
Building something new. Previously research @openai @GoogleDeepMind @scale_AI @Stanford
Joined August 2022
- Tweets 375
- Following 621
- Followers 8,675
- Likes 2,130
25 Photos and videos










Pinned Tweet

Apr 21
I’ve started a new company with @tkkong!
TK is a driving force behind a lot of Ramp’s success, building much of the core product, incubating the procurement platform, and leading Ramp Labs.
We’re a team of IMO and Physics Olympiad gold medalists, and we’re hiring the most talent-dense team.

I’ve started a new company with @philhchen!
Phil built frontier LLMs across research & engineering at OpenAI, DeepMind, and Scale.
I was shipping AI experiments at Ramp Labs.
We've been heads down building personalized AI coworkers for every business.
We’re growing our team of researchers, designers, and IMO gold medalists. Reach out if you're interested!

60
15
374
119,559
When I was considering joining Anthropic in 2023, their main pitch was “we have prioritized safety over commercialization and actually made decisions that hurt our business because they were the right moral choice.”
Everyone I met at the company was incredibly sincere about their mission alignment. I’m cynical and don’t believe that some people joining Anthropic today would hold this position, but I do think the early team really believed in this mission.
8
2
140
31,884
Jun 12
“Smart model review all pretraining data” seems like an attractive option until you realize that this costs exactly the cost of pretraining, or at least on the same order
If you try to be smart about it and ask a model what it thinks of each pretraining token, that’s basically distillation
Jun 12

An underrated part of this discussion is that
(a) there's huge leverage in improving data, and
(b) there's no way Anthropic could safeguard this
xAI could instruct Fable to look through EVERY row of pretraining data and fix any typos and errors. this probably the single highest-leverage activity for a lab playing catchup
and it's not possible for Anthropic to prevent this without completely kneecapping the model itself, because data quality work looks like any other kind of knowledge work ("check this text for errors", "rewrite this in a formal tone")
14
2,806
Jun 11
Fable is definitely a step forward in execution ability, but I still find myself providing a lot of architecture guidance.
Example: while building a Slack agent, Fable chose to stream back SSEs from the agent session to Slack, and I had to instruct it to give a tool to post to Slack instead.
6
707
Jun 10
Warriors or Knicks game as referral bonus: send over your most cracked eng friends and we’ll take you to a game next season if they join


2
19
7,110
Jun 9
Mythos / Fable launch reminds me of strawberry / o1 launch.
Hype mostly justified but clearly serving a controlled narrative
Cybersecurity / safety implications beyond what the existing safeguards were designed to handle
The feeling of it's so over for everyone else, and yet proof of existence is all it takes for the most resourceful among us
Mar 5

anthropic leaks of 2026 are the new openai leaks of 2023
1
2
39
7,165
Phil Chen retweeted

Jun 9
After a semester building internal tooling at @conviction, I’m excited to announce that I’m joining @tkkong and @philhchen this summer at Concept!
I first met TK through Shreyan Jain (cc @shreyanj98) when I was looking for designers to speak with last summer. He’s a clear thinker and I deeply enjoyed that conversation. I noticed Concept in the latest Embed batch and reached back out to join their small and mighty team.
I’m looking forward to wearing hats aplenty over the next twelve weeks! I’ll be posting updates and learnings as I go. 🚀

56
4
259
54,405
Jun 9
.@josephjojoe is a man of many talents. He's already made impact across product, GTM, and design (more to share about this soon). He's also gotten everyone in the office saying "revealed preference" and doing the 6-7 move.
Jun 9

After a semester building internal tooling at @conviction, I’m excited to announce that I’m joining @tkkong and @philhchen this summer at Concept!
I first met TK through Shreyan Jain (cc @shreyanj98) when I was looking for designers to speak with last summer. He’s a clear thinker and I deeply enjoyed that conversation. I noticed Concept in the latest Embed batch and reached back out to join their small and mighty team.
I’m looking forward to wearing hats aplenty over the next twelve weeks! I’ll be posting updates and learnings as I go. 🚀
7
1,660
Jun 4
2026 was about rapid expansion of AI budgets. 2027 will be about cost optimization.
My token run rate is ~$250k / yr now with 5.5 / 4.8 all on xhigh when I use API (thankfully I usually don't). With Mythos / GPT-next, this might look more like 1M / yr which feels irresponsible
1
23
5,257
Jun 2
is anyone building dynamic workflows with Claude managing Codex subagents? This would be the best of both worlds. Claude is much better at task decomposition and Codex is much better at executing well-defined specs.
May 30
Claude really cooked with dynamic workflows. Really impressed with how forward-thinking the team has consistently been in building the right abstractions for orchestrating more complex intelligence
8
18
6,391
May 30
Claude really cooked with dynamic workflows. Really impressed with how forward-thinking the team has consistently been in building the right abstractions for orchestrating more complex intelligence
5
20
8,674
May 30
Have only been able to use it from the Claude desktop app but being able to track live progress on subtasks from the DAG is cool
6
629
May 28
Had a great time sharing how we’re AI pilling our customers at @DecagonAI @a16z @Accel event
Reach out if you want to build the future of work with us or AI pill your own teams
May 28

Directionally accurate summary of the AI pilled talk we at @DecagonAI hosted with @a16z @Accel
In general:
1/ everyone has a different approach to AI pilling
2/ most people don't know what they're doing even if it seems they do
3/ just start and try everything as much and as fast as possible
@andrewqu @philhchen @realbbooi

2
2
26
4,106
May 26
Thought experiment: if @karpathy's efforts at Anthropic yield a Claude model that is capable of pretraining the next generation of Claude, then any company with sufficient GPU infrastructure could use Claude to pretrain their own Claude-clone.
Of course, Anthropic would then ban that company from using Claude. But then wouldn't any company with enough Claude spend be incentivized to use Claude to train their own Claude-clone eventually? What happens in 1-2 years when even open-weights models become good enough to run their own training?
16
44
10,431

We’re sharing our internal AI job board
Every company will have internal ops and engineers building AI agents
Discover roles from @Box, @tryramp, @DecagonAI, @baseten, @WeAreLegora, and 150 companies
And if you’re an AI lead driving internal transformation, join our leaders community below
internal-ai-jobs.concept.sit…
19
10
272
23,137
Apr 29
Incredible work from @dwarkesh_sp and @reinerpope. Must-watch for anyone who wants to understand modern AI systems
Apr 29

Did a very different format with @reinerpope – a blackboard lecture where he walks through how frontier LLMs are trained and served.
It's shocking how much you can deduce about what the labs are doing from a handful of equations, public API prices, and some chalk.
It’s a bit technical, but I encourage you to hang in there - it’s really worth it.
There are less than a handful of people who understand the full stack of AI, from chip design to model architecture, as well as Reiner. It was a real delight to learn from him.
Recommend watching this one on YouTube so you can see the chalkboard.
0:00:00 – How batch size affects token cost and speed
0:31:59 – How MoE models are laid out across GPU racks
0:47:02 – How pipeline parallelism spreads model layers across racks
1:03:27 – Why Ilya said, “As we now know, pipelining is not wise.”
1:18:49 – Because of RL, models may be 100x over-trained beyond Chinchilla-optimal
1:32:52 – Deducing long context memory costs from API pricing
2:03:52 – Convergent evolution between neural nets and cryptography
3
1
52
11,711
Phil Chen retweeted

Apr 28
I left Google DeepMind, moved from SF to NYC, all within 2 weeks to join @quadrillion_ai — to build the future of automated research intelligence with the highest slope founder and most talent dense team.
I grew up in Silicon Valley — the old Facebook office was my second home. I’d hang out there after school, drawing with my crayons while looking around at the sea of computers with lines of code. Since a young age, I felt empowered to have an array of interests beyond tech: piano, ballet, figure skating, art. The valley embraced diversity of thought, and that’s what inspired me to stay for Stanford and my career thus far.
But today, SF is one big hive-mind.
So, I moved to NYC, away from family and friends to build a company that doesn’t need to rely on a bubble to survive.
I’m meeting customers day after day in all kinds of verticals, connecting with them in different ways and seeing our product bring real value. Here, I’m able to live in diversity of thought.
I’m excited to build the future of research in the city of opportunity. Let’s chat if this excites you.

95
18
342
218,057
Apr 26
working at a startup during my junior year with @tachim was one of my best career decisions. join us (link below)
I’m hiring 2 eng interns for the summer in SF.
No starter tasks. You’ll ship real product with a talent-dense team of OpenAI researchers, early Ramp product leads, and Olympiad medalists.
If you’re looking for a high-growth summer, apply below.

3
1
39
6,396
Apr 26
5
790
Apr 23
🧵 on quantitative internal evals
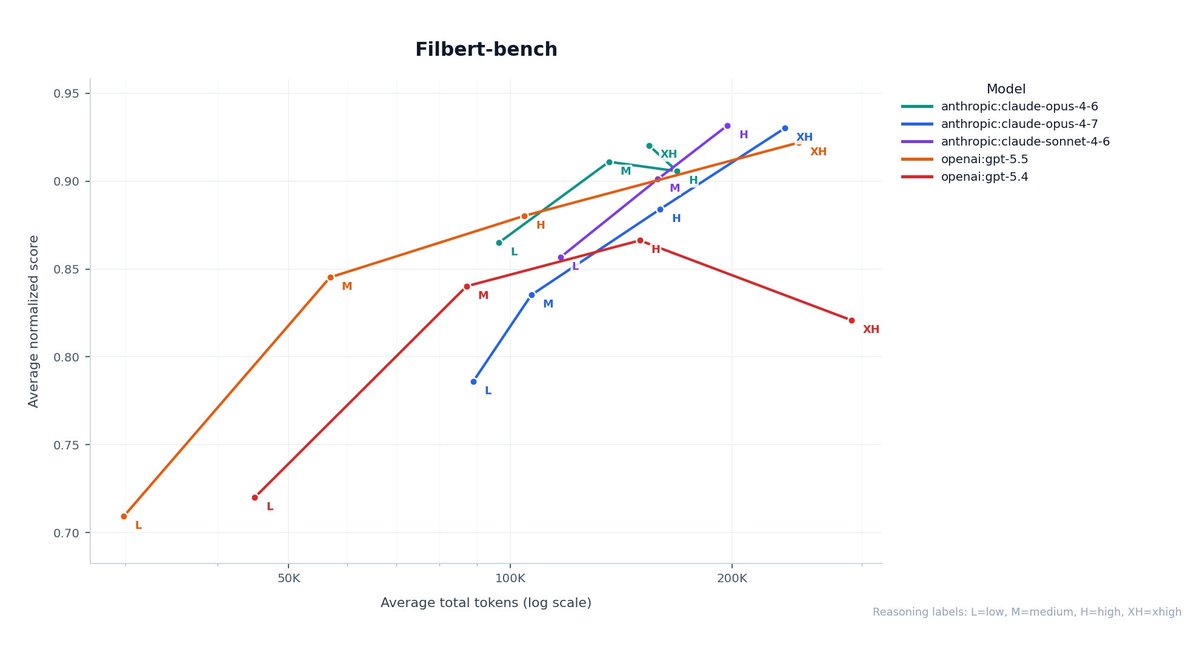
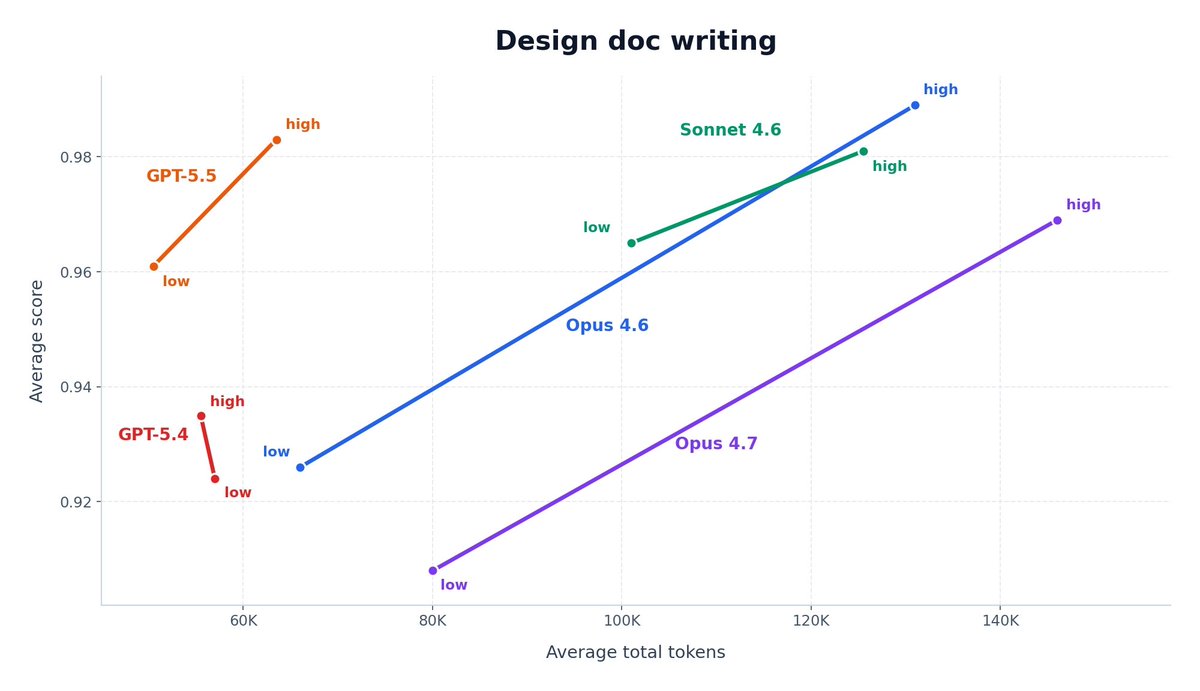
1/4: GPT 5.5 excels at writing design docs efficiently. I turned some design docs I wrote recently into an eval. The prompt is a list of functional requirements to achieve within a codebase, and the design doc is graded based on full, partial, or missing adherence to each functional requirement.
Apr 23
I’ve used GPT 5.5 for the past few weeks as an early tester, and it’s the biggest upgrade I’ve felt since o3.
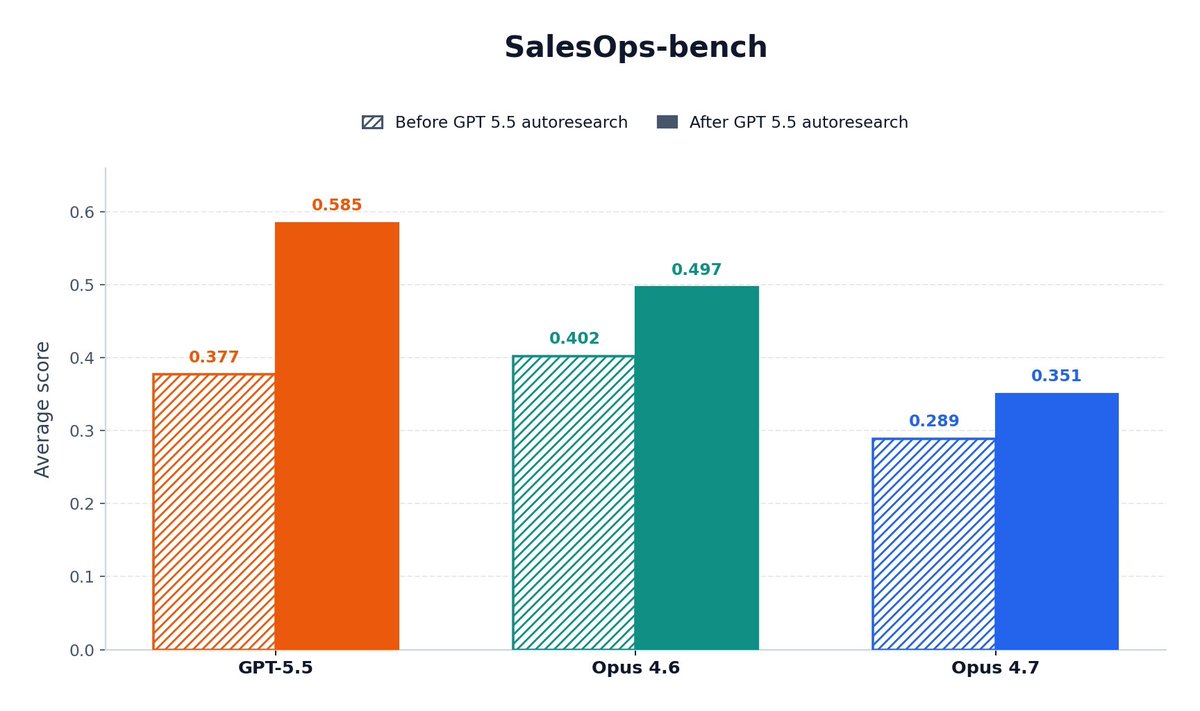
GPT 5.5 is really smart for autoresearch-type jobs. It suggests tasteful research directions, implements the directions correctly, and works reliably for hours at a time. I used it to optimize our harness against an internal dataset, and eval results doubled.
I’ve been fighting some race conditions for the past few weeks. GPT 5.4, Opus 4.6, and Opus 4.7 all spun in circles for hours, playing whack-a-mole with issues while creating new ones. GPT 5.5 found the architectural issue, confirmed its approach with me, and then implemented the fix elegantly.
I use it as my daily driver for agentic coding because it actually finishes what it says it will do. When I tell it to fix a flaky test until it runs 20 times consecutively without failure, GPT 5.5 actually works on it for over 24 hours and then succeeds. Opus has never done so faithfully.
2
1
33
4,655
Apr 23
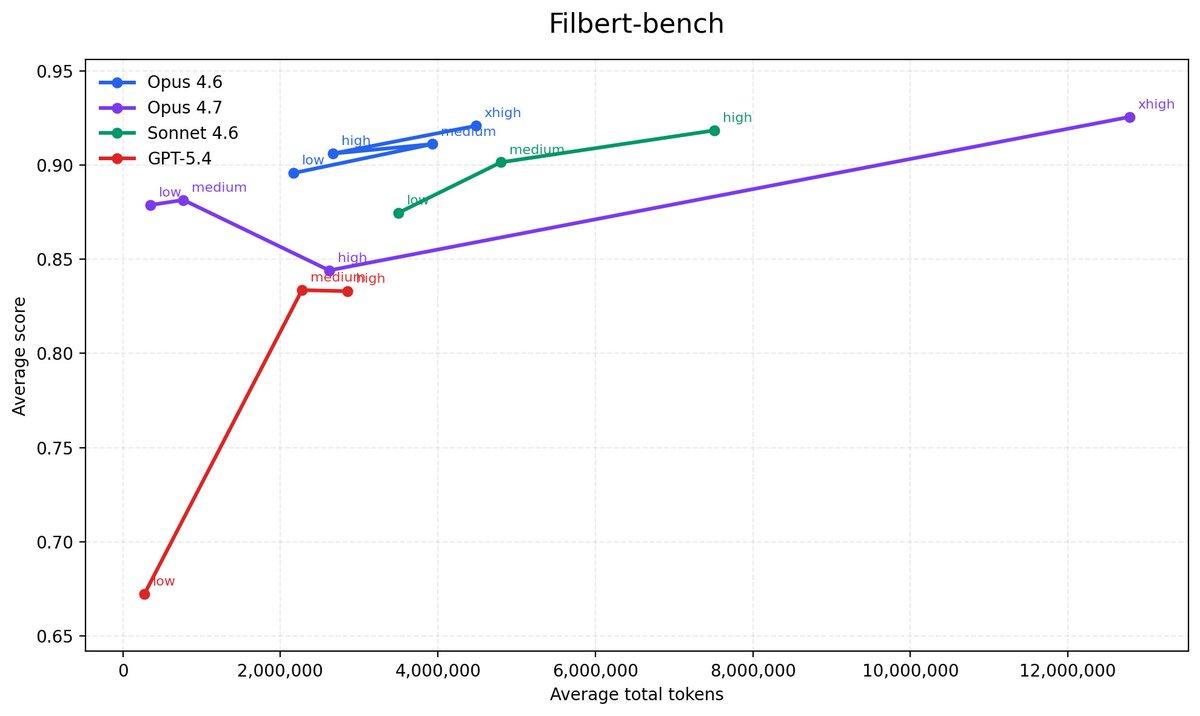
3/4: The model is not perfect and lags behind Claude on token efficiency on internal coding benchmarks.
1
11
990
Apr 23
4/4: However, I use it as my daily driver for agentic coding because it actually finishes what it says it will do. When I tell it to fix a flaky test until it runs 20 times consecutively without failure, GPT 5.5 actually works on it for over 24 hours and then succeeds. Opus has never done so faithfully.
10
797