
Building AI for the real world. token maxxing. prev: Doohickey.ai, martech, enterprise consulting, @Techstars
Joined January 2009
- Tweets 1,808
- Following 889
- Followers 291
- Likes 1,402
105 Photos and videos











Winkle retweeted

Jun 12
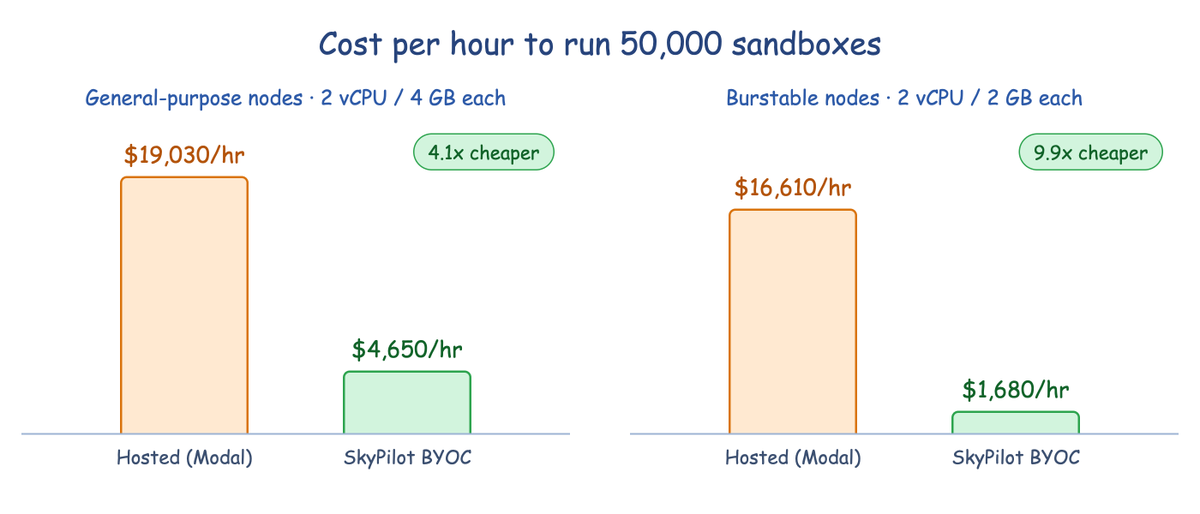
Sandboxes are all the rage (Modal, E2B, AWS, ..). Most AI teams pay a >4x markup to run sandboxes on someone else's machines.
Introducing SkyPilot Sandboxes — Run BYOC sandboxes on your own clusters.
• 50,000 sandboxes on a single cluster
• Sub-second launches with warm pools
• Great for RL rollout (keep sandbox clusters close to GPUs)
Benchmark shows @skypilot_org Sandboxes are 4-10x cheaper than Modal at lower latency. Full results in blog.
19
35
544
60,879
Winkle retweeted

Jun 11
the work that used to require $100k security reports and formal verification can now be done for $200/month with claude fable 5 and certora prover (free btw) and kani. 2026 is so fucking lit.
3
1
12
5,275
Winkle retweeted

Jun 11
I've been telling people for 25 years that Jane Street is not interested in formal methods.
No more!
And we're actively hiring to form a new formal methods team!
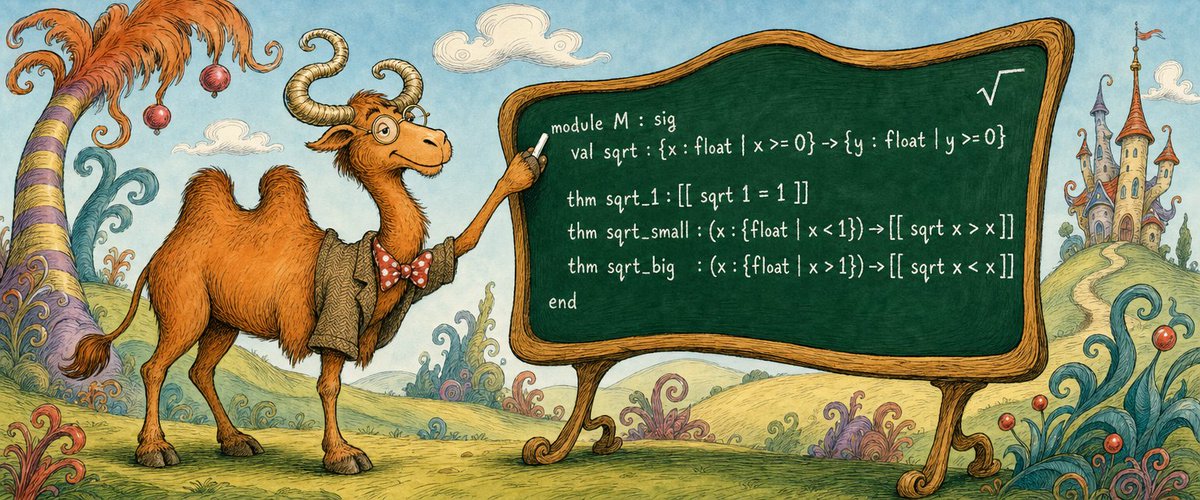
29
72
1,067
120,043

Winkle retweeted

Jun 11
Great software always took shape in conversation, not the commit. With agents, the conversation that generates the code is becoming the true source of our software. And Git can't keep up.
So we built something that can. Meet DeltaDB: zed.dev/blog/introducing-del…
64
149
1,912
242,312

Winkle retweeted

Jun 10
fable 5 did a 5k/-5k refactor on our oldest messiest react code, detangling a lot of stuff.
Overall I'm very pleased and will be doing more of this, and in more parts of the stack.
The diff appears to have no regressions, but still exploring w/ a mix of manual testing and browser automation.
I like about 80% of the decisions fable made (you can see in the prompt chain below where i added more steering). Some of the decisions I think made the code worse and more complex:
- introducing react-context - hides complexity but actually makes the program harder to reason about
- did some clever hacks like ...spreads to reduce the total line count without actually reducing/simplifying any tramp data
It did not have the taste to do some things until i explicitly steered it.
- reduce prop drilling patterns
- remove effects
Aside: i'm noticing a trend where folks like me that lean quite backend-heavy, are finally having to learn a LOT about what good frontend code means (thanks @0xblacklight ). My only only guess is that this is due to the fact that its easier to vibe code frontend because you can see it. That means code quality deteriorates much faster, and regressions creep into your poorly-factored codebase. React is DECEPTIVELY complex - easy to work with, easy to get started, but the actual mental model you need to have to do it well is INCREDIBLY deep, and most people are just beginning this journey.
Prompts - this was during a ~2hr session where I queued the following messages in order, each line is a separate queued message, usually added more every ~20 minutes as i skimmed the diffs, keeping a queue of ~5-7 messages until the end.
refactor the $sessionId page / root component until its clean and under 500 lines
/compact
refactor the $taskId page / root component until its clean and under 500 lines
/compact
make it cleaner
/compact
make it cleaner
/compact
/no-use-effect (our skill to read the react docs and remove unnecessary use effects)
/compact
/no-use-effect
/compact
Remove some prop drilling. There's too much prop drilling. Why is all the state being threaded down from the top? Most of these things can own their own state workflow. It is absolutely fine to refactor the UI components to use children or to pull the UI components out of packages/ui and remove the pure wired split. More important to limit the amount of prop drilling. Let's see what we can do there on the pages we've touched so far and if you need to move storybook stories over, you can do that too.
/compact
Remove some prop drilling. There's too much prop drilling. Why is all the state being threaded down from the top? Most of these things can own their own state workflow. It is absolutely fine to refactor the UI components to use children or to pull the UI components out of packages/ui and remove the pure wired split. More important to limit the amount of prop drilling. Let's see what we can do there on the pages we've touched so far and if you need to move storybook stories over, you can do that too.
remove more prop drilling we have hooks for all this shit, push state down, use stores, make the code good
remove more prop drilling we have hooks for all this shit, push state down, use liveQueries and tanstack db, use stores, make the code good
remove more prop drilling we have hooks for all this shit, push state down, use liveQueries and tanstack db, use stores, make the code good
please create a giant html canvas with collapsible sub nodes that walks through this refactor step by step in a top-down hierarchical manner, it is to be optimized for human consumption
23
6
181
21,784
Winkle retweeted

Jun 10
the future of all work is this.
You must define:
- a goal
- the criteria that define it
- the verifier that makes sure it is achieved
- the sensors that inform the verifier
- the actuators that affect the sensors
- The envelope that contains the sensors and actuators
Jun 10

The codex "goal" feature is a really good way to spend dozens of hours optimizing some total bullshit btw. If your final criteria is it all vague it will specification game and make masturbatory "evidence" and "verifiers" and "gates" and "smoke tests". must be hell internally
40
42
806
74,796
Winkle retweeted

Jun 9
One of my personal favorite features announced at WWDC will I suspect be a sleeper hit: container machines, allowing your Mac to run a lightweight, persistent Linux environment with your home directory and repos automatically mounted: github.com/apple/container/b…
228
815
9,696
728,019

I spent a lot of the weekend doing recursive dynamic workflows
which—while technically blocked by the Claude Code dynamic workflow JS environment in the package itself—can still be accomplished _in effect_ using a technique called trampolining, which allows an outer loop to effectively manage inner recursion out of something like an event queue
incidentally, trampolining is how we always got Claude’s agent-subagent architecture (max depth n=1) to implement deeply nested OpenProse blocks
I picked this technique up from Spring, would wire together Java calls. better yet this foundation plays especially nicely with middleware (useful in LLM systems!)
anyway, dynamic workflows present an even further fertile ground for the trampoline, as you can basically build an entire event loop (in JavaScript!) and manage the inner agent calls as a virtual recursive stack even though the environment permits just a max depth of 1
this is fraught with challenges around shared state, but nothing that hasn’t already been solved
5
3
89
4,724
Winkle retweeted

Jun 8
recommended reading.
github.com/openclaw/clawswee…
github.com/openclaw/crabflee…
Jun 8

You can look at clawsweeper and crabfleet where I explore these ideas, it’s all oss.
6
16
507
88,194

Jun 7
Glad to see our customers and friends recognized for their hard work
Jun 5

Here's a gift link to a piece about Columbus Ohio becoming a magnet for high tech companies... nytimes.com/2026/06/05/busin…
9
Winkle retweeted

Jun 4
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
1,771
4,662
28,648
18,492,087
Winkle retweeted

Jun 1
A year ago at GTC, Jensen brought out a DGX Spark in one hand and a MacBook in the other.
Yesterday, at GTC Taipei, Jensen brought out NVIDIA's new RTX Spark laptop in both hands.
This is the start of a new era of personal computing - the personal AI era.
In the new era, there are two competing platforms:
- @apple with macOS / MLX
- @nvidia with Windows / CUDA
Everyone will have an always-on personal agent that runs locally, constantly looking out for you, working for you proactively, monitoring the internet and talking to other agents. This will be a personal AI agent you own, that's private, that's aligned with you (not OpenAI or Anthropic). @karpathy calls it personal computing v2.
Let's set the scene for the new era of personal computing by diving into the one thing that will matter the most - the hardware.
The best hardware for local AI isn't what's running in a data center. It's a radically different problem. Here's a breakdown of the 3 most important things:
1. Memory.
LLMs are big. To run a model locally, you need to fit the entire model into memory. Apple (with Apple Silicon) and NVIDIA (with DGX Spark RTX Spark) have both moved towards unified memory, which puts all the memory on one chip - leveraging cheaper LPDDR5X memory - useful for making more memory accessible to the GPU. The alternative competing architecture is a disaggregated CPU/GPU architecture - which is what the DGX Station uses. It has a large pool of slow LPDDR5X CPU memory (496GB @ 396GB/s), and a small pool of high-speed HBM3e GPU memory (252GB @ 7.1TB/s). It has a high bandwidth link (900GB/s) between the CPU memory and GPU memory, enabling fast disaggregated inference e.g. Attention on GPU, FFN on CPU. This enables running really large models like Kimi K2.6 (1T parameters) by offloading experts from CPU memory to GPU memory as they are needed. You could imagine something like this in a smaller form factor.
Hardware today:
- Apple M5 Max MacBook Pro: 128GB unified memory.
- NVIDIA DGX Spark / RTX Spark: 128GB unified memory.
2. Memory bandwidth.
In a data center, multiple user's requests can be batched together, which amortizes the cost of moving model weights into memory across many requests, pushing up arithmetic intensity to compute bound territory - meaning FLOPS matters a lot. Locally, everything runs at low batch size, which is low arithmetic intensity, i.e. memory bound - so FLOPS don't matter. What matters memory bandwidth. High memory bandwidth -> fast TPS. Low memory bandwidth -> slow TPS.
Hardware today:
- Apple M5 Max MacBook Pro: 617GB/s memory bandwidth.
- NVIDIA DGX Spark: 273GB/s memory bandwidth.
- NVIDIA RTX Spark: TBC.
3. Power.
In a data center, we talk about MegaWatts. Locally, we talk about Watts. Laptops have limited battery life. The best laptop batteries have a capacity of ~100Wh. LLM inference on a MacBook Pro consumes ~140W, meaning battery life with a persistent personal agent is less than an hour. This is unusable. The game will become how long can you run a useful agent on a laptop battery. Apple and NVIDIA will compete on how long an agent can run on battery - this will become the new battery life metric. This could be where an NPU or NPU/GPU hybrid really shines. Apple ANE has about 10x better power efficiency than the GPU on Apple Silicon (but has ~4-5x less memory bandwidth, with about the same FLOPS as the GPU). There will be an entire design space of how to build energy efficient agents - this will involve co-optimizing the harness, models, inference engines together.
Hardware today:
- Apple M5 Max MacBook Pro: Consumes 140W, battery capacity ~100Wh
- NVIDIA DGX Spark: Rated for 240W, consumes 140W. No battery (direct PSU).
- NVIDIA RTX Spark: TBC.
The hardware battle will be fierce, and I expect a move towards co-design, i.e. hardware designed *with* personal agent workloads. On top of this, models are improving, we're getting more intelligence per bit/watt, and open-source harnesses like @NousResearch Hermes / OpenClaw are improving rapidly. Within the next 2 years, we'll inevitably have unmetered, private Opus-4.8 / GPT-5.5 level intelligence running locally on a future version of a MacBook or RTX Spark. I like this future a lot better than the one where OpenAI / Anthropic control the intelligence layer of the internet and can rent-seek on intelligence.
Beyond this, NVIDIA is ahead on general AI ecosystem, i.e. the CUDA moat. Apple is ahead on local AI ecosystem, i.e. models quantized/rightsized for MacBooks, native macOS apps, and ease of setup. We'll see how this might change as the new RTX Spark also brings full native CUDA to Windows-on-Arm laptops for the first time, potentially closing the gap.
There are many other factors I haven't mentioned here, but I believe I've covered the timeless, most important things for the new era of personal computing.


45
56
519
108,297
> What do you use subagents for?
many things, but my favorite:
the good old fan-out-fan-in
and I think there is more to this than "you can parallelize token spraying" (which... is fun, but... careful)
rather, the more important fan-out pattern is one in which each branch (subagent) accumulates experience, and then the fan-in synthesizes this experience into condensed learnings
what do I mean by experience?
it's conventional wisdom by now that the models do better when they have back-pressure to spew their tokens against
the thinking goes: if you're using agents to one-shot something, chances are it may be wrong on the first try. but if you give them some back-pressure--say, tests that they can run against the real world and whose results they can observe--their outputs converge on something more accurate
and it's not just parallelizing unit tests... any experiential "theory meets reality" observation of the world rolls up into this category. the one that emerges most often in my own usage is parallel research and synthesis
so it's not only interesting to parallelize work to just generate more tokens, it's interesting to parallelize work because you can accumulate experience faster
the fan-out-fan-in is an efficient empirical learning pattern
imagine splitting yourself to parallelize your lived experience into a sort of multiverse reality all of which you remember after your shards re-converge with learnings in tow

May 31

What do you use subagents for?
11
11
371
55,423
Winkle retweeted
Jun 1
Anthropic has confidentially submitted a draft S-1 registration statement to the Securities and Exchange Commission.
Pending completion of SEC review, this gives us the option to pursue an initial public offering.
Read more: anthropic.com/news/confident…
983
2,618
21,766
19,812,264
if you've been using OpenProse, you now have a bunch of dynamic workflows saved as code that lean on best practice classical engineering principles to build composable scalable dynamic workflows
and all your programs got better and faster and cheaper for free
model: opus-4.8
harness: claude code /workflow
is rapidly approaching Prose Completeness

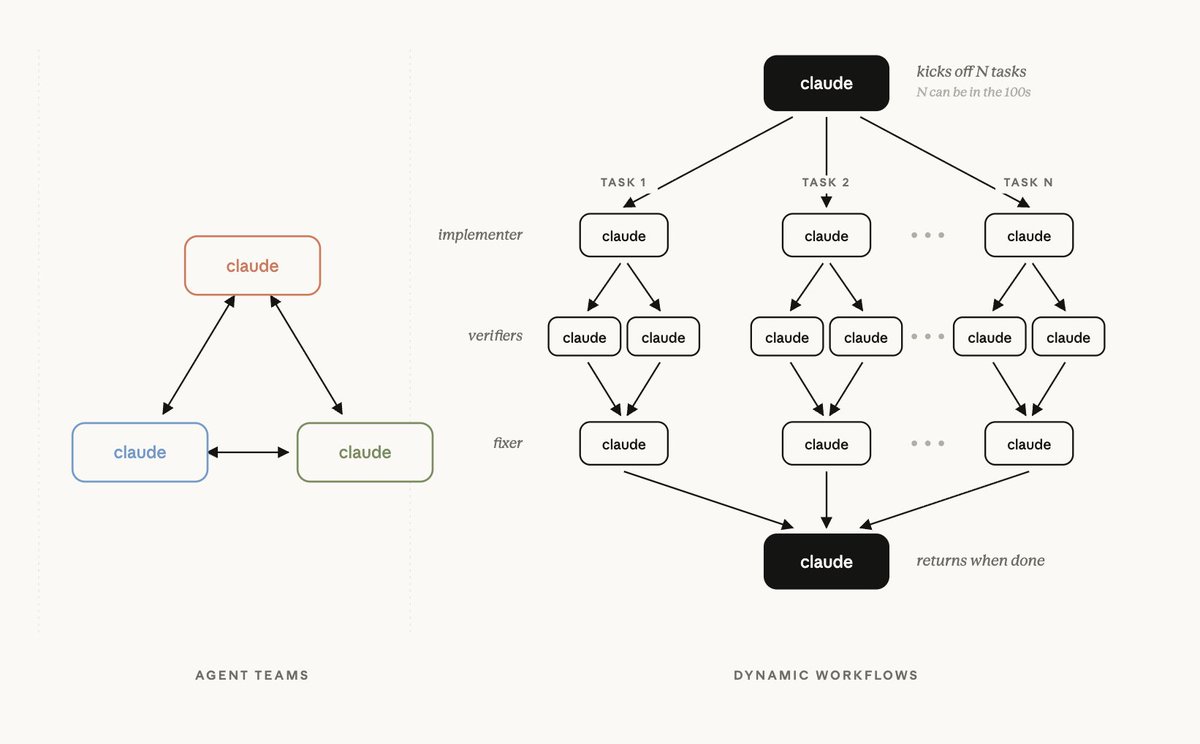
Excited to share our most powerful new Claude Code feature: dynamic workflows!
Mention "workflow" in a prompt and Claude will dynamically create an orchestration plan that it strictly follows, allowing you to confidently trust that every stage happens in the right order even across 100s of agents.
4
8
40
5,639
Winkle retweeted

May 28
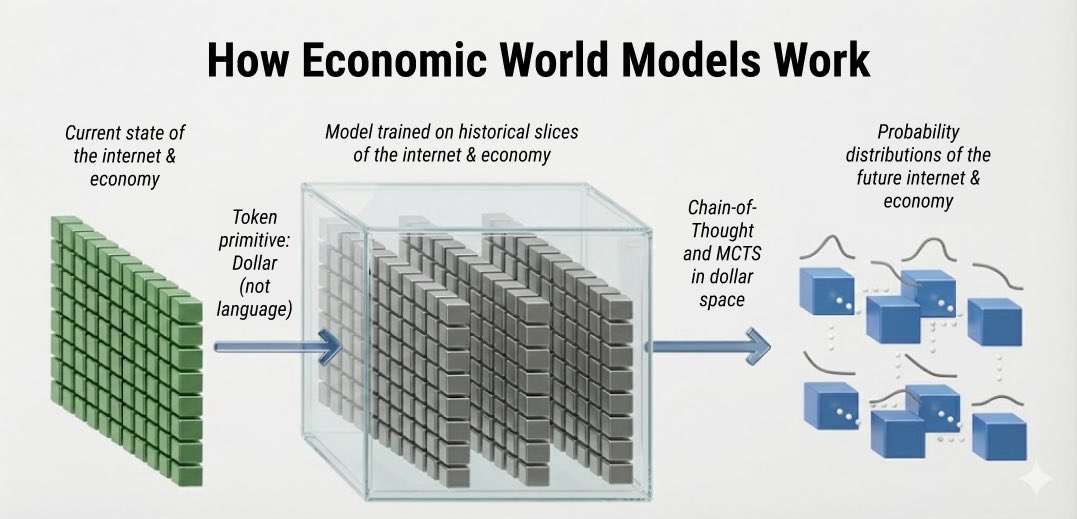
We present empirical evidence of the first general economic scaling law beyond language data.
We are incredibly excited to publish it, and definitively say:
Recursive Self-Improvement is
a Portfolio Optimization Problem
AlphaFund.com/whitepaper
21 Dec 2025

In the past 2 years we’ve gone from unprofitable to
> top 10%,
> top 1%,
with the upcoming launch of Mark3.5,
> top 0.1%
performing hedge fund.
However, a hedge fund is just a proof of technology. Our ambitions are much larger. AlphaFund Labs has built what SSI is trying to.
Our mission is to:
predict the future
of supply and demand
so that humanity
has the resources
that we need
when we need them.
If you want to support creating Economic SuperIntelligence, reach out. It’s the most important work in the world.
20
50
525
104,619