
Software Guy @ Ollama
Joined May 2014
- Tweets 1,448
- Following 229
- Followers 1,507
- Likes 5,025
109 Photos and videos








Pinned Tweet

18 Dec 2020
For your pandemic Friday viewing enjoyment. 'kubectl run -it --rm --image=ghcr.io/pdevine/thisisfine tif' or for the docker inclined 'docker run -it --rm ghcr.io/pdevine/thisisfine'
1
1
9

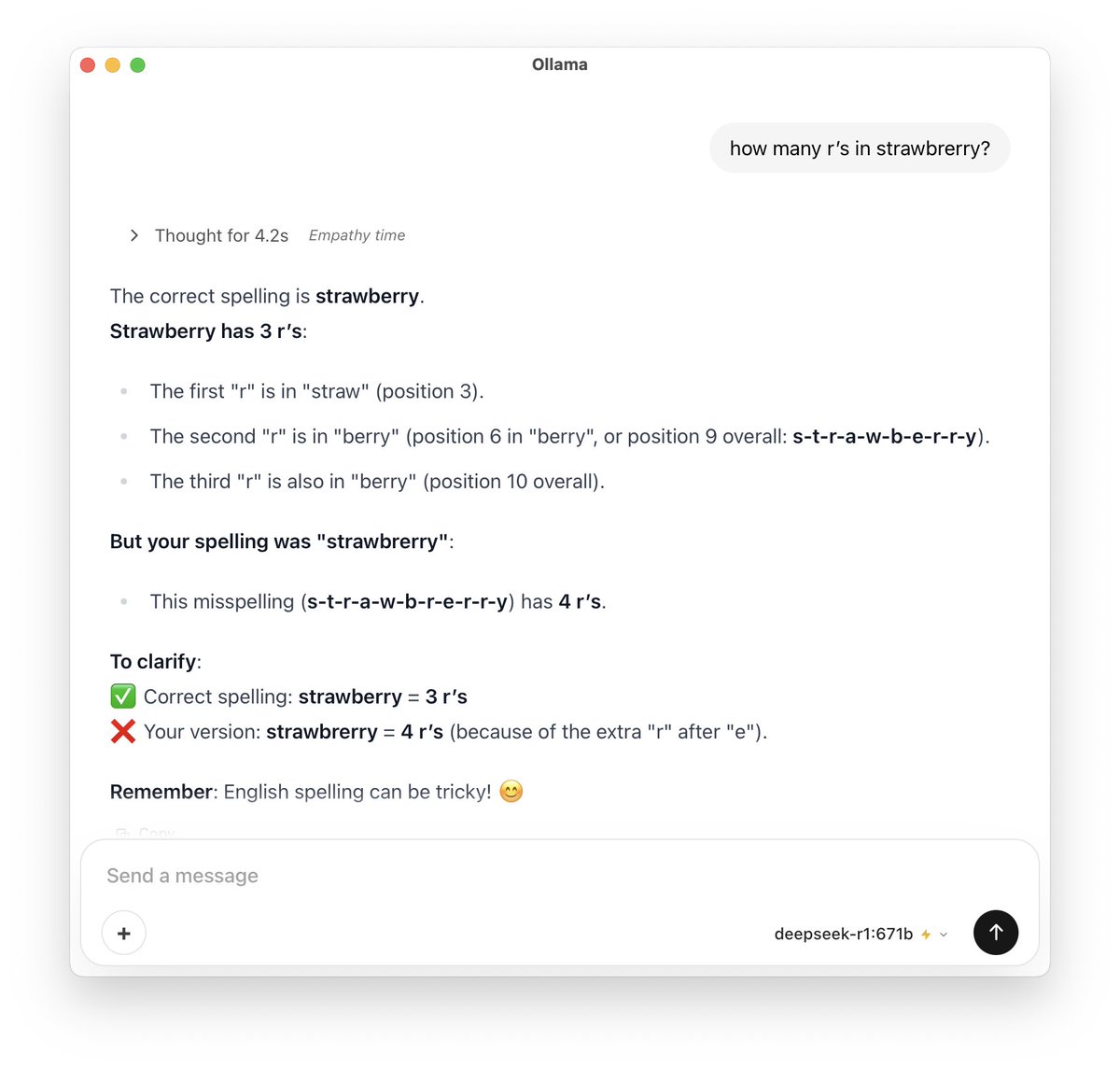
Gemma 4 Quantization-Aware Training (QAT) weights are now available on Ollama!
They reduce memory requirements while maintaining model quality.
E2B:
ollama run gemma4:e2b-it-qat
E4B:
ollama run gemma4:e4b-it-qat
12B:
ollama run gemma4:12b-it-qat
26B:
ollama run gemma4:26b-a4b-it-qat
31B:
ollama run gemma4:31b-it-qat
Try them with ollama launch integrations to use with your favorite tools 👇👇👇
Jun 5

We just dropped Gemma 4 Quantization-Aware Training (QAT) checkpoints on Hugging Face!
All Gemma 4 model sizes and their drafters are now optimized with QAT to cut memory requirements and maximize on-device performance!
42
160
1,465
109,841
May 8
I think almost all of the MTP/DFlash demos I've been seeing over the last few weeks have been using simple greedy sampling. That's great if you can live with temperature = 0, but I think most people want more sampling options.
115
DeepSeek v4 Pro is now on Ollama's cloud! 🚀🚀🚀
Try it with Claude Code:
ollama launch claude --model deepseek-v4-pro:cloud
Try it with Hermes Agent:
ollama launch hermes --model deepseek-v4-pro:cloud
Chat with the model:
ollama run deepseek-v4-pro:cloud
🧵

ALT Ollama now runs DeepSeek
120
174
1,626
105,129
deepseek-v4-flash is now available on Ollama's cloud! Hosted in the US.
Try it with Claude Code:
ollama launch claude --model deepseek-v4-flash:cloud
Try it with OpenClaw:
ollama launch openclaw --model deepseek-v4-flash:cloud
Try it with Hermes:
ollama launch hermes --model deepseek-v4-flash:cloud
Try it with chat:
ollama run deepseek-v4-flash:cloud
(DeepSeek V4 Pro is coming shortly)
🧵
Apr 24

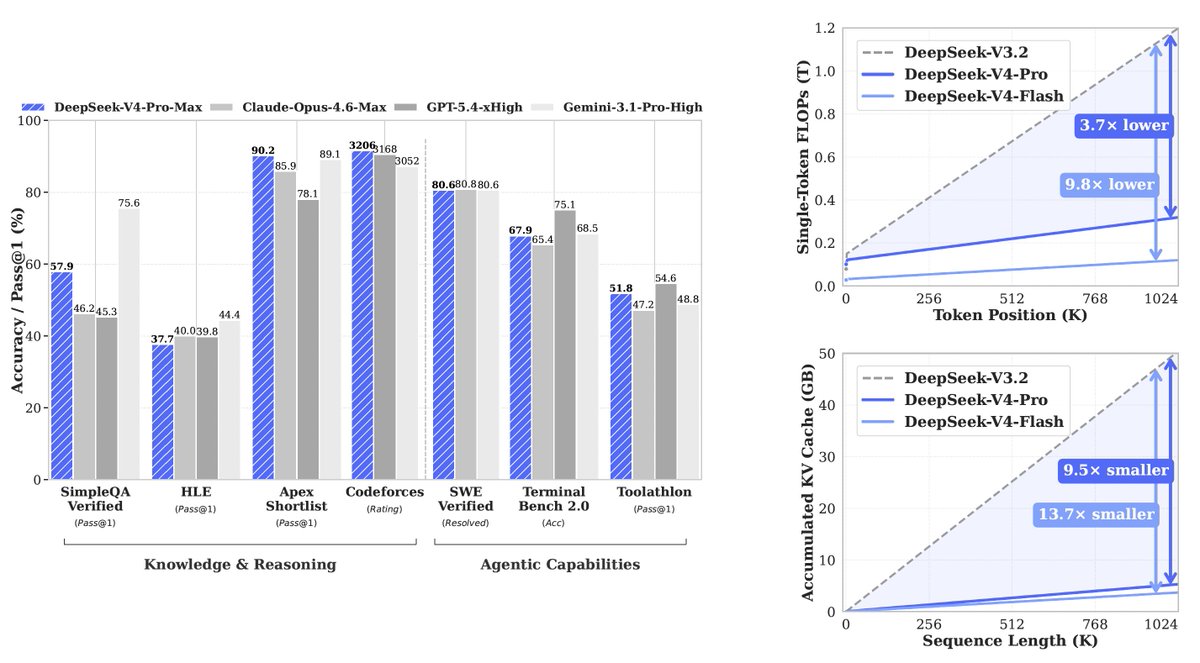
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: huggingface.co/deepseek-ai/D…
🤗 Open Weights: huggingface.co/collections/d…
1/n

88
149
1,555
151,129
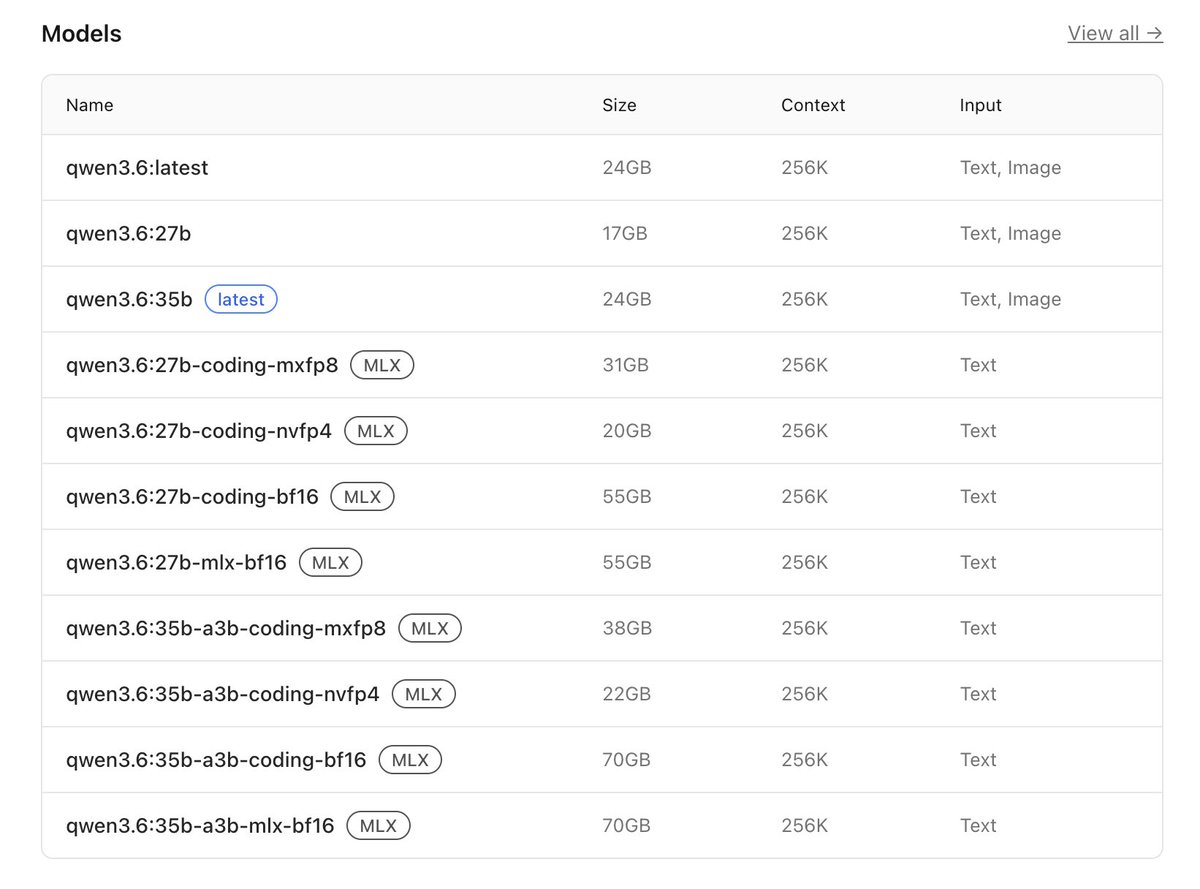
Qwen 3.6 27B model is available on Ollama!
Use it with all the integrations in Ollama or chat with the model.
Chat with the model:
ollama run qwen3.6:27b
OpenClaw:
ollama launch openclaw --model qwen3.6:27b
Claude Code:
ollama launch claude --model qwen3.6:27b
More 👇👇👇
Apr 22

🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power!
Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇
What's new:
🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks
💡 Strong reasoning across text & multimodal tasks
🔄 Supports thinking & non-thinking modes
✅ Apache 2.0 — fully open, fully yours
Smaller model. Bigger results. Community's favorite. ❤️
We can't wait to see what you build with Qwen3.6-27B! 👀
🔗👇
Blog: qwen.ai/blog?id=qwen3.6-27b
Qwen Studio: chat.qwen.ai/?models=qwen3.6…
Github: github.com/QwenLM/Qwen3.6
Hugging Face:
huggingface.co/Qwen/Qwen3.6-…
huggingface.co/Qwen/Qwen3.6-…
ModelScope:
modelscope.cn/models/Qwen/Qw…
modelscope.cn/models/Qwen/Qw…

64
117
1,211
167,373
Patrick Devine retweeted

Apr 18
Hermes Agent 🤝 Ollama

ollama launch hermes
Ollama 0.21 includes supports Hermes Agent, the self-improving AI agent built by @NousResearch.

ALT ollama now has hermes agent support
38
67
1,268
80,367
Patrick Devine retweeted

Apr 18
This tip was dead on.
On my Apple Silicon, switching my @NousResearch Hermes Agent from qwen3.6:35b-a3b to qwen3.6:35b-a3b-mxfp8 cut runtime from 21.6s to 12.7s and increased generation speed from 29.6 to 50.3 tok/s (~1.7x faster).
Apr 17

If you're on a Mac, make sure you run `qwen3.6:35b-a3b-nvfp4` or `qwen3.6:35b-a3b-mxfp8`. Those are a lot faster because they'll run on the MLX backend.
16
42
749
64,996
Apr 17
If you're doing agentic coding with qwen3.6 and @ollama, check out `qwen3.6:35b-a3b-coding-nvfp4`, `qwen3.6:35b-a3b-coding-mxfp8`, and `qwen3.6:35b-a3b-mlx-bf16` which have the recommended hyperparameters set and are blinding fast.
14
16
374
20,979
Apr 17
If you're on a Mac, make sure you run `qwen3.6:35b-a3b-nvfp4` or `qwen3.6:35b-a3b-mxfp8`. Those are a lot faster because they'll run on the MLX backend.
Qwen 3.6 is here, and open-source! Run it locally with improved agentic coding capabilities.
Try it with Claude Code:
ollama launch claude --model qwen3.6
Try it with OpenClaw:
ollama launch openclaw --model qwen3.6
Run it:
ollama run qwen3.6
60
164
2,588
301,866
Apr 1
So glad to finally get this out! We also added a new LRU trie cache w/ Qwen 3.5 which makes using coding tools like Claude and Pi super usable running locally.
Ollama is now updated to run the fastest on Apple silicon, powered by MLX, Apple's machine learning framework.
This change unlocks much faster performance to accelerate demanding work on macOS:
- Personal assistants like OpenClaw
- Coding agents like Claude Code, OpenCode, or Codex
3
4
47
6,536
Patrick Devine retweeted

Feb 13
New @ollama update is god's work btw
Give it a try
Just run `ollama` and thats it
1
5
42
8,661
Jan 27
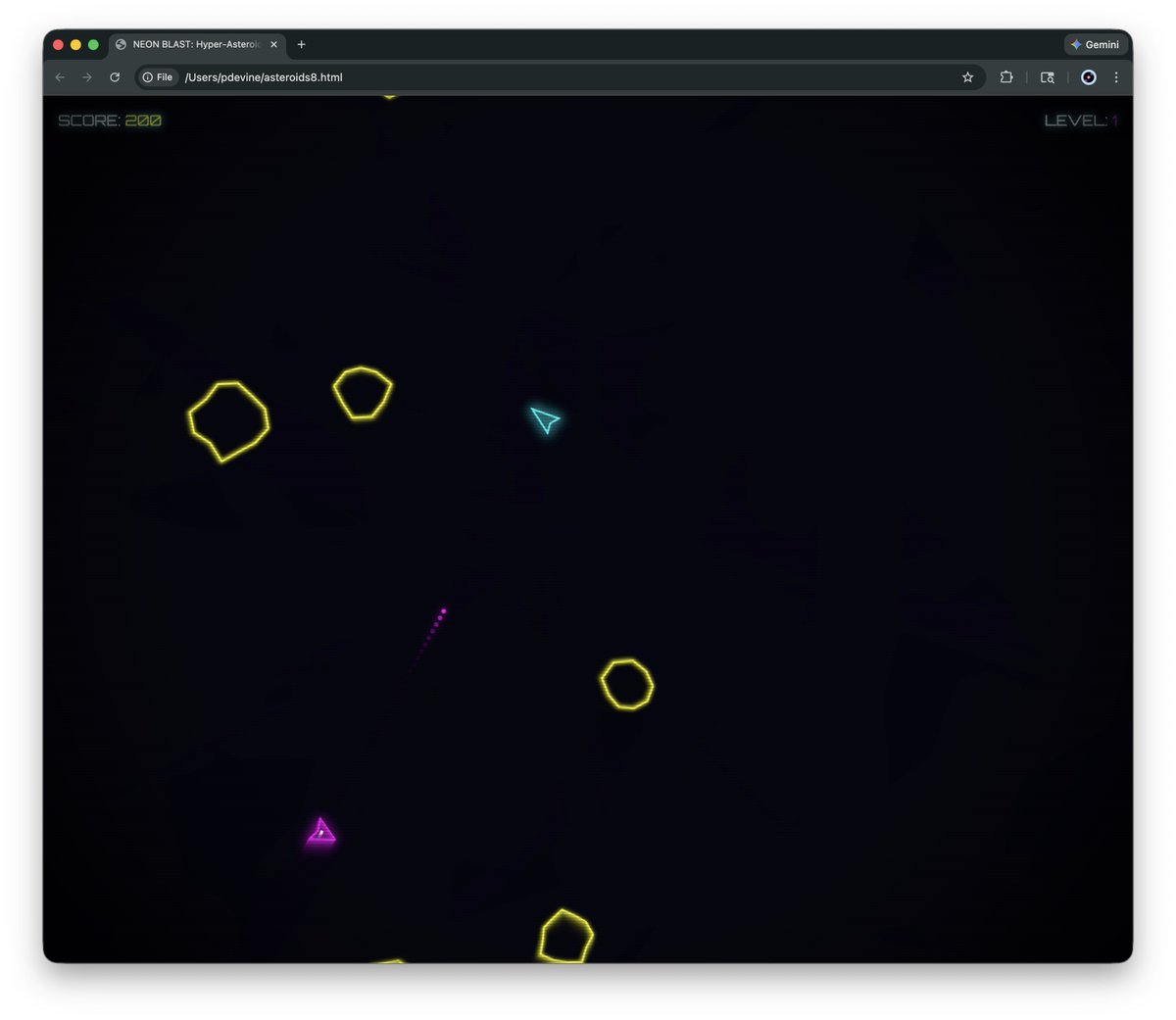
1-shot prompt Asteroids game w/ GLM-4.7-Flash on the experimental MLX backend for @ollama. This was w/ 8-bit affine quantization and a MBP.
4
7
28
10,284
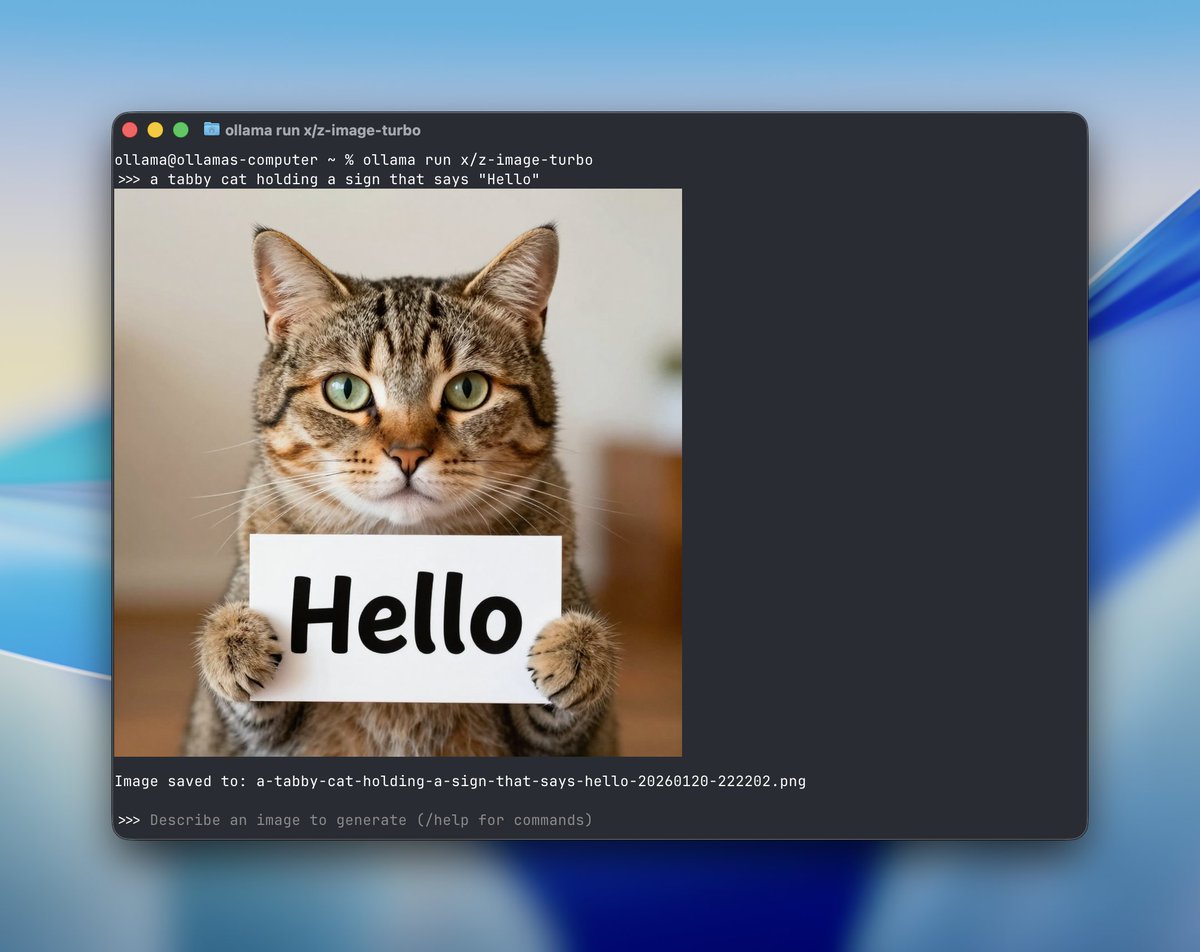
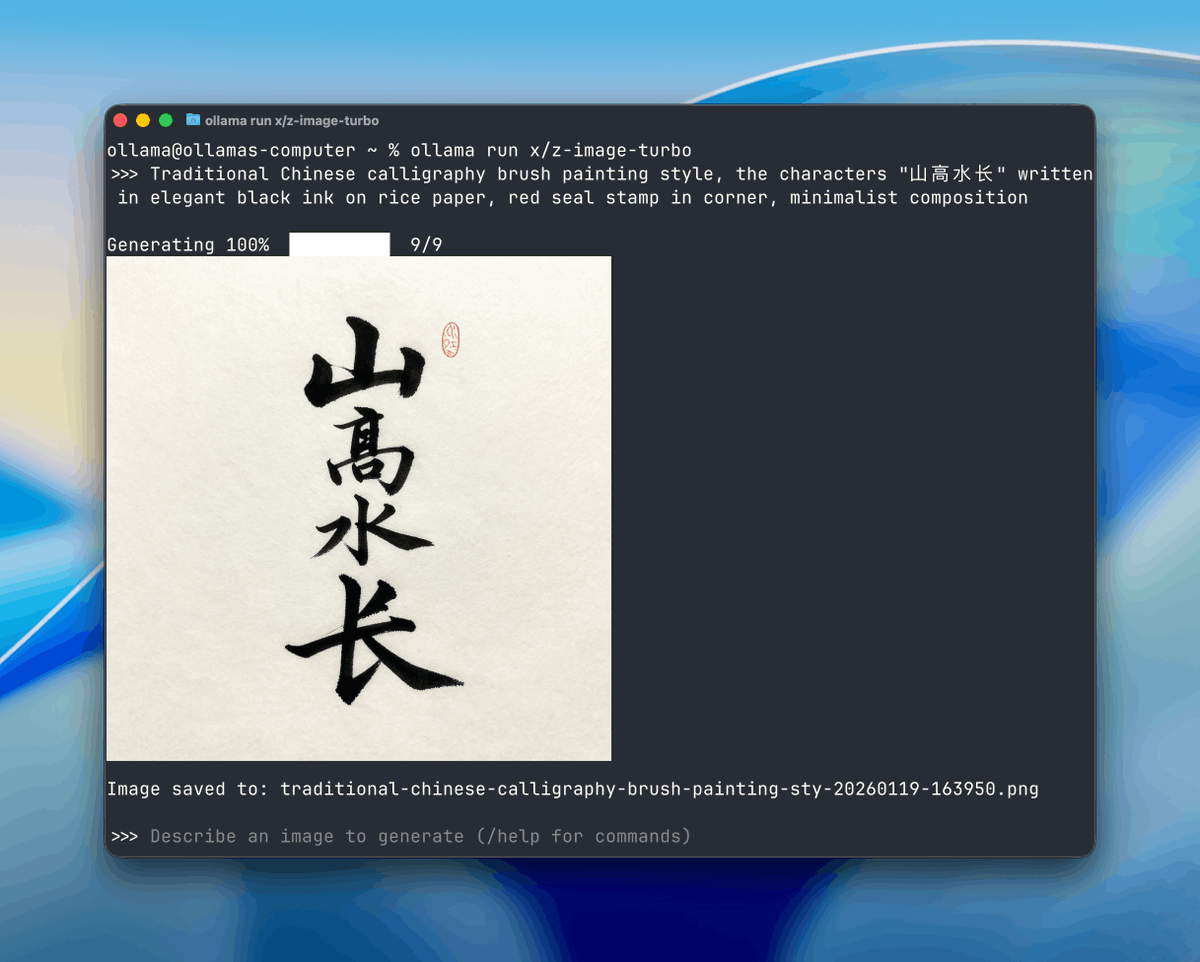
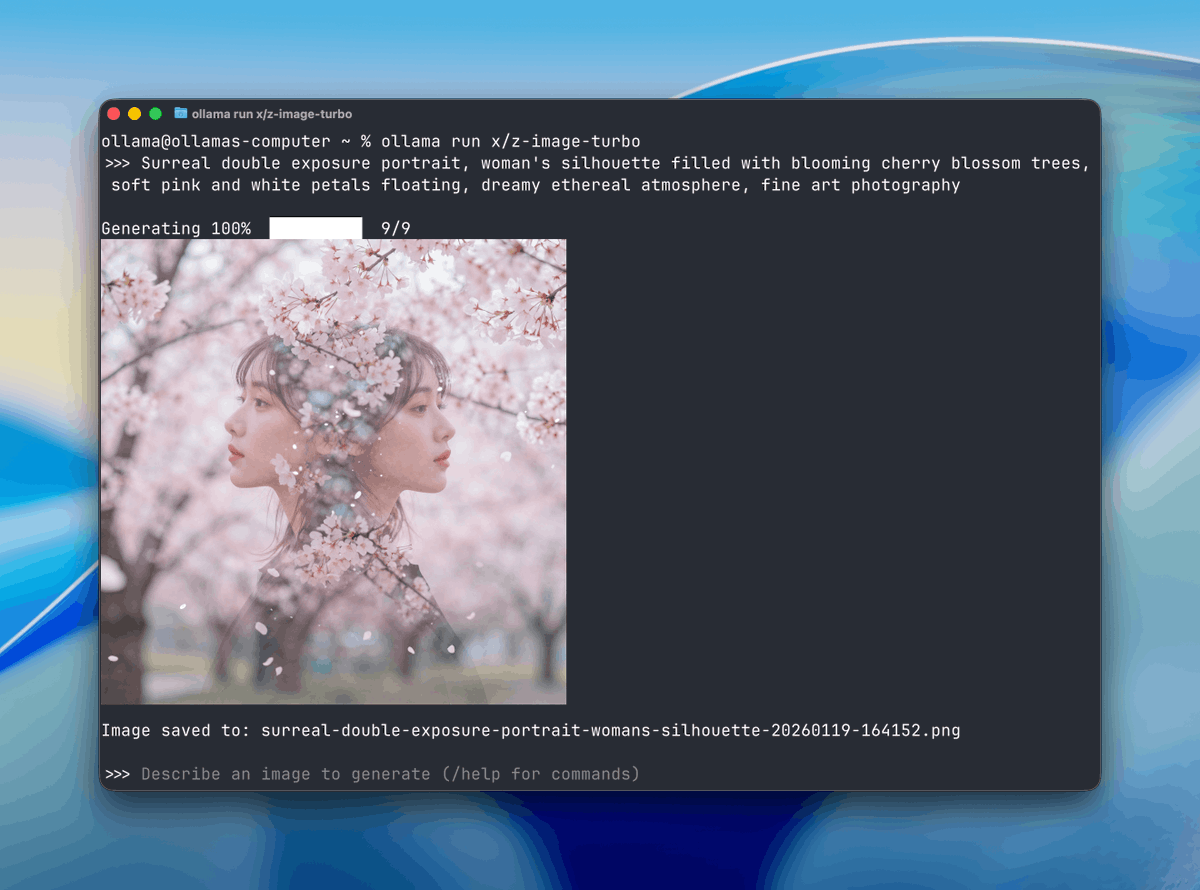
Ollama is here with image generation!
ollama run x/z-image-turbo
ollama run x/flux2-klein
In the latest release we've added experimental support for
@Ali_TongyiLab Z-image-turbo
@bfl_ml Flux.2 Klein!
(macOS with Windows and Linux coming soon)
See examples 👇👇👇

ALT Ollama loves you, and wants to make your life better with images!
50
229
1,295
93,006
21 Nov 2025
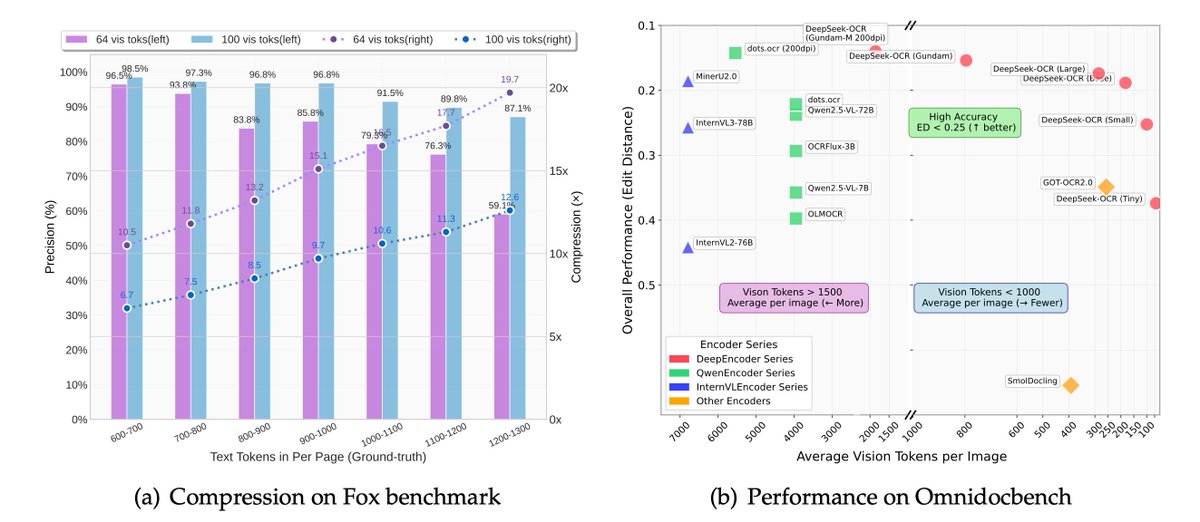
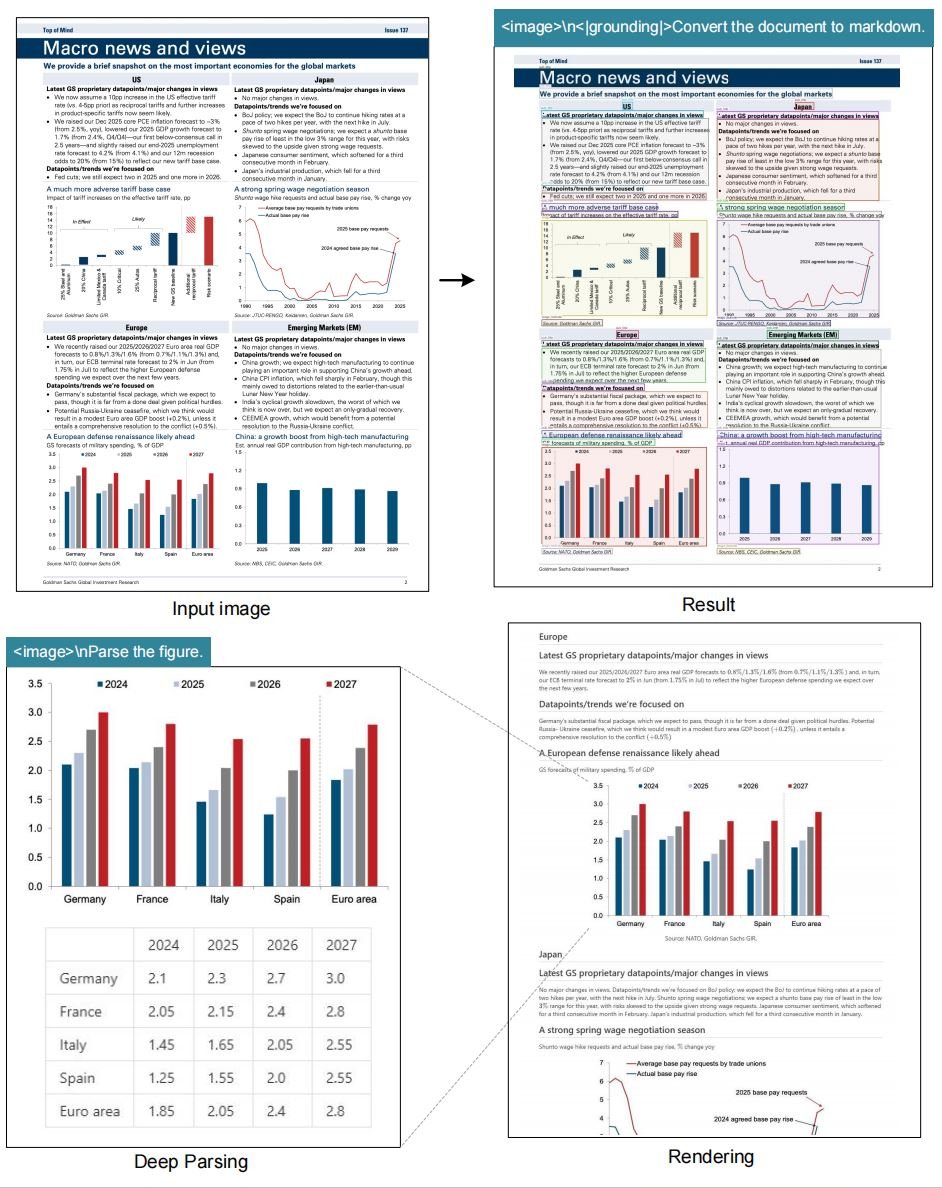
This one took a little while to get out, but we got it over the finish line! Just note that it's *not* like a normal vision model, and the grounding (i.e. the prompt you give it) is really important to get correct if you want good outputs.
Ollama v0.13 now supports DeepSeek-OCR!
ollama run deepseek-ocr
Try it with Ollama's CLI or directly use the model via Ollama's API!
👇👇👇
ALT Ollama now supports DeepSeek-OCR


2
1
3
744
21 Nov 2025
We also tried quantizing it, but we ran into problems getting good results, so we only released in Brainfloat16 weights, but the model itself is pretty small.
1
128
New open-weight LLM by Deep Cogito!
Locally (671B):
ollama run cogito-2.1
Ollama's Cloud:
ollama run cogito-2.1:671b-cloud
19 Nov 2025

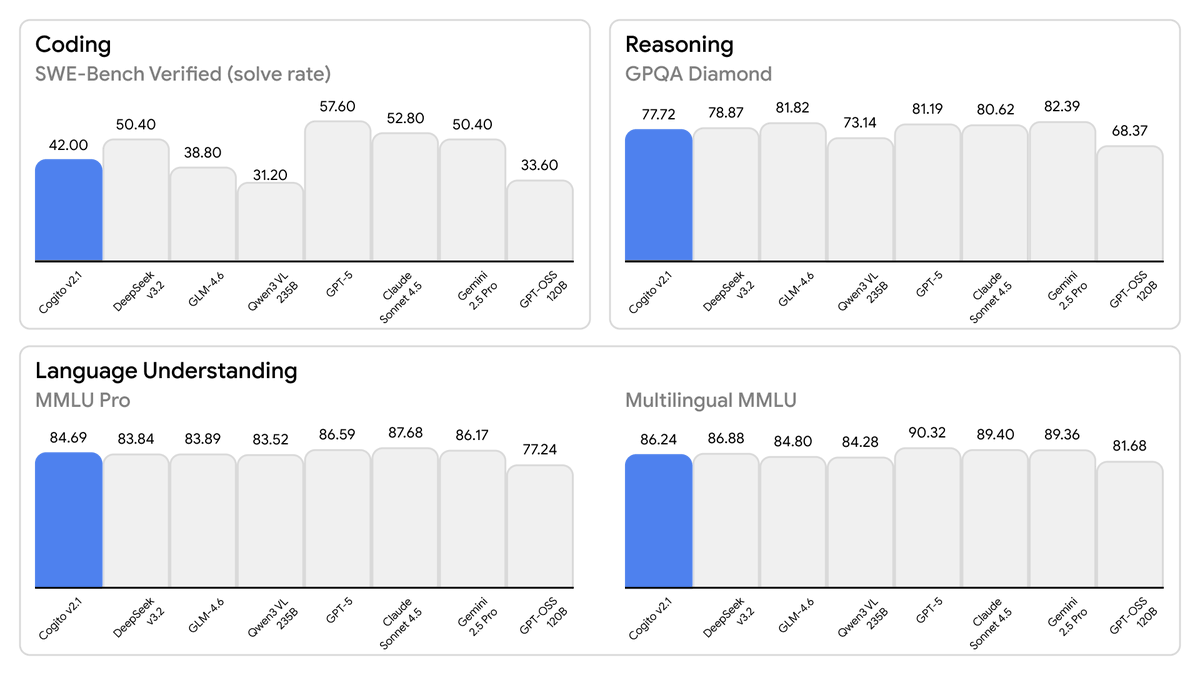
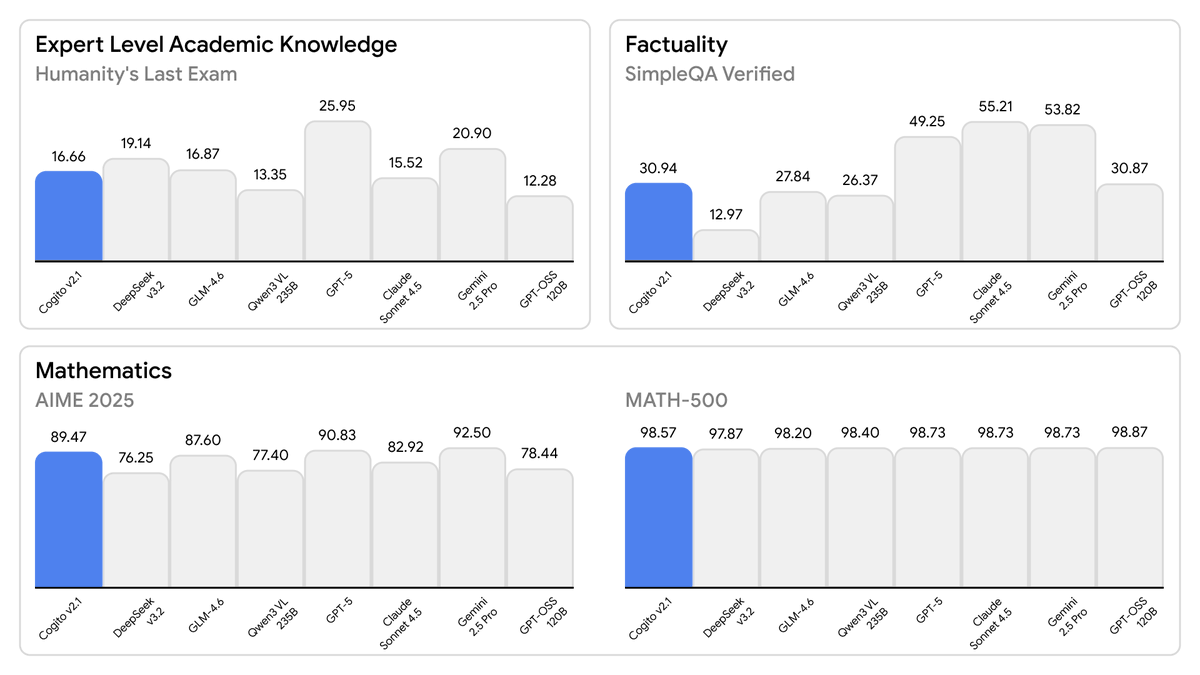
Today, we are releasing the best open-weight LLM by a US company: Cogito v2.1 671B.
On most industry benchmarks and our internal evals, the model performs competitively with frontier closed and open models, while being ahead of any US open model (such as the best versions of OpenAI’s GPT-OSS, Nvidia’s Nemotron and Meta’s Llama).
We also built an interface where you can try the model (it’s free and we don’t store any chats): chat.deepcogito.com
Additionally, you can download the model on @huggingface, or try it out on @openrouter, @togethercompute, @FireworksAI_HQ , @ollama cloud, @runpod, @baseten, or run it locally using @ollama or @UnslothAI.
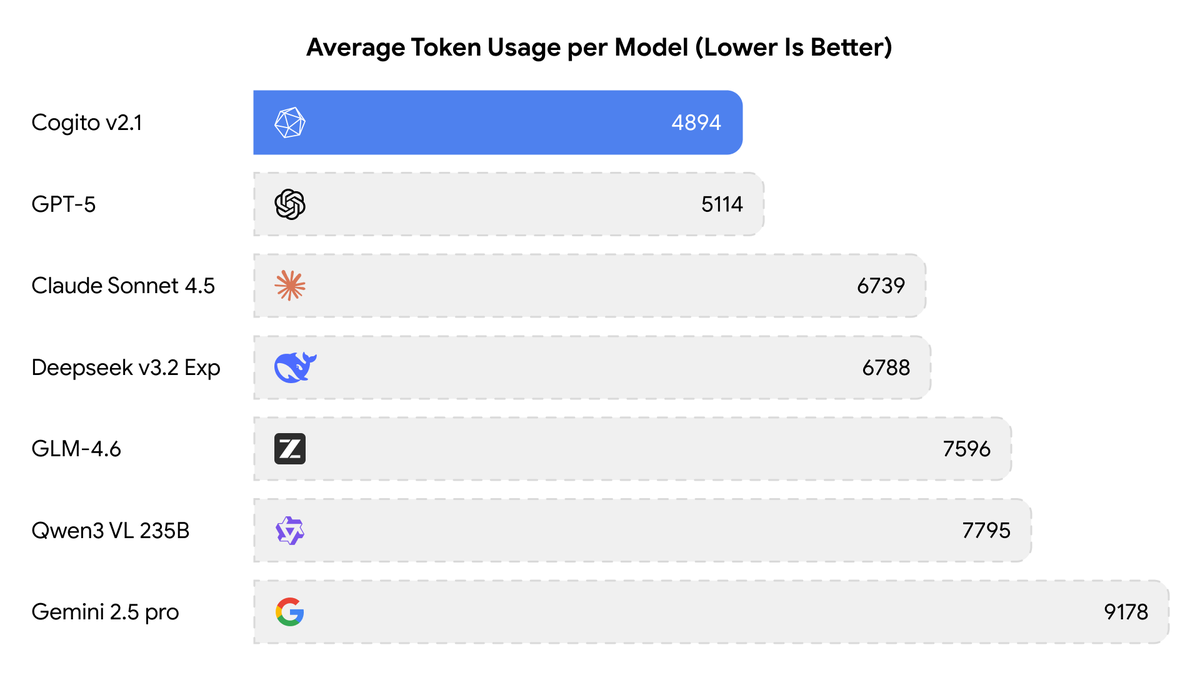
This model uses significantly fewer tokens amongst any similar capability models, because it has better reasoning capabilities. You will also notice improvements across instruction following, coding, longer queries, multi-turn and creativity.
📌 Model Weights: huggingface.co/collections/d…
📌Openrouter: openrouter.ai/deepcogito/cog…
📌 HF Blog: huggingface.co/blog/deepcogi…
Some notes on our approach design choices below 👇
5
30
178
32,312
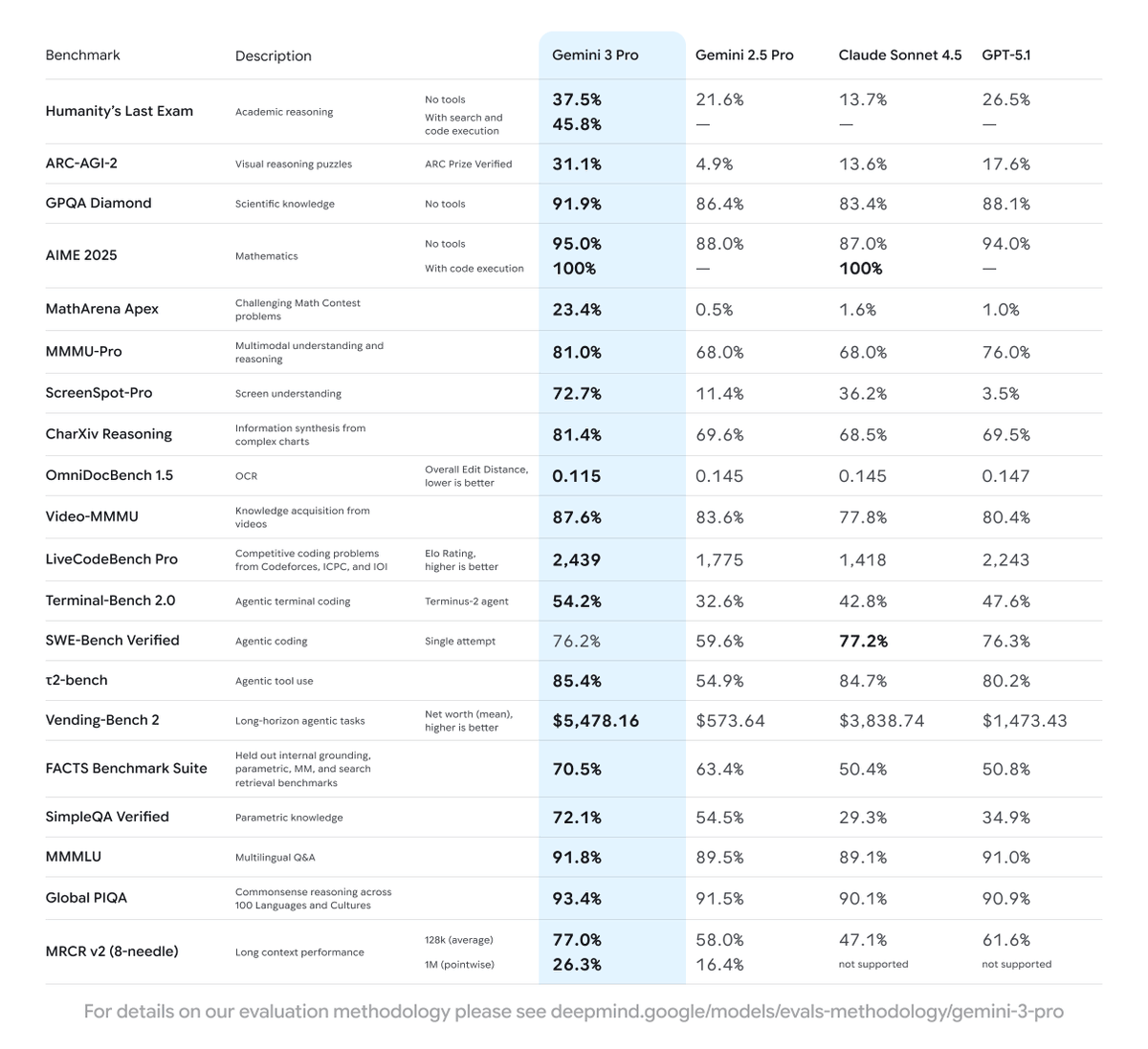
Gemini 3 pro now updated on free tier, pro tier and max tier!
ollama run gemini-3-pro-preview
Now back to more open source model launches 🤩
ollama run gemini-3-pro-preview
🧠 State-of-the-art reasoning
🖼️ Deep multimodal understanding
💻 Powerful vibe coding so you can go from prompt to app in one shot
⭐ Improved agentic capabilities, so it can get things done on your behalf, at your direction
Gemini 3 Pro is available on Ollama's Cloud Max plan. We are working on expanding availability across Ollama.
Learn more about Ollama's cloud 👇👇👇

ALT Ollama 🤝 Gemini 3 Pro
5
35
380
54,966
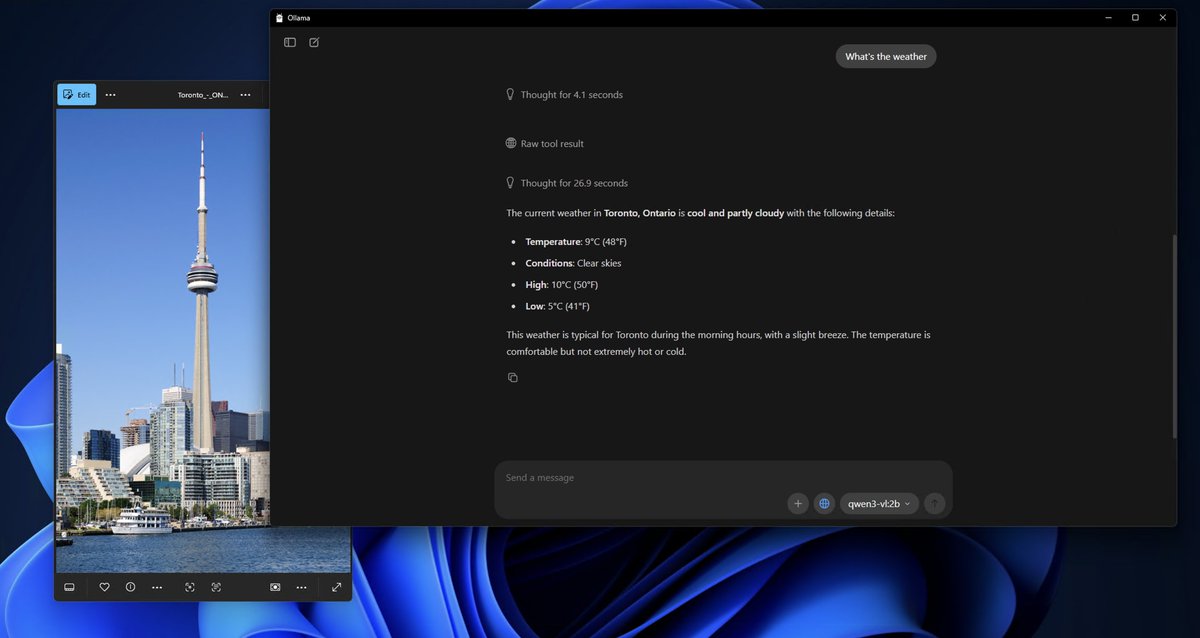
ollama run qwen3-vl
Ollama's engine now supports all the Qwen 3 VL models locally. 2B to 235B parameter sizes.
The smaller models work exceptionally well for their size.
The latest version of Ollama v0.12.7 is needed!
Give it a try! 👇👇👇



22
78
498
119,342
16 Oct 2025
Actually, seems like >40tok/s for full precision gpt-oss:120b. I'll keep testing.
2
192