
Joined May 2026
- Tweets 72
- Following 44
- Followers 18
- Likes 50
4 Photos and videos


Pinned Tweet

May 4
I spent 14 years building internal developer platforms.
Then AI came… and we’re repeating the exact same mistakes.
Prompts instead of tickets.
Hallucinations instead of standards.
Vibe coding instead of outcomes.
This is the manifesto for what comes next.
“DevOps is Dead” — the full origin story.
Visit us at outcomeops.ai
#AI #PlatformEngineering #OutcomeOps
2
2
67
Jun 4
The pipeline didn’t fail. The wiki did.
When an engineer follows inaccurate advice from an AI that was reading an outdated internal wiki, the root cause isn’t the model. It’s the missing organizational intelligence layer.
New post on what that layer actually looks like:
outcomeops.ai/blogs/what-doe…
1
8
May 18
The model works. The prompts work. RAG works.
The output is still wrong — and now compliance is asking questions.
This is why the category shifted from “AI coding tool” to AI Engineering Platform.
New video full guide:
youtu.be/60UcaSuCRGMBlog:
outcomeops.ai/blogs/what-is-…
1
2
35
May 18
Cut through the feature list noise with these 5 questions:
Where does it run? (Customer cloud, vendor cloud, or laptop?)
What’s the unit of work? (PR vs chat vs task)
Cost model?
Audit story?
Does it know your patterns or just guess?
These decide 90% of enterprise deals.
1
2
22
May 18
The model layer is becoming a commodity.
The platform layer is where enterprise AI lives or dies.
If you’re in regulated industries (fin services, healthcare, defense, insurance), deployment model is the entire decision.
Post 8/8Full 2026 guide comparison here: → Blog:
outcomeops.ai/blogs/what-is-…
Watch the video breakdown: youtu.be/60UcaSuCRGM
What’s your biggest friction with AI-generated code at org scale right now? Drop it below 👇
2
20
May 17
Hot take on the $1.3M/month screenshot everyone is sharing:
This isn't a story about how powerful agents are. It's a story about how undisciplined agentic development has become.
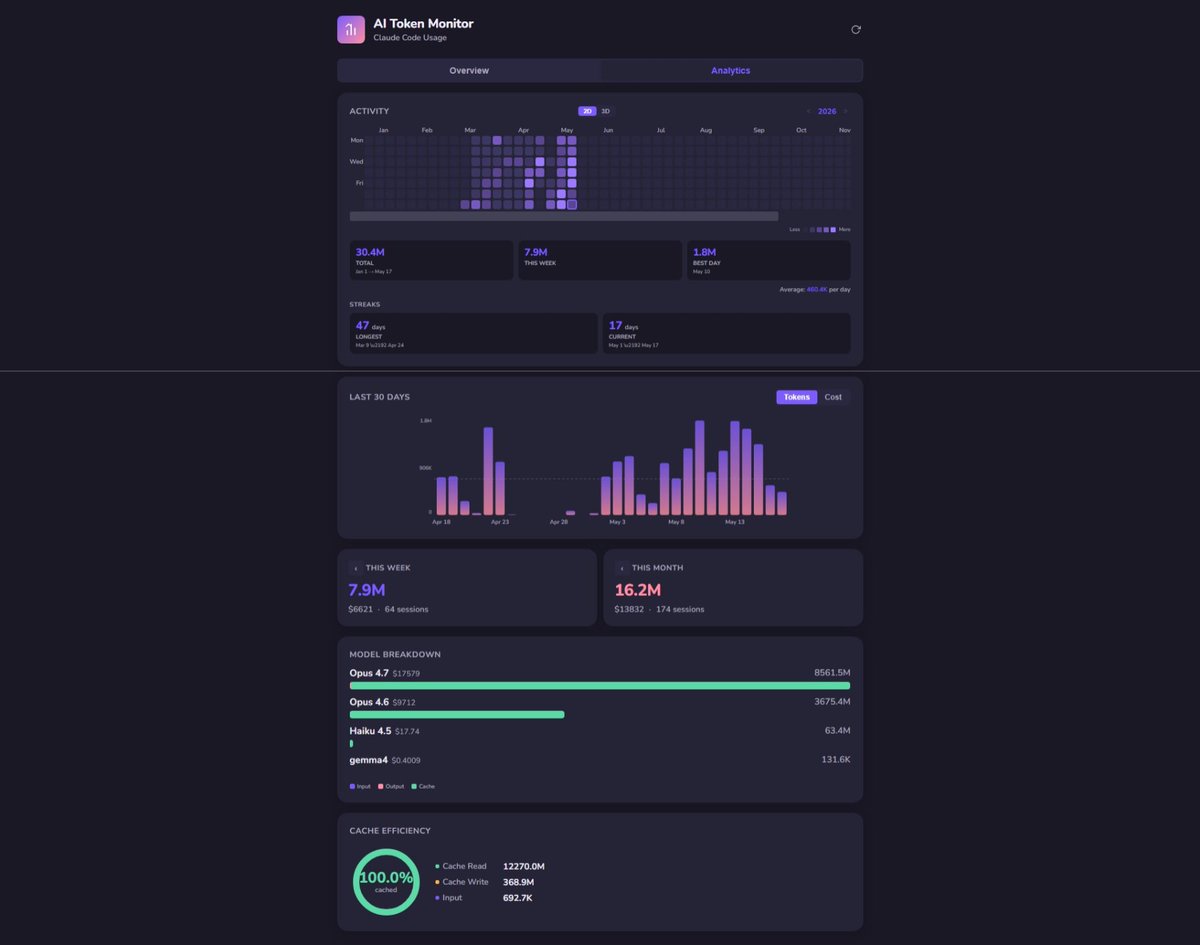
603B tokens. 7.6M requests. ~79K tokens per request on average. That's not reasoning. That's stuffing the entire world into context every turn because nobody built a retrieval layer.
I was on stage at Tech Alley's AI meetup this week making this exact argument. The pattern is everywhere — an engineering leader reached out to me recently because he was melting Claude Opus 1m token context window forcing it to reason across multiple repos. Every turn re-read every file. The fix wasn't a bigger context window. The fix was a code-map and symbol graphs over MCP.
When my agent ships a feature, it doesn't read 10 repos. It queries semantic search against pre-built code-maps and symbol graphs to get back exactly the integration surface it needs. Token spend drops by an order of magnitude. Output quality goes up because the context is signal, not noise.
Frontier model pricing is subsidized today. When that ends, the teams without a context engineering layer are going to discover their AI strategy was actually a venture-funded hallucination.
Cost-per-shipped-feature is the only KPI that matters. Not tokens. Not requests. Outcomes per dollar.
The harness isn't the bottleneck. Context is. That's what we built OutcomeOps to fix.
-> outcomops.ai
1
2
38
May 17
Same agentic workload pattern. Two completely different cost profiles.
Top: undisciplined context, fresh tokens every turn, $1.3M/month. Bottom: governed context via MCP, prompt cache hit rate near 100%, fraction of the cost.
Frontier model providers just told you what they think agents cost. The Anthropic Agent SDK credit cap. The Codex subsidy that survives only because Peter works at OpenAI now. Both are signals.
The pattern that survives when the subsidies end isn't bigger context windows or faster models. It's context engineering. Code-maps over MCP. Semantic retrieval. Cache-aware prompt structure.
Build for cache hits, not token volume. The economics will follow.
For comparison, my own monitor over the same window shows 12.26B cache reads against 692K fresh input tokens. ~17,700:1 cache-to-fresh ratio. Cost profile is two orders of magnitude lower for comparable agentic workload.
1
2
36
May 17
Why We Built OutcomeOps (And What Comes Next)
Every major corporate evolution follows the same pattern: a set of best practices, a few tools, and a promise of transformation.
DevOps did this. So did Agile. So did Cloud.
But each time, 80% of enterprises missed the point. They adopted the tools, not the mindset. They automated pipelines without aligning outcomes. They measured deploys instead of value.
Now AI is here, and it’s happening again.
Read more and subscribe to our Substack:
outcomeops.substack.com/p/wh…
#outcomeengineering #outcomeops #aiengineering #orginizationalintelligence
2
16
May 15
Prompt engineering is a skill. Context engineering is a system.
Here's the 60-second explanation of why the difference matters at enterprise scale and why tools like Anthropic Skills, OpenSpec, and GitHub Spec Kit are the local optimization trap.
Context Engineering Patterns. We define both terms, name the spec-driven tools that solve context engineering at the repo level, and show why real systemic context engineering ADRs encoded, code maps queryable, decades of legacy code in Java, .NET, Python, even ABAP all grounded is the layer enterprises actually need.
youtube.com/watch?v=WERjfVDZ…
#ContextEngineering #PromptEngineering #AnthropicSkills #OpenSpec #GitHubSpecKit #LocalOptimizationTrap #OutcomeOps
1
2
38
May 15
What you'll learn
- What prompt engineering actually is and what it isn't
- Why "context engineering" doesn't just mean RAG
- Why Anthropic Skills, OpenSpec, and GitHub Spec Kit are the local optimization trap
- How ADRs, code maps, and grounded legacy code form the systemic layer
- Why enterprises need the systemic layer above their dev tools Why this matters at enterprise scale Spec-driven tools work for one repo, one developer, one greenfield project.
When you scale across teams, departments, legacy systems, compliance regimes, and decades of institutional knowledge, spec-driven approaches create silos.
In LEAN terms: classic muda.
OutcomeOps eliminates this waste value stream flows via reusable context; working software is grounded in codified intent.
Read more:
Context Engineering deep dive: outcomeops.ai/context-engine… -
Escaping Local Optimization Anti-Patterns: outcomeops.ai/blogs/escaping…
AWS Kiro, OutcomeOps & Spec-Driven Context Engineering: outcomeops.ai/blogs/aws-kiro… -
OutcomeOps the platform: outcomeops.ai
Brian Carpio (founder): briancarpio.com
2
37
May 13
Just published: “Kiro OutcomeOps: Spec-Driven IDE Meets Enterprise Org Intelligence (2026)”
Developers get the delightful spec-driven flow they want. Enterprises get the persistent context layer they actually need.
outcomeops.ai/blogs/aws-kiro…
1/5
1
2
79
May 13
Side-by-side comparison real payoff:
→ Higher first-time PR approval
→ Less architectural drift
→ Devs stay in their IDE while AI actually knows how your company builds software
Full table and details in the post.
4/5
1
2
34
May 13
If you’re running Kiro (or evaluating any agentic IDE) in a regulated or large environment, this hybrid is the move.
Book a 30-min live demo with your repos/ADRs → we’ll connect it live.
outcomeops.ai/blogs/aws-kiro…
What do you think — worth layering Context Engineering on top of spec-driven tools?
5/5 #Kiro #OutcomeOps #ContextEngineering #AWS
2
54
May 11
Tired of AI coding tools that force you to choose between speed and security/compliance?
We just published our full FAQ on air-gapped AI code generation for regulated industries. Thread with the biggest questions 👇
1
2
20
May 11
Generic AI = generic code.
OutcomeOps indexes your ADRs, Confluence, Jira → enforces them on every chunk.
See the full section in our FAQ on how we turned docs into load-bearing guardrails.
1
2
24
May 11
Quick poll for platform/engineering leaders in regulated industries:
Biggest blocker with current AI coding tools? A) Security/IP risk B) No org-specific context C) Compliance hallucinations D) Other
(Answers in our new FAQ 👇)
Tabnine is an AI coding assistant focused on developer-facing experiences — code completion, chat, and agents inside the IDE — with on-prem and air-gapped deployment options for security-sensitive environments.
OutcomeOps is an AI code generation platform focused on organizational context and governance. It generates entire features from Jira tickets, enforces ADRs at chunk-time, and routes every change through a self-review and human PR approval flow.
Tabnine helps developers write code faster. OutcomeOps helps enterprises enforce standards at scale. They solve different problems — some customers use both.
outcomeops.ai/faq
1
3
49