
PhD student @UTAustin | @AmazonScience AI PhD Fellow | Towards super-human AGI using RL🚀
Joined December 2016
- Tweets 145
- Following 345
- Followers 387
- Likes 434
37 Photos and videos
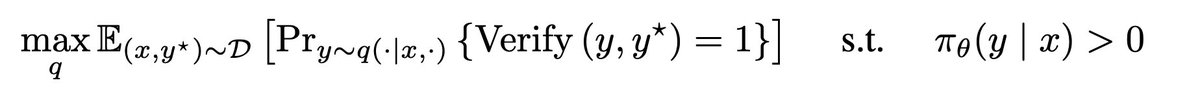

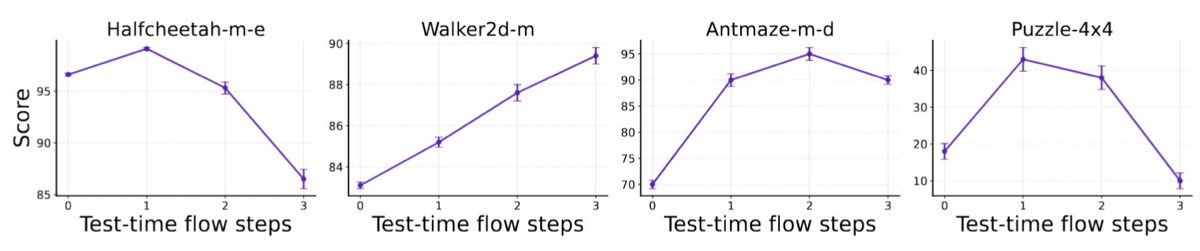




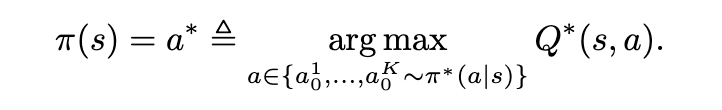
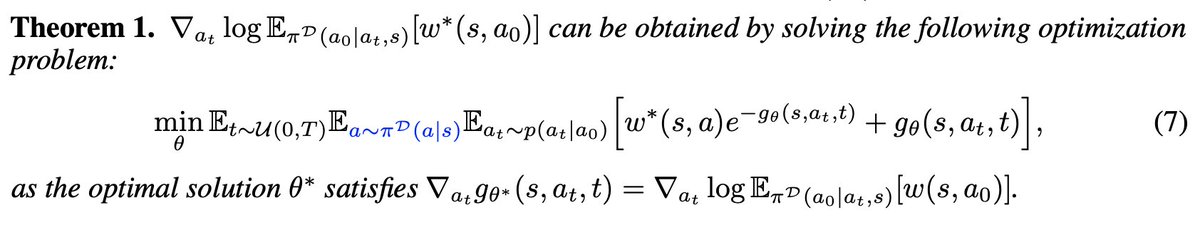
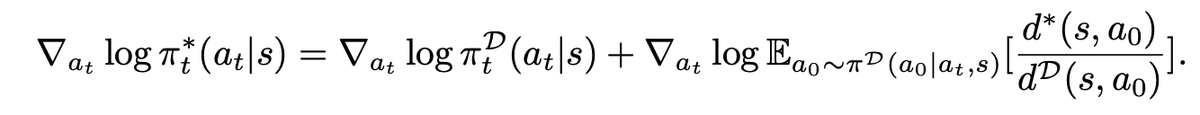

Both offline RL and LLM RL fine-tuning can be formulated as behavior-regularized RL problems.
We propose Value Grdient Flow (VGF), a new scalable and sample-efficient paradigam that treats behavior-regularized RL as an optimal transport problem.
arxiv.org/abs/2604.14265 🧵[1/7]
3
23
176
13,601
Haoran Xu retweeted

Jun 10
对搞 AI agents、reasoning model 的人来说,这篇论文真的很实用性有趣。
如果你在做 reasoning model 的 post-training、蒸馏、on-policy 数据生成,或者想改进小模型的长链思考能力,这篇能给你一个干净的思路和可落地的 trick。
尤其对 hard math 问题,收益比较实在。
现在训小模型学大模型的长链思考,像 o1 那种,常用 on-policy distillation是让小模型自己先生成 reasoning 轨迹,一步步写思考过程,然后大老师模型在它生成的轨迹上逐个 token 教它。
小模型如果开头几步就走错了,后面再怎么写都救不回来。这时老师还得硬着头皮在那个带病前缀上继续监督。
结果老师自己的输出分布会分裂成两半,一半想继续错下去,一半想纠正,给学生的学习信号就变得很乱、梯度碎片化。
以前大家各种修 token loss 的 trick,比如截断、重加权、top-k 啥的,都只能治标不治本,因为问题根子在整个轨迹的前面就坏了。
就像是学生写数学证明,第一步假设错了,老师还得在错的假设上逐字批改后面每一步,教出来的东西自然稀碎。
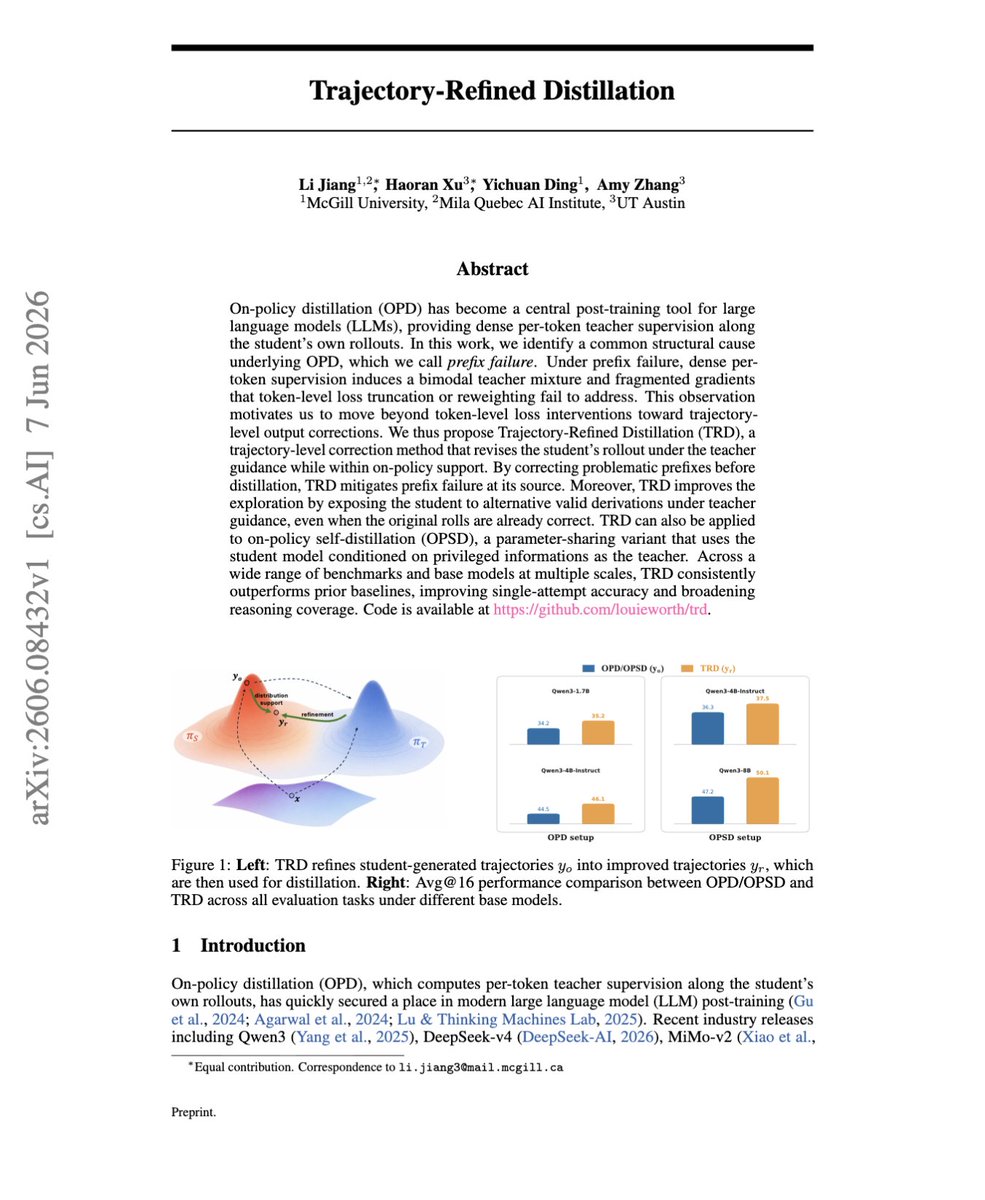
论文的解法是Trajectory-Refined Distillation。
不直接在学生原始轨迹上蒸馏,主要让老师先把整个学生轨迹重写、精炼成一个更好的版本,修正错误前缀,同时尽量保留学生原来有用的部分和风格,保持在学生分布支持内。然后,学生去模仿这个被老师修正过的干净完整轨迹。
我理解这种方法算是把监督从token 级修补升级到trajectory 级修正了。
尽管这只是incremental contribution,而且相当依赖老师 refinement 的质量,如果老师不够强,修正效果会打折。但是整体上把把 prefix failure”这个现象说清楚、形式化了,还有实验证据支持已经很好了。
个人的品味,感觉这篇尤其在难的数学题上 gains 明显,还能让轨迹变短,更高效,自蒸馏时甚至能解出原来完全解不出的题。一个小改动就实际能用的感觉很舒服。
Jun 10

"Trajectory-Refined Distillation"
This paper shows a core failure in on-policy distillation.
When a student takes a wrong reasoning path, the teacher is forced to supervise from that broken prefix, so token-level KL becomes noisy.
So they introduced TRD that fixes this by refining the whole rollout first.
What it does is the teacher rewrites the student trajectory into a better reasoning path, then the student distills from that corrected trajectory.
While this is a small change, it still moves distillation from token fixes to trajectory fixes, giving cleaner supervision and stronger reasoning gains.
3
19
116
13,048
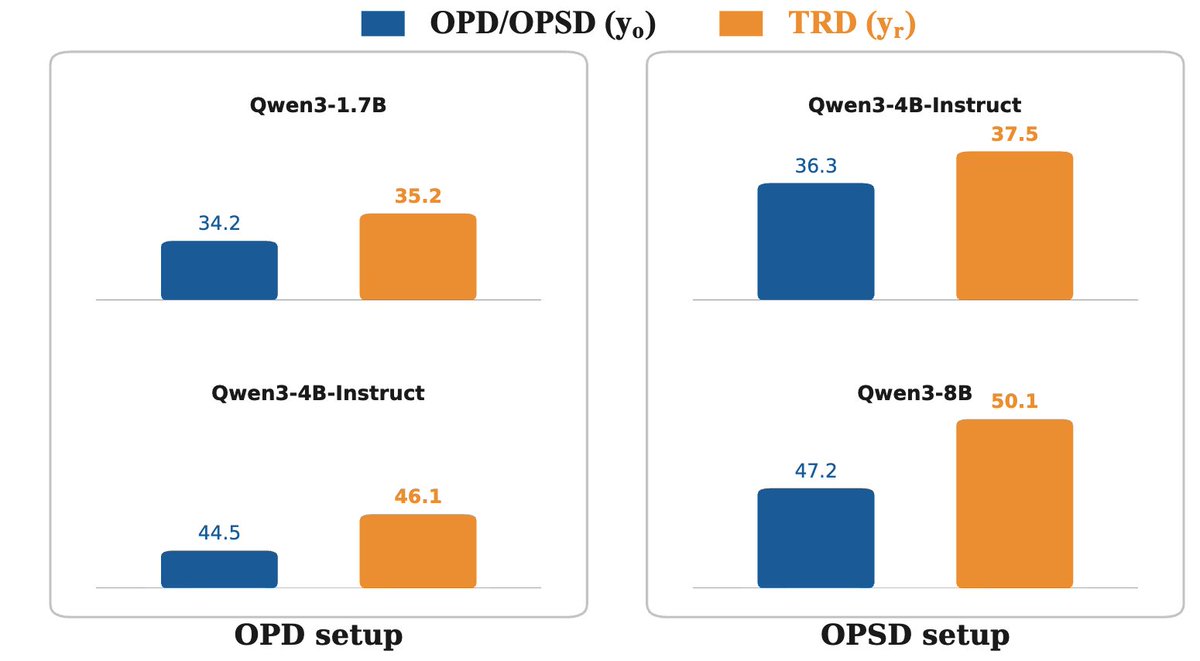
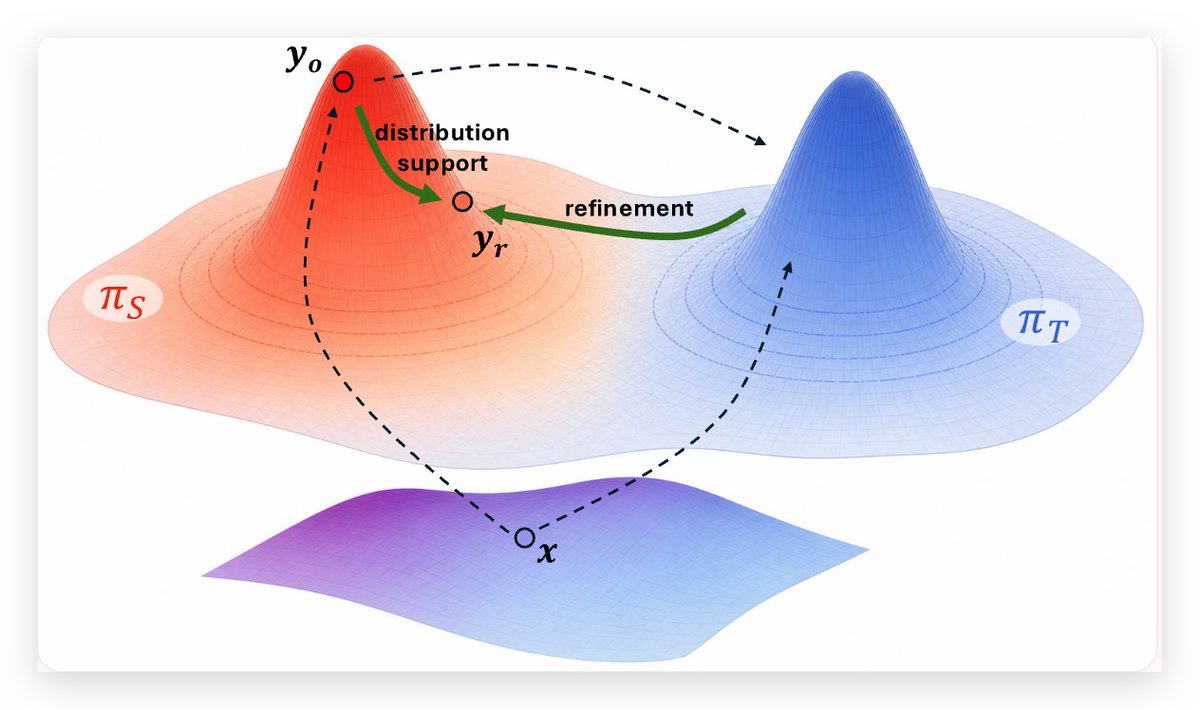
🤔On-policy (self) distillation has a prefix failure issue: when the student's rollout y_o is wrong (far from the teacher distribution), the teacher’s gradient signal becomes problematic.
🚨Introducing Trajectory-Refined Distillation (TRD), a trajectory-level refinement of y_o to solve the issue.
tldr: OPD/OPSD❌ TRD ✔️
Paper: arxiv.org/pdf/2606.08432
4
16
152
10,148
This is a great blog by @louieworth summarizing recent on-policy distillation papers and introducing new perspectives!
Jun 9

New blog post: On-Policy Distillation — Promise, Pitfalls, and Prospects.
OPD combines on-policy rollouts with dense teacher supervision.
But it is not a free lunch.
I discuss three failure modes and introduce our new paper.
louieworth.github.io/blog/op…

1
1
389
Haoran Xu retweeted

Jun 9
OPD is on-policy, but its supervision is still post-hoc and one-step.
The student generates a rollout. The teacher then supervises that fixed trajectory token by token.
Our new paper argues that this can fail at the wrong scale.
When the prefix itself is broken, the problem is not only which tokens to reweight, clip, or truncate. The problem is the trajectory.
We propose Trajectory-Refined Distillation (TRD): refine the student rollout under teacher guidance before distillation.
with @ryanxhr Yichuan Ding @yayitsamyzhang
Paper: arxiv.org/pdf/2606.08432
4
12
93
4,906
We find that token-level loss (reweighting/clipping) is not enough to solve this issue.
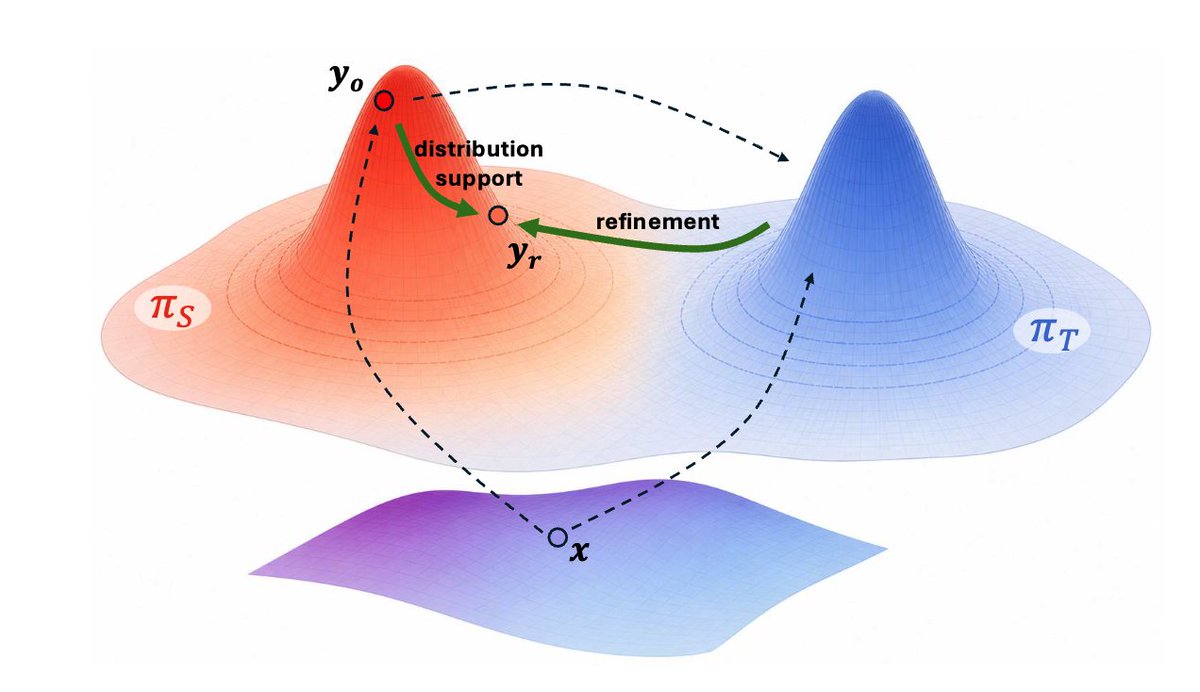
TRD refines y_o into y_r that stays within student's support while maximizing the verified reward, y_r thus stays closer to the teacher distribution.
TRD uses y_r to do knowledge distillation, this is not strictly on-policy, but we find this mildly off-policy distillation works pretty well empirically.
1
1
2
617
Check @louieworth's post for more details!
x.com/louieworth/status/2064…
Jun 9
OPD is on-policy, but its supervision is still post-hoc and one-step.
The student generates a rollout. The teacher then supervises that fixed trajectory token by token.
Our new paper argues that this can fail at the wrong scale.
When the prefix itself is broken, the problem is not only which tokens to reweight, clip, or truncate. The problem is the trajectory.
We propose Trajectory-Refined Distillation (TRD): refine the student rollout under teacher guidance before distillation.
with @ryanxhr Yichuan Ding @yayitsamyzhang
Paper: arxiv.org/pdf/2606.08432
1
355
Haoran Xu retweeted

Apr 20
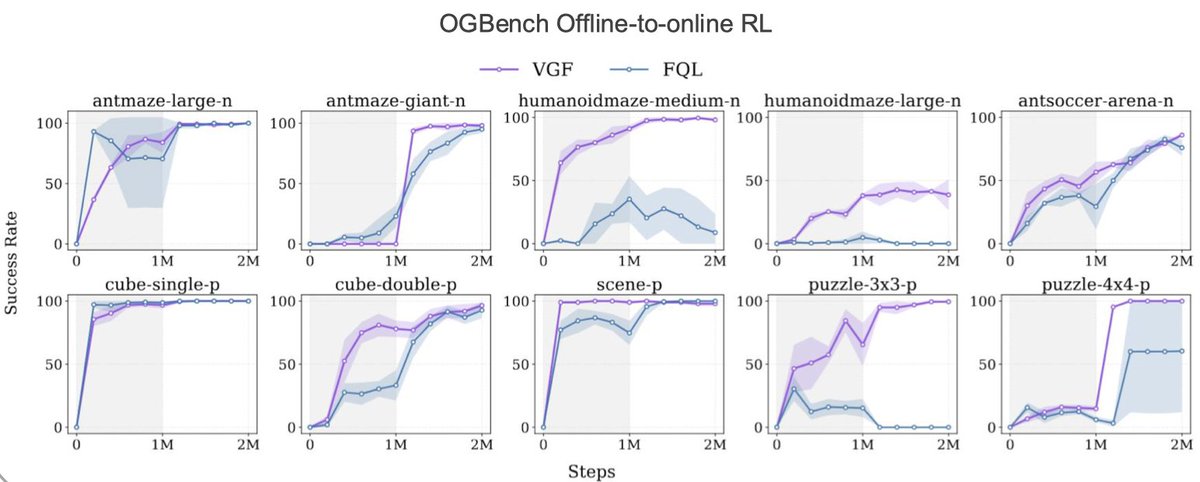
@ryanxhr has developed this very nice work framing offline RL as an optimal transport problem, with SOTA results on offline RL benchmarks and LLM RL tasks. Check it out, and chat with him at ICLR!

Both offline RL and LLM RL fine-tuning can be formulated as behavior-regularized RL problems.
We propose Value Grdient Flow (VGF), a new scalable and sample-efficient paradigam that treats behavior-regularized RL as an optimal transport problem.
arxiv.org/abs/2604.14265 🧵[1/7]
3
39
2,802
Both offline RL and LLM RL fine-tuning can be formulated as behavior-regularized RL problems.
We propose Value Grdient Flow (VGF), a new scalable and sample-efficient paradigam that treats behavior-regularized RL as an optimal transport problem.
arxiv.org/abs/2604.14265 🧵[1/7]
3
23
176
13,601
Both offline RL and LLM RL fine-tuning can be formulated as behavior-regularized RL problems.
We propose Value Grdient Flow (VGF), a new scalable and sample-efficient paradigam that treats behavior-regularized RL as an optimal transport problem.
arxiv.org/abs/2604.14265 🧵[1/7]
3
23
176
13,601
This is joint work w/ @KaiwenHu856, Somayeh Sojoudi, @yayitsamyzhang.
Paper: arxiv.org/abs/2604.14265.
Code: github.com/ryanxhr/vgf.
A nice walkthrough: arxivexplained.com/papers/re….
I will present VGF at @iclr_conf and can't wait to see you all at 🇧🇷. 🧵[7/7]
1
2
335
I will be at #NeurIPS2025 from 12/3 to 12/7 to present two papers. Come to chat everything about RL!
1️⃣ Unifying Online and Offline RL via Implicit Value Regularization
🗓️ Thu, Dec 4, 11:00 AM – 2:00 PM, Exhibit Hall C, D, E #303
1
4
263
Grateful and honored to receive the Amazon AI Fellowship to support my research!
21 Oct 2025

Excited to announce @amazon's new AI PhD Fellowship Program supporting 100 students across 9 universities like Carnegie Mellon, MIT & Stanford. Fellows will be paired with senior scientists working in related fields, plus receive financial support and AWS credits for research. Learn more: amazon.science/news/amazon-l…

6
306