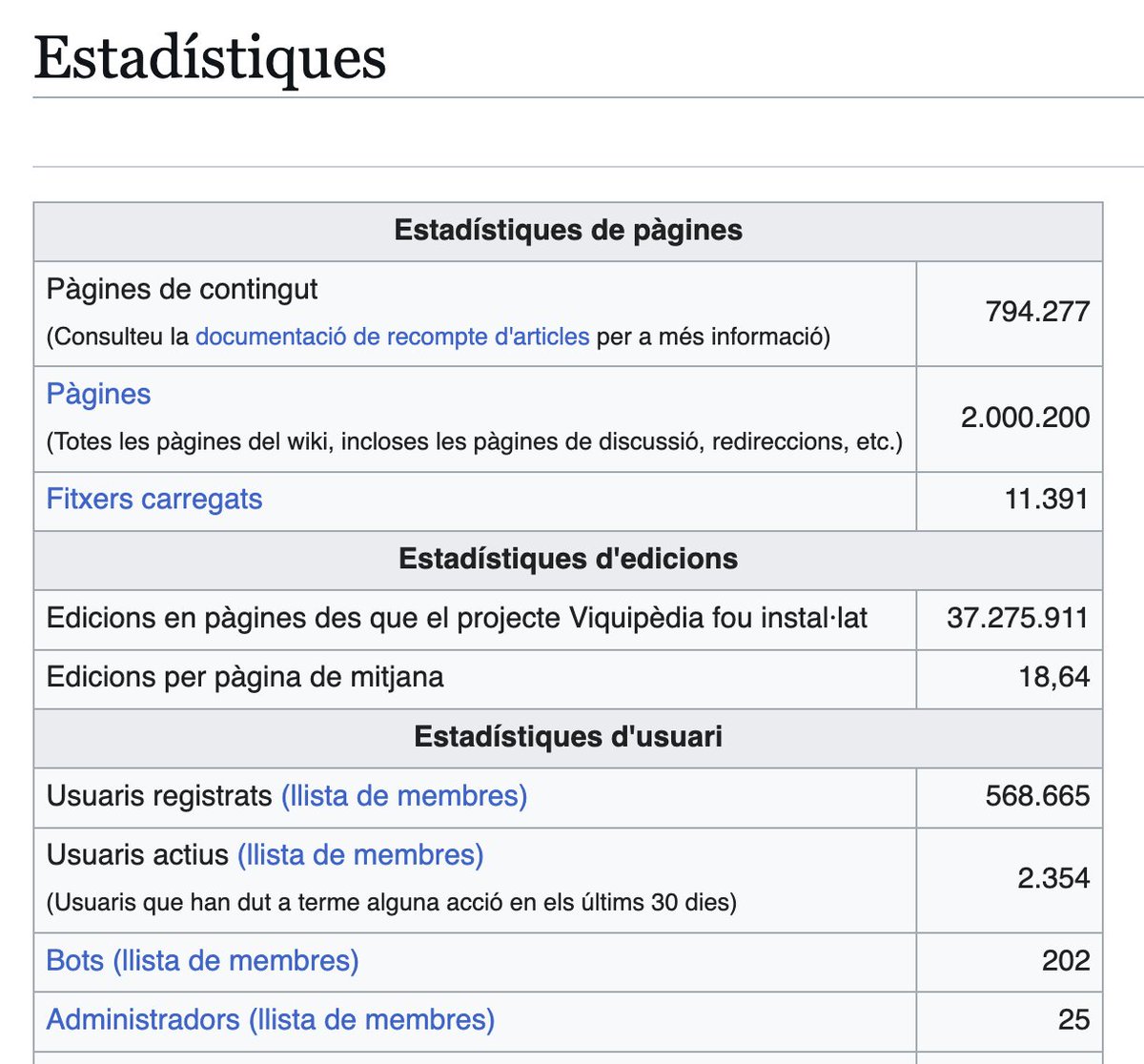
Aquesta setmana la @Viquipedia en català ha arribat als 2 milions de pàgines. Això inclou totes les pàgines del wiki, incloses les pàgines de discussió, redireccions, etc.
A data d'avui, tenim 794.277 articles editats i revisats per humans, que parlem la mateixa llengua. Seguim!
1
26
75
2,115
oriol retweeted

May 23
Al 2008 al Batxillerat científic hi havia 18 hores d'assignatures científiques.
> Al 2022 va haver-hi una reforma que va rebaixar fins a 12 hores de ciències.
> Ara, en el document presentat pel Govern d'Illa el 22 de desembre, quedaran només 8 h de matèries de ciències.

🤬🤬🤬🤬🤬🤬🤬🤬
Avui publiquem tots els detalls dels plans del PSC per destruir el futur científic, tecnològic i industrial de Catalunya. Seguint ordres del PSOE.
Creus que exagero?
Llegeix això: mailchi.mp/octuvre/aturar_el…
Cal organitzar-se i DETENIR-LOS.
Que corri, si us plau.
27
901
1,364
48,327
May 11
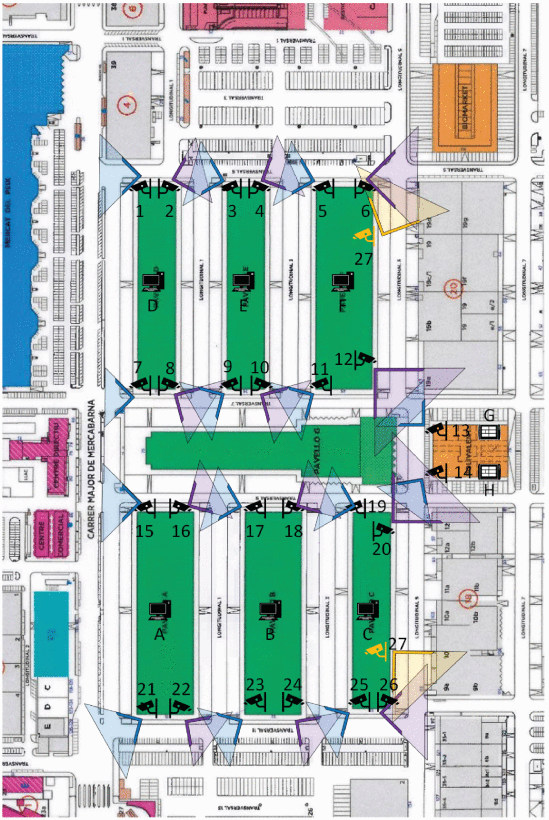
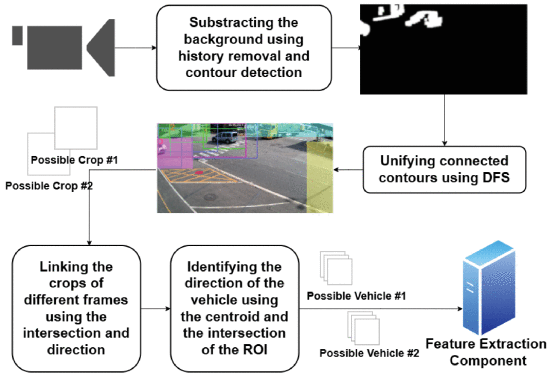
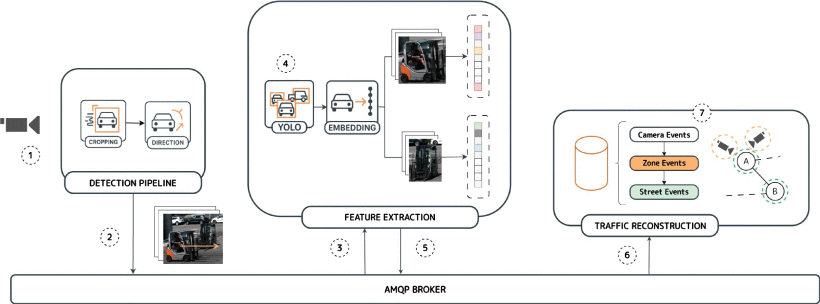
In traffic monitoring, the challenge is not only to detect vehicles accurately, but to do it in real time, across many cameras and limited computational resources.
Our work addresses the gap between edge computer vision accuracy and deployment in constrained fog environments. ⬇️
1
1
68
May 11
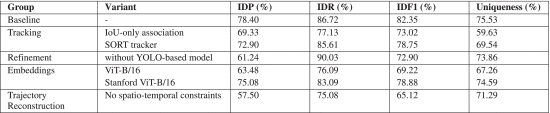
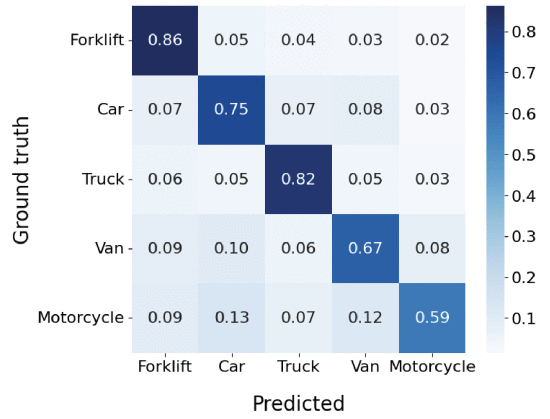
The system was validated on both public benchmarks and a real-world logistics hub: Mercabarna. One of the largest wholesale fresh-food hubs in the Mediterranean.
Under deployment conditions, it correctly identified more than 80% of vehicles while maintaining constraints!
1
1
52
May 11
You can read the full paper in IEEE Access:
ieeexplore.ieee.org/document…
#MultiCameraTracking
#VehicleTracking
#VehicleReIdentification
#ComputerVision
#FogComputing
1
29
oriol retweeted

Apr 15
Google just solved an old RNN problem.
A new paper from Google Research introduces "Memory Caching," and the idea is almost too simple to believe.
Here's the problem it solves:
Modern RNNs compress the entire input into a single fixed-size memory state. As sequences get longer, old information gets overwritten. That's why they still struggle with recall-heavy tasks compared to Transformers.
Memory Caching addresses this by splitting the sequence into segments and saving the RNN's memory state at the end of each segment. When generating output, each token looks back at all these saved checkpoints, not just the current memory.
The complexity trade-off is elegant:
- Standard RNNs: O(L)
- Transformers: O(L²)
- Memory Caching: O(NL), where N = number of segments
You control the trade-off by choosing how many segments to cache. The model smoothly interpolates between RNN-like efficiency and Transformer-like recall.
The paper proposes four ways to use these cached memories:
1. Residual Memory: just sum all cached states (simplest)
2. Gated Residual Memory (GRM): input-dependent gates that weigh each segment's relevance to the current token
3. Memory Soup: interpolates the actual parameters of cached memories into a custom per-token network
4. Sparse Selective Caching (SSC): MoE-style routing that picks only the most relevant segments
Gated Residual Memory (GRM) consistently performs best across tasks.
Under simplifying assumptions, hybrid architectures that interleave RNN and attention layers can be viewed as a special case of Memory Caching. This gives clean intuition for why hybrid models work. They're implicitly caching memory states.
On recall-heavy tasks, Memory Caching significantly closes the gap between RNNs and Transformers. When applied to already strong models like Titans, it pushes them even further ahead on language understanding benchmarks.
Transformers still lead on the hardest retrieval tasks like UUID lookup at long contexts. But the direction is clear: you don't need to choose between fixed memory and quadratic attention. There's a useful middle ground now.
All experiments are at academic scale (up to 1.3B params). Whether these gains hold at frontier scale remains open. This comes from the same team behind Titans and MIRAS, so it's part of a larger research program on memory-augmented sequence models.
Paper: "Memory Caching: RNNs with Growing Memory" (Behrouz et al., 2026)
Link in the next tweet.

21
104
653
43,883
oriol retweeted

Apr 12
Inspirats per la iniciativa del MCP Server del govern francès per consultar dades obertes, des d’opendata punt cat acabem de crear:
Opendata.cat-MCP-Server per consultar totes les dades obertes dels organismes de #Catalunya
Fil!
opendata.cat/mcp/
18
99
312
25,925
oriol retweeted

Apr 10
Many people (myself included) are wondering:
If not LLMs, what should I work on?
In today's blog, I provide a unified framework for finding blue-ocean opportunities in AI, especially in this chaotic era of LLMs.
kindxiaoming.github.io/blog/…
28
107
899
73,110
oriol retweeted

Mar 26
ATENCIÓ: 'Valentina de Montblanc', la primera sèrie d'estètica anime en català creada a Catalunya, arribarà a la plataforma 3Cat el 23 d'abril. Feu-ne difusió perquè ho sàpiga tothom!

83
1,041
2,616
238,170
oriol retweeted

Mar 12
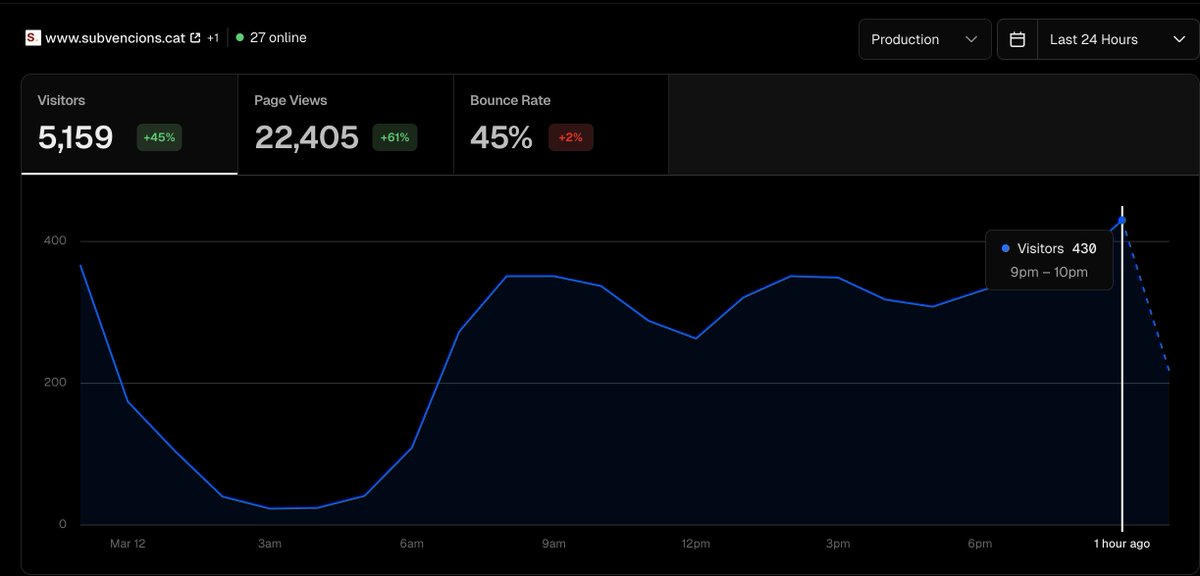
La meva hipòtesi sobre què ha passat amb subvencions
Fa just 1 setmana vaig publicar subvencions.cat. Va ser un projecte d'1 dia. Començat pel matí i acabat a la nit. Tot funcionava correctament. Tenia bastants accessos, però res indicava que forcés la infraestructura de la Generalitat. Al cap i a la fi, la integració amb la base de dades de subvencions forma part dels serveis que ofereixen.
Com molts sabeu, durant 28h van retirar-ne l'accés al públic. A tothom, no només a la meva web. Sincerament, porto sent usuari de Dades Obertes més de 5 anys i mai havien fet res similar amb conjunts de dades comparables. En tornar a ser públics, el conjunt de dades havia canviat. Faltaven els registres de subvencions i ajuts de Diputacions i Ajuntaments.
No només això, sinó que de forma efectiva, com a ciutadans, ja no podem recuperar el conjunt de dades d'abans del canvi. Tot i que en teoria és un servei que s'ofereix a: analisi.transparenciacatalun… (podeu intentar-ho, mai s'arribarà a descarregar).
El que em porta al per què. Per què intentar amagar dades que clarament han de ser públiques? Per llei.
Crec que l'explicació és la següent: veureu que els principals receptors de subvencions són 'beneficiaris no identificats' i 'persones físiques'. Res d'irregular en això; simplement, s'ha anonimitzat. No sóc expert en dret, però possiblement sigui el que toca fer.
El cas és que abans del canvi apareixien noms propis, molts cops de persones migrades, associats a un CIF que al seu torn era d'associacions. Crec que això no havia de passar.
Crec que el procés d'anonimització no es va fer del tot bé. I la manera de solventar aquest error va ser filtrar aquells organismes pels quals sospitaven que el control d'anonimització no havia estat prou efectiu.
Aquesta crec que és una explicació lògica que, per una banda, és molt humana perquè tapa un error i, per l'altra, explica per què s'estan donant explicacions parcials que, sincerament, poden sonar a excuses.
Espero que sapiguem alguna cosa aviat. Avui la web ha tingut un rècord de visites. La meva idea era fer un petit projecte per millorar l'accessibilitat de dades públiques. Dades que ens permeten valorar la feina dels nostres dirigents. Sense dades moltes coses s'aguanten. Però els diners són nostres. I tenim dret a saber on van.
102
1,153
2,317
147,253