
1 Photos and videos
Ruslan Aydarkhanov retweeted

May 12
TheStage AI Platform is now open to everyone.
Automatically accelerate your models and download them to run in the cloud or on smartphones.
34
23
146
3,596,758
Ruslan Aydarkhanov retweeted
Apr 10
Beyoncé heard cursing. TheWhisper heard Arsenal.
The fastest Whisper in the world.
Open-source real-time ASR.
Top 5 on OpenASR benchmarks.
1800 RTFx.
Built for live captions, transcription, and voice apps.
See the repo
4
19
179
2,655,479

Apr 8
AI infra releases look simple from the outside.
In practice, it’s a lot of moving parts becoming one product. Elastic Models is our open-source library of accelerated models, and v0.2.0 brought updates across speech, video, image, and LLMs.
See what shipped in v0.2.0
4
17
Ruslan Aydarkhanov retweeted
Mar 19
How do you make text-to-music run in real time in production?
The model has to keep audio generation ahead of playback.
Our new case study with @MireloAI shows how inference optimization delivered up to 2.4х higher throughput.
See the full case study ↓
4
8
385
Ruslan Aydarkhanov retweeted
Mar 4
Proud to team up with @brilliantlabsAR and @neuphonicspeech on Halo’s on-device privacy engine.
Coming to Brilliant Labs’ Halo smart glasses: real-time voice vision, POV stays private.
ANNA GPU/NPU SDK memory manager for wake word, STT, TTS, diarization.
SDK demo 👇
6
9
25
2,324
Ruslan Aydarkhanov retweeted
Jan 22
Are you a big fan of jacket potato?
This is an open-source, real-time multilingual ASR for live speech.
It stays robust in heavy noise – even at SNR 0 dB.
That’s why it understands speech where people struggle to hear.
Use it for transcription, research, and multilingual apps
2
29
343
131,208
Jan 15
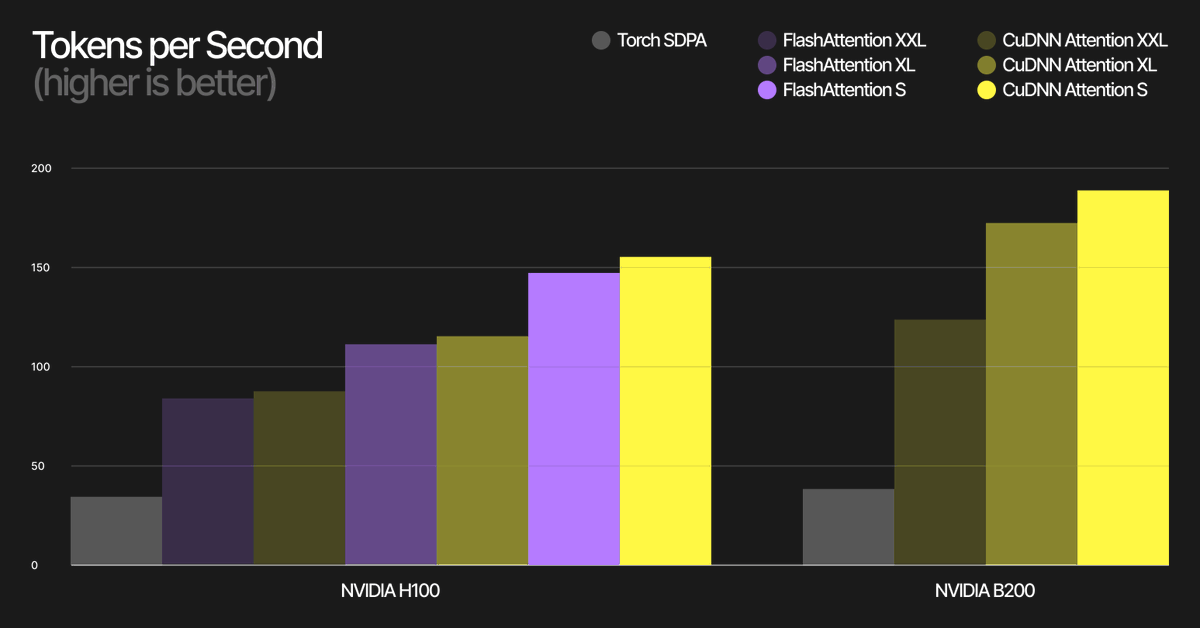
At @TheStageAI, Elastic Models started with paged FlashAttention.
This month we’re moving sequence generation to cuDNN Paged Attention to stay fast and speed up bring-up across newer @NVIDIA GPUs (including Jetson).
Details: app.thestage.ai/blog/Integra…
2
8
330
Jan 12
TheWhisper just got a big update.
It’s open-source, handles 11 languages, works with noisy audio, streams in real time, and runs on a single model.
I’ve been focused on making it as fast as possible while keeping SOTA quality across languages.
Try it out on Hugging Face →

1
22
120,602
Ruslan Aydarkhanov retweeted
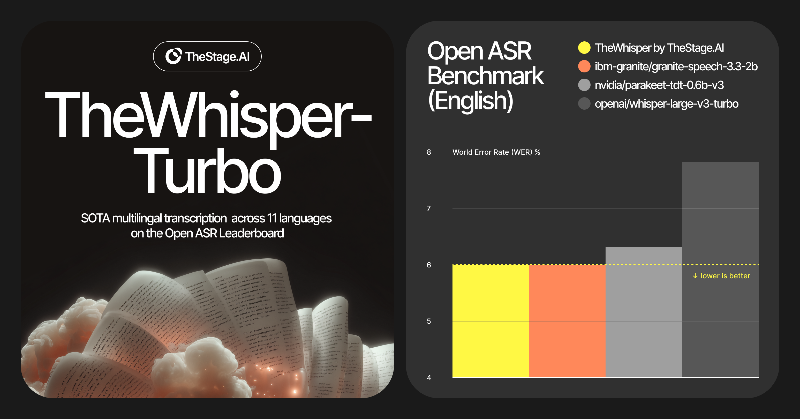
We updated TheWhisper.
Open-source multilingual speech-to-text for noisy, real-world audio.
6.00 WER on Open ASR, beating NVIDIA Parakeet and OpenAI Whisper.
Compressed and accelerated with @TheStageAI ANNA, Automated Neural Networks Accelerator.
Try it on our GitHub →
4
8
95
523,236
18 Dec 2025
In voice AI, latency and speed matter. Lower Time to First Token makes voice interfaces respond faster. Higher Real-Time Factor keeps captions aligned with speech. We built TheWhisper, our open source self-hosted speech-to-text engine, with this in mind. Test it here
github.com/TheStageAI/TheWhi…
4
55
Ruslan Aydarkhanov retweeted
4 Dec 2025
Significant speed and size gains in model inference are possible without hurting output quality.
ANNA is our PyTorch framework for automated model acceleration, a new way to think about MLOps.
Smaller ckpts, lower cost, faster inference, no retrain.
Test demo or request access

1
8
149
844,222

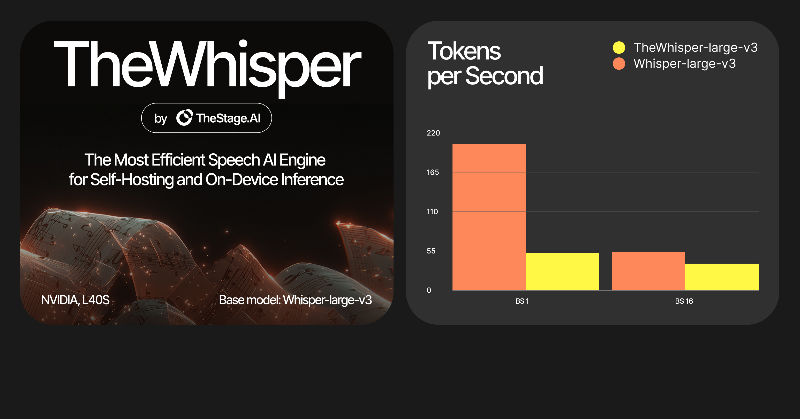
We posted a tutorial on real-time on-device transcription using TheWhisper, our optimized open-source model at @TheStageAI.
It runs short windows on Apple Silicon with sub-150 ms latency and about 2 W power.
Build fast speech apps on your Mac

4
20
210
753,157
Ruslan Aydarkhanov retweeted

30 Oct 2025
We believe that everyone will become a model builder! That's why we are creating an automated acceleration and deployment stack which undestands ai engineers needs
30 Oct 2025

We’re finally reaching the era of everyone training their own models based on open-source (versus relying on black box generalist APIs) and it is glorious!
1
3
15
8,544

Ruslan Aydarkhanov retweeted
9 Sep 2025
Excited to share our MLPerf Inference v5.1 results (@MLCommons).
We ran @StabilityAI SDXL on 8×H100 via @nebiusai with our stack, ANNA.
18.1 img/s in target quality range.
Fast, reproducible, world-class performance from our team, submitted alongside top AI players ↓

5
30
165,434