
✨ AI Product Engineer of backend.ai / 👨🍳 Creator of AI:DOL and nextjs.org / ♨️ Saunner (サウナー) for Totonou (ととのう)
Joined July 2009
- Tweets 14,640
- Following 288
- Followers 917
- Likes 14,320
1,521 Photos and videos










Jun 13
I've have cleanup my skills today to prepare for the next steps but I couldn't get using Fable anymore. 💩
34
Jimmy Moon (현경, 炫炅) retweeted

Jun 12
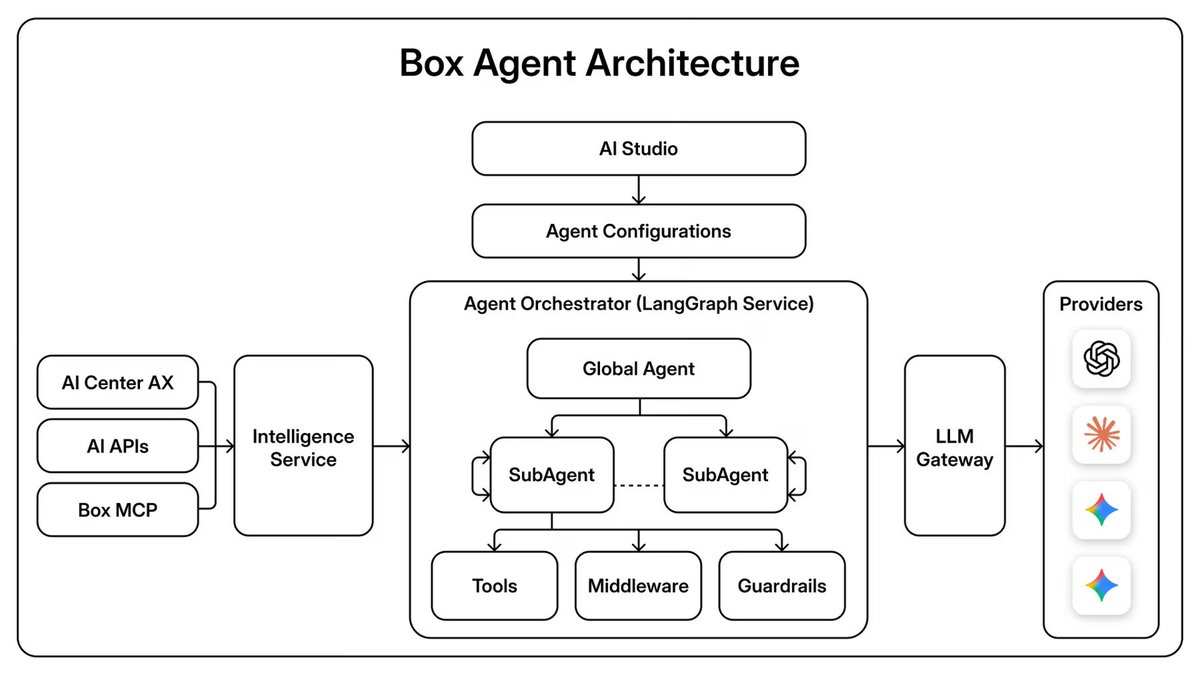
.@Box Agent is built on Deep Agents.
✅ Cross-library search
✅ Multi-doc synthesis
✅ Structured reports
✅ All within Box's existing security and permissions model
6
18
89
7,105
Jimmy Moon (현경, 炫炅) retweeted

Jun 12
Meet Kimi-K2.7-Code 👀
Here’s what developers should know to fully unlock K2.7-Code potential:

Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


76
175
2,948
216,322
Jun 12
AI라는 ‘곱하기’를 만났을 때, 진짜 폭발력을 만드는 건 당신의 기본기라는 ‘모수’입니다. AI 가 발전하는 만큼 우리도 우리 스스로를 개발해야하는 것을 놓치면 안 됩니다. 저 스스로에게도 하는 말이기도 합니다.
3
9
509
Jimmy Moon (현경, 炫炅) retweeted

Jun 12
AI SDK now supports agent harnesses like Claude Code, Codex, and Pi with sandboxed sessions and AI SDK-compatible streams:
𝚌𝚘𝚗𝚜𝚝 𝚊𝚐𝚎𝚗𝚝 = 𝚗𝚎𝚠 𝙷𝚊𝚛𝚗𝚎𝚜𝚜𝙰𝚐𝚎𝚗𝚝({
𝚑𝚊𝚛𝚗𝚎𝚜𝚜: 𝚌𝚕𝚊𝚞𝚍𝚎𝙲𝚘𝚍𝚎,
𝚜𝚊𝚗𝚍𝚋𝚘𝚡: 𝚌𝚛𝚎𝚊𝚝𝚎𝚅𝚎𝚛𝚌𝚎𝚕𝚂𝚊𝚗𝚍𝚋𝚘𝚡(),
});
Available in canary: 𝚗𝚙𝚖 𝚒 𝚊𝚒@𝚌𝚊𝚗𝚊𝚛𝚢. We welcome your feedback as we bring agent harness portability to the ecosystem, with excellent DX.
vercel.com/changelog/program…
44
66
875
351,352
Jun 11
하네스 엔지니어링에서 명시적인 스킬 호출이 에이전트를 실행시키는 방법이였다면 이제는 그냥 자연어로 일을 맡기고 우리는 더 많고 복잡한 일을 할 수 있게 되었읍니다.
에이전트 엔지니어링이 이제 단단해진 하네스를 기반이 확립이 되고 점차 발전해서 이제는 에이전트가 미션을 주면 충분히 일을 해결할 수 있게 된 것이라고 보면 됩니다. 프롬프트-컨텍스트-하네스 라고 이름 붙여진 것과 전혀 다른 것이 아니라 우리가 에이전트와 일하면서 점점 더 우리의 다루는 기술이 익숙해지고 정립이 되면서 생기는 자연스러운 변화입니다.
만약 처음 시작이라면 프롬프트 엔지니어링 부터 조금씩 익숙해지셔야 합니다. 점점더 사용하는 방법은 추상화 되고 쉬워지겠지만 아래의 기술을 습득하고 싶다면 그 밑에 깔여 있는 기본 동작의 원리를 이해하는 것은 언제나 중요 했습니다.
Jun 10

루프 엔지니어링 - 에이전트를 프롬프트하는 시스템을 설계하기
- 코딩 에이전트에게 매 턴마다 직접 프롬프트하던 방식을 끝내고, 에이전트를 대신 프롬프트하는 시스템을 설계하는 작업 방식으로의 전환
- 루프는 목적을 정의하면 AI가 완료될 때까지 반복하는 재귀적…
news.hada.io/topic?id=30336
1
6
31
6,523
Jimmy Moon (현경, 炫炅) retweeted

Jun 3
A sneak peak of our initial A2UI support 👇
3
6
74
12,835
Jimmy Moon (현경, 炫炅) retweeted

Jun 11
We've just added two new Claude Managed Agents features:
1. Scheduled deployments - run tasks on a schedule
2. Environment variables - expose vault credentials for CLIs as environment variables

139
267
3,689
449,518
Jun 11
I attempted to control a page managed by WebMCP using Antigravity with a 'Get Order' prompt. Then, Antigravity changed the page URL to the demo site. what a hack
67
Jimmy Moon (현경, 炫炅) retweeted

Jun 11
Part of the OpenClaw hardening work is reducing surface risk; for some media conversion we had to shell out to ffmpeg.
In the next release that can now be done via wasm, with similar performance for our use cases.
github.com/openclaw/ffmpeg-w…
26
25
486
74,285
Jimmy Moon (현경, 炫炅) retweeted

The WebMCP origin trial is now available in Chrome 149 → goo.gle/4x97wMK
Sign up to integrate experimental features for live testing and help shape future iterations of the API. Build structured tools so agents can complete tasks accurately without guessing your UI.
3
24
125
15,837

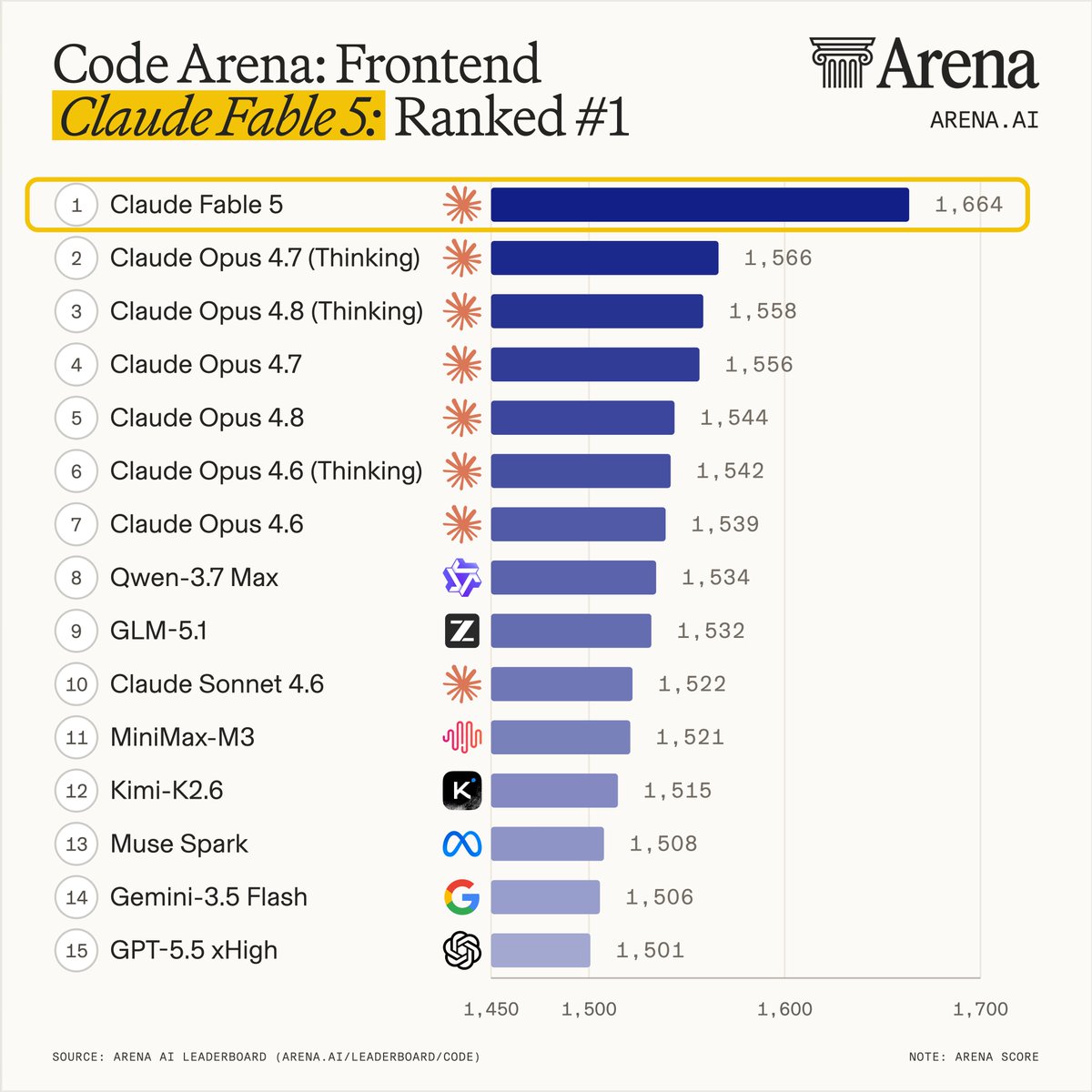
Claude Fable 5 ranks #1 in Code Arena: Frontend, leading by a wide margin over Opus-4.8.
Highlights:
- #1 in every sub leaderboard: HTML, React
- #1 in every sub category: Brand & Marketing, Reference-Based Design, Data & Analytics, Consumer Product, Gaming, Simulations, and Content Creation Tools.
Huge congrats to @AnthropicAI for this milestone! The thread breaks down how Claude Fable 5 ranks across single-modality arenas.

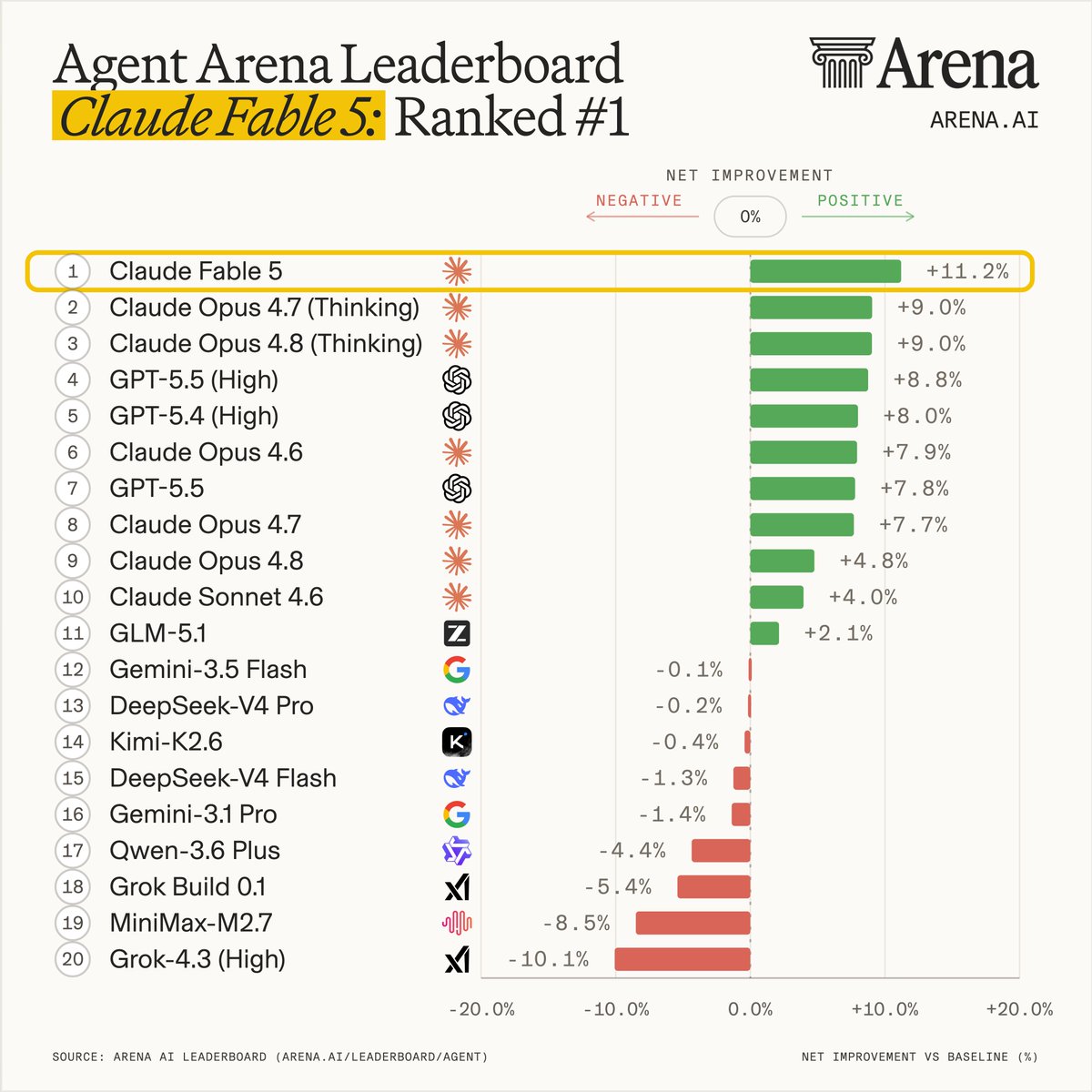
Exciting news: Claude Fable 5 ranks #1 on the new Agent Arena leaderboard!
Fable 5 leads by the widest margin ever over Opus-4.8 and GPT-5.5 on two key signals: confirmed task success rate and praise vs. complaint, despite weaker steerability. If Fable can do something, it will do it very well. If it can't/doesn't want to do something, it may be hard to steer the model towards the goal.
In Agent Arena, we measure models on millions of real-world, long-horizon agentic tasks. Models get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
We use the causal tracing methodology to measure a model's net improvement which indicates how much it improves outcomes relative to the average model.
Huge congrats to @AnthropicAI for the incredible milestone! Below we break down how Claude Fable 5 (based on Mythos) scored across 5 signals, drawn from tasks submitted by a global community of users.
136
243
2,676
411,127
Jun 11
Coding agents are getting smarter every month, but they still don't know exactly what to build. Therefore, to prepare for this situation, we must develop our own tastes. If we fail to do so, we are just coding workers.
34
